本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Windows Azure Storage
- Nosql:TiKV为例
- 总结
引言
天才的开源精神对于普通人来说是一种莫大的福音,好在老天爷赏饭个人无法决定,但论文和github确是没有门槛的。再次感谢巨硬赏饭吃[1]。
大概两年以前写过一篇名为《聊聊块存储、文件存储、对象存储》的文章,以当时的认知谈论这样一个话题其实很难有一些有意义的观点,但是对我来说看着自己认知转变的过程确实是有趣的。
[4]中各路大佬的回答高屋建瓴,对于模型之间关系描述基本没有什么需要补充点了,在[5]中提到:
相对于文件存储目录树的组织形式,对象存储OSS采用扁平的文件组织形式,采用RESTFul API接口访问,不支持文件随机读写,主要适用于互联网架构的海量数据的上传下载和分发。
扁平的名称空间可以高度概述对象存储,但是我认为这不是选型的核心因素,对象存储的各种操作可以轻松的用Nosql代替。以目前兴起的serverless计费模式来看,nosql和对象存储都是根正苗红的paas产品,那么在nosql能力可以轻松覆盖对象存储时到底区别在哪里呢?这个问题类似于前段时间在公司和一个朋友的讨论,如果ES的查询能力(CTSDB)确实强于时序数据库,那为什么时序还要存在呢?这些问题的答案都一样,本质上是取舍。
以目前腾讯云上的产品来看看:
对象存储:

文件存储:

块存储:
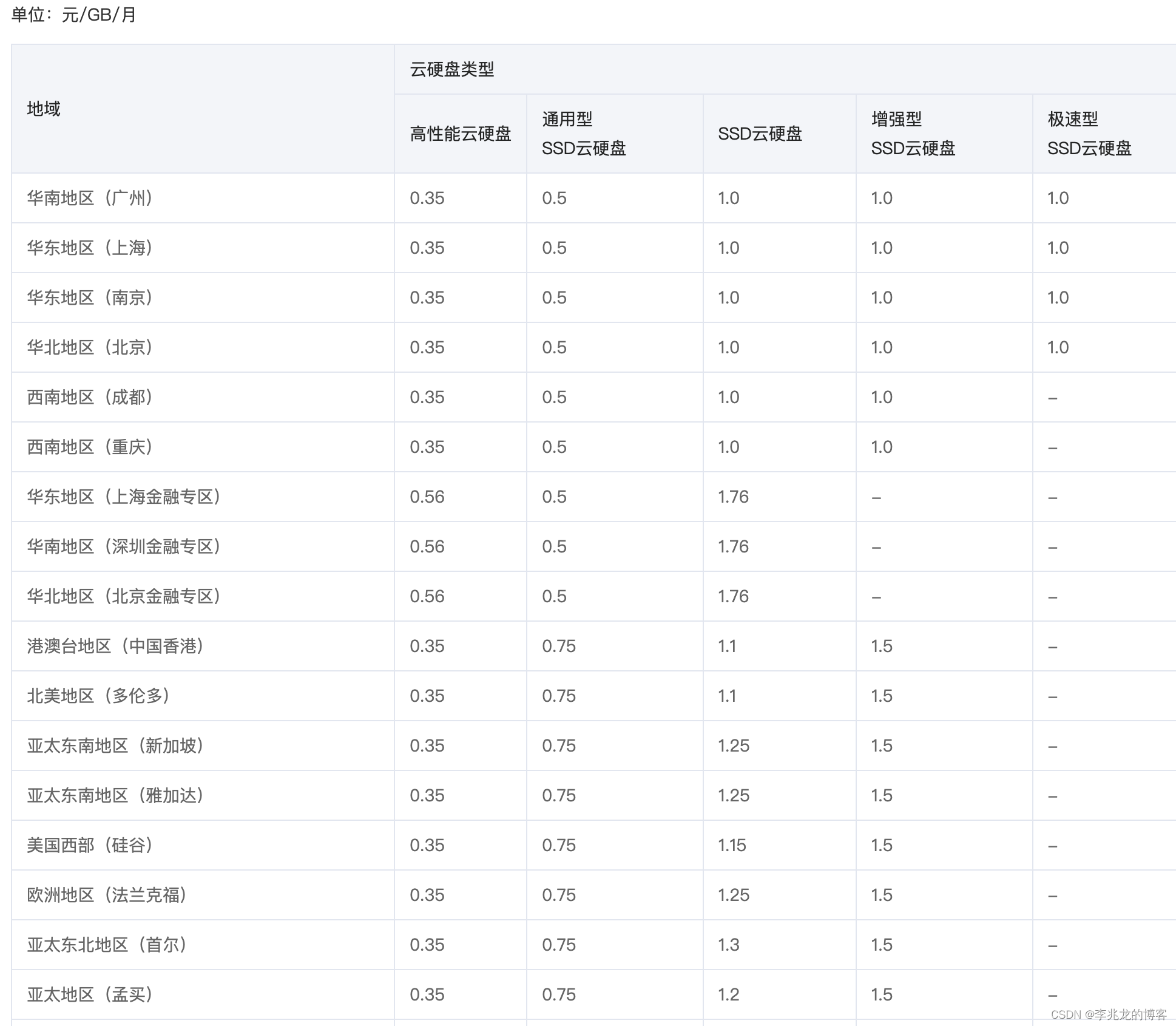
多快好省是不存在的,在成本,性能,吞吐之间的权衡才是选型的关键,但为什么成本的差距会如此巨大呢?我们从架构的角度谈一谈这个问题。
Windows Azure Storage
关于Global Partitioned Namespace不必多谈,事实上到现在对象存储的模型还是没变,即app_id+bucket_id+obj,其实也就是下面图中的url。
WAS[1]基本架构如下,这套架构的影响之大让我觉得现在的绝大多数公有云厂商可能还在使用(可能除了S3)。
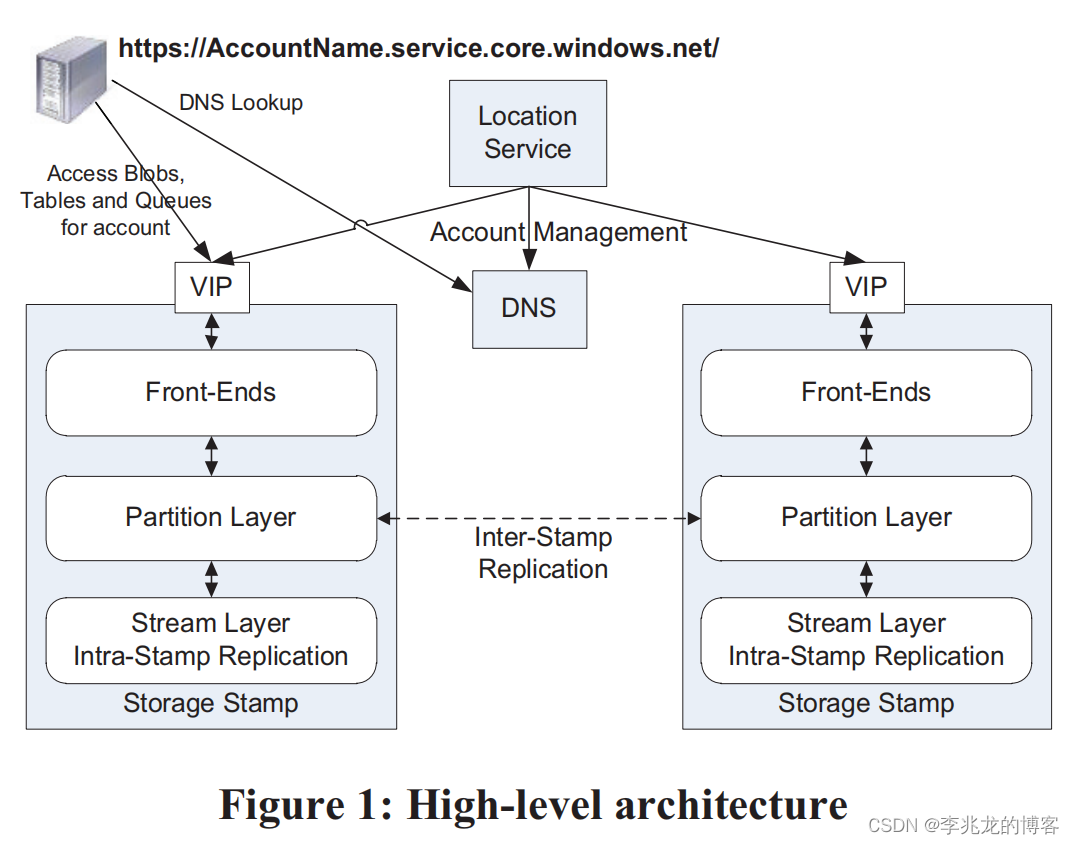
整个对象存储大核心流程即为Storage Stamp,基本被分为三个部分,从用户的请求到数据存储到链路为:
- Front-End Layer:负责对象存储本身的产品级能力,以及转发请求到不同的Partition Layer。
- Partition Layer:核心模块,论文中提到这里的内部数据结构为一个对象表,其中存储表结构,数据及其他抽象,这里显然是会存储对象到Stream Layer的索引的,不然论文中也不会说Partition Layer到数据可以到PB级别。
- Stream Layer:实际存储文件的存储模块,其核心概念为Stream/Extent,论文中提到每个Stream在Partition Layer中看来都是一个大文件,而且每一个Extent都是append only的,当然这意味着需要一些垃圾回收策略,因为对象本身是可修改的。
论文中的如下概念我比较感兴趣:
- 因为append only的特性,并不是所有的Extent的数据都是三副本的,对于更冷的数据会用纠删码降低存储成本,以原文中的数据来看可以把存储成本从3倍降低到1.3到1.5倍。这也意味着Stream Layer的架构和现在流行的Nosql架构师不同的。(在nosql中我们是否可以使用纠删码来做巡检中的key修复,以抵御SSD字节级别故障?)
- 高性能日志:很多硬盘被优化为实现更高的吞吐量,在IO中倾向于选择更连续的IO请求,这意味着大规模的流式写入可能会是的IO公平性较差,导致部分IO处于饥饿状态,这会导致上层请求排队非常严重,这启发我们如果硬盘IO处于关键路径时硬盘的IO调度算法是一个必须被考虑的问题。WAS种保留一个独立的HDD/SSD作为日志驱动,这使得WAL和LOG不必与数据盘的IO操作竞争。
- 监控能力:在2011时ELK体系与Prometheus生态还没有完善,文中提到WAS使用一个与用户数据所在Storage Stamp的巨大虚拟机完整的控制所有的计算节点,以实现近实时的吞吐监控。当然现在不必这样了。
- 租户级隔离:文中提到使用Sample-Hold 算法前N个负载最高的partition,根据历史访问信息判断在过载时拒绝的概率。这种方法很好想,实施也很简单,这也从侧面显示,WAS也是多租户在同一个LSM树中的,这种能力需要引擎支持。PS:这本来上篇文章中想要讨论的问题。
- Pressure Point Testing:提供了自动发起分裂/合并/迁移/Checkpoint及其他操作的toolkit,以及网络故障,磁盘延迟注入等,这些能力看似鸡肋,实则为这样一个复杂系统维护过程中必不可少的工具。我一直认为计算机领域一个天才胜过100个庸才,所有人都知道故障注入,只有奈飞的大神们提出了混沌工程理论。
- Name Server:名字服务现在已经模块化了,完全不必对象存储团队去做。
- 初始的WAS中提供的其实是tablet,queue,blob三种模型,不同模型对于性能的要求不同,在同一组硬件部署不同的服务可以降低成本。
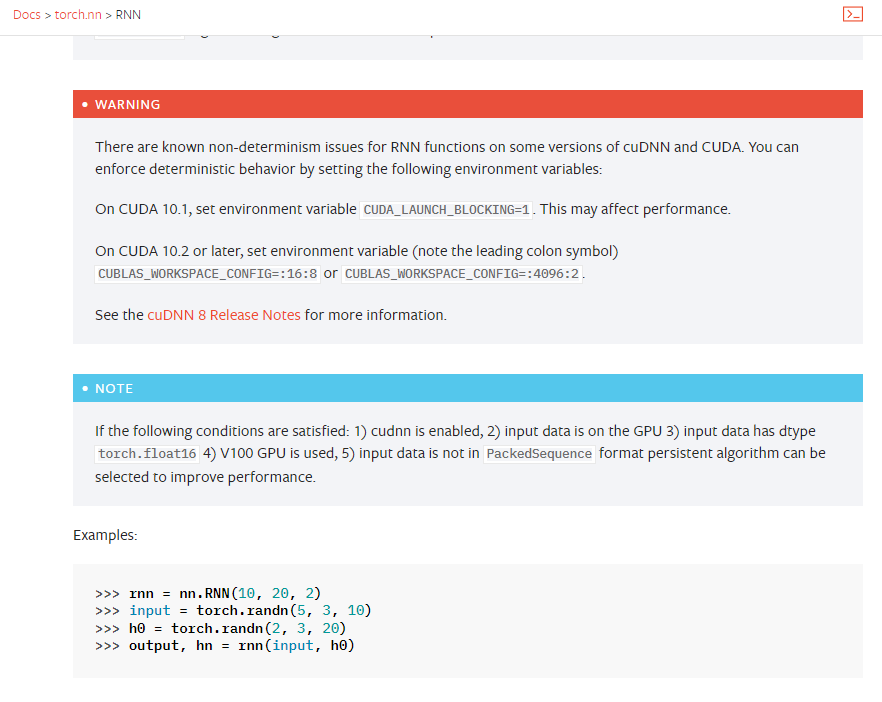
Stream Layer在文中被描述为如下职能(对理解这篇paper非常重要的一句话):
The stream layer provides an internal interface used only by the partition layer. It provides a file system like namespace and API, except that all writes are append-only. It allows clients (the partition layer) to open, close, delete, rename, read, append to, and concatenate these large files, which are called streams. A stream is an ordered list of extent pointers, and an extent is a sequence of append blocks.
看起来Stream Layer拥有如下特点
- 基础数据模型为Stream+Extent
- append only,意味着在上层修改操作下底层需要回收不再被Stream指向的Extent,每一个Extent Nodes (EN)中仅仅存储连续多Extent,Stream的概念只在Stream Manager 中。
看起来Stream Layer是一个块存储模块,但是我对块存储并不熟悉,这种数据组织形式在引擎来说和KV相差很大。
Nosql:TiKV为例
图片来源[6]
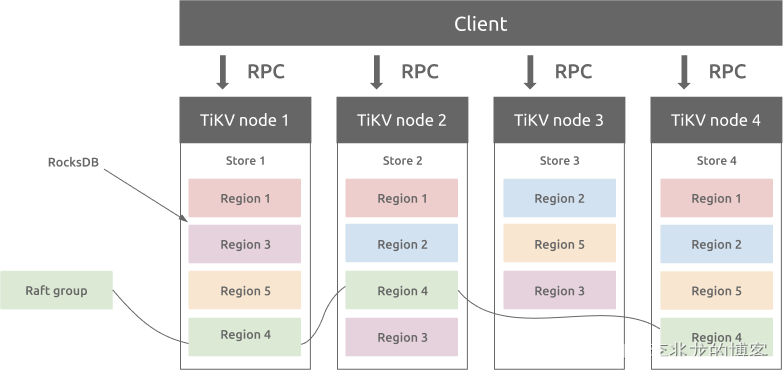
现在仿佛只要是个人就要调侃一下Nosql不就是RocksDB+Raft吗,最可怕的是这句话好像也没法反驳。
分布式KV系统要提供的语义简单的多,宏观来讲架构也清晰的多,基本上分层如下:
- API + 协处理器
- 事务层
- MVCC
- 复制
- 存储引擎
首先从成本上讲,为了能拿出手的性能,SSD是标配,其次基本不可能混部。事实上不可能所有的数据都是热数据,降冷几乎是必须的,怎么降呢?同一套引擎再搞个HDD的?或者硬盘异构混部?不可能的,直接扔对象存储完事。
再者本身TiKV作为存储节点,因为协处理器又有不少的计算任务,本身的资源利用率再调度合理的情况下已经不错,所以架构上基本都没啥区别。再者WAS的Partition Layer中的Object Table看起来也就是个KV。
不过基于对象存储前端的特殊的接口与访问方式,Partition Layer的具体实现其实有很多技术难点,这里不再细谈。
总结
此刻回答文首的两个问号,以我拙见,针对于不同数据模型,介质,成本,性能,负载,工业界/学界有不同的优化方法,具现后就是不同的产品,了解权衡才是选择与设计的关键所在。
所以一切的一切本质就是回归到云的真谛,成本与弹性。
所以再次回到两年前的那个问题,块存储、文件存储、对象存储到区别是什么呢?我并不知道如何解释这个问题,但是我知道接口并不是唯一的突破点,这是两年期间的进步,
WAS论文中提到同一堆栈中不同模型对于性能的要求不同,在同一组硬件部署不同的服务可以降低成本,接着[7]中satanson大佬的观点,和现有的事实,我认为下一步我们要做的事情可能是:
- 不通模型混部以提升资源利用率,而不是更细粒度的租户隔离
- 更多模型特化的data flow,以提升性能
- …
复制问题已经消解,读写链路,运营能力可以公用,确实只剩引擎可以留给不同模态的优化了,对于绝大多数场景来讲要上已经完全够用了,成本的优势足以抵消部分性能需求,而且本来和内存数据库的市场也不一样,nosql的未来在工业界应该是多模的,极致性能留给学界吧。
最后一点,Windows Azure Storage这篇典型的工业论文写的极有水平,不知道能不能拿个SIGOPS Hall of Fame Award,毕竟DynamoDB,BigTable,Spanner,Chubby这些先驱都拿奖了,个人感觉[1]和上面四个是一个水平的。
参考:
- Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency
- ECC之Reed-Solomon算法
- 聊聊块存储、文件存储、对象存储
- 块存储、文件存储、对象存储这三者的本质差别是什么?
- 如何选用NAS、OSS和EBS?
- TiKV简介
- 到现在为止,NoSQL 运动给数据库系统留下什么宝贵的思想?