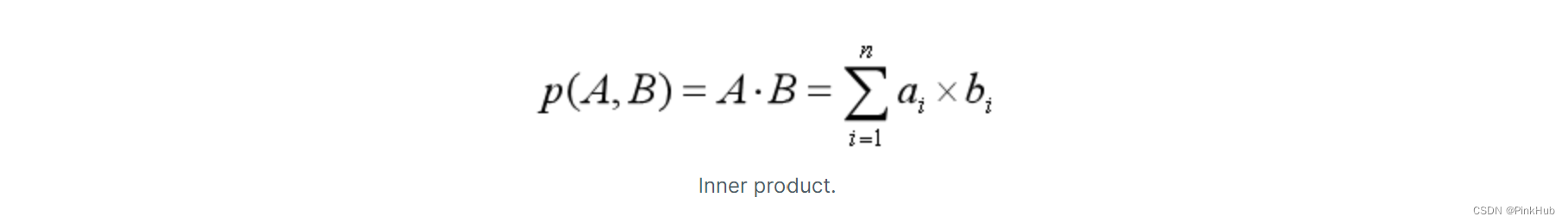作为高分辨率三维重建的方法之一,从单张图像生成稠密三维点云在计算机视觉领域中一直有着较高的关注度。
以下文献提出了一种针对二维和三维信息融合的方法以解决三维点云稀疏难以检测远处的目标的问题。
Multimodal Virtual Point 3D Detection
该文献提出一种将 RGB 传感器无缝融合到基于激光雷达的 3D 识别的方法。它采用一组二维检测来生成密集的三维虚拟点,以增强原本稀疏的三维点云。这些虚拟点与常规的激光雷达获得的原始点云一起自然地整合到任何标准的基于激光雷达的三维检测器中。由此产生的多模式检测器简单而有效。
在大规模的nuScenes数据集上的实验结果表明,该框架将强大的 CenterPoint 基线大幅提高了 6.6mAP,并超过具有竞争性的融合方法。
该方法的思路比较简单,具体如下。
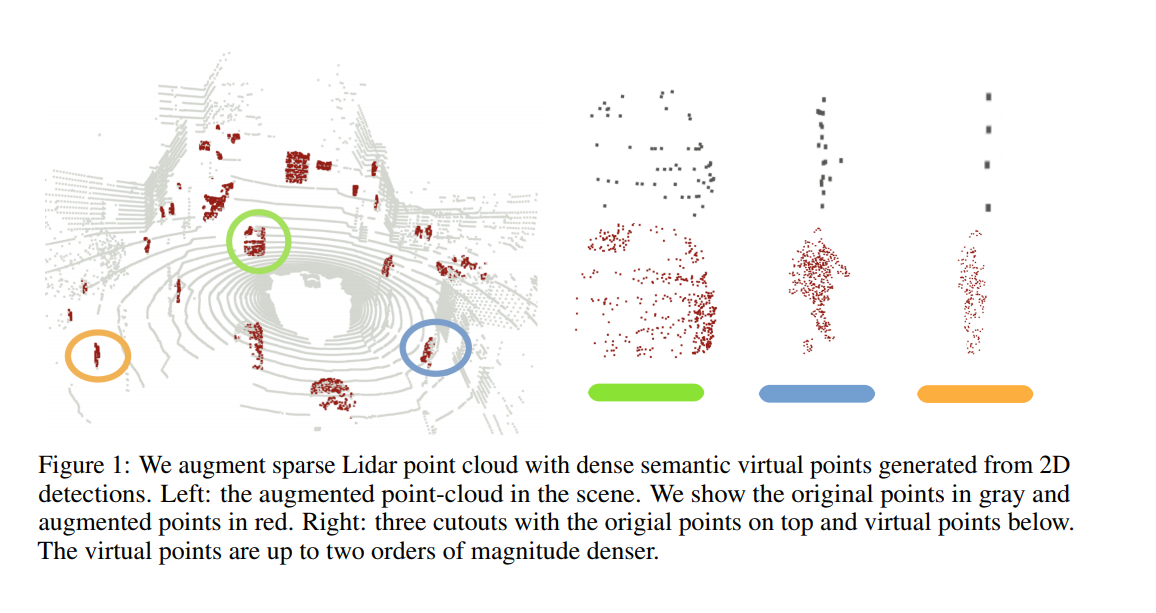
该论文的思想借鉴了PointPainting,实际上是利用图像实例分割结果,对激光点云做了稠密化。
PointPainting是获得图像分割结果后,把点云投影到图像上,得到每个点对应的图像分割的label。
假设原来的点云是N×3,就多了一维图像分割的label,变成N×4,然后用常规的点云处理算法处理,基于Point、Voxel或BEV。
同样是将点云投影到图像上,这篇论文反其道行之。
作者提出点云的一个缺点是太稀疏了,比如一辆车上只有几个激光点打了上去,而图像像素是全都“打”了上去。所以提出了一种方法,根据稠密的像素稠密化点云。
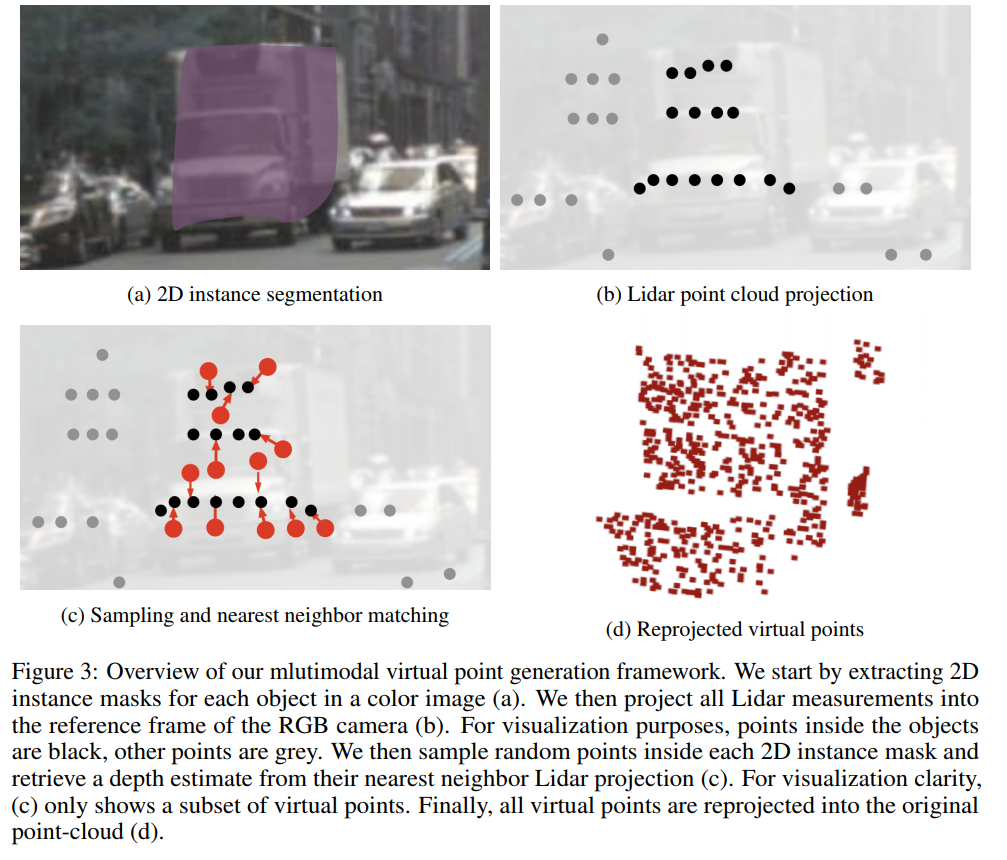
其生成虚拟点的方法:
1)首先对与点云对应的二维RGB图像进行语义(实例)分割,将激光点投影到图像(二维RGB相机坐标内)上,这样图像上每个instance上都会有几个激光点投上去。注意:这里仅考虑位于前景点实体分割中的点。
2)然后,对每个instance内的像素进行随机采样K个点(图c红色点),与被激光点投影上的像素(图c黑色点)进行最近邻关联,根据最近的几个原始点云的深度插值出虚拟点的深度。
3)最后,根据联合标定阶段得到坐标系变换矩阵将这些点投影回激光坐标系,得到virual lidar points,同时这些虚拟点包含实体分割中的类别信息。这样就达到了点云稠密化的效果,然后使用现在流行的3D backbone点云处理算法进行处理。
上述生成虚拟点的依据可能是对于属于同一个前景目标中的点,其前景深度不会相差很大,所以可以用其周围点的深度信息来对虚拟点的深度信息进行补全。从而到达缓解点云稀疏性的目的。
相比于baseline CenterPoint,从以下述表格中可以看出,使用生成的虚拟点确实能够在一定程度上提高模型的检测性能。此外,相比于同样采用分割结果来进行多模态融合的PointPainting, 该方法也获得了更好的性能。

此外,作者还研究了实体分割精度对于检测性能的影响。

文中通过使用降低输入分辨率模拟实体分割精度下降的方法,从文中可以看出,本文所提方法对于实例分割的精度还是具有较高的鲁棒性。
此外,作者还在文中提到,其在实验过程中验证了本文中所使用的基于邻近点进行深度估计的精度,平均误差在0.33m左右,可见在同一前景目标中,这种基于临近点的深度估计精度还是比较高的。