在大数据时代,数据是每个企业的五星资产,被誉为“新石油”,但未经处理的数据往往参杂着大量“杂质”。这些“脏数据”不仅影响分析结果,严重的甚至误导企业决策。数据清洗作为数据预处理的关键环节,正是通过“去芜存菁”,让数据焕发价值。那么,数据清洗究竟在清洗什么?本文将为你一一解析。
一、什么是数据清洗?
数据清洗是指对收集到的原始数据进行处理,以纠正缺失、异常、错误、不规范的数据,从而提高数据的质量和可用性。我们所谓的数据清洗并非简单的“删删改改”,而是针对不同脏数据类型的系统性处理。当然脏数据类型也是丰富多样的,常见的有空值、异常值、重复值、错误数据、不规范格式等。比如用户信息表中有用户的性别为空而出现空值;比如用户统计信息表中出现年龄大于200而出现异常值;比如多人收集到同一个人的订单出现的数据重复;比如日期正常格式应该是 YYYY -MM-DD,但是系统却记成了 MMDDYYYY等等。这些场景的脏数据如果不加以处理,就会对结果影响非常大,在进行数据分析、数据挖掘潜在价值的时候 ,往往很容易导致分析结果出现偏差,无法提供可靠的数据依据。数据清洗的核心就是发现原始数据的问题并做出针对性的修复,最终目标是让数据达到准确、完整、一致、可靠的标准。在做出针对性修复过程中,需要结合业务场景去灵活的选择方法。例如:信贷交易数据:需要严格的处理异常值和缺失值;社交媒体数据:需要清洗特殊符号、停用词和错乱数据。
二、具体清洗内容及过程
这里对数据清洗的工作做一个汇总,附图:
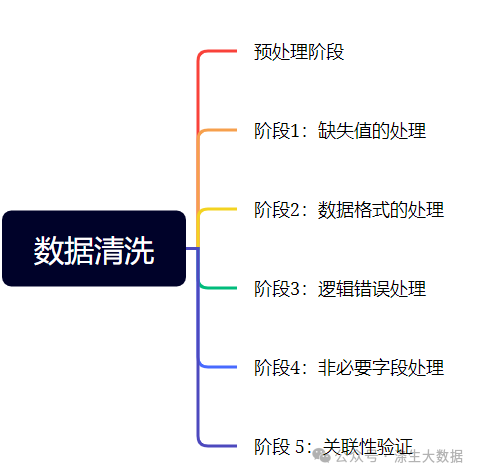
1.预处理阶段
预处理阶段主要要搞明白那些数据是有价值的值得清洗的: 首先是将数据的加载。我们需要把业务原始数据加载到我们的平台,对于非必要的数据字段,我们可以不用加载,选择有价值的数据进行清洗。 其次是看数据。这里的看数据,并不是简单的看书,对于数据的元数据,比如字段解释、数据来源、代码表等等一切描述数据的信息,都要好好的研究,对于真正的主数据,我们则需要就行数据探查,比如抽取一部分数据,看看数据的分布情况,看看数据的重复情况,还可以分维度聚合,各个视角的对比数据,对数据本身有一个直观的了解,并且初步发现一些问题,为之后的处理做准备。
2.缺失值的处理
缺失值是最常见的数据问题,处理缺失值也有很多方法,我建议按照以下四个步骤进行: 1)制定补充策略:对每个字段我们都可以计算其缺失值比例,当然现实项目中由于字段过多,不会这么做,但是大部分重要字段还是要一一计算,然后按照我们探查出来的缺失比例和字段重要性,分别制定策略,具体可用下图表示:
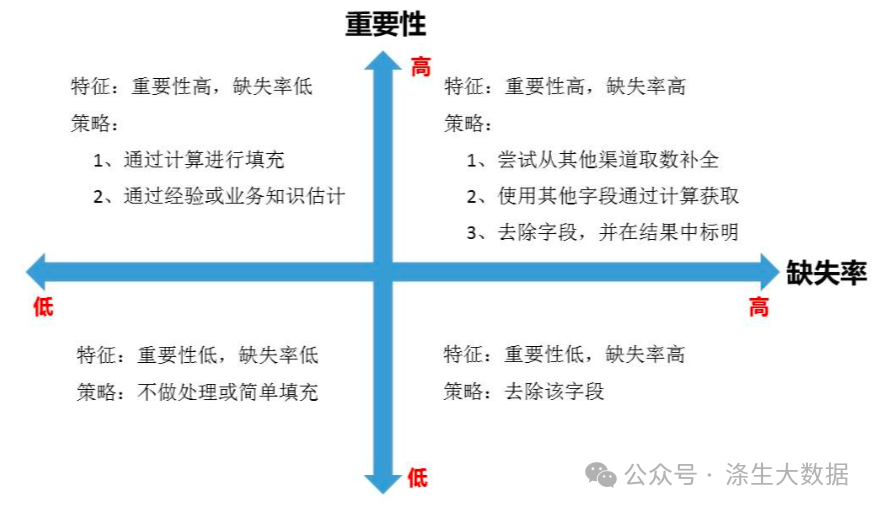
2)填充缺失内容:对于缺失值的填充每个企业会有所不同,但是常见的有以下三种: 以业务知识或经验推测填充缺失值 以同一指标的计算结果填充缺失值,比如均值、中位数、众数等。 以数据附近的数据值填充,比如向上取、向下取。 3)业务数据处理,重新加载:如果一些字段非常重要,但是它的缺失率又非常高,那就需要和取数人员或业务人员了解,是否有其他渠道可以取到相关数据。 以上,简单的梳理了缺失值清洗的步骤,但其中有一些内容远比我说的复杂,比如填充缺失值。很多讲统计方法或统计工具的书籍会提到相关方法,有兴趣的各位可以自行深入了解。
3.数据格式的处理
数据很大一定程度上格式不是完全正确的,比如如果数据是由系统数据库而来,那么在格式和内容方面出错的概率很小,与元数据描述一致。而如果数据是爬虫爬来的,或者是由人工收集来的,那么则很大程度上会存在格式的问题,大概率可能在格式和内容上存在一些问题,通常情况下,格式内容问题有以下几类: 1)时间、数值、全半角等显示格式不一致 这种问题是最常见的,通常与输入端有关,前端没有强校验,或者来自不同的额前端,整合到一起就会出现类似问题,这个也非常好处理,想办法将其整合成一致的格式。 2)特定字段中有不该存在的字符 某些字段只包含一部分字符,但是如果出现了多余的其他字符,那就是属于错误的,比如身份证号是数字+字母,不会再出现其他的情况,还有就是输入的过程中多输入了字符,比较典型的案例就是头、尾、中间包含了空格,自己又很少发现。也又概率出现姓名中存在特殊符号、身份证号中出现汉字等问题。这些情况,想办法拿到正确的数据,如果不能,就需要去除特殊的字符。 3)内容与字段元数据描述的内容不符 这类问题也是一大头痛问题,姓名填写了性别,身份证号写了手机号等等,手机号填写了身份证,均属于这类问题。 该问题之所以让人头痛,只因为他的特殊性:你并不能简单的删除来来处理它,因为有可能是人工填写的错误,也有可能是导入数据时存在列没有对齐的问题,所以在处理这个问题时,要详细识别问题属于什么类型。如果输入错位,我们想办法归为,如果是字段列没有对齐,拿重新导入数据,把列对齐。
4.逻辑错误处理
有一些数据我们虽然格式是正确的,但是经过我们的推敲明显是存在问题,对于这部分数据,就是使用简单逻辑推理去发现问题的数据,然后想办法修正,防止对分析结果有很大的影响。包含以下几个步骤: 1)剔除不合理值 什么是不合理的值?就是一些值乍看没啥问题,但是是现实世界不匹配,比如有人在填表时候乱填,年龄填个300岁,年收入1000000万,你说这些数据错了吧,他倒是也没啥问题,但是真的有人活了300岁吗?很显然不符合社会客观规律,这种情况二种处理思路,要么直接删掉,要么按缺失值处理。这种值又是如何发现呢?我们可以做一些简单的逻辑判断。 2)去重 去重是所有清洗过程中,必不可少的动作,因为重复的数据对后续的使用影响太大了,很容易就造成数据倾斜,所以去重不管是做什么表,都要明白你的表的粒度,考虑去重。有的数据开发人员喜欢把去重放在第一步,这也是可以,但是这里强烈建议把去重放在格式内容清洗之后,原因也很简单,由于格式问题造成的重复数据也存在,比如姓名维:'张三’可能因为空格问题记录成‘张 三’ 。这样,你只有在格式化以后在能去重。 3)矛盾数据处理 什么是矛盾数据,有些字段是可以互相验证的,最简单的例子就是年龄和身份证,比如:填写的身份证号是1201131970XXXXXXX,然后填写的年龄为20岁,这个就存在明显的矛盾。总不能一个人永远20岁吧,在这种情况下,需要根据字段的数据来源,来判定哪个字段的信息更为可靠,更为真实,来剔除或重构不可靠的字段。比如金融实名的字段总比自己填写的年龄要靠谱的多。当然逻辑错误并不仅仅局限上面列举的,实际还有很多情况,在实际操作中要酌情处理。
5.非必要字段处理
这一步也非常简单,对于不用的字段直接删掉即可,比如业务表中的备份,冗余字段。但是还是要建议在清洗的每做一步都备份一下,或者在小规模数据集上试验成功再处理全量数据,这样我们就可以对我们处理的数据进行追溯,万一删错了会追悔莫及。当然实际操作过程中也存在一些问题,比如: 把看上去不需要的字段,但是实际上对业务十分重要的字段删了; 某个字段看着觉得有用,但又没想好怎么用,不知道是否该删; 看走眼,误操作删错字段了。 所以对于前两种情况,建议是:如果数据量没有大到不删字段就没办法处理的程度,那么能不删的字段尽量不删。至于第三种情况,就像我们说的一定要做好备份。
6.数据验证
这一步也是必不可少的,如果你的数据来源是多数据源,那么就十分有必要进行关联性验证。例如,你有用户的实名认证信息,后来又经过一些列问卷调查获取了一部分信息,那么两者我们可以通过姓名和手机号关联,看看是不是同一个人。严格意义上来说,这一步已经脱离数据清洗的范畴了,但是关联数据变动在数据库模型中就应该涉及。多个来源的数据整合是非常复杂的工作,一定要注意数据之间的关联性,尽量在分析过程中不要出现数据之间互相矛盾。
三、为什么数据清洗如此重要?
准确的数据是一切决策的根基。数据清洗通过识别和修正错误数据,确保每一个数据点都真实可靠,从而为企业的决策提供坚实的基础,使决策能够建立在正确的事实之上。但如果数据存在大量异常值、重复值或缺失值,那么分析结果将极不可靠。具体清洗数据的好处: 保障数据质量:尤其是在数据准确性和可信度的方面。 提升分析准确性:根据清洗后的数据进行分析,能够很大程度上提高分析结果的可靠性,减少决策错误。 减少存储成本:通过删除重复和无关的数据,有效减少存储空间的浪费。