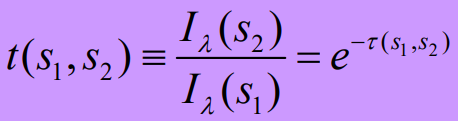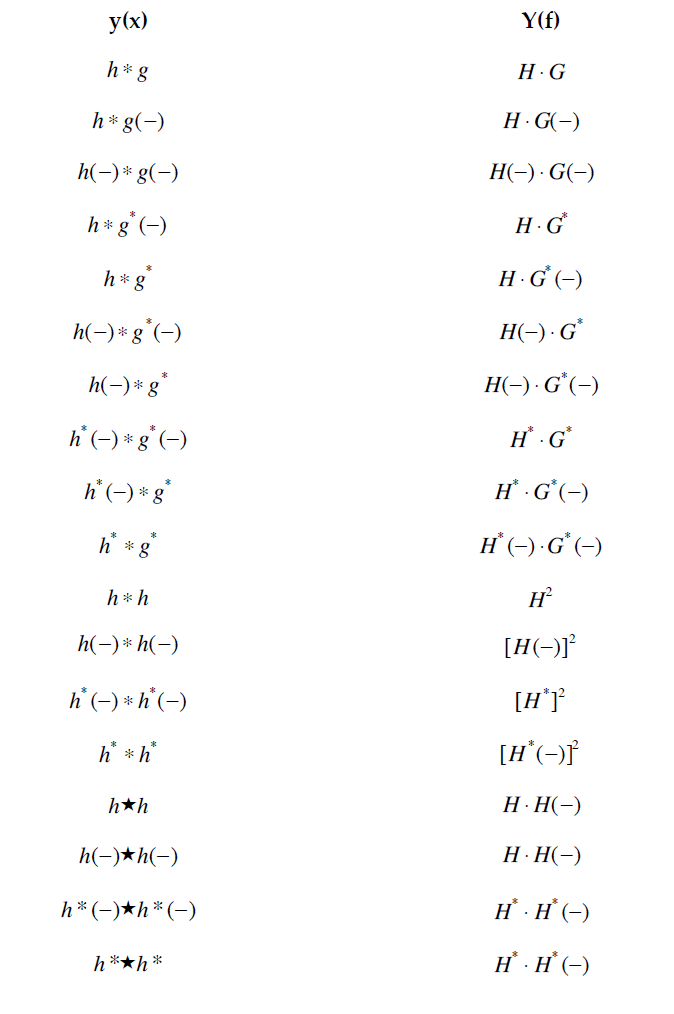One2Multi Graph Autoencoder for Multi-view Graph Clustering | Proceedings of The Web Conference 2020 (acm.org)
目录
Abstract
1 Introduction
2 Model
2.1 Overview
2.2 One2Multi Graph Convolutional Autoencoder
Informative graph convolutional encoder
Multi-view graph decoder
Reconstruction loss
2.3 Self-training Clustering
2.4 Optimization
Abstract
多视图图聚类受到关注,它寻求用,可以提供更全面但更复杂信息的多个视图,对图进行划分。虽然一些方法在多视图聚类方面取得了不错的成功,但大多采用shallow model处理多视图图内部的复杂关系,会限制多视图图信息建模能力。
作者首次尝试将深度学习技术应用于属性多视图图聚类,提出了一种新的任务导向的One2Multi图自编码器聚类框架。One2Multi图自编码器能够通过使用一个信息图视图和内容数据来重建多个图视图学习节点嵌入。因此,可以很好地捕获多个图的共享特征表示。在此基础上,提出了自训练聚类目标,迭代改进聚类结果。通过将自训练和自编码器重构整合到一个统一的框架中,模型可以共同优化适合图聚类的聚类标签分配和嵌入。
1 Introduction
大多数图聚类方法只关注处理一个图,但现实中图形数据很复杂。因此要使用多视图图而不是单视图图,来更好表示实的图数据,其中每个图视图代表节点之间的一种关系。以学术网络为例,一个图视图可以表示共同作者关系,另一个图视图可以表示共同会议关系,作者还可以与代表性关键字相关联,作为其属性。这种复杂图通常被称为属性多视图图,它以互补和综合的方式对交互系统进行建模,具有更准确的图聚类潜力。
属性多视图图聚类可以被分为两类:(1)基于图分析的方法。其目的是最大化不同视图之间的相互一致性,从而将图划分为组。(2)图嵌入。利用图嵌入技术从多视图图数据中学习节点的表示,随后使用k-means等传统聚类方法。
但这些方法都被认为是浅层模型,对揭示复杂图数据中的深层关系的能力有限。此外,上述方法对节点属性信息关注较少。
近年来,GNN作为一种深度非线性表示学习框架,在节点分类和聚类等图分析任务上显示出了强大的性能。然而,大多数gnn是针对单视图图开发的。此外,也有一些作品将GNN扩展到多视图设置,但它们是在半监督场景下设计的,用于分类任务。将CNN用于属性多视图图聚类会遇到挑战:(1)简单的融合方法建立多个模型,开发多个编码器和解码器,每个编码器和解码器对应于每个视图。然而,由于引入了不同视图中包含的噪声,这种简单的方法并不有效。更重要的是,multi2multi模型只能单独提取每个视图表示,而共享表示可能对任务更重要。从所有观点中学习也很耗时。(2)如何使GNN学习到的嵌入更适合聚类任务?节点嵌入和聚类通常是两个独立的任务。节点嵌入的目的是重建原始图,因此学习到的节点嵌入不一定适用于节点聚类。因此,需要以统一的方式优化节点嵌入和聚类。
观察真实的多视图图数据,可以发现:(1)虽然多视图信息从不同方面反映了节点关系,但它们应该具有一些共同的节点特征。(2)在许多场景中,通常存在一个最具信息量的视图比其他视图产生更好的聚类效果。
本文提出了一种新的One2Multi图自编码器框架,用于属性多视图图聚类。该模型的基本思想是从信息量最大的图视图和内容数据中提取共享表示,然后利用共享表示重构所有视图。根据这一思路,我们设计了一种新型的One2Multi图形自编码器,它由一个编码器和多个解码器组成。具体来说,它利用多视图图结构和节点内容来学习节点表示,通过一个多层图卷积网络(GCN)编码器从最具信息量的视图中学习节点表示,多个图解码器重构所有视图。进一步,设计了自训练聚类目标,使当前聚类分布趋近于更适合聚类任务的目标分布。通过联合优化重构损失和聚类损失,该模型可以同时优化节点嵌入和聚类,并在统一的框架内相互改进。
贡献总结如下:
(1)第一次将图深度学习用到多视图图聚类;
(2)提出了一种新的One2Multi自编码器框架,用于属性多视图图聚类,One2Multi 图自编码器提供了一个有效的深度框架来集成多视图图结构和内容信息。此外,该框架还对多视图图嵌入学习和图聚类进行了相互促进的优化。
2 Model
2.1 Overview
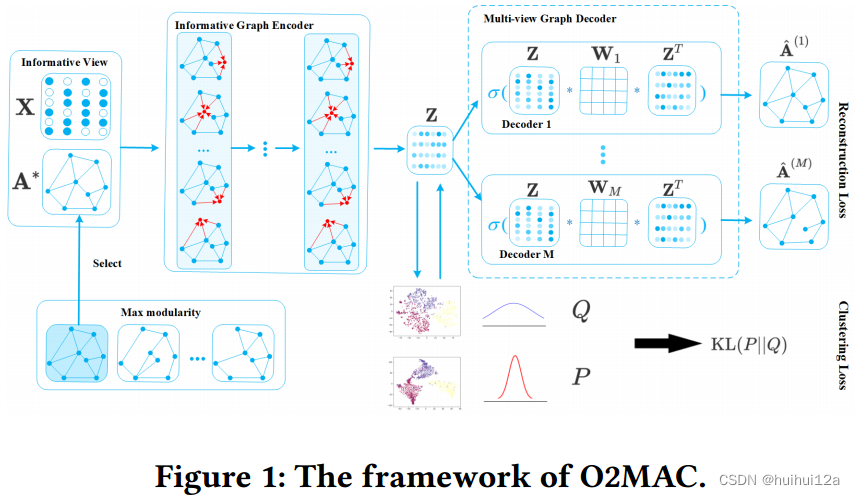
该模型主要由两部分组成:One2Multi图自编码器和自训练图聚类。One2Multi图自编码器由一个信息图编码器和多视图图解码器组成。采用启发式度量模块化方法,选择信息量最大的视图作为图编码器的输入,将图结构和节点内容编码为节点表示。
然后设计了一个多视图图解码器来解码表示,以重建所有视图。由于One2Multi图自编码器的精致设计,它不仅学习了共享表示,而且吸收了不同视图的结构特征。使用由学习嵌入本身生成的软标签来监督编码器参数和聚类中心的学习。对多视图图的嵌入和聚类在统一的框架中进行优化,从而得到一个信息丰富的编码器,使其表示更适合聚类任务。
2.2 One2Multi Graph Convolutional Autoencoder
为了在统一框架中表示多视图图结构A(1)、···、A(M)和节点内容X,作者开发了一种新的One2Multi图自编码器(O2MA)架构,其中所有视图共享一个图卷积编码器,从一个信息图视图和内容数据中提取共享表示,并设计了一个多解码器,从共享表示中重构多视图图数据。
Informative graph convolutional encoder
由于不同的图视图是在同一组节点之间通过不同方面表示关系,并且所有图视图共享内容信息,因此视图之间存在共享信息。此外,在许多场景中,通常存在一个最具信息量的视图来有最好聚类性能。因此,信息视图和其他视图之间的共享信息可以从信息量最大的图视图和内容数据中提取出来,然后用于重构所有的图视图。
基于上述假设,以信息量最大的图视图A∗∈{A(1),···,A(M)}和节点内容信息X作为输入,重构所有图视图。使用启发式度量——模块化,来选择信息量最大的视图。首先将每个单视图图邻接矩阵和内容信息分别馈送到GCN层中学习节点嵌入,然后对学习到的嵌入执行k-means来获得它们的聚类指标。基于聚类指标和邻接矩阵,计算每个图视图的模块化得分,并选择得分最高的图视图作为信息量最大的图视图。因为模块化提供了评估聚类结构的客观度量。
信息图编码器是两层的GCN,初始的节点嵌入是节点的属性:

Multi-view graph decoder
为了监督编码器提取所有视图的共享表示,提出了一种多视图图解码器,从表征Z,重构出多视图数据,解码器由M个特定于视图的解码器组成
,预测视图m中两个节点之间是否存在连接,Wm是视图m的特定于视图的权重。也就是基于图嵌入训练了一个多视图链接预测层。
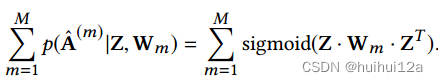
Reconstruction loss
对于多视图图自编码器,将每个图视图数据的重构误差之和最小化:
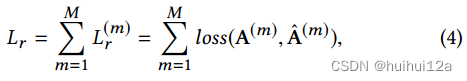
由于解码器的多视图结构,在反向传播过程中,多解码器的梯度会通过信息图编码器传播(会更新信息图编码器的参数,使它能产生更利于重构出更好的多视图嵌入)。因此,在处理前向传播时,图编码器将提取所有视图的共享表示。这个模型也可以看作是多任务学习。多视图图解码器为信息图编码器提取共享表示提供了多任务监督信号,使共享表示更加全面和一般化。
2.3 Self-training Clustering
前面提到的One2Multi图卷积自编码器可以将属性多视图图编码成紧凑的表示形式。然而,嵌入空间中的节点接近性是为了保留原始多视图图数据的局部结构,这可能不能保证适合聚类。对于聚类来说,良好的数据分布是同一聚类内的节点密集聚集,不同聚类之间的边界明显。因此,有必要引入其他目标来指导嵌入学习过程。采用自训练聚类目标,利用”high confident“节点作为软标签来监督图聚类过程。
除了重构损失外,将隐藏的嵌入输入到一个自我训练聚类目标中,该目标最小化以下目标:
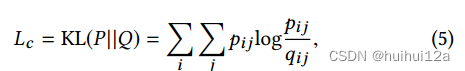
其中Q是软标签的分布,qij采用Student 's t-分布来度量,表示节点i的嵌入zi与聚类中心µj之间的相似度:
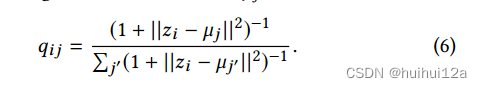
qij可以看作是每个节点的软聚类分配分布。pij是目标分布:
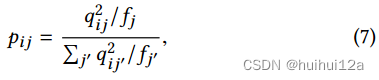
其中,是对每个质心的损失贡献进行归一化的软聚类频率,以防止大型聚类扭曲隐藏特征空间。目标分布P将Q提高到二次幂以得到更密集的分布。通过最小化Q和P之间的KL散度,可以使Q的分布更加密集。观察到“high confident”的节点在KL散度最小化开始时对梯度的贡献更大。“high confident”的节点表示节点有很高的概率属于某个由Eq. 6计算的集群。这种现象可以解释为半监督训练。
Overall objective function
共同优化了One2Multi图自编码器嵌入和聚类学习,总目标函数定义为:
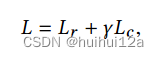
2.4 Optimization
首先预训练没有自训练聚类部分的One2Multi图自编码器,以获得一个训练良好的嵌入Z。然后进行自训练聚类目标来改进这种嵌入。为了初始化聚类中心,对嵌入节点Z执行标准k-means聚类,以获得k个初始质心{µj}。具体来说,需要更新的参数有三种:One2Multi图自编码器的权值W (l)和W1、···、WM、聚类中心µ和目标分布P.
(1)聚类中心的更新

(2)解码器参数的更新
可以看到,Wm的更新只与视图m的重构损失有关,因此,视图特定解码器的权重可以捕获视图特定的局部结构信息
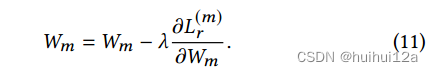
(3)编码器参数的更新
W (l)的更新与所有视图的重构损失相关,使得编码器的权重可以提取所有视图的共享表示。
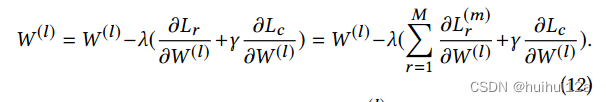
(4)更新目标分布
目标分布P依赖于预测的软标签。为了避免自训练过程中的不稳定性,每T次迭代应使用所有嵌入节点更新P。根据Eq. 6和Eq. 7更新P,在更新目标发行版时,分配给vi的标签由:
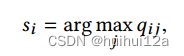
qij由式6计算。如果目标分布的两次连续更新之间的标签分配变化(以百分比表示)小于阈值δ,则训练过程将停止。我们可以从最后一个优化后的Q得到聚类结果。