在用户眼里,业务需要永远正常对外提供服务,这就要求应用系统的高可用(High availability,即 HA)。高可用主要是针对架构而言,第一步一般会采用分层的思想将一个庞大的应用系统拆分成应用层、中间件、数据存储层等独立的层,每一层再拆分成更细粒度的组件;第二步就是让每个组件对外提供服务,毕竟每个组件都不是孤立存在的,都需要互相协作,对外提供服务才有意义;第三步就是保证架构中所有组件以及对外暴露服务都要做到高可用,任何一个组件或其服务没做高可用,都意味着系统存在风险。
1、高可用设计
何组件要做高可用,都离不开「冗余」和「自动故障转移」,众所周知单点是高可用的大敌,所以组件一般是以集群(至少两台机器)的形式存在的,这样只要某台机器出现问题,集群中的其他机器就可以随时顶替,这就是「冗余」。简单计算一下,假设一台机器的可用性为 90%,则两台机器组成的集群可用性为 1-0.1*0.1 = 99%,所以显然冗余的机器越多,可用性越高。
但光有冗余还不够,如果机器出现问题,需要人工切换的话也是费时费力,而且容易出错,所以我们还需要借助第三方工具(即仲裁者)的力量来实现「自动」的故障转移,以达到实现近实时的故障转移的目的,近实时的故障转移才是高可用的主要意义。
在业界一般用几个九来衡量系统的可用性,如下
| 可用级别 | 系统可用性% | 宕机时间/年 |
|---|---|---|
| 不可用 | 90% | 36.5天 |
| 基本可用 | 99% | 87.6小时 |
| 较高可用 | 99.9% | 8.76小时 |
| 高可用 | 99.99% | 52.56分钟 |
| 极高可用 | 99.999% | 5.26分钟 |
互联网采用的微服务架构示意如下(简单架构):
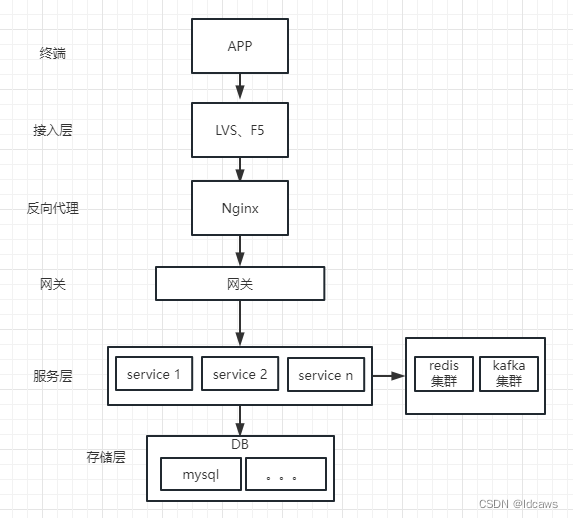
可见架构主要分为以下几层:
- 接入层:主要由 F5 硬件或 LVS 软件来承载所有的流量入口;
- 反向代理层:Nginx,主要负责根据 url 来分发流量,限流等;
- 网关:主要负责流控,风控,协议转换等;
- 服务层:主要业务服务;
- 存储层:也就是 DB,如 MySQL,Oracle 等,一般由服务层调用返回;
- 中间件:ZK,Redis,Kafka 等,主要起到加速访问数据等功能;
1.1、服务层
服务层采用的是微服务架构,微服务架构体系自带高可用机制,此处不再展开。
1.2、中间件
Redis
Redis 的高可用需要根据它的部署模式来看看,主要分为「主从模式」、「哨兵模式」和「集群模式」,具体参考《Redis之高可用方案浅析》。
Kafka
Kafka集群示意图如下
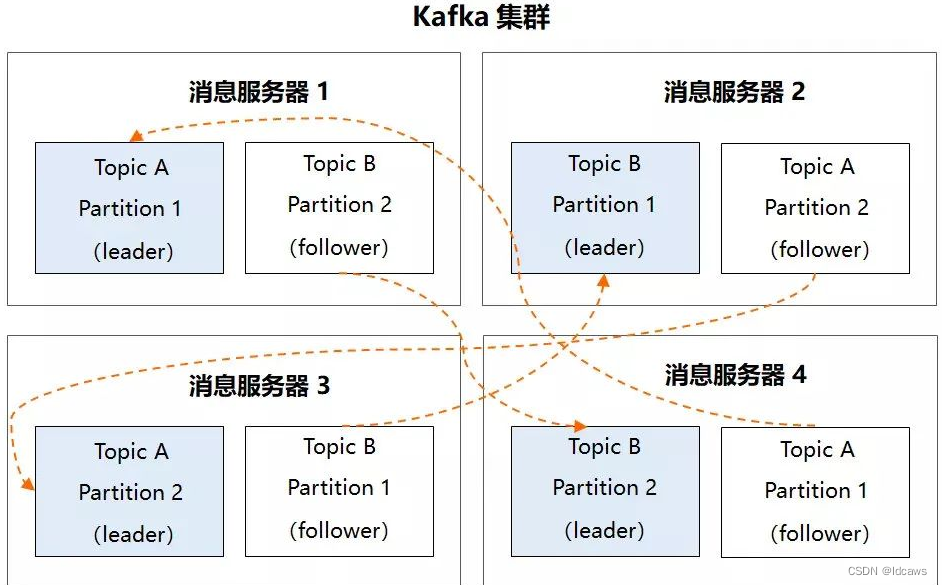
可以看到每个 Topic 的 Partition 都分布式存储在其它消息服务器上,这样一旦某个 Partition 不可用,可以从 follower 中选举出 leader 继续服务,不过与 ES 中的数据分片不同的是,follower Partition 属于冷备,也就是说在正常情况下不会对外服务,只有在 leader 挂掉之后从 follower 中选举出 leader 后它才能对外提供服务。
2、双机热备设计
从广义上讲,就是对于重要的服务,使用两台服务器,互相备份,共同执行同一服务。当一台服务器出现故障时,可以由另一台服务器承担服务任务,从而在不需要人工干预的情况下,自动保证系统能持续提供服务。
从狭义上讲,双机热备就是使用互为备份的两台服务器共同执行同一服务,其中一台主机为工作机(Primary Server),另一台主机为备份主机(Standby Server)。在系统正常情况下,工作机为应用系统提供服务,备份机监视工作机的运行情况(一般是通过心跳诊断,工作机同时也在检测备份机是否正常),当工作机出现异常,不能支持应用系统运营时,备份机主动接管工作机的工作,继续支持关键应用服务,保证系统不间断的运行。双机热备针对的是IT核心服务器、存储、网络路由交换的故障的高可用性解决方案。
双机热备的种类,主从模式是最标准、最简单的双机热备,即通常所说的active/standby方式;双机互备,在双机热备的基础上,两个相对独立的应用在两台机器同时运行,但彼此均设为备机,当某一台服务器出现故障时,另一台服务器可以在短时间内将故障服务器的应用接管过来,从而保证了应用的持续性。多点集群可以理解为双机热备在技术上的提升。多机服务器可以组成一个集群,根据应用的实际情况,可以灵活地在这些服务器上进行部署,同时可以灵活地设置接管策略。
Keepalived 起初是专门针对 LVS 设计的一款强大的辅助工具,主要用来提供故障切换(Failover)和健康检查(Health Checking)功能;在非 LVS 群集环境中使用时,Keepalived 也可以作为热备软件使用。
Keepalived 采用 VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)热备份协议,以软件的方式实现 Linux 服务器的多机热备功能。
根据上面互联网采用的微服务架构中的分层,下面聊聊那些组件应用双机热备方案。
2.1、接入层&反向代理层
可用通过引入Keepalived实现,类似如下
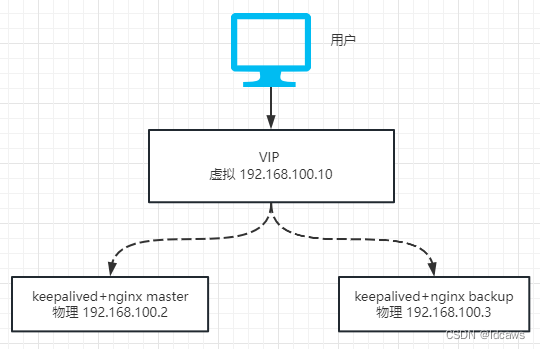
两个 nginx 以主备的形式对外提供服务,注意只有 master 在工作(即此时的 VIP 在 master 上生效),另外一个 backup 在 master 宕机之后会接管 master 的工作,那么 backup 怎么知道 master 是否正常呢,答案是通过 keepalived,在主备机器上都装上 keepalived 软件,启动后就会通过心跳检测彼此的健康状况,一旦 master 宕机,keepalived 会检测到,从而 backup 自动转成 master 对外提供服务,此时 VIP 地址即在 backup 上生效,也就是我们常说的「IP漂移」,通过这样的方式即解决了nginx的高可用。
具体参考《浅入浅出keepalived+nginx实现高可用双机热备》。
2.2、存储层
mysql的高可用设计也是引用Keepalived来实现高可用,类似如下
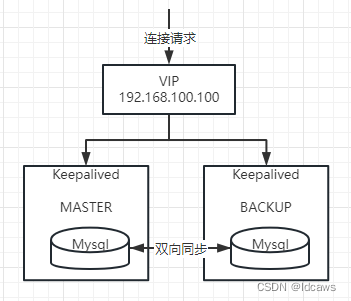
如果 master 宕机了,Keepalived 也会及时发现,于是从库会升级主库,并且 VIP 也会“漂移”到原从库上生效,所以说大家在工程配置的 MySQL 地址一般是 VIP 以保证高可用。数据量大了之后就要分库分表了,于是就有了多主,就像 Redis 的分片集群一样,需要针对每个‘主’配备多个‘从’,类似如下
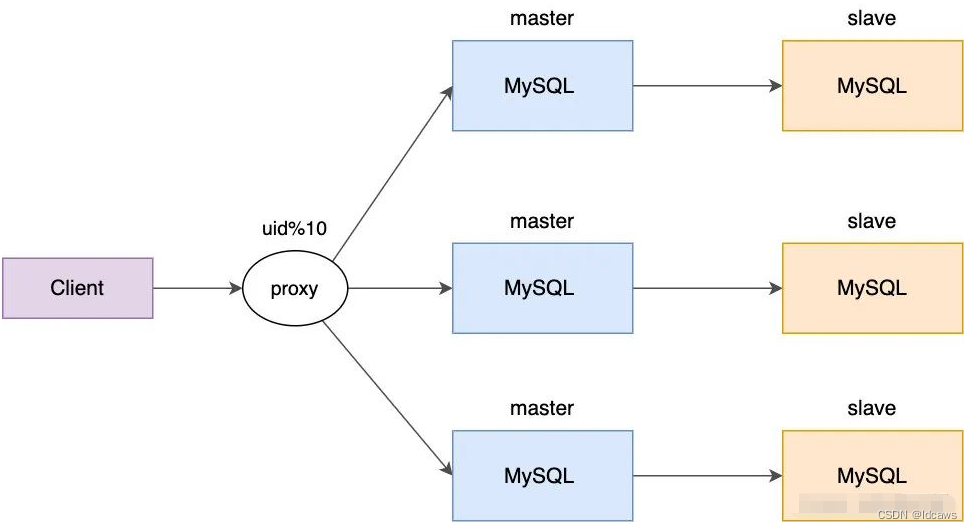
(摘自网上,感谢~)
具体参考《Mysql之高可用方案浅析》。
3、小结
看完了架构层面的高可用设计,相信大家对高可用的核心思想「冗余」和「自动故障转移」会有更深刻的体会,观察以上架构中的组件你会发现冗余的主要原因是因为只有一主,为什么不能有多主呢,也不是不可以,但这样在分布式系统下要保证数据的一致性是非常困难的,尤其是节点多了的话,数据之间的同步更是一大难题。
对每个组件进行高可用设计这也至少迈出了第一步,在生产上还会有很多突发情况,如流量洪峰,安全问题、代码问题、部署问题等等,所以还需要做好每个环节,提高系统的高可用性。



![[Nacos] Nacos Server之间的操作 (十一)](https://img-blog.csdnimg.cn/d0af0f04ff164505a57fdeb68245fc4f.png)