- 压缩感知系列博客:
- 压缩感知入门①从零开始压缩感知
- 压缩感知入门②信号的稀疏表示和约束等距性
- 压缩感知入门③基于ADMM的全变分正则化的压缩感知重构算法
文章目录
- 1. Problem
- 2. 仿真结果
- 3. MATLAB算法
- 4. 源码地址
- 参考文献
1. Problem
信号压缩是是目前信息处理领域非常成熟的技术,其主要原理是利用信号的稀疏性。一个稀疏信号的特征是,信号中有且仅有少量的位置是有值的,其它位置都是零。对于一个稀疏的信号,在存储时只需要记录有值的位置,从而实现对原始信号的压缩。
对于原本不稀疏的信号,可以利用一种字典(正交变换基,例如傅里叶、小波)对信号进行线性表示,得到原始信号在这个稀疏域上的稀疏表示系数,只需要记录这些少量的系数就能够实现对信号的压缩存储。
在信号重建时,首先对信号补零得到原始维度的信号,由于采用的变换字典是正交的,可以通过正交的变换得到原始信号。
压缩感知与传统的信号压缩有着异曲同工之妙,而不同之处在于,压缩感知的信号压缩过程是将原始的模拟信号直接进行压缩(采样即压缩)。而传统信号压缩通常是先将信号采样后再进行压缩(采样后压缩),这种压缩方式的主要问题在于采用较高的采样资源将信号采集后,又在信号压缩过程将费尽心思采集到的信号丢弃了,从而造成资源的浪费1。
以经典的图像采集为例,对于一副 m × n m\times n m×n的图像信号 I I I进行采集,根据正交变换的思想,至少要对其进行 N = m × n N=m\times n N=m×n次采样才能够得到这副图像。
若该图像是稀疏的,根据压缩感知理论,可以至少进行 M M M次采样就能够采集到该信号,其中 M < < N M<<N M<<N, M M M的值有信号的稀疏性决定。
一个压缩感知采样过程可以表示为
A x = b + e (1) Ax=b+e\tag{1} Ax=b+e(1)
其中, A ∈ R M × N A\in \mathbb R^{M\times N} A∈RM×N表示观测矩阵, x ∈ R N × 1 x\in \mathbb R^{N\times 1} x∈RN×1表示 I ∈ R m × n I\in \mathbb R^{m\times n} I∈Rm×n的向量形式, b ∈ R M × 1 b\in \mathbb R^{M\times 1} b∈RM×1表示测量向量, e ∈ R M × 1 e\in \mathbb R^{M\times 1} e∈RM×1表示测量噪声。可以看到,一个 N N N维的信号在采样过程中被压缩成 M M M维的信号,这里的 M < N M<N M<N。
信号重构过程可以表示为一个优化问题,利用信号的梯度稀疏性质,可以构建目标函数:
min x ∣ ∣ D x ∣ ∣ 1 s . t . A x = b + e (2) \min_x\ ||Dx||_1\ s.t. \ Ax=b+e\tag{2} xmin ∣∣Dx∣∣1 s.t. Ax=b+e(2)
其中, x x x为待求解信号, D D D为全变分算子2。去除约束有
min x λ ∣ ∣ D x ∣ ∣ 1 + 1 2 ∣ ∣ A x − b ∣ ∣ 2 2 (3) \min_x \ \lambda||Dx||_1+\frac12 ||Ax-b||^2_2\tag{3} xmin λ∣∣Dx∣∣1+21∣∣Ax−b∣∣22(3)
该问题是一个非凸、不光滑问题,无法直接采用梯度下降法求解。引入变量 d d d,将问题(3)转化为ADMM的一般形式3
min x 1 2 ∣ ∣ A x − b ∣ ∣ 2 2 + λ ∣ ∣ d ∣ ∣ 1 s . t . D x − d = 0 (4) \min_x \frac12 ||Ax-b||^2_2+\lambda||d||_1 \ \ s.t.\ \ Dx-d=0\tag{4} xmin21∣∣Ax−b∣∣22+λ∣∣d∣∣1 s.t. Dx−d=0(4)
利用增广拉格朗日法引入凸松弛,同时去除约束条件,有
L ( x , d , μ ) = 1 2 ∣ ∣ A x − b ∣ ∣ 2 2 + λ ∣ ∣ d ∣ ∣ 1 + μ T ( D x − d ) + δ 2 ∣ ∣ D x − d ∣ ∣ 2 2 (5) L(x,d,\mu)=\frac12 ||Ax-b||^2_2+\lambda||d||_1+\mu^T(Dx-d)+\frac \delta 2||Dx-d||^2_2\tag{5} L(x,d,μ)=21∣∣Ax−b∣∣22+λ∣∣d∣∣1+μT(Dx−d)+2δ∣∣Dx−d∣∣22(5)
其中 μ \mu μ为拉格朗日乘子, δ > 0 \delta>0 δ>0为拉格朗日惩罚项。为了使表达更简洁,可做如下替换:
L ( x , d , μ ) = 1 2 ∣ ∣ A x − b ∣ ∣ 2 2 + λ ∣ ∣ d ∣ ∣ 1 + δ 2 ∣ ∣ D x − d + p ∣ ∣ 2 2 − δ 2 ∣ ∣ p ∣ ∣ 2 2 (6) L(x,d,\mu)=\frac12 ||Ax-b||^2_2+\lambda||d||_1+\frac \delta 2||Dx-d+p||^2_2-\frac \delta 2||p||_2^2\tag{6} L(x,d,μ)=21∣∣Ax−b∣∣22+λ∣∣d∣∣1+2δ∣∣Dx−d+p∣∣22−2δ∣∣p∣∣22(6)
其中 p = μ / δ p=\mu / \delta p=μ/δ。利用ADMM,问题(6)的求解可通过交替求解以下三个问题进行实现:
x n + 1 = a r g min x 1 2 ∣ ∣ A x − b ∣ ∣ 2 2 + δ 2 ∣ ∣ D x − d n + p n ∣ ∣ 2 2 (7) x_{n+1}=arg\,\min_x\ \frac12 ||Ax-b||^2_2+\frac \delta 2||Dx-d_n+p_n||^2_2\tag{7} xn+1=argxmin 21∣∣Ax−b∣∣22+2δ∣∣Dx−dn+pn∣∣22(7)
d n + 1 = a r g min u λ ∣ ∣ d ∣ ∣ 1 + δ 2 ∣ ∣ D x n − d + p n ∣ ∣ 2 2 (8) d_{n+1}=arg\,\min_u\ \lambda||d||_1+\frac \delta 2||Dx_n-d+p_n||^2_2\tag{8} dn+1=argumin λ∣∣d∣∣1+2δ∣∣Dxn−d+pn∣∣22(8)
p n + 1 = p n + ( D x n + 1 − d n + 1 ) (9) p_{n+1}=p_n+(Dx_{n+1}-d_{n+1})\tag{9} pn+1=pn+(Dxn+1−dn+1)(9)
2. 仿真结果
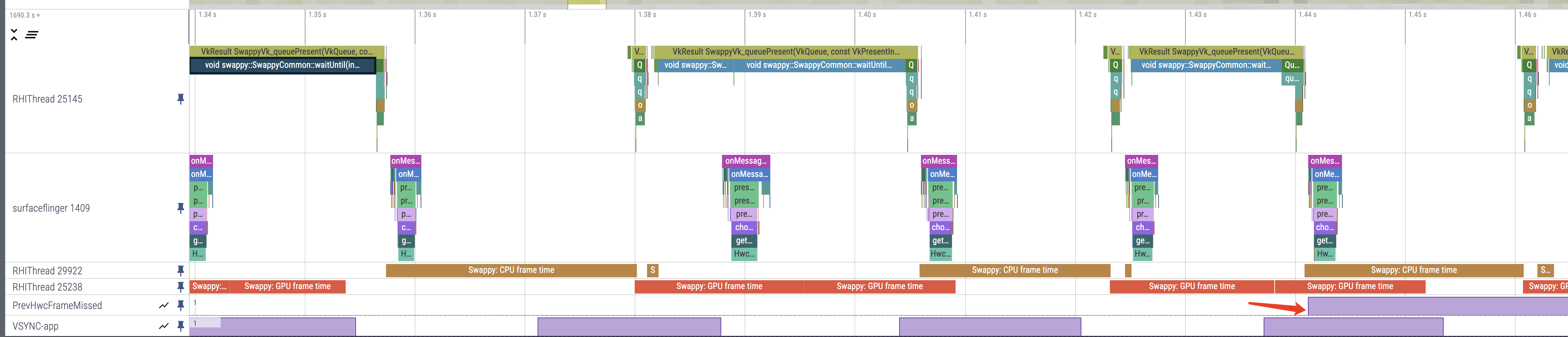
测试图像采用的是house,分别测试在20%、40%、60%、80%和100%采样率时,压缩感知重构算法的图像恢复结果。

从仿真结果可以看到,在20%采样率时,信号的基本轮廓信息就被成功采集了,当采样率达到60%以上时,继续增加采样率并没有使得图像更加的清晰,也就是说,针对这副图像,若采用传统的正交采集的方式,有将近一半的采样资源是被浪费的。
3. MATLAB算法
ratio=0.5;%采样率
x=double(imread('house.bmp'));
[m,n]=size(x);
N=m*n;
M=floor(ratio*N);
A=rand(M,N);%观测矩阵
e=50*randn(M,1);%测量噪声
% 信号采集过程,利用线性投影对信号x进行采集,同时考虑了测量噪声
b=A*reshape(x,N,1)+e;
% 信号重构过程,利用仅有的M个测量值恢复维度为N的信号
x_r=ADMM_TV_reconstruct(A,b,300,500,100);
figure;
subplot(121);
imshow(uint8(x));
title('原始图像');
subplot(122);
imshow(uint8(reshape(x_r,m,n)));
title(sprintf('重构图像(%d%%采样率)',ratio*100));
function xp=ADMM_TV_reconstruct(A,b,delta,lambda,iteratMax)
[~,N]=size(A);
[Dh,Dv]=TVOperatorGen(sqrt(N));
D=sparse([(Dh)',(Dv)']');
d=D*ones(N,1);
p=ones(2*N,1)/delta;
invDD=inv(A'*A+delta*(D'*D));
for ii=1:iteratMax
x=invDD*(A'*b+delta*D'*(d-p));
d=wthresh(D*x+p,'s',lambda/delta);
p=p+D*x-d;
end
xp=x;
end
function [Dh,Dv]=TVOperatorGen(n)
Dh=-eye(n^2)+diag(ones(1,n^2-1),1);
Dh(n:n:n^2,:)=0;
Dv=-eye(n^2)+diag(ones(1,n^2-n),n);
Dv(n*(n-1)+1:n^2,:)=0;
end
4. 源码地址
https://github.com/dwgan/ADMM_TV_reconstruct
参考文献
Baraniuk, Richard G. “Compressive sensing [lecture notes].” IEEE signal processing magazine 24.4 (2007): 118-121. ↩︎
Rudin, Leonid I., Stanley Osher, and Emad Fatemi. “Nonlinear total variation based noise removal algorithms.” Physica D: nonlinear phenomena 60.1-4 (1992): 259-268. ↩︎
Boyd, Stephen, et al. “Distributed optimization and statistical learning via the alternating direction method of multipliers.” Foundations and Trends® in Machine learning 3.1 (2011): 1-122. ↩︎