文章目录
- 进程间的通信
- 管道
- popen 和 pclose
- pipe
- FIFO
- 共享内存
- system V 版本的共享内存
- 创建/获取共享内存
- 共享内存涉及的函数
- 共享内存的通信
- 两个进程同时对共享内存进行读写
- 信号量
- 使用信号量保护共享资源
- 消息队列
- 死锁
- 信号
- 内核不可中断状态
进程间的通信
管道
在操作系统中,管道(Pipe)是一种用于进程间通信的机制。其中有名管道和匿名管道是两种不同类型的管道。
有名管道(Named pipe)也叫FIFO(First In First Out),它是一种存在于文件系统中的特殊文件,可以用于不同进程之间通信。有名管道需要通过mkfifo函数创建,并且必须以某种方式命名,以允许多个进程通过相同的名称打开和使用该管道。有名管道的数据传输是半双工的,即在同一时间只能有一个进程写入数据,而其他进程只能读取数据。
匿名管道(Anonymous pipe)则是一种无需文件系统支持的管道,用于具有父子关系的进程之间进行单向通信。匿名管道由pipe函数创建,其传输方向为单向,只能从一个进程的输出端到另一个进程的输入端。匿名管道的缺点是只能在具有亲缘关系的进程之间使用。
popen 和 pclose
popen() 和 pclose() 是 C 语言标准库中与处理进程相关的两个函数。
popen() 函数可以用于打开一个管道并启动一个进程,返回一个文件指针,可以通过该文件指针来读取或写入被启动进程的标准输入或输出。函数原型如下:
#include <stdio.h>
FILE *popen(const char *command, const char *mode);
command 参数是一个字符串,表示要执行的命令,类似于在终端上输入的命令。mode 参数是一个字符串,指定使用 popen() 打开的管道是读取模式还是写入模式。
popen() 函数成功时返回一个文件指针,失败时返回 NULL。
pclose() 函数用于关闭由 popen() 打开的文件流,并结束对应的进程。函数原型如下:
#include <stdio.h>
int pclose(FILE *stream);
stream 参数是由 popen() 返回的文件指针。pclose() 函数返回被结束进程的退出状态码。
需要注意的是,使用 popen() 和 pclose() 函数需要特别小心,因为它们会创建新的进程。如果不谨慎使用,可能会引发安全问题。另外,这两个函数只适用于 Unix-like 系统。
#include <stdio.h>
#include <stdlib.h>
int main()
{
FILE *fp;
char buffer[1024];
fp = popen("ls -l", "r");
if (fp == NULL) {
fprintf(stderr, "Failed to run command\n");
exit(1);
}
while (fgets(buffer, sizeof(buffer), fp) != NULL) {
printf("%s", buffer);
}
pclose(fp);
return 0;
}
pipe
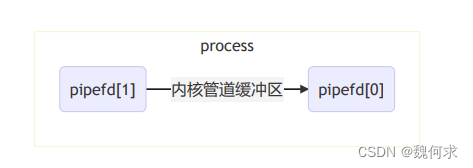
使用系统调用 pipe 可以创建匿名管道,为了支持可移植性,管道是半双工的,所以一般同时使用两条管道来实现全双工通信。使用 pipe 之前,需要首先创建一个大小为2的整型数组,用于存储文件描述符。但系统调用执行完成之后,pipefd[0]是读端的文件描述符,pipefd[1]是写端的文件描述符。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int fds[2];
if (pipe(fds) == -1) {
perror("pipe");
exit(EXIT_FAILURE);
}
pid_t pid = fork();
if (pid == -1) {
perror("fork");
exit(EXIT_FAILURE);
}
else if (pid == 0) { // 子进程
close(fds[1]); // 关闭子进程写端
char buf[128] = {0};
ssize_t nbytes = read(fds[0], buf, sizeof(buf));
if (nbytes == -1) {
perror("read");
exit(EXIT_FAILURE);
}
printf("%s\n", buf);
exit(EXIT_SUCCESS);
}
else { // 父进程
close(fds[0]); // 关闭父进程读端
ssize_t nbytes = write(fds[1], "hello", 5);
if (nbytes == -1) {
perror("write");
exit(EXIT_FAILURE);
}
wait(NULL); // 等待子进程退出
exit(EXIT_SUCCESS);
}
}
FIFO
FIFO(First In First Out)是一种基于文件操作的进程间通信方式,也被称为命名管道。它提供了一个特殊的文件类型,可以在不相关进程之间传递数据。FIFO 在外观上类似于常规的 Unix 管道,但其使用方式有所不同。FIFO 具有一个在文件系统中唯一的路径名,并通过调用 mkfifo 函数进行创建,创建后即可在任意进程中打开和读写。
与普通文件不同的是,FIFO 既可以读也可以写,并且数据遵循先进先出的原则进行读写。当一个进程向 FIFO 中写入数据时,另一个进程可以从 FIFO 中读取这些数据。如果没有进程正在读取 FIFO 中的数据,写入的数据将被存储在 FIFO 中,直到有进程来读取它们。
下面是一个简单的使用 FIFO 进行进程间通信的示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FIFO_NAME "/tmp/my_fifo"
int main() {
const char *msg = "Hello, FIFO!";
int fd;
mode_t mode = S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH; // 文件权限:rw-r--r--
if (mkfifo(FIFO_NAME, mode) == -1) { // 创建 FIFO
perror("mkfifo");
exit(EXIT_FAILURE);
}
printf("Waiting for readers...\n");
fd = open(FIFO_NAME, O_WRONLY); // 打开 FIFO 写端
printf("Got a reader. Writing data...\n");
write(fd, msg, sizeof(msg)); // 向 FIFO 中写入数据
printf("Data written.\n");
close(fd); // 关闭 FIFO 写端
exit(EXIT_SUCCESS);
}
在上面的示例中,我们首先定义了一个名为 FIFO_NAME 的常量,它是 FIFO 在文件系统中唯一的路径名。然后使用 mkfifo 函数创建了一个名为 /tmp/my_fifo 的 FIFO,并指定了该文件的权限。
接着,在等待读取者到来时,调用 open 函数打开 FIFO 的写端,并向其中写入数据。最后,关闭 FIFO 的写端并退出程序。
需要注意的是,FIFO 是阻塞的,这意味着当没有任何进程读取 FIFO 中的数据时,写入数据的进程将被阻塞,直到另一个进程来读取数据为止。同样,当没有任何进程向 FIFO 中写入数据时,读取数据的进程也会被阻塞。因此,在实际使用中,我们通常需要使用多线程或异步 I/O 等技术来防止进程被阻塞。
共享内存
共享内存是一种用于在进程之间共享数据的技术。使用共享内存的原因有以下几个方面:
- 提高进程间通信效率:相较于其他进程间通信方式(如管道、消息队列等),共享内存具有更高的速度和效率,因为它不需要在进程之间复制数据,而是直接将内存区域映射到多个进程的地址空间中。
- 方便数据共享:共享内存可以将同一块内存区域映射到多个进程的地址空间中,在这些进程之间共享数据变得非常简单。这对于需要在多个进程之间协作完成某项任务的应用程序非常有用。
- 简化编程逻辑:通过使用共享内存,不必像其他 IPC 机制那样使用繁琐的系统调用来发送和接收数据。这使得编写并发程序变得更加容易。
- 节省系统资源:由于共享内存不需要在进程之间复制数据,因此可以节省系统资源,提高系统的整体性能。
需要注意的是,共享内存也存在一些潜在的问题,例如数据同步和互斥、权限控制等方面的问题。如果使用不当,可能会导致数据损坏或程序崩溃等问题。因此,在使用共享内存时,需要仔细考虑和实现相关的同步机制和安全措施。
内存管理单元(MMU)是一种硬件组件,用于在计算机中管理和控制程序访问内存的方式。MMU负责将虚拟内存地址转换为物理内存地址,并确保每个程序只能访问其分配的内存区域,从而防止程序之间的干扰或损坏。
MMU通过利用地址转换技术实现这一功能。当程序尝试访问虚拟内存地址时,MMU会查找页表,将其转换为对应的物理内存地址,然后将数据从物理内存中读取或写入。如果程序尝试访问未分配给它的内存,MMU将拒绝该请求并抛出异常。
除了内存保护外,MMU还可以帮助实现操作系统的虚拟内存管理、进程隔离和安全性。它是现代计算机体系结构中必不可少的组成部分。
system V 版本的共享内存
ftok()函数是一个用于将文件路径名和一个整数标识符(项目 ID)转换为唯一的System V IPC(Inter-Process Communication,进程间通信)键值的函数。它的原型定义在头文件 sys/ipc.h 中:
key_t ftok(const char *pathname, int proj_id);
当使用System V IPC进行进程间通信时,往往需要一个唯一的IPC键来标识一个共享的资源(如消息队列、共享内存等)。这个键是由path参数和proj_id参数组合而成的。其中path表示被关联的文件的路径名,proj_id则是用户自定义的单调递增的序号。
ftok()函数通过计算出一个唯一的整数值来返回一个键值(key_t类型),该值可供 System V IPC使用。这个计算过程中,使用了 path 和 proj_id 两个参数,因此只要这两个参数不同,得到的键值就是唯一的。
例如,如果两个进程都需要访问同一块共享内存区域,它们可以通过 ftok 函数得到相同的键值,然后分别调用 shmget 函数来获取对该共享内存区域的引用。
创建/获取共享内存
使用 System V IPC 机制创建和获取共享内存的主要步骤如下:
- 调用
ftok函数生成一个键值(key)。 - 调用
shmget函数创建或获取一个共享内存区域,并返回一个共享内存标识符(shmid)。 - 调用
shmat函数将共享内存附加到当前进程的地址空间中,并返回指向共享内存首地址的指针。 - 当不再需要访问共享内存时,调用
shmdt函数将共享内存从当前进程的地址空间中分离。 - 当所有进程都不再使用该共享内存时,调用
shmctl函数删除共享内存对象。
//创建共享内存
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#define SHM_SIZE 1024
int main() {
int shmid;
key_t key;
char *shm, *s;
// 生成键值
key = ftok(".", 'a');
// 创建共享内存段
shmid = shmget(key, SHM_SIZE, IPC_CREAT | 0666);
if (shmid == -1) {
perror("shmget");
exit(1);
}
// 将共享内存连接到当前进程的地址空间
shm = shmat(shmid, NULL, 0);
if (shm == (char *) -1) {
perror("shmat");
exit(1);
}
// 写入数据到共享内存
s = shm;
for (char c = 'a'; c <= 'z'; c++) {
*s++ = c;
}
*s = '\0';
// 分离共享内存
if (shmdt(shm) == -1) {
perror("shmdt");
exit(1);
}
printf("共享内存已创建\n");
return 0;
}
- 获取共享内存
要获取一个已经存在的共享内存段,需要执行以下步骤:
- 使用
ftok函数生成一个键值。 - 调用
shmget函数获取共享内存标识符(shmid)。 - 调用
shmat函数将共享内存连接到当前进程的地址空间,并返回指向共享内存段的指针。
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int main() {
int shmid;
key_t key;
char *shm, *s;
// 生成键值
key = ftok(".", 'a');
// 获取共享内存段
shmid = shmget(key, 0, 0666);
if (shmid == -1) {
perror("shmget");
exit(1);
}
// 将共享内存连接到当前进程的地址空间
shm = shmat(shmid, NULL, 0);
if (shm == (char *) -1) {
perror("shmat");
exit(1);
}
// 读取共享内存中的数据
for (s = shm; *s != '\0'; s++) {
putchar(*s);
}
putchar('\n');
// 分离共享内存
if (shmdt(shm) == -1) {
perror("shmdt");
exit(1);
}
printf("共享内存已获取\n");
return 0;
}
共享内存涉及的函数
共享内存是一种进程间通信的方式,涉及的函数与参数如下:
- shmget() 函数:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
- key:共享内存区域的标识符,通过它来识别同一块共享内存区域。
- size:共享内存区域的大小,单位是字节。
- shmflg:标志位,用来指定对共享内存区域的访问权限和操作方式。
- shmat() 函数:
#include <sys/types.h>
#include <sys/shm.h>
void *shmat(int shmid, const void *shmaddr, int shmflg);
- shmid:由shmget()函数返回的共享内存区域标识符。
- shmaddr:指定将共享内存附加到进程地址空间的地址,通常设置为NULL,由系统自动分配一个空闲地址。
- shmflg:标志位,用于指定共享内存的访问权限和附加方式。
- shmdt() 函数:
#include <sys/types.h>
#include <sys/shm.h>
int shmdt(const void *shmaddr);
- shmaddr:指向共享内存区域的指针,通常是由shmat()函数返回。
- shmctl() 函数:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
- shmid:共享内存区域的标识符,用于标识要进行操作的共享内存区域。
- cmd:指定要执行的操作类型,例如IPC_STAT、IPC_SET等。
- buf:共享内存区域的状态信息结构体,用于获取或者设置共享内存区域的相关信息。
共享内存的通信
共享内存是一种在多个进程之间共享数据的方式,它可以用于进程间通信(IPC),特别适合于需要高速数据传输的场景。共享内存允许多个进程访问同一块物理内存区域,这样就避免了进程之间频繁地进行数据拷贝和通信的开销。
在使用共享内存进行进程间通信时,通常需要以下步骤:
- 创建共享内存区域:在Linux系统中,可以使用shmget()函数创建共享内存区域。该函数需要指定共享内存区域的大小、权限等参数,并返回一个共享内存标识符(shmid)。
- 将共享内存区域映射到进程地址空间:可以使用shmat()函数将共享内存区域映射到进程的地址空间中。该函数需要指定共享内存标识符和映射的地址位置,返回映射后的地址指针。
- 进行数据读写操作:多个进程都可以通过映射后的地址指针访问共享内存区域中的数据,从而实现数据的读写操作。
- 解除共享内存区域映射:在不再需要使用共享内存区域时,可以使用shmdt()函数解除共享内存区域的映射关系。
- 删除共享内存区域:可以使用shmctl()函数删除共享内存区域。该函数需要指定共享内存标识符和操作类型,通常使用IPC_RMID操作类型来删除共享内存区域。
需要注意的是,在使用共享内存进行进程间通信时,需要对数据访问进行同步控制,以避免多个进程同时修改数据造成的竞争条件。常用的同步控制方式包括信号量、互斥锁等。
两个进程同时对共享内存进行读写
如果两个进程同时对共享内存进行写操作,就有可能导致数据的不一致性。因为这两个进程可能会同时写入相同的内存位置,从而造成数据被覆盖或丢失。
为了避免这种情况,可以使用互斥锁(mutex)来保护共享内存。当一个进程要访问共享内存时,它需要先获得互斥锁。如果另一个进程已经持有了锁,则该进程必须等待直到锁被释放。一旦一个进程拿到了锁,它就可以安全地访问共享内存,并在完成操作后释放锁,以便其他进程可以访问共享内存。
使用互斥锁可以确保每次只有一个进程能够访问共享内存,从而保证数据的一致性。
信号量
信号量(Semaphore)是一种用于控制多个进程/线程互斥访问共享资源的机制。它通常作为进程间同步或线程间同步的手段之一,在操作系统和并发编程中被广泛使用。
在操作系统中,信号量是一个计数器,初始值为一个非负整数。当进程需要获取某个共享资源时,首先检查信号量的值是否大于0,如果大于0,则将信号量的值减1,并允许进程访问该共享资源;如果等于0,则表示该共享资源已被其他进程占用,当前进程需要等待,直到信号量的值变为大于0。当进程释放共享资源时,需要将信号量的值加1,以便其他进程可以继续访问该共享资源。
在并发编程中,信号量通常由一个类实现。在Java语言中,可以使用java.util.concurrent.Semaphore类来实现信号量机制。
信号量是一种用于进程间同步的IPC。信号量本身是一个计数器,表示有多少个共享资源可以共享使用。 当进程访问共享资源时,首先需要需要检查信号量的数值,如果信号量为正,那么进程就可以使用该资 源,并且信号量数值减1,也就是操作系统所述的P操作;如果信号量的数值为0,那么就进程就休眠直 到信号量大于0。当进程不再访问共享资源的时候,信号量加1,并且唤醒休眠的进程,这就是操作系统 所述的V操作。为了在进程切换的时候也能保证信号量的正确性,信号量值的测试和减1操作是原子操 作,也被称为原语,原子这里代表不可分割的含义。如果信号量的值初始为1,那么就可以被称为二元信 号量。
使用信号量保护共享资源
在并发编程中,临界区指的是一段代码或者程序区域,这些代码会访问共享资源(如内存、文件等),而当多个线程同时访问这些资源时,就可能产生竞态条件(race condition)或者其他不确定性的行为。因此,在临界区内部需要采取特殊的措施来保证同步和互斥,以避免多个线程同时对共享资源进行访问,从而导致数据的损坏或者结果的异常。通常可以通过使用锁、信号量、互斥体等同步机制来实现对临界区的保护。
消息队列
消息队列是一种基于异步通信的消息传递机制,它将消息发送者和接收者解耦,并允许它们独立地处理消息。在消息队列中,消息发送者将消息发送到队列中,而消息接收者则从队列中取出消息并进行处理。
消息队列通常由以下几个部分组成:
- 消息生产者:负责创建并发布消息到队列中。
- 消息队列:存储所有发布的消息,并将其按照指定的规则进行排序和管理。
- 消息消费者:从队列中获取消息并对其进行处理。
消息队列有很多优点,包括:
- 解耦:消息队列可以将消息发送者和接收者解耦,从而提高系统的可扩展性和灵活性。
- 异步:消息队列支持异步通信,可以让发送者和接收者不必等待对方的响应,从而提高系统的响应速度和吞吐量。
- 缓冲:消息队列可以作为缓冲区,帮助平衡发送者和接收者之间的数据流量,从而避免系统的瓶颈问题。
- 可靠性:消息队列通常具有很高的可靠性,可以通过复制和备份等方式来保证数据的安全性和可用性。
消息队列通常涉及以下几个函数:
msgget:创建一个新的消息队列或者获取已有的消息队列。
msgsnd:向消息队列中发送一条消息。
msgrcv:从消息队列中接收一条消息。
msgctl:对消息队列进行控制(例如删除消息队列)。
这些函数是用于在进程之间传递数据的,它们可以被用于实现各种不同的应用程序,例如多进程协作、任务分发等。
死锁
死锁是指两个或多个进程在执行过程中,因竞争资源而造成的一种互相等待的现象,若无外力作用,它们都将无法继续执行下去。简单来说,就是一个进程持有某个资源并请求其他进程所持有的资源,但其他进程又不释放该资源,导致所有进程都被阻塞,不能继续执行。
死锁通常发生在多进程并发编程中,比如多线程共享同一资源时,如果对资源的访问没有进行适当的同步和协调,就容易出现死锁。解决死锁的方法包括:避免、预防、检测和恢复。其中,避免死锁是最好的方法,可以通过加锁的顺序、限制资源的使用等方式来避免死锁的发生;预防死锁则需要采取一些特定的策略和算法;检测死锁可以通过系统监控和记录来实现;恢复死锁则需要采取一些紧急措施,比如强制终止进程或者回滚操作等。
信号
在 Linux 中,信号(signal)是一种进程间通信机制,用于向进程发送信息以通知它们发生了某个事件。
Linux 中支持数十种不同的信号,每个信号都有一个唯一的整数标识符。这些信号可以分为两类:
- 异步信号:由操作系统或其他进程触发,例如 SIGTERM(终止进程)和 SIGKILL(强制终止进程)等。
- 同步信号:由应用程序自身触发,例如 SIGSEGV(段错误)和 SIGFPE(浮点异常)等。
当进程接收到一个信号时,它可以采取以下三种行为之一:
- 忽略该信号
- 执行默认操作,例如终止进程或者核心转储
- 执行用户指定的处理函数
除了 SIGKILL 和 SIGSTOP 信号外,大多数信号都可以被捕获和处理。我们可以通过调用 signal() 或者 sigaction() 函数来为一个进程注册信号处理函数。当该进程接收到对应的信号时,就会执行该处理函数。
需要注意的是,信号处理函数应该尽量简短,因为它们会打断正在执行的代码流程,可能导致数据出错或锁死问题。
signal() 函数可以用于为一个进程注册信号处理函数。它的函数原型如下:
#include <signal.h>
void (*signal(int signum, void (*handler)(int)))(int);
该函数接收两个参数:
signum:要注册处理函数的信号编号。handler:指向信号处理函数的指针。
signal() 函数返回一个指向以前信号处理函数的指针,如果返回值是 SIG_ERR,则表示注册失败。
在使用 signal() 函数时,需要注意以下几点:
- 信号处理函数必须具有以下形式:
void handler(int sig),其中sig是接收到的信号编号。 - 如果将
handler参数设置为SIG_IGN,则表示忽略该信号。 - 如果将
handler参数设置为SIG_DFL,则表示执行默认操作。
内核不可中断状态
处于内核不可中断状态(进程控制块的state成员此时为TASK_UNINTERRUPTIBLE)的进程无法接受并 处理信号。处于这种的状态的进程在 ps 中显示为D,通常这种状态出现在进程必须不受干扰地等待或者 等待事件很快会发生的时候出现,比如进程正在等待磁盘读写数据的时候。对于非嵌入式程序员而言, 这种状态是几乎没办法实现。内核不可中断状态是进程等待态的一种形式。