作者:Dave Erickson

在过去的几个周末里,我一直在 “即时工程” 的迷人世界中度过,并了解像 Elasticsearch® 这样的矢量数据库如何通过充当长期记忆和语义知识存储来增强像 ChatGPT 这样的大型语言模型 (LLM)。 然而,让我和许多其他经验丰富的数据架构师感到困扰的一件事是,那里的许多教程和演示完全依赖于向大型网络公司和基于云的人工智能公司发送您的私人数据。
私人数据有多种形式,并且出于多种原因受到保护。 对于初创公司和企业来说,他们都知道他们的私人数据有时是他们的竞争优势。 内部数据和客户数据通常包含个人身份信息,如果不加以保护,这些信息会在法律和现实世界中对人类造成后果。 在可观察性和安全领域,缺乏谨慎使用第三方服务可能是数据泄露的根源。 我们甚至听说过与使用 AI 聊天工具有关的网络安全漏洞指控。
没有任何设计是无风险或完全私密的,即使是与像 Elastic 这样对隐私和安全做出坚定承诺或在真正空气隔离(air gap)中进行部署的公司合作时也是如此。 但是,我处理过足够多的敏感数据用例,知道使用隐私优先的方法启用 AI 搜索具有非常实际的价值。 我喜欢我的同事 Jeff Vestal 关于将 OpenAI 工具与 Elasticsearch 结合使用的出色演练,但本文将采用不同的方法。
我对这个项目的方法有两个目标:
- 私有 —— 当我说私有时,我是认真的。 虽然我将使用云托管的 Elasticsearch,但如果用例需要它,我希望它能够空气隔离(air-gapped)完全地工作。 让我们证明我们可以在不将我们的私人知识发送给第三方的情况下让人工智能搜索工作。
- 乐趣 —— 另外,让我们在做的时候找点乐子。 我们将使用 Wookieepedia 的一部分,这是一个在数据科学练习中很受欢迎的社区星球大战维基百科,并制作一个私人 AI 琐事助手。 我写这篇文章时已接近 5 月 4 日,虽然在这篇文章发表时我们已经过了那个日期,但我的粉丝是全年无休的。
跟随并亲自尝试的最简单方法是在 Elastic Cloud 上启动一个 Elasticsearch 实例并运行提供的 Python notebook,这将在小规模上实施该项目。 如果你想运行包含 180K 段星球大战知识的完整 Wookieepedia 抓取并创建精通星球大战知识搜索,你可以在此处遵循 GitHub 存储库中的代码。
全部完成后,它应该如下所示:
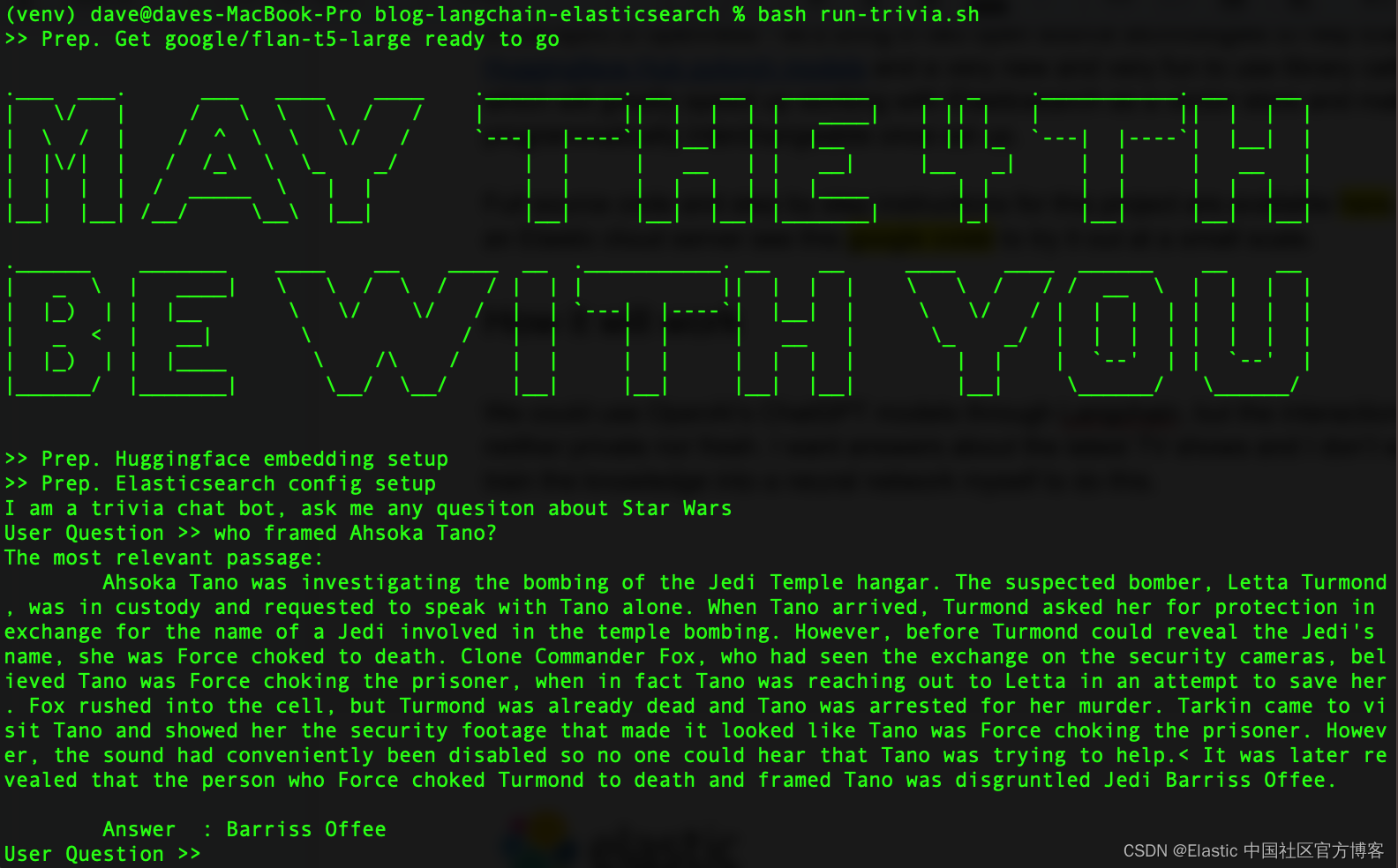
本着开放的精神,让我们引入两项开源技术来帮助 Elasticsearch:Hugging Face transformers 库和新的有趣的 Python 库 LangChain,这将加快 Elasticsearch 作为矢量数据库的工作速度。 作为奖励,LangChain 将使我们的 LLM 在设置后以编程方式可互换,这样我们就可以自由地试验各种模型。
它将如何运作
LangChian 是什么? LangChain 是一个 Python 和 JavaScript 框架,用于开发由大型语言模型提供支持的应用程序。 LangChain 将与 OpenAI 的 API 一起工作,但它也擅长抽象出数据库和人工智能工具之间的差异。
就其本身而言,ChatGPT 在星球大战琐事方面并不差。 然而,它的训练数据集已经有好几年了,我们需要有关星球大战宇宙中最新电视节目和事件的答案。 还要记住,我们假装这些数据太私密,无法与云中的大型 LLM 共享。 我们可以用更新的数据自己调整一个大型语言模型,但有一种更简单的方法可以做到这一点,它还允许我们始终使用最新的可用数据。
今天让我们引入一个更小且易于自托管的 LLM。 我用谷歌的 flan-t5-large 模型得到了很好的结果,它弥补了它缺乏训练的能力,它具有很好的从注入的上下文中解析出答案的能力。 我们将使用语义搜索来检索我们的私人知识,然后将该上下文与问题一起注入我们的私人 LLM。

1)从 Wookieepedia 中抓取所有经典文章,将数据放入暂存的 Python Pickle 文件中。
2A)使用 LangChain 的内置 Vectorstore 库将这些文章的每一段加载到 Elasticsearch 中。
2B)或者,我们可以将 LangChain 与在 Elasticsearch 本身中托管 pytorch 转换器的新方法进行比较。 我们会将文本嵌入模型部署到 Elasticsearch 以利用分布式计算并加快该过程。
3)当有问题出现时,我们会使用 Elasticsearch 的向量搜索找到与问题语义最相似的段落。 然后,我们将把该段落添加到一个小型本地 LLM 的提示中作为问题的上下文,然后将其留给生成 AI 的魔力,以获得对我们的琐事问题的简短回答。
设置 Python 和 Elasticsearch 环境
确保你的机器上有 Python 3.9 或类似版本。 我使用 3.9 是为了更容易与 GPU 加速库兼容,但这对于这个项目来说不是必需的。 任何最新的 3.X 版本的 Python 都可以使用。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformers如果你已经下载了示例代码,你可以直接使用以下 pip install 命令提取我使用的代码的确切版本。
pip install -r requirements.txt你可以按照此处的说明设置 Elasticsearch 集群。 免费云试用是最简单的入门方式。
在文件夹中创建一个 .env 文件并加载 Elasticsearch 的连接详细信息。
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"步骤 1. 抓取数据
代码仓库在 Dataset/starwars_small_sample_data.pickle 中有一个小数据集。 如果你可以在小范围内工作,则可以跳过此步骤。
抓取代码改编自 Dennis Bakhuis 出色的数据科学博客和项目 - 看看吧! 他只拉取每篇文章的第一段,我改代码全部拉取。 他可能需要将数据保持在适合主内存的大小,但我们没有这个问题,因为我们有 Elasticsearch,这将使它能够很好地扩展到 PB 范围。
你也可以非常轻松地在此处插入你自己的私有数据源。 LangChain 有一些优秀的实用程序库,可以将你的文本数据拆分成更短的块。
抓取不是本文的重点,所以如果你想自己小规模运行,请查看 Python notebook,或者下载源代码并像这样运行:
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py完成后,你应该能够像这样浏览保存的 Pickle 文件以确保它有效。
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)
如果你跳过网络抓取,只需将 bookFilePath 更改为 “starwars_small_sample_data.pickle” 即可使用我包含在 GitHub 存储库中的示例。
步骤 2A. 在 Elasticsearch 中加载嵌入
完整的代码展示了我是如何仅使用 LangChain 来做到这一点的。 代码的关键部分是像上面的例子一样循环遍历保存的 Pickle 文件并提取出作为段落的字符串列表,然后将它们交给 LangChain Vectorstore 的 from_texts() 函数。
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)步骤 2B. 使用托管训练模型节省时间和金钱
我发现在我的旧 Intel Macbook 上,创建嵌入需要很多小时的处理时间。 我很友善 —— 看起来好几天了。 我认为我可以使用 Elastic 托管服务的动态可扩展机器学习 (ML) 节点更快地完成这件事,而且花费更少。 免费试用集群不会让你扩展该层,因此此步骤对某些人来说可能比对其他人更有意义。
最终结果:这种方法在 Elastic Cloud 中运行成本为 5 美元/小时的节点上花费了 40 分钟,这比我在本地可以做的要快得多,并且与 OpenAI 当前的 token 收费处理嵌入的成本相当。 高效地执行此操作是一个更大的主题,但我对在 Elastic Cloud 中运行并行推理管道的速度如此之快印象深刻,而无需学习新技能或将我的数据交给非私有 API。
对于这一步,我们将把嵌入生成卸载到 Elasticsearch 集群本身,它可以托管嵌入模型并以分布式方式嵌入文本段落。 为此,我们必须加载数据并使用摄取管道来确保最终形式与 LangChain 使用的索引映射相匹配。 在 Kibana 的开发工具中运行以下 REST 命令:
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}接下来,我们将使用 eland Python 库将嵌入模型上传到 Elasticsearch。
source .env
python3 step-3A-upload-model.py接下来让我们转到 Elastic Cloud 控制台并将我们的 ML 层扩展到总共 64 个 vCPU(是我当前笔记本电脑的 8 倍)。

现在,在 Kibana 中,我们将部署经过训练的 ML 模型。 在规模上,性能测试表明,用户应该从每个模型分配 1 个线程开始,并增加分配数量以提高吞吐量。 可以在此处找到文档和指南。 我进行了实验,对于这个较小的集合,我得到了 32 个实例的最佳结果,每个实例有 2 个线程。 要进行设置,请转到 Stack Management > 机器学习。 使用 Synchronized saved objects 功能让 Kibana 看到我们使用 Python 代码推送到 Elasticsearch 的模型。 然后在单击它时出现的菜单中部署该模型。

现在让我们再次使用 Dev Tools 创建一个新的索引和摄取管道来处理文档中的文本段落,将结果放入一个称为 “vector” 的密集矢量字段中,并将该段落复制到预期的 “text” 字段中。
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}测试管道以确保其正常工作。
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}现在我们已准备好使用用于 Elasticsearch 的普通 Python 库批量加载数据,目标是我们的摄取管道以正确创建向量嵌入并转换我们的数据以符合 LangChain 的期望。
source .env
python3 step-3B-batch-hosted-vectorize.py成功! 数据在 OpenAI 方面约为 1300 万个 tokens,因此在非私有和云中处理此数据大约需要 5.40 美元。 使用 Elastic Cloud,花费 5 美元/小时的机器需要 40 分钟。
加载数据后,请记住使用云控制台将你的 Cloud ML 缩小到零或更合理的值。
第 3 步。在星球大战问答中获胜
接下来我们来玩一下 LLM 和 LangChain。 我创建了一个库文件 lib_llm.py 来保存这段代码。
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued belowtemplate_informed 是关键但也很容易理解的部分。 我们所做的只是格式化一个提示模板,它将采用我们的两个参数:上下文和用户的问题。
从上面继续这个最终的主要代码,它看起来像下面这样:
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")结论
因此,通过一些数据争论,我们现在已经使用了 AI,而没有将我们的数据暴露给第三方托管的 LLM。 AI 世界瞬息万变,但保护私人数据的安全和控制是我们所有人都应该认真对待的事情,以应对数据泄露带来的监管、财务和人员后果。 这不太可能改变。 我们与使用搜索来调查欺诈、保卫国家并改善弱势患者群体结果的客户合作。 隐私很重要。 要了解有关如何在这些空间中使用 Elastic 的更多信息,请查看:
- Elastic 公共部门
- Elastic 金融服务
你有没有像我一样爱上 LangChain? 正如一位睿智的老绝地武士曾经说过的那样:“那很好。 你已经迈出了迈向更大世界的第一步。” 从这里有很多方向。 LangChain 消除了使用 AI 提示工程的复杂性。 我知道 Elasticsearch 在这里可以扮演许多其他角色,比如生成式 AI 的长期记忆,所以我很高兴看到这个快速变化的空间会产生什么。
在这篇博文中,我们可能使用了由其各自所有者拥有和运营的第三方生成人工智能工具。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对您使用此类工具可能产生的任何损失或损害承担任何责任。 使用带有个人、敏感或机密信息的 AI 工具时请谨慎行事。 你提交的任何数据都可能用于人工智能训练或其他目的。 无法保证你提供的信息将得到安全保护或保密。 在使用之前,你应该熟悉任何生成人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch 和相关标志是 Elasticsearch N.V. 在美国和其他国家/地区的商标、徽标或注册商标。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。