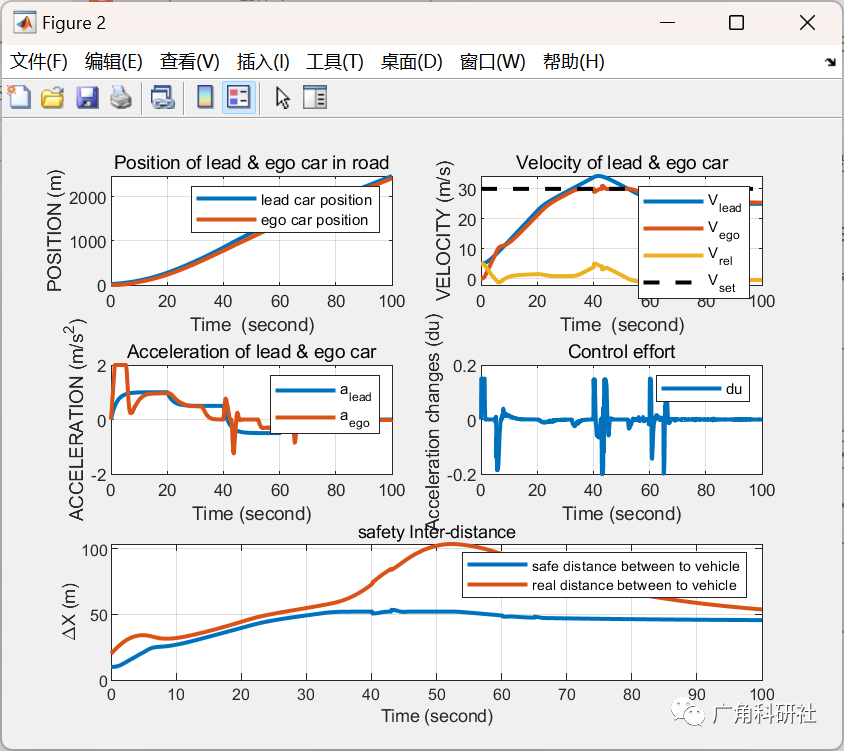
论文:GPRAR: Graph Convolutional Network based Pose Reconstruction and Action Recognition for Human Trajectory Prediction(2016)
摘要
高精度的预测对于自动驾驶等各种应用至关重要。现有的预测模型在现实世界中很容易出错,因为观察结果(例如人类的姿势和位置)通常是嘈杂的。为了解决这个问题,我们引入了GPRAR,一种基于图卷积网络的姿态重建和动作识别,用于人体轨迹预测。GPRAR 的关键思想是在嘈杂的场景下生成鲁棒特征:人类的姿势和动作。为此,我们使用两个新的子网络来设计 GPRAR: PRAR (姿态重建和动作识别)和 FA (特征聚合器)。PRAR 旨在从人体骨骼的连贯和结构特性中同时重建人体姿势和动作特征。它是由一个编码器和两个解码器组成的网络,每个解码器由多层时空图卷积网络组成。此外,我们提出了一个特征聚合器(FA),以通道方式聚合学习到的特征:人类姿势、动作、位置和相机运动,使用基于编码器-解码器的时间卷积神经网络来预测未来的位置。在常用数据集:JAAD 和TITAN 进行的大量实验表明,GPRAR 的精度比最先进的模型有所提高。具体而言,GPRAR 在 JAAD 和 TITAN 数据集的噪声观测下,预测精度分别提高了22%和50%。
GPRAR
网络结构
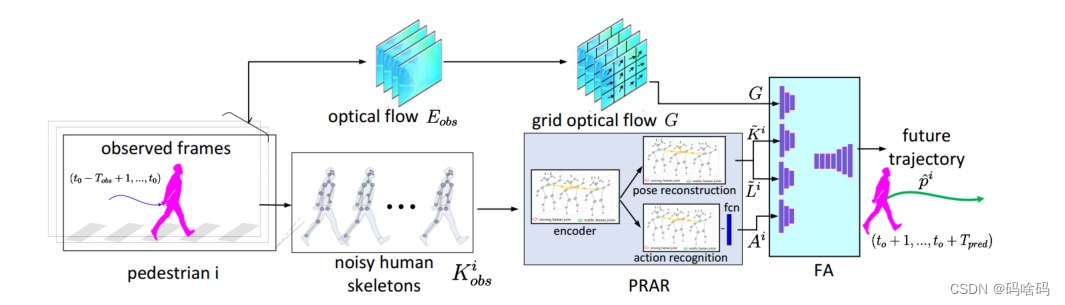
GPRAR 系统概述。我们的预测模型由两个子网络组成:PRAR 和 FA。PRAR 以目标行人
i
i
i 观察到的有噪声的人体骨骼序列
K
o
b
s
i
K^i_{obs}
Kobsi 作为输入,对有噪声的人体骨骼进行重构(去噪)并识别人体动作。在后期,FA将学习到的特征聚集在一起:网格光流
G
G
G、重建的人体骨骼
K
i
~
\tilde {K^i}
Ki~、位置
L
i
~
\tilde {L^i}
Li~ 和动作特征
A
i
A^i
Ai ,并预测行人
i
i
i 的未来轨迹。
- 人体姿态重建和动作识别网络(PRAR)
PRAR的基本思想是从噪声姿态检测中重构人体姿态并同时学习动作特征。为了最好地利用人类骨骼的相干性和结构特性,PRAR 由一个编码器和两个解码器实现,其中每个编码器和解码器是一个多层时空图卷积网络,操作在自然连接的人体关节(或姿势图)上。 - 我们提出了一个编码器-解码器(FA)
以通道方式聚合学习到的特征:使用时间卷积网络(TCNs)来重构姿势和位置,动作,和相机运动。然后使用聚合特征输出目标行人的未来轨迹。
本文的贡献
- 我们提出了一个在噪声观测下高效鲁棒的人类轨迹预测网络(GPRAR)(第3节)。GPRAR 由两个新的子网络组成:人类姿态重建和动作识别网络(PRAR)和基于编码器-解码器的特征聚合器(FA)。
- 我们在两个常用数据集上评估了我们的模型:TITAN 和 JAAD,并表明我们的方法在噪声情况下优于其他方法(第4节)。我们还进行了消融研究,以证明系统每个组成部分的有效性。
相关工作
- 动态场景中的轨迹预测
该研究最近的大部分工作依赖于递归神经网络(RNNs)、时间卷积网络(TCNs)或其变体等方法。大多数方法,它们依赖于真实的人类位置和姿势特征,而这些特征在现实世界中是不可用的。 - 图神经网络
STGCN 卷积运算从卷积神经网络(CNN)扩展到图
系统设计
任务是在给定过去的 T o b s T_{obs} Tobs 帧的情况下预测 N 个行人的未来位置。为简单起见,我们对目标行人 i ∈ N i∈N i∈N 的任务描述如下:
- 在每个时间(当前帧) t 0 t_0 t0,我们的模型接收从过去的 T o b s T_{obs} Tobs 帧中提取的噪声特征作为输入,并在接下来的 T p r e d T_{pred} Tpred 帧中产生行人 i i i 的未来轨迹。我们使用了两个序列的噪声输入特征:人类骨骼 K o b s i K^i_{obs} Kobsi 和光流 E o b s E_{obs} Eobs,这些 E o b s E_{obs} Eobs 是使用可用的公共检测器(例如,OpenPose 和FlowNet )获得的。
- PRAR 是一种新型的基于编码器-解码器的时空姿态图卷积网络,基于行人 i i i 观察到的有噪声(不完整)的人类骨骼序列 K o b s i K^i_{obs} Kobsi,对这些有噪声的人类骨骼进行重构(去噪)并识别人类行为。然后将重构的姿态 K i ~ \tilde{K^i} Ki~ 和动作特征 A i A^i Ai 作为特征聚合器(FA)的输入来预测未来的位置。此外,由于观察到的位置是表征人体整体运动的重要特征,我们从重构姿态 K i ~ \tilde{K^i} Ki~ 序列中提取重构位置序列 L i ~ \tilde{L^i} Li~,并在下一阶段将其转发给 FA。在另一个分支(图1)中,我们计算网格光流 G,将每个光流图像 e t ∈ E o b s e_t∈E_{obs} et∈Eobs 划分为 3*4 的网格,并对每个网格单元中所有像素的值取平均值。网格光流表示场景中不同区域的摄像机运动,因此比像素级光流提供更精确的摄像机运动。最后,Feature Aggregator (FA) 通过基于编码器-解码器的一维时间卷积网络,对所有学习到的特征 G 、 K i ~ 、 L i ~ 、 A i G、\tilde{K_i}、\tilde{ L^i}、A^i G、Ki~、Li~、Ai 进行聚合,预测行人 i i i 在接下来的 T p r e d T_{pred} Tpred 帧中的未来轨迹 p i ^ \hat{p^i} pi^。我们考虑行人之间的独立运动,因此,将上述相同的过程应用于相同观察时间内的 N 个行人,并通过批处理预测 N 个输出轨迹。
PRAR
PRAR 的目标是生成鲁棒的动作和姿态特征,以提高在极端情况下(例如,遮挡,快速相机运动等)和危及公共探测器敏感性的情况下的预测。为此,我们设计了由一个编码器和两个解码器组成的 PRAR,每个编码器由多层图神经网络(GNNs)组成,GNN 在观察到的人类骨骼序列上运行,如图2所示。在讨论细节之前,让我们重点介绍 PRAR 的以下技术创新:
- 虽然一些工作将 GNNs 用于人体骨骼的动作识别任务,但 GNNs 尚未用于姿态重建和人体轨迹预测任务。
- PRAR 是第一个用于多任务学习的基于编码器-解码器的 GNNs ,其中学习得到的鲁棒姿态特征对上述提及的两个任务都受益。
- PRAR 是一个即插即用模块,可以单独训练,但也可以与其他模型集成和联合训练,用于人类轨迹预测。
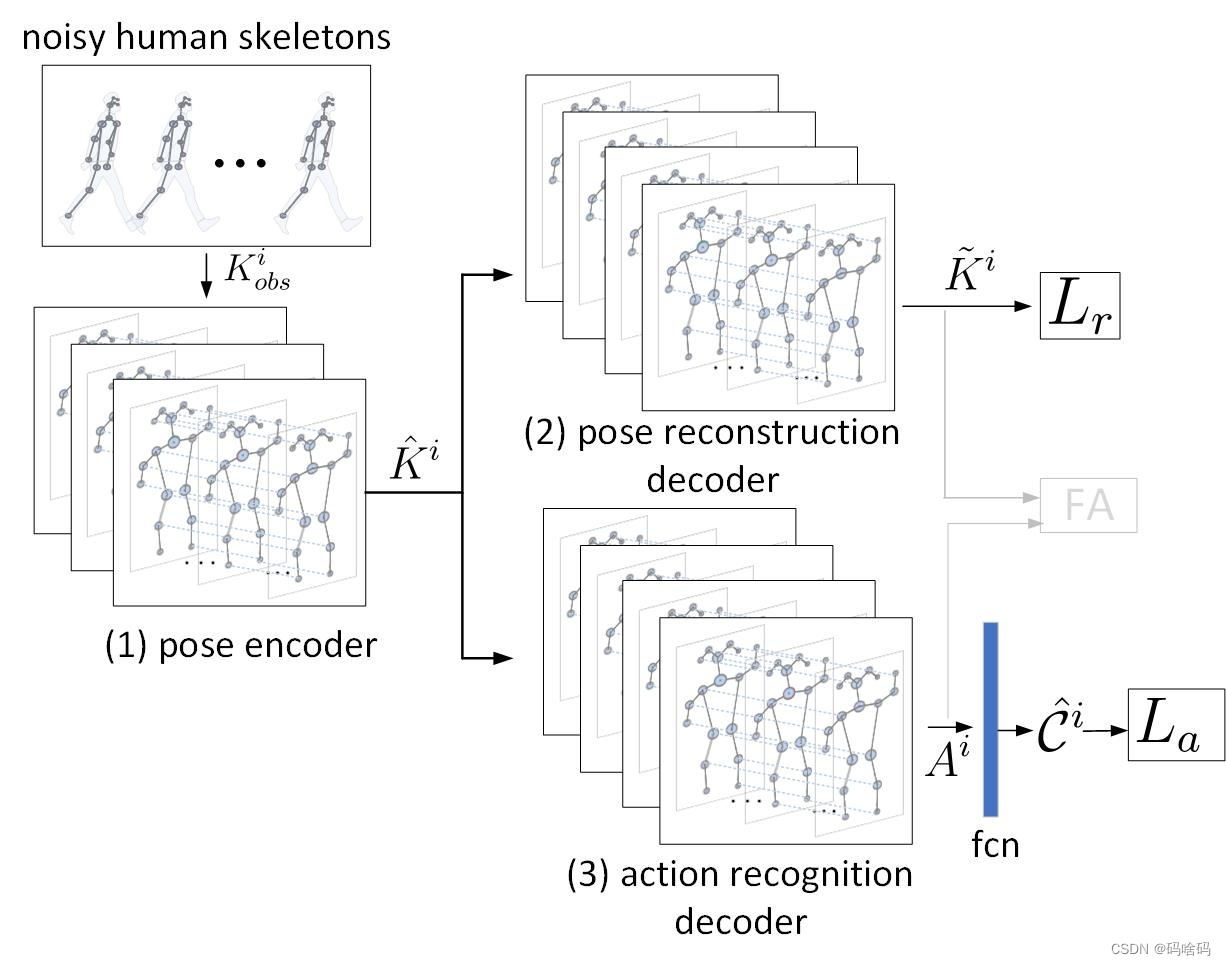
PRAR包括一个姿态编码器和两个解码分支,用于姿态重建和动作识别。
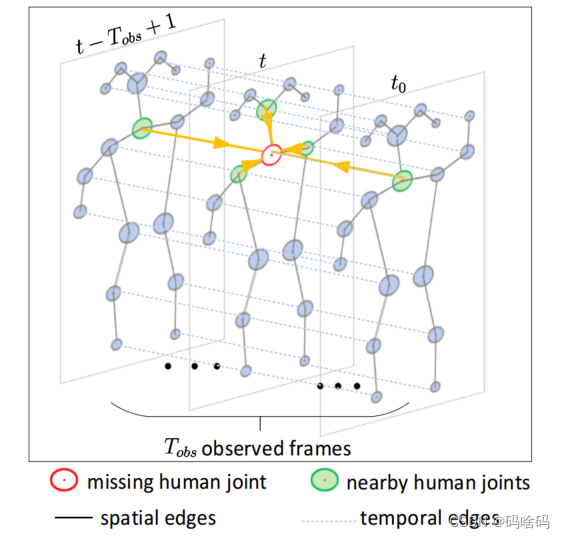
(b)使用基于骨架的时空图卷积网络设计了每个姿态编码器/解码器的单层
(b)中也显示了重建缺失关节的示例,其中可以通过考虑来自附近关节的空间和时间域的信息来实现。
Feature Aggregator(FA)
FA 的目标是通道聚合所有学习到的特征:重构姿态
K
i
~
\tilde{K_i}
Ki~,重构位置
L
i
~
\tilde{L_i}
Li~,动作特征
A
i
A^i
Ai 和区域光流
G
G
G。
具体来说,FA 由四个特征编码器和一个解码器组成。每个编码器使用多层一维时间卷积(conv1d)、整流线性单元(ReLU)和Batch normalization(BN)对一个输入特征(即重构的姿势、位置、动作和摄像机运动)进行编码。
LOSS计算
PRAR使用均方误差损失:
L
(
W
)
=
∑
i
N
∑
t
T
p
r
e
d
∣
∣
p
^
t
i
−
p
‾
t
i
∣
∣
2
L(W) = \sum^N_i\sum^{T_{pred}}_t ||\hat{p}^i_t - \overline{p}^i_t||^2
L(W)=i∑Nt∑Tpred∣∣p^ti−pti∣∣2
W
W
W包括模型的所有可训练参数
实验
数据集:JAAD(站、跳、蹲、弯、跑、走、躺、坐、跪)和 TITAN(站立和走路)
动作类分布不均匀,每个数据集分别进行实验,将每个数据集中的视频总数分成训练/验证集,比例为80/20。我们使用10帧进行观测,并预测 JAAD 数据集的下10帧(即0.3秒,预测下0.3秒)。对于 TITAN 数据集,我们观察了10个注释帧(1秒),并预测了接下来20个注释帧(2秒)的轨迹。
训练分为两段
- 第一阶段:预训练PRAR进行姿态重建和动作识别
由于 TITAN 和 JAAD 的完整人类骨骼和人类动作数量有限,我们首先在大规模 Kinetics 数据集上训练 PRAR 以获得初始网络权重,然后在 TITAN 和 JAAD 数据集上对其进行微调。我们在补充材料中展示了预训练 PRAR 对动力学的有效性。我们使用与[30]中相同的训练/验证分割来训练 PRAR。为了生成训练数据,我们只提取完整的姿态样本并将其用作基础真值。在训练过程中,PRAR 的输入是通过随机丢弃一些人体节点(即设置为缺失节点)来获得的,遮挡率为0%到50%。为了验证,使用所有姿态样本。动作标签与Kinetics数据集提供的每个姿势相关联,也用于训练公式2中的损失函数 PRAR。将验证结果最佳的模型在 JAAD 和 TITAN 数据集上继续训练(微调)。我们使用相同的方法提取 JAAD/TITAN 数据集的姿态样本。经过验证的最佳模型将用于下一阶段的训练。 - 第二阶段:训练GPRAR进行轨迹预测。
我们针对 JAAD[14]和 TITAN[20]数据集上的轨迹预测任务定制了预训练 PRAR。具体而言,我们将 FA 模块附加在 PRAR 之上,并在每个数据集的训练集上训练整个预测模型。在训练整个 GPRAR 的同时,我们允许更新 PRAR 的网络参数。这就是适应性学习方法。我们在消融研究中证明了它比非自适应方法更有效。在这两个阶段,我们的模型都使用随机梯度下降[2]进行训练,学习率为0.01 和 50个 epoch。我们在每10个 epoch 后将学习率衰减0.1。最后一个训练 epoch 得到的模型在验证集上进行验证。为了实现时空图卷积,我们使用了[30]中讨论的类似实现步骤。我们的网络模型是使用 PyTorch 实现的[26]。
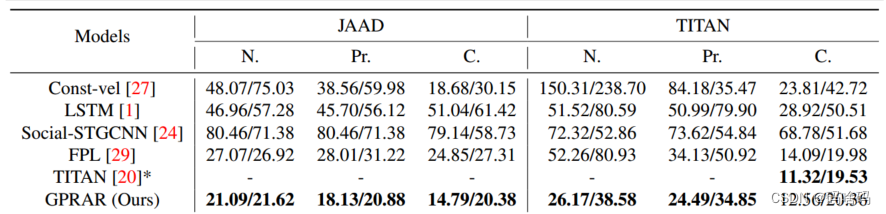
先进的方法比较
评价指标
我们使用两个常用的指标来评估我们的系统[1,29]:
(a)平均位移误差(ADE):预测和真实轨迹的所有位置的均方误差;
(b)最终位移误差(FDE):所有人类轨迹最终预测位置和真实位置的均方误差。
结论
在本文中,我们提出了一种新的动态视频序列人类未来轨迹预测模型 GPRAR,该模型可以有效地处理现实世界中有噪声的场景。本文的主要贡献是两个新的子网:PRAR 和 FA。PRAR 被训练用于多任务学习:动作识别和姿态识别,而FA将多个学习到的特征聚合在一起用于轨迹预测。PRAR 的关键实现是使用基于编码器-解码器的图卷积神经网络,这有助于利用人体姿势的结构特性。通过广泛的实验,我们已经表明,与最先进的模型相比,GPRAR 产生了优越的性能。我们进一步对引入的特征进行了性能分析,并表明我们的模型在遮挡和各种人类行为下有效地执行。

![[Nacos] Nacos Server之间的操作 (十一)](https://img-blog.csdnimg.cn/d0af0f04ff164505a57fdeb68245fc4f.png)