文章目录
- 1.左值引用和右值引用
- 左值引用
- 右值引用
- 2.左值引用和右值引用的比较
- 左值引用总结
- 右值引用总结
- 3.右值引用的使用场景和意义
- 知识点1
- 知识点2
- 知识点3
- 知识点4
- 总结
- 4.完美转发
- 万能引用
- 见识完美转发的使用
- 完美转发的使用场景
1.左值引用和右值引用
传统的C++语法中就有引用的语法,而C++11中新增了右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
左值引用
- 左值是一个表示数据的表达式(如变量名或解引用的指针);
- 我们可以获取它的地址;
- 我们可以对它赋值;
- 左值可以出现在赋值符号的左边,也可以出现在赋值符号的右边;
- 定义const修饰符后的左值,不能给它赋值,但是可以取它的地址;
- 左值引用就是给左值引用,即给左值取别名。
使用方法:
#include<iostream>
#include<vector>
using namespace std;
int main()
{
//以下的p,b,c,*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
//以下几个是对上面左值的引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;
return 0;
}
右值引用
- 右值也是一个表示数据的表达式(如字面常量,表达式返回值,函数返回值等等);
- 右值引用可以出现在赋值符号的右边,但是不能出现在赋值符号的左边。
- 右值不能取地址。
- 右值就是对右值的引用,给右值取别名。
int main()
{
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}
一定要注意:右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址,也就是说,我们本来不能取字面量10的地址,但是rr1引用后,导致我们可以对rr1取地址了,也可以修改rr1,这个时候rr1就变成左值了。如果不想rr1被修改,可以用const int&& rr1去引用,为什么用const修饰之后就可以了呢?因为——x+y这个表达式的返回值是临时变量,临时变量具有常性,所以用const修饰之后就不会报错了。
int main()
{
double x = 1.1, y = 2.2;
x + y;
10;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
//rr2 = 5.5; //报错
return 0;
}
2.左值引用和右值引用的比较
注意两点:
- 能不能取地址是区分左值引用和右值引用的主要区别。
- 不能认为有分配空间的就是左值引用,没有被分配空间的就是右值引用。因为在上述的例子中,x+y表达式是右值,但是实际上它是占用空间的,表达式的返回值存储在临时变量中。
左值引用总结
- 左值引用只能引用左值,不能引用右值
- 但是const修饰的左值引用可以给右值取别名,也可以引用左值
int main()
{
//左值
int a = 10;
//左值引用可以引用左值
int& ra1 = a;
//左值引用不能引用右值
int& ra2 = 10;//编译失败,因为10常量是右值
//const修饰的左值引用可以引用左值,也可以引用右值
const int& ra3 = a;
const int& ra4 = 10;
return 0;
}
右值引用总结
- 右值引用只能给右值取别名,不能引用左值
- 但是右值引用可以给move后的左值取别名
int main()
{
int a = 0;
int b = 1;
int* p = &a;
a + b;
//右值引用可以给右值取别名
int&& raf1 = 10;
int&& raf2 = a + b;
//右值引用可以给move后的左值取别名
int&& raf3 = a;//报错:无法将右值引用绑定到左值
int&& raf3 = std::move(a);
}
3.右值引用的使用场景和意义
出现右值的原因之一:可以把左值和右值区分开。
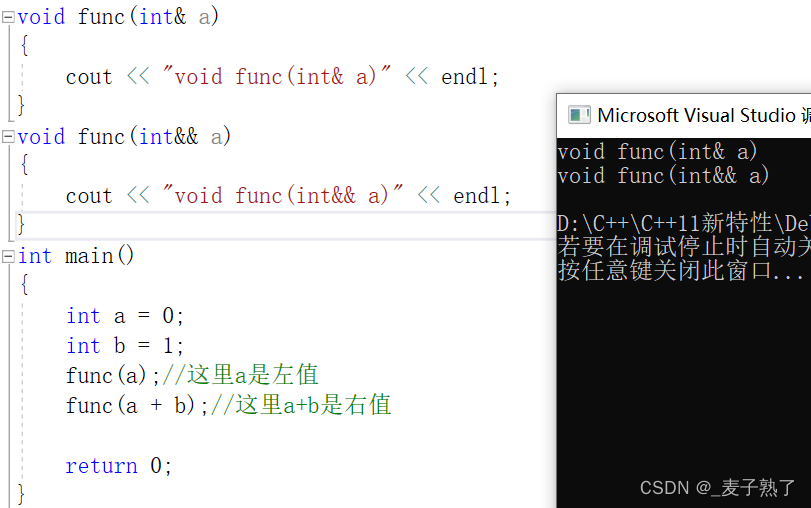
我们来看以下代码,函数名都为func,但是参数不同,一个是左值引用,一个是右值引用,我们来看看能否运行成功,将左值和右值区分开。
#include<iostream>
#include<vector>
using namespace std;
void func(int& a)
{
cout << "void func(int& a)" << endl;
}
void func(int&& a)
{
cout << "void func(int&& a)" << endl;
}
int main()
{
int a = 0;
int b = 1;
func(a);//这里a是左值
func(a + b);//这里a+b是右值
return 0;
}
运行结果:OK,编译通过,运行正确。所以虽然函数名相同,但是由于参数不同,调用的函数也不同。
最重要的是我们把左值和右值区分出来了。
前面我们可以看到左值引用既可以引用左值和又可以引用右值,那为什么C++11还要提出右值引用呢?是不是化蛇添足呢?下面我们来看看左值引用的短板,右值引用是如何补齐这个短板的!
左值引用存在的短板:
之前我们学习过 左值引用可以直接减少拷贝。
- 左值引用传参;
- 传引用返回。
但是如果函数内是局部对象,局部对象出了函数作用域那块空间就销毁了,这种情况下是不能用引用返回的。 对引用还不太理解的宝子可以先看这篇文章:【C++】引用&详细解析
右值引用如何解决左值引用存在的短板?
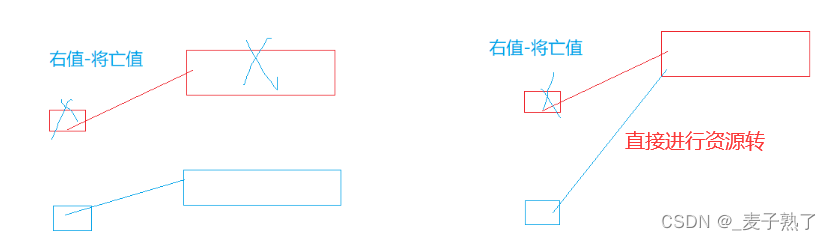
对于右值,有些书上又将其分为纯右值和将亡值。纯右值一般是内置类型,将亡值一般是自定义类型。如果右值将亡了,还对它进行深拷贝代价是有点高的,所以对于右值(将亡值),我们采用的是资源转移,即不重新开辟空间。上图!
接下来,我们来看几个例子,这样能更加理解左值引用和右值引用。
知识点1
例一:这里采用的是自定义string类。便于调试观察每个步骤调用的是什么函数。

知识点2
例二:下面是一个可以将整型转换成字符串的函数——注意是传值返回。同样用的是自定义的string类,这样调试时便于观察每个步骤调用的是哪个函数。
namespace nan
{
nan::string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
nan::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}
}
int main()
{
// 在nan::string to_string(int value)函数中可以看到,这里
// 只能使用传值返回,传值返回会导致至少1次拷贝构造(如果是一些旧一点的编译器可能是两次拷
//贝构造)。
nan::string ret1 = nan::to_string(1234);
return 0;
}
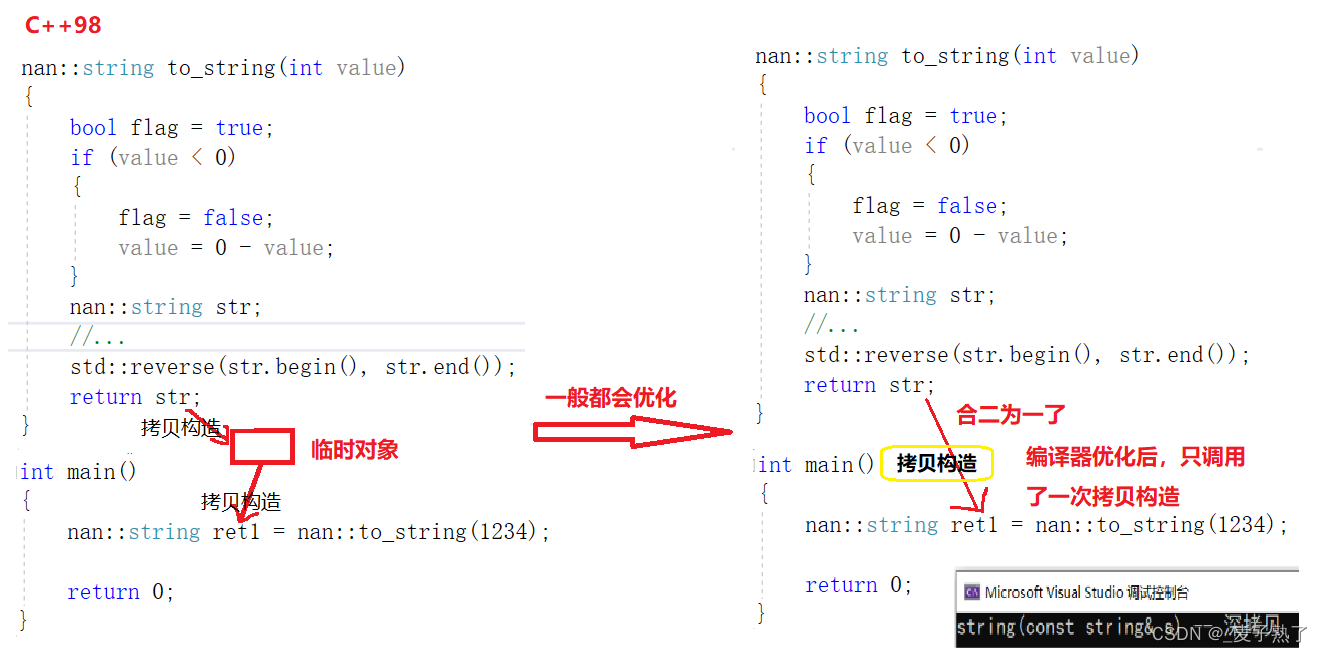
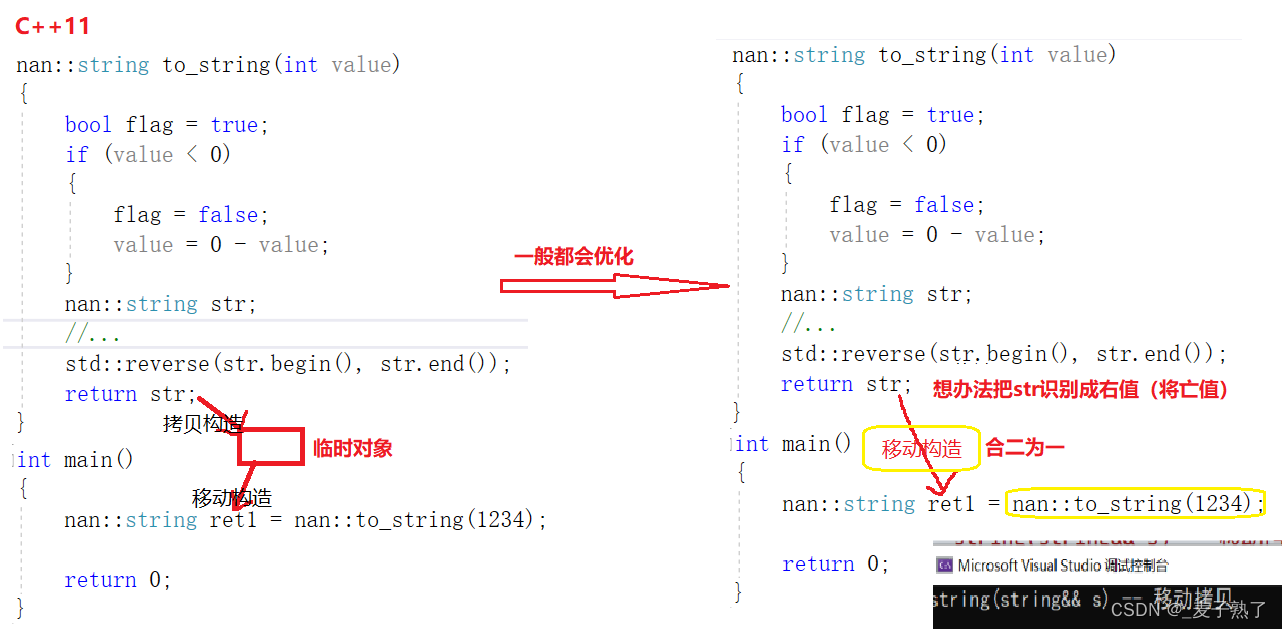
解释例2:返回时,由于编译器做了优化,将返回值(左值)通过某种方式转变成了右值(将亡值),所以直接采用了移动构造,即先调用了移动构造函数,然后才调用了析构函数。、
知识点3
move是库里面的函数,如果右值想引用左值,用上move函数即可。但是move函数不能随便乱用哦,大家看下面这个代码,先构造了s1,然后用s1拷贝构造s2,s1是左值,第3句代码想将s1通过move函数转换成右值,进行移动构造。
但是从运行结果我们发现,s1的家竟被s3偷了,所以一定要辨别使用场景,不能乱用move函数。
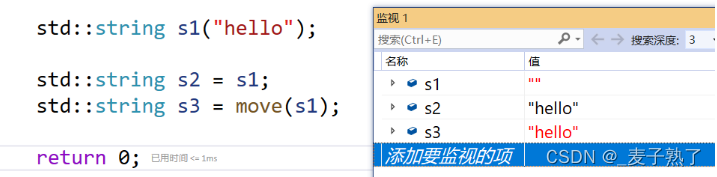
注意:move函数不是将s1转换成右值,而是move函数的返回值是右值。
这样写就不会被偷家了:
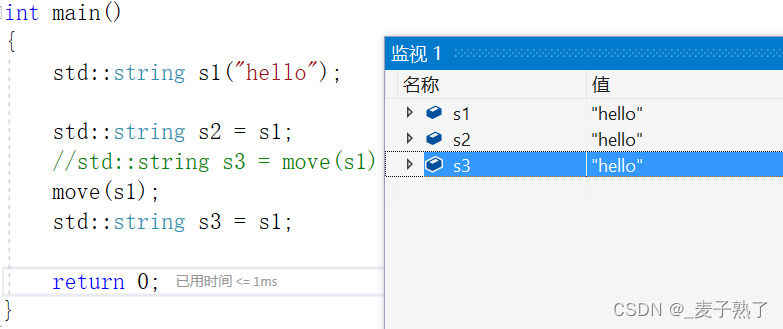
知识点4
C++11以后,STL所有的容器都增加了移动构造:

并且STL所有的容器的插入数据接口都增加了右值引用版本。
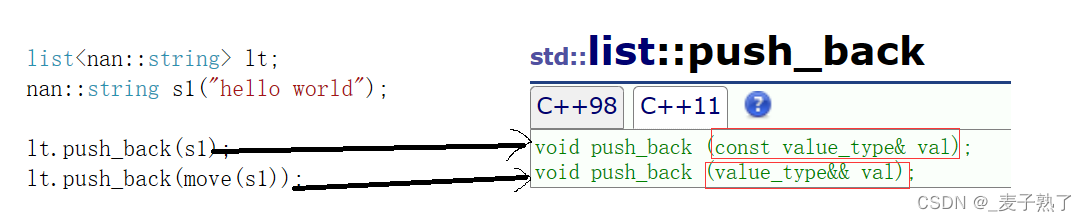
那么有什么意义呢?
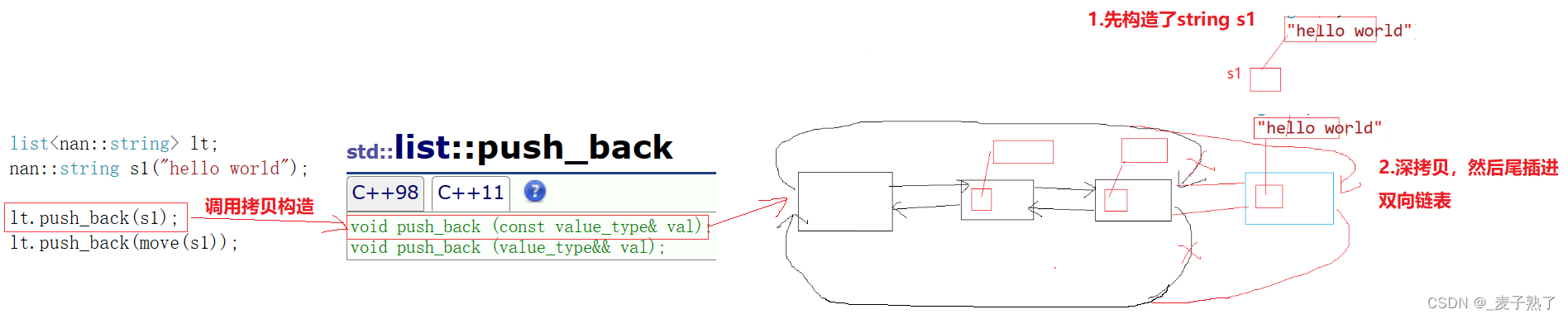
第一种尾插方式采用的是拷贝构造函数——深拷贝,所以会再拷贝出一份s1,然后插入链表中,通过下面的调试窗口,可以看出原来的字符串s1还存在。
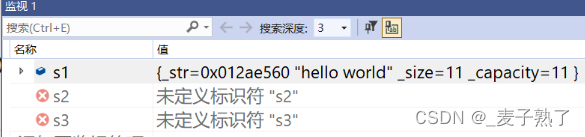

第二种尾插方式采用的是移动构造——浅拷贝,直接转移资源,将前面深拷贝构造出来的s1直接拿来尾插,不需要再深拷贝构造一个s1,又大大提高了效率。但是,通过调试窗口发现,s1被偷家了,悬空了!所以要注意一下这点。
总结
问题:匿名对象属于左值还是右值?——答案:匿名对象是右值。
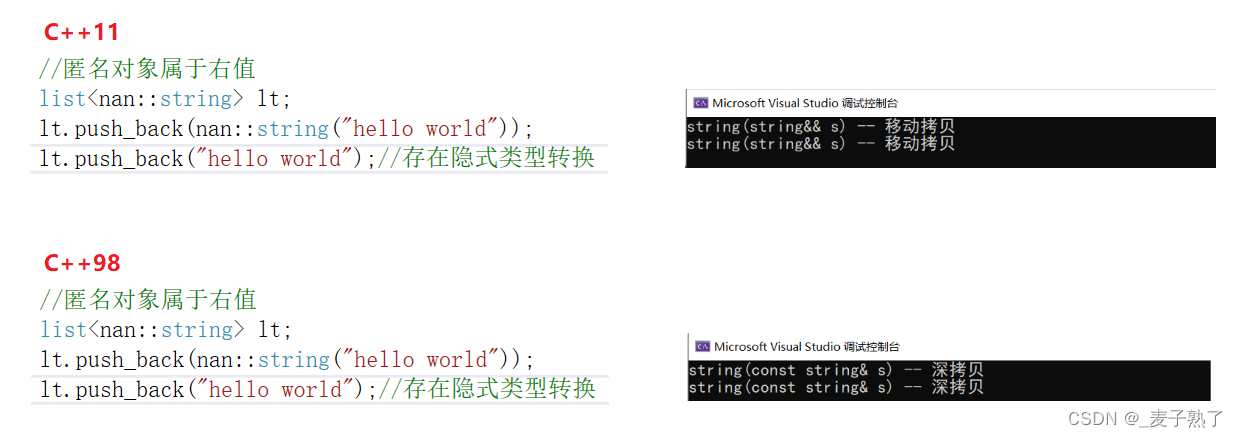
总结:
- C++98,只有拷贝构造;C++11之后,既有拷贝构造,也有移动构造;
- 左值引用减少拷贝,提高效率,右值引用也是减少拷贝,提高效率,但是它们的角度不同,左值引用是直接减少拷贝,右值引用是间接减少拷贝,编译器先识别数据是左值还是右值,如果是右值,则不再深拷贝,直接移动拷贝(直接移动资源),提高效率。
4.完美转发
万能引用
模板中的&& , 不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
栗子如下:
template<class T>
void PerfectForward(T&& t)
{
//...
}
然后我们现在通过下列代码,观察一个现象:
下面重载了四个Func函数,这四个Func函数的参数类型分别是左值引用、const左值引用、右值引用和const右值引用。在主函数中调用PerfectForward函数时分别传入左值、右值、const左值和const右值,在PerfectForward函数中再调用Func函数。如下:
#include<iostream>
using namespace std;
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
// 万能引用(引用折叠):既可以引用左值,也可以引用右值
template<typename T>
void PerfectForward(T&& t)
{
Fun(t);
}
int main()
{
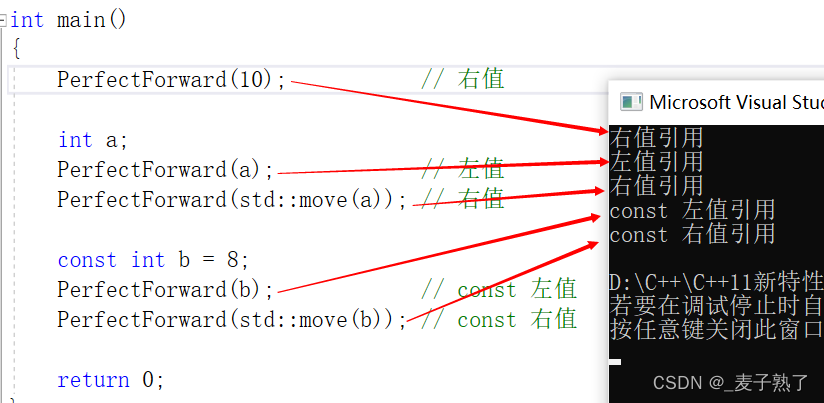
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
运行结果:

由于PerfectForward函数的参数类型是万能引用,因此既可以接收左值也可以接收右值,而我们在PerfectForward函数中调用Func函数,就是希望调用PerfectForward函数时传入左值、右值、const左值、const右值,能够匹配到对应版本的Func函数。但实际调用PerfectForward函数时传入左值和右值,最终都匹配到了左值引用版本的Func函数,调用PerfectForward函数时传入const左值和const右值,最终都匹配到了const左值引用版本的Func函数。

造成这种结果的原因:
根本原因就是:右值被引用后会导致右值被存储到特定位置,这时这个右值可以被取到地址,并且可以被修改,所以在PerfectForward函数中调用Func函数时会将t识别成左值。因为右值默认具有常性,右值引用后属性是左值,这样才能实现资源转移。

也就是说,右值经过一次参数传递后其属性会退化成左值,如果想要在这个过程中保持右值的属性,就需要用到完美转发。
见识完美转发的使用
保持原有属性的关键:要想在参数传递过程中保持其原有的属性,需要在传参时调用std::forward函数。
#include<iostream>
using namespace std;
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
// 万能引用(引用折叠):既可以引用左值,也可以引用右值
template<typename T>
void PerfectForward(T&& t)
{
// std::forward<T>(t)在传参的过程中保持了t的原生类型属性。
Fun(forward<T>(t));
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
运行结果:
完美转发的使用场景
下面模拟实现了一个简化版的list类,类当中分别提供了左值引用版本和右值引用版本的push_back和insert函数。
namespace zxn
{
template<class T>
struct ListNode
{
T _data;
ListNode* _next = nullptr;
ListNode* _prev = nullptr;
};
template<class T>
class list
{
typedef ListNode<T> node;
public:
//构造函数
list()
{
_head = new node;
_head->_next = _head;
_head->_prev = _head;
}
//左值引用版本的push_back
void push_back(const T& x)
{
insert(_head, x);
}
//右值引用版本的push_back
void push_back(T&& x)
{
insert(_head, std::forward<T>(x)); //完美转发
}
//左值引用版本的insert
void insert(node* pos, const T& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = x;
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
//右值引用版本的insert
void insert(node* pos, T&& x)
{
node* prev = pos->_prev;
node* newnode = new node;
newnode->_data = std::forward<T>(x); //完美转发
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = pos;
pos->_prev = newnode;
}
private:
node* _head; //指向链表头结点的指针
};
}
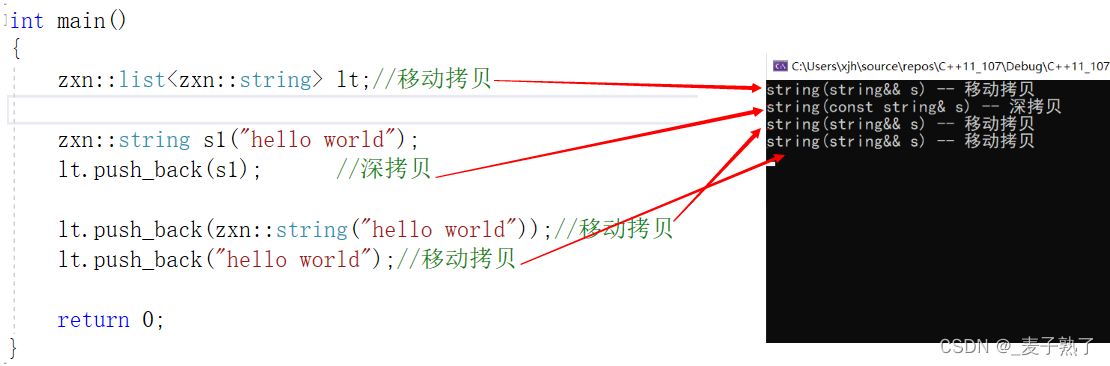
如果我们没有使用std::forward完美转发,会导致运行结果全是拷贝构造函数,即深拷贝。