目录
一、Stable Diffusion介绍
二、Stable Diffusion环境搭建
1.Anaconda下载与安装
2.Pycharm(IDE)下载与安装
3.CUDA、CuDNN下载与安装
三、Stable Diffusion的本地部署
1.克隆项目到本地
2.初始化打开项目
3.安装环境所需库
4.运行代码以及效果展示
至此,AI绘画 Stable Diffusion本地部署以及初步功能实现完成!制作不易,望喜欢!
一、Stable Diffusion介绍
最近火热的AI绘画技术吸引了很多人的目光,AI绘画今年取得如此广泛关注的原因,有很大的功劳得益于Stable Diffusion的开源。它是由德国慕尼黑大学机器视觉与学习研究小组和Runway的研究人员基于CVPR2022的一篇论文:《High-Resolution Image Synthesis with Latent Diffusion Models》,并与其他社区团队合作开发的一款开源模型。



以上是Stable Diffusion的效果图。有经验、有条件的小伙伴可以去翻阅大佬们的Paper,刚接触AI绘画的零基础小白也可以随我去一步步部署、搭建、复现这篇论文的功能哦!此项目有显卡门槛,建议显存越大越好。
Stable Diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的数据库子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。Latent Diffusion Models通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文本转图片生成能够在10G显存的GPU下运行,并在几秒钟内生成图像,无需预处理和后处理,这确实是速度和质量上的突破。
二、Stable Diffusion环境搭建
1.Anaconda下载与安装
1.Anaconda介绍:Anaconda是开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。总之,它是放实现代码条件的容器!
2.Anaconda下载:Anaconda | The World's Most Popular Data Science Platform
进入官网后如下图所示,点击Download即可开始下载:
下载完成后在文件夹中有一个exe程序文件,双击打开:

3.Anaconda安装:依次点击Next-I agree-All Usrs-Next,然后到如下图片所示:
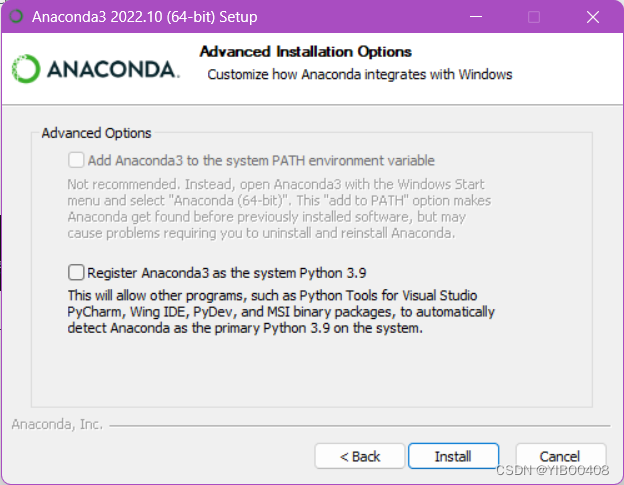
把两个选项都勾选上,这样省去自己去添加环境变量,之后点击Install-Next-Next-Finish就完成安装了。
4.测试Anaconda:按下win+R,输入cmd,打开终端,输入conda有输出即可,输入conda -V可查看Anaconda版本。
至此Anaconda安装完成!底下是一些配置。
5.添加Anaconda镜像:添加镜像源之后底下的安装各种库速度会快很多
打开Anaconda PowerShell Prompt(建议添加桌面快捷方式以后要经常打开):
输入如下代码即可:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes6.继续输入以下代码创建本项目AI绘画的基础环境(其中包含了python,名字可自定):
conda create -n ai-painting python=3.102.Pycharm(IDE)下载与安装
1.Pycharm介绍:PyCharm是一种Python IDE(Integrated Development Environment,集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制。总之它是运行代码的地方啦!
2.Pycharm下载:PyCharm: the Python IDE for Professional Developers by JetBrains
进入官网后如下图所示,点击Download即可开始下载:
选择Community日常学习就已足够:
下载完成后在文件夹中有一个exe程序文件,双击打开:
点击Next-选择路径再点Next-勾选所有选项再点Next-Install-Finish,至此Pycharm安装完成。
3.CUDA、CuDNN下载与安装
1.CUDA、CuDNN介绍:
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用GPU的处理能力,可大幅提升计算性能;
CuDNN (NVIDIA CUDA 深度神经网络库) 是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。
全球的深度学习研究人员和框架开发者都依赖CuDNN 来实现高性能 GPU 加速。借助 CuDNN,研究人员和开发者可以专注于训练神经网络及开发软件应用,而不必花时间进行低层级的 GPU 性能调整。
CuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MxNet、PaddlePaddle、PyTorch 和 TensorFlow。我们接下来就需要用到Pytorch深度学习框架。
2.CUDA下载与安装:
首先需要查看自己的笔记本最高支持CUDA多少,方法是:win+R,输入cmd,在命令行输入
nvidia-smi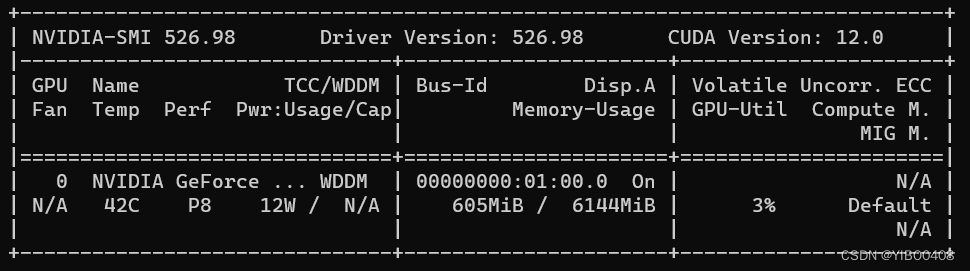
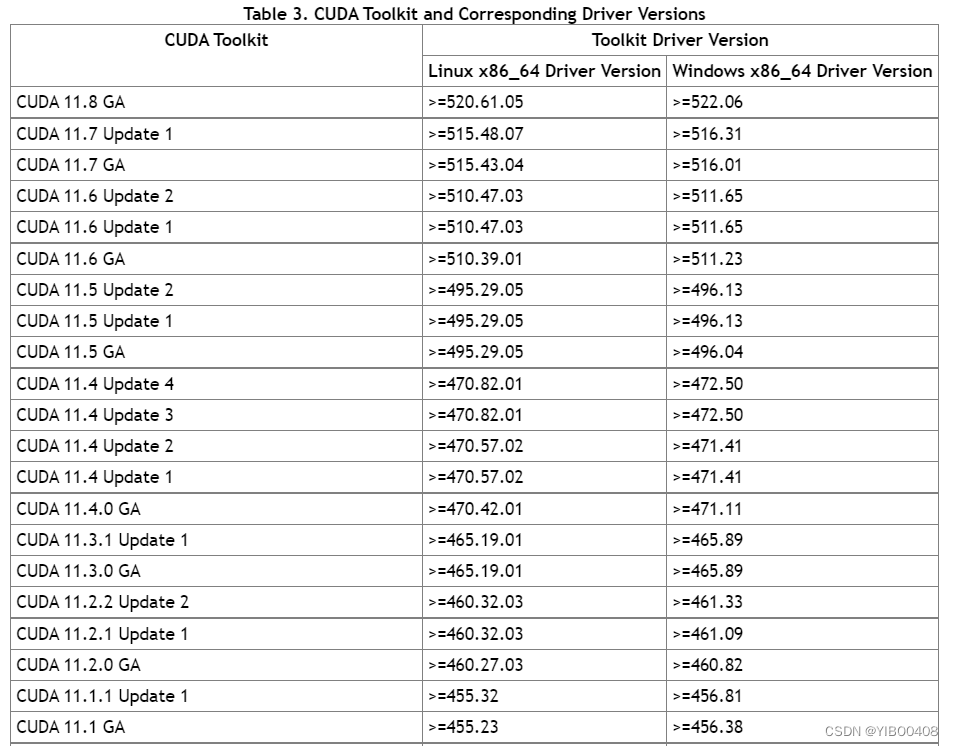
可以看到中间的Driver Version驱动版本以及右上角的CUDA VersionCUDA版本,我最高支持到12.0,而底下的Pytorch官网推荐只支持最新的11.6和11.7,所以我们只需下载其中之一就可,此处我下载的是11.7(前提是你的算力得达到11.7,所以电脑配置不高的小伙伴就不好做了哦),下面可查看驱动版本和CUDA版本匹配情况,各位根据实际情况来。如果达不到最新的CUDA版本,可以去官网搜索下载低等级的,但是能做这个项目的显卡门槛都得3060以上,一般都往最新的去下载就行。
下面我们打开如下网址来下载CUDA11.7:CUDA Toolkit Archive | NVIDIA Developer
此处我选择了第二个CUDA11.7.1版本,点击Windows=>x86-64=>11=>exe(local)(本地离线下载),最后点击Download,这里大家根据自己电脑实际情况来操作,此处我只在win11上完成。
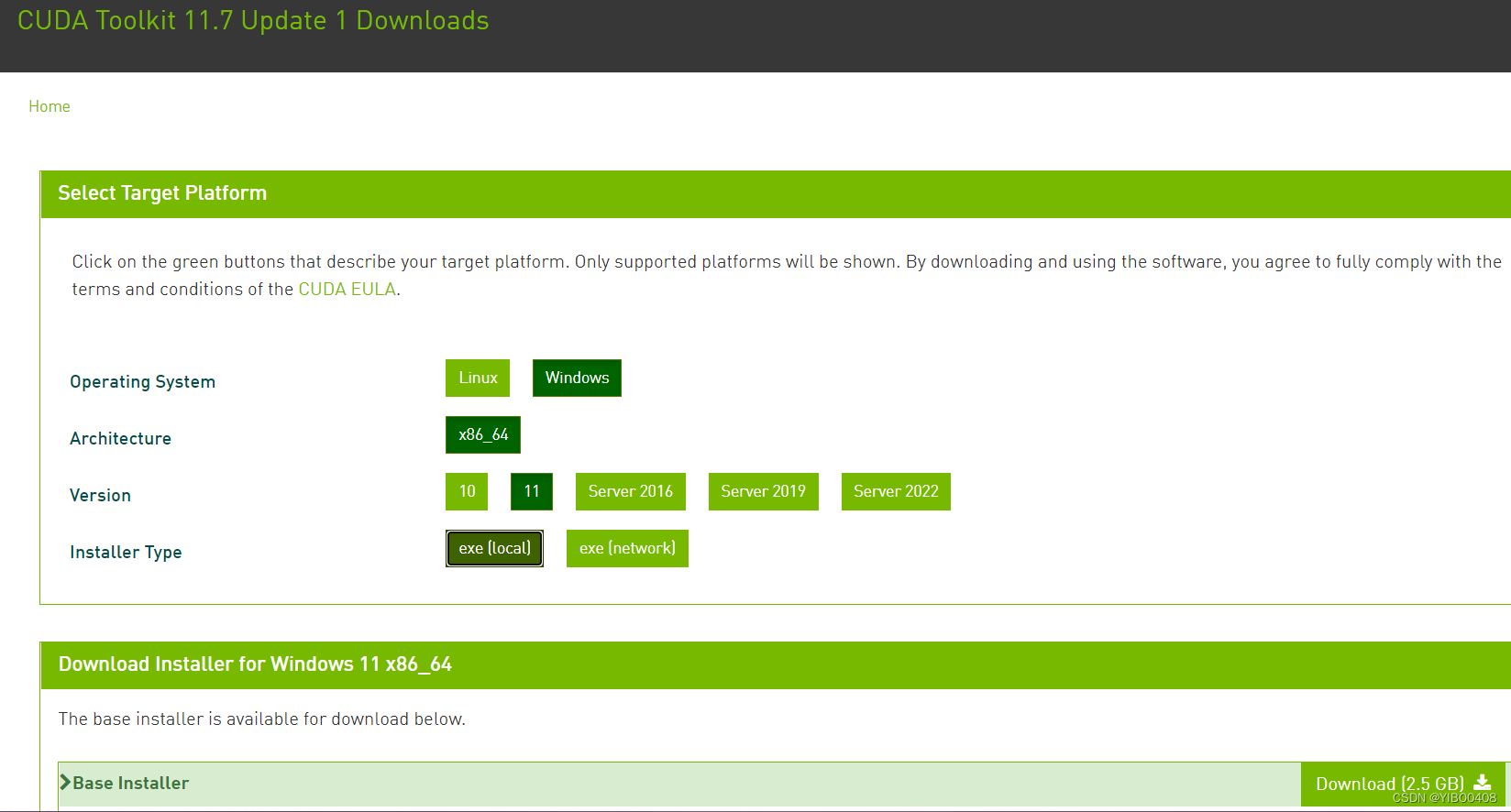

下载完安装CUDA时,首先设置临时解压目录,默认就好,继续往下。
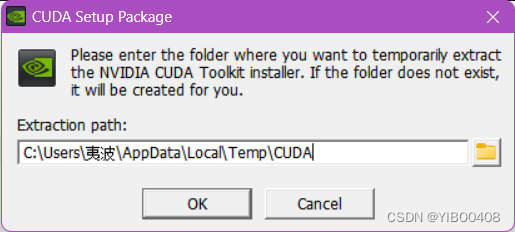
选择自定义安装,自己设置安装目录,可放C盘可放D盘,放D盘的话可以新建一个跟预设一样的路径,看着舒服。
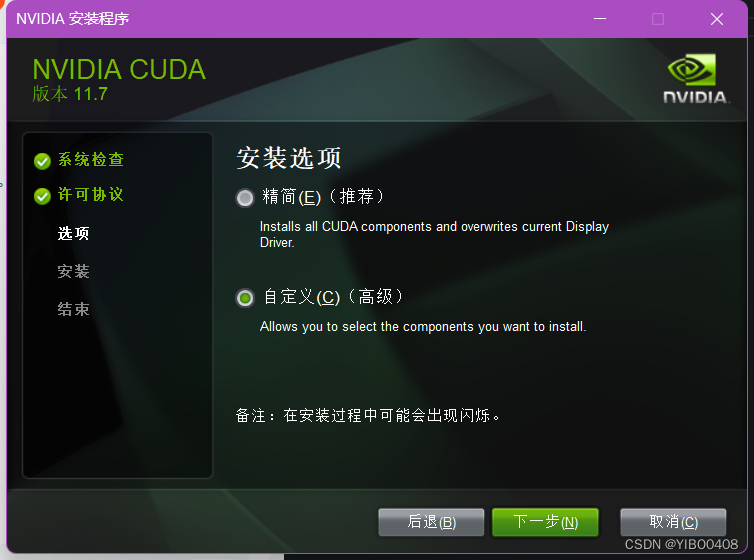
自定义安装选项如下:如需要CUDA的部分就行,然后把VS取消。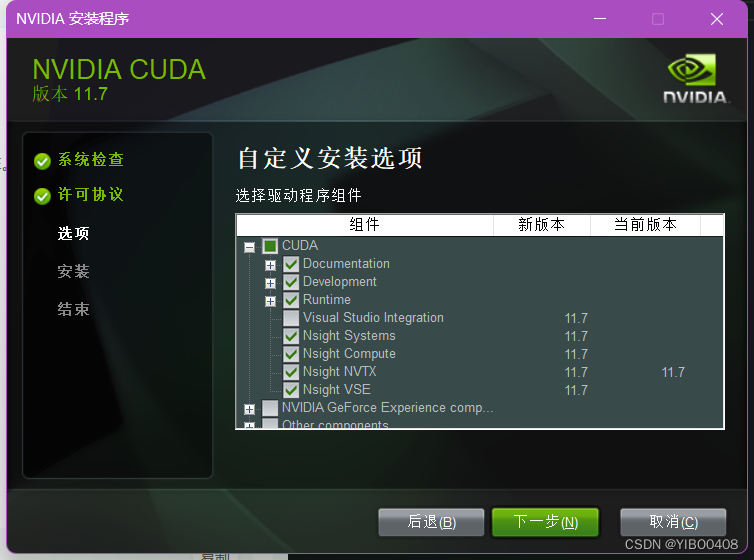
自定义安装位置,我在D盘相同位置新建了个文件夹存放。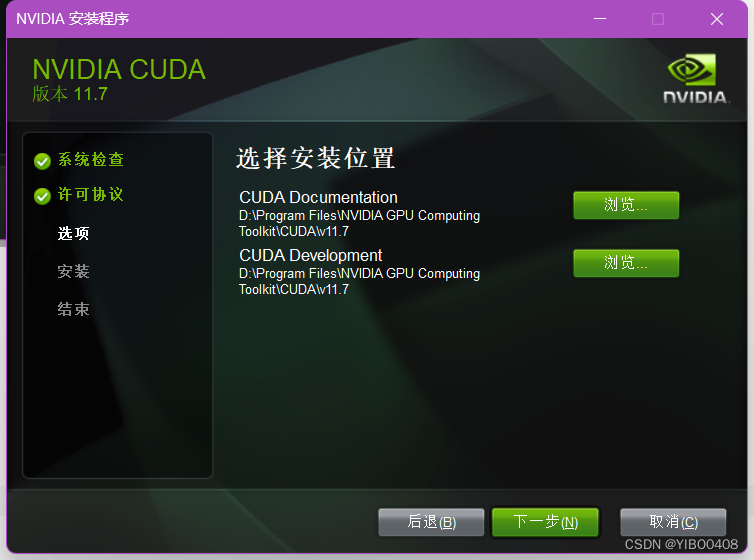
继续往下,到最后CUDA安装完成!
至于环境变量问题,一般是都设置好了,但如果你有之前版本的CUDA环境变量最好删掉,把新安装的优先级往前放。
如何打开并查看系统环境变量:此电脑右击,选择属性,点击中间的高级系统设置,

点击环境变量,
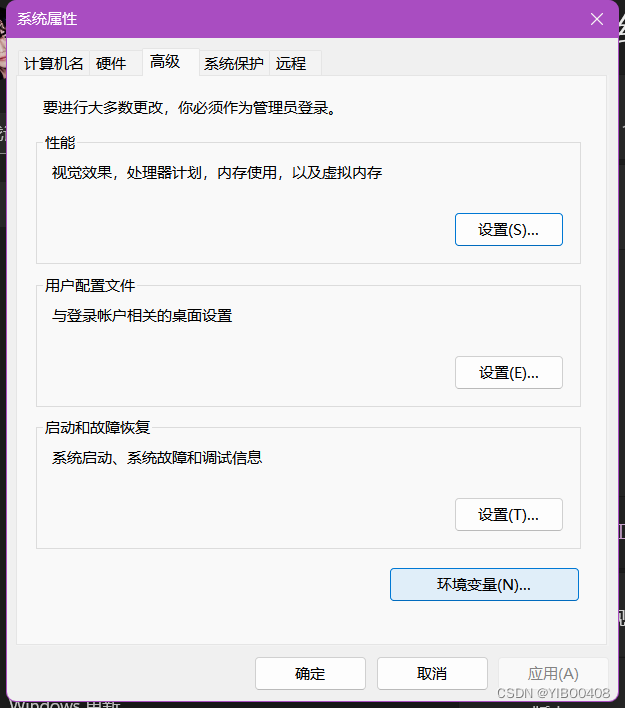
点击系统环境变量,可查看到CUDA_PATH是否为自己新安装的版本。
下面验证是否安装成功:win+R,输入cmd,打开终端,输入:
nvcc -V 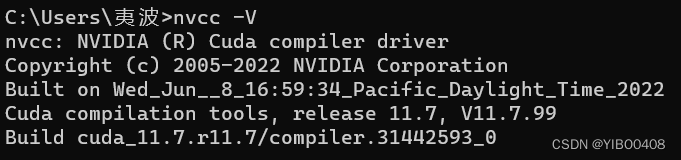
至此,CUDA安装完毕,下面介绍CuDNN的下载与安装。
3.CuDNN下载与配置
下载CuDNN的网址如下:cuDNN Archive | NVIDIA Developer
要想下载CuDNN,首先得注册一下NVIDIA的账号,建议用网易163或者有条件的Gmail邮箱都可,QQ邮箱劝退,可能收不到验证邮件。
验证完邮件会填写相关信息,其中NVIDIA的Organization URL,随便找个URL就可。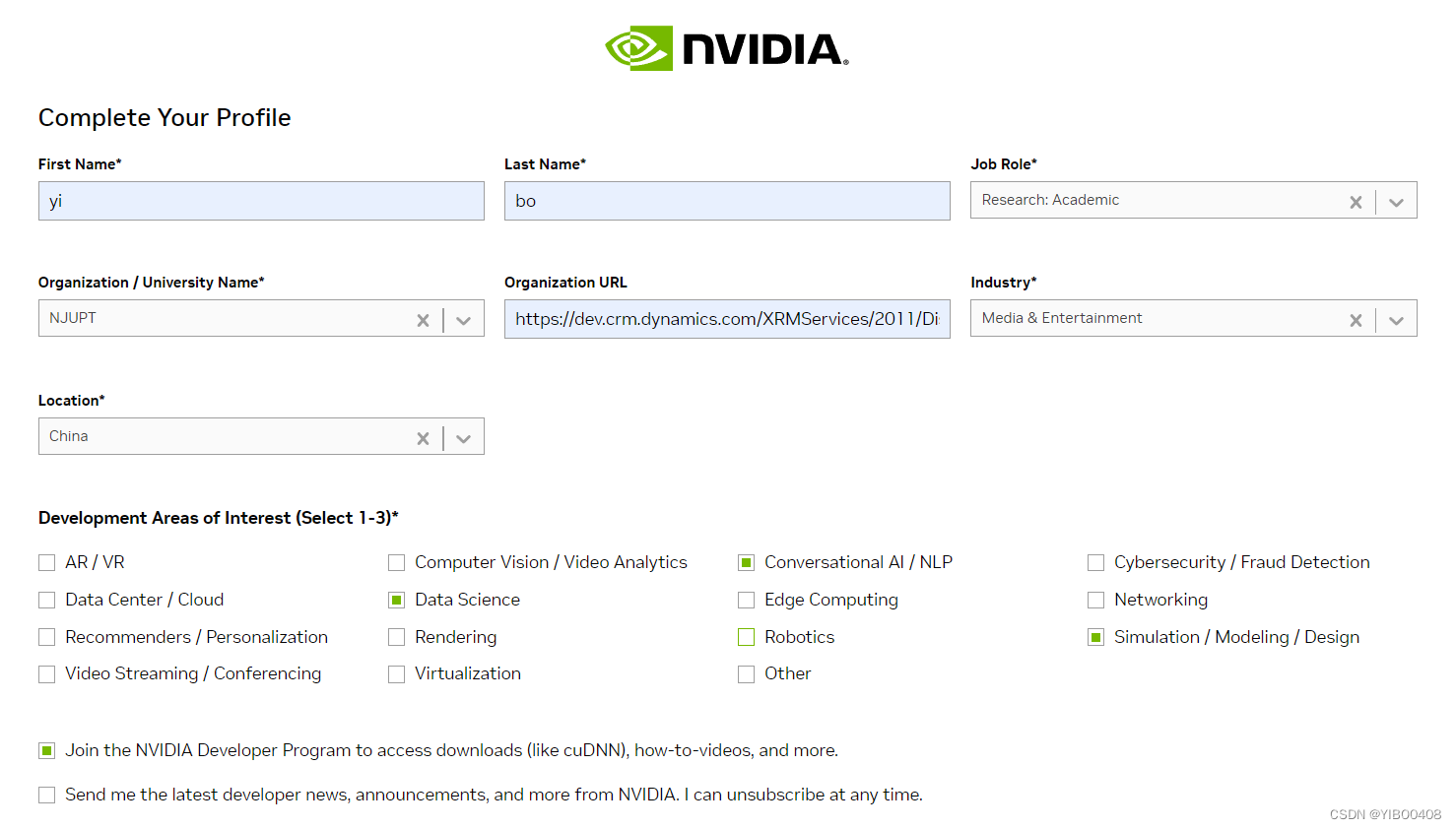
注册完毕,出现CuDNN下载界面,根据提示,选择for CUDA 11.x的版本就可,点击选择Windows版本即可下载,这是一个zip文件。
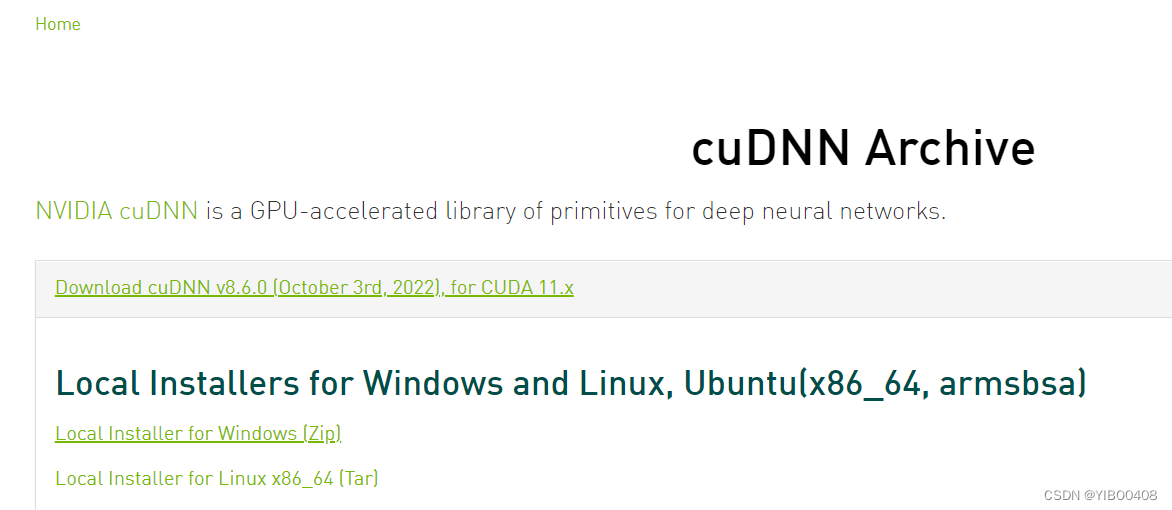
下载解压到D盘,打开可以发现CuDNN并不是一个exe,而是三个配置文件夹,是给CUDA锦上添花的,能更强悍地通过GPU进行高性能加速。
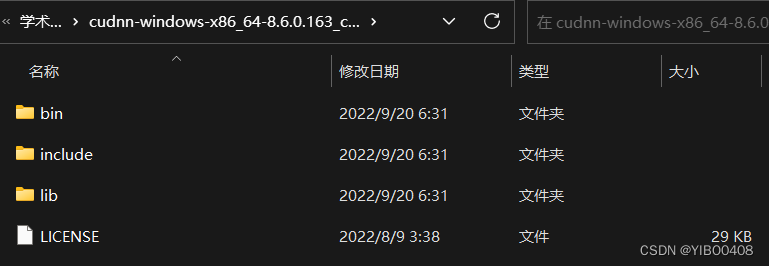
于是,把这三个文件夹复制到CUDA的安装路径的文件夹下:D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7,即可完成CUDA与CuDNN的合体。
检查是否合体成功,需要验证功能,打开如下文件夹:D:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\extras\demo_suite,在文件夹空白处右击,选择在终端打开,输入ba然后迅速TAB(键盘左边),意思就是打开bandwidthTest.exe文件,开始验证。
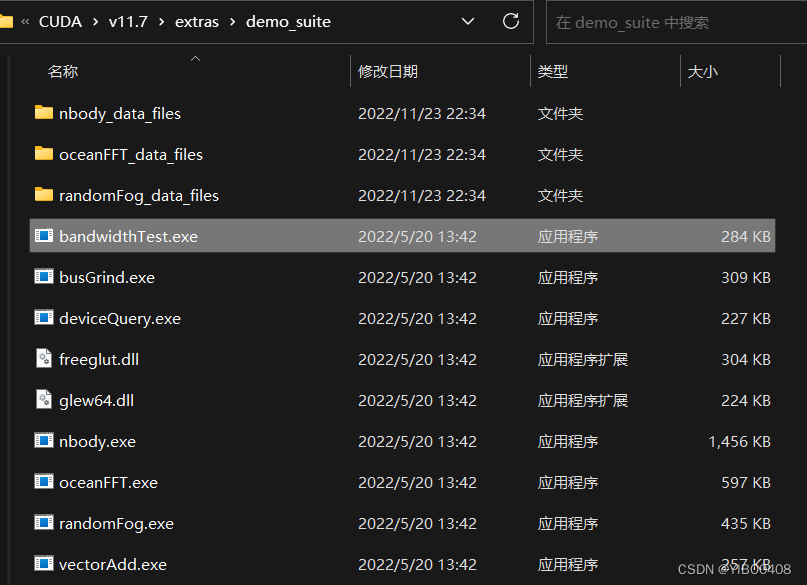
验证如下,如看见Result = PASS,即成功安装。
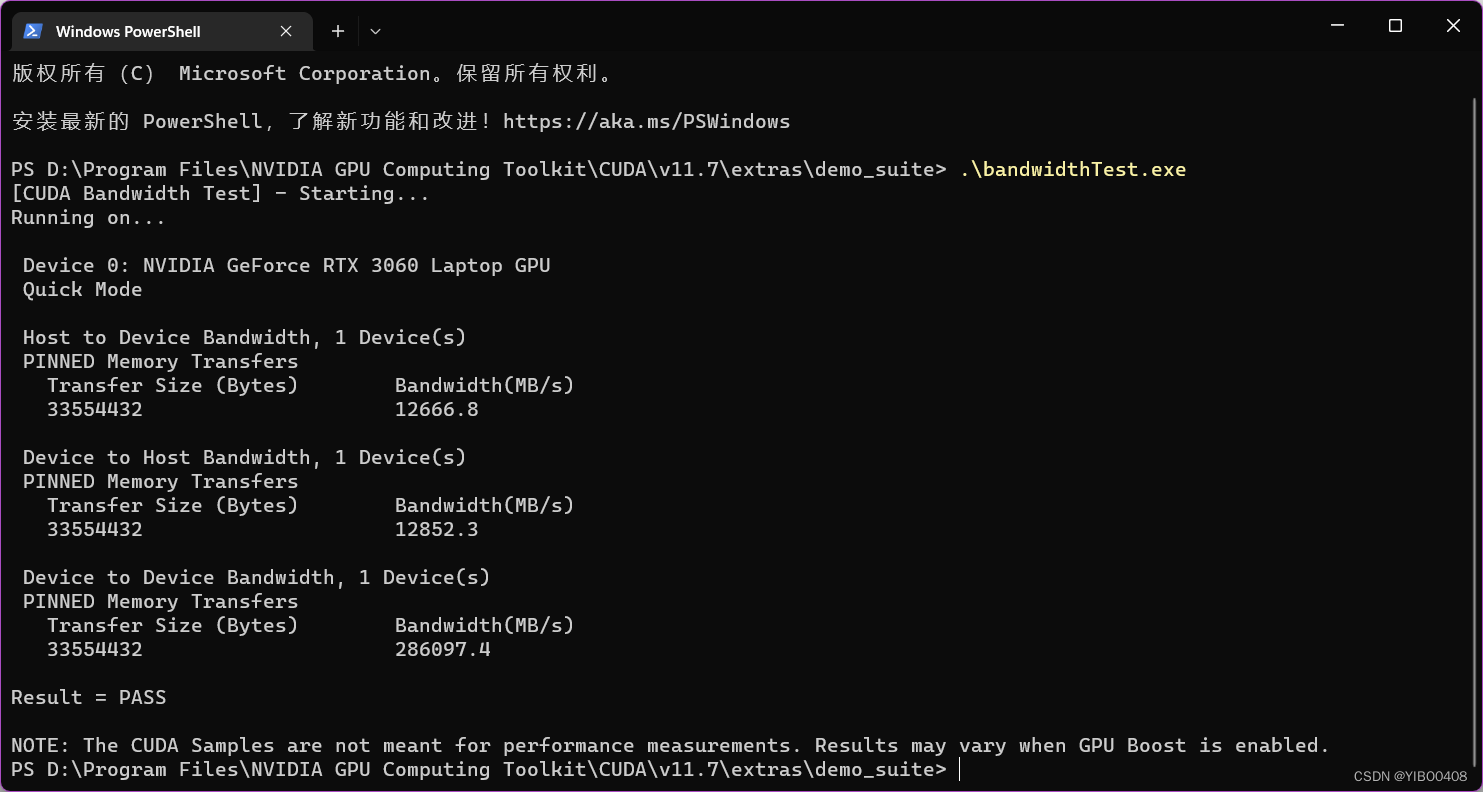
还需验证下deviceQuery.exe文件,运行下PASS即可。
至此,CUDA与CuDNN的安装配置全部完成!
三、Stable Diffusion的本地部署
1.克隆项目到本地
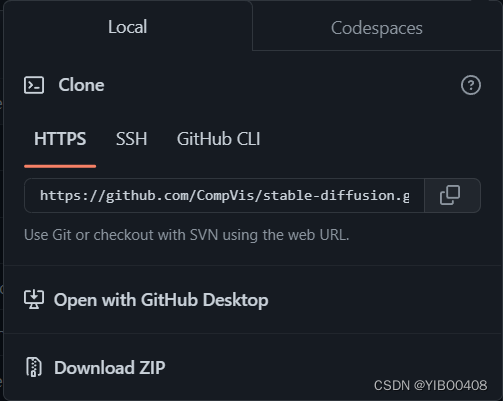
Stable Diffusion项目地址:GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
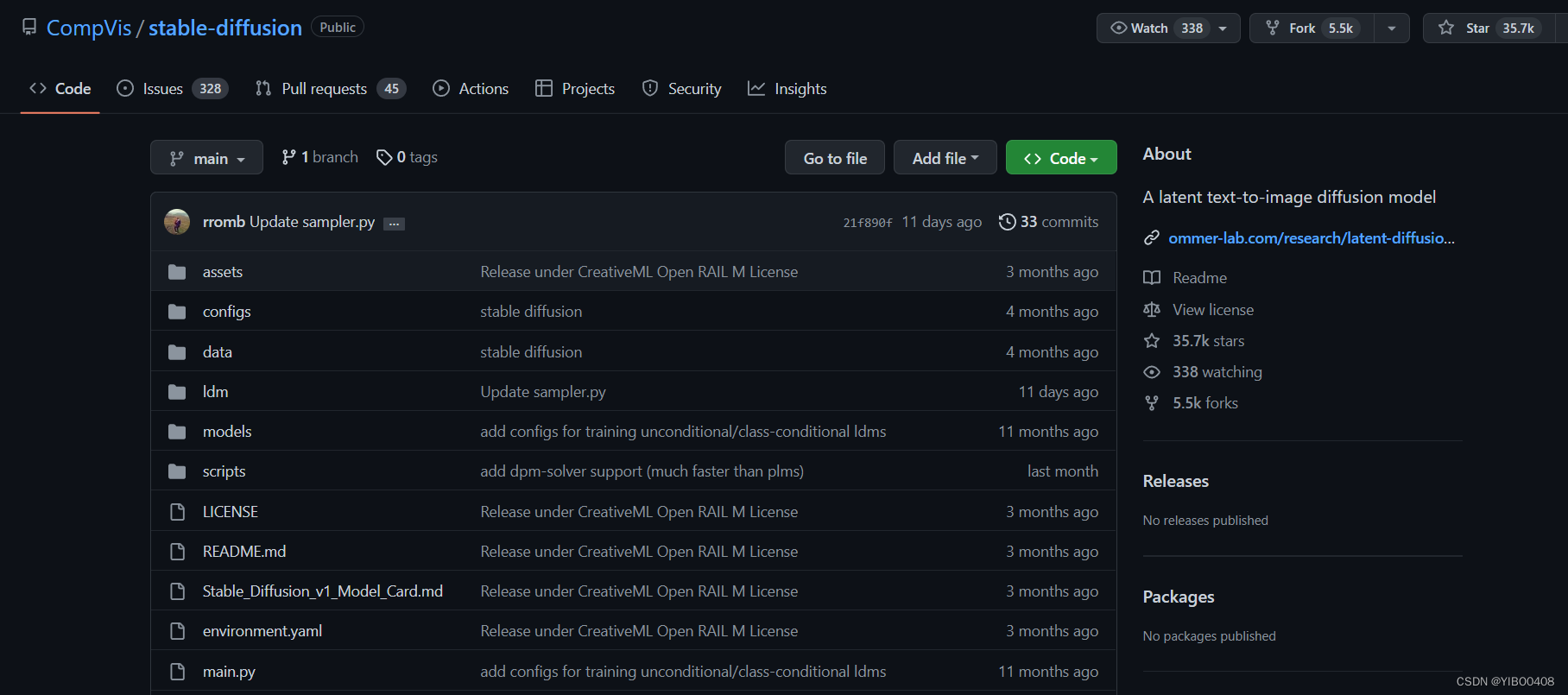
可以选择直接在终端git,但需要下载git相关工具,我选择直接点击如上图的绿色图标,选择Download ZIP即可下载项目压缩包,下载完解压到你的D盘,D盘是我的学术盘,我所有的代码以及配置都存放在D盘里。
2.初始化打开项目
解压后的文件夹可以直接拖到Pycharm图标上打开:

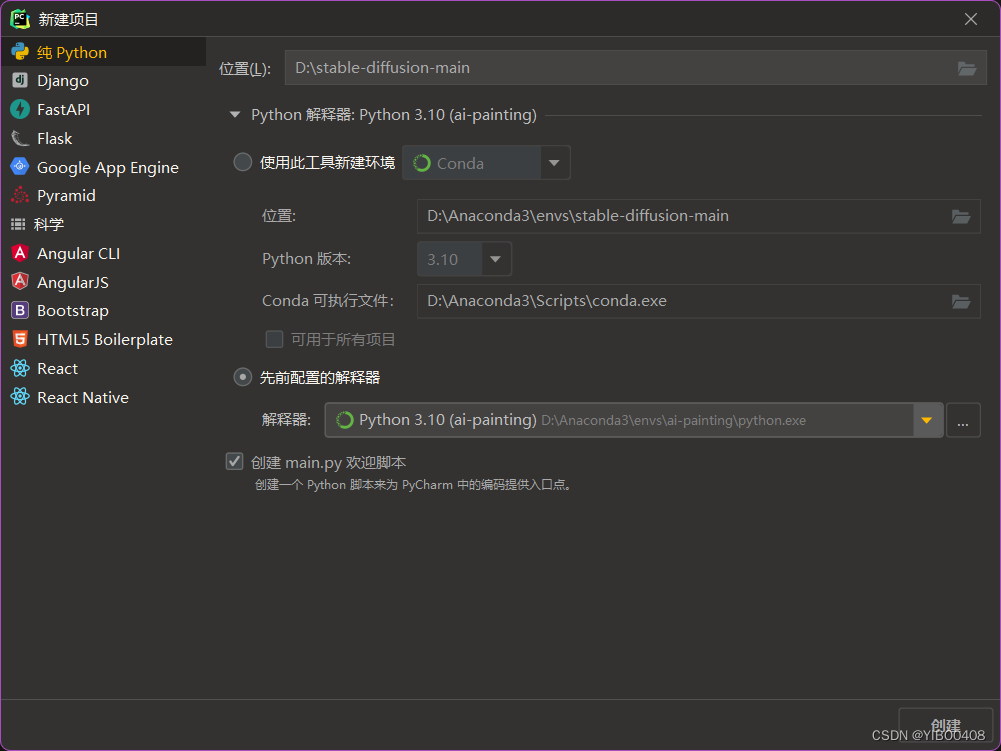
打开之后的第一件事就是配置解释器,因为我们之前已经创建过Anaconda的环境,直接选择先前配置的解释器,选中自己创建的环境即可。
3.安装环境所需库
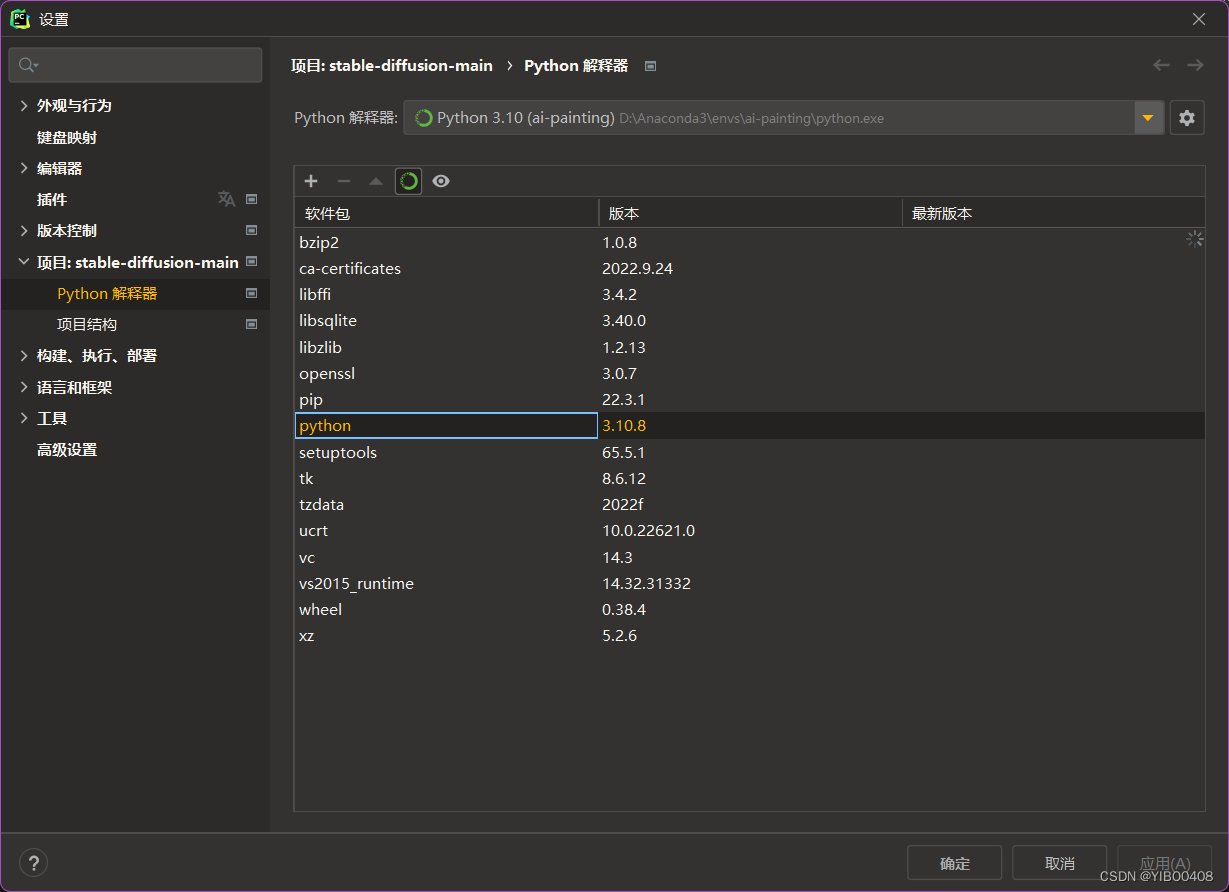
此时我们新创建的解释器里只有于Python相关的最基础的几个库,如下图所示:
我们还要根据项目所需,安装相应的库。可以发现,项目里有一个environment.yaml文件,里面保存着项目作者实现项目所需要的库以及版本,我们可以根据它的版本来一键安装。但是,一键安装有时候会因为网速等问题出现一系列报错失败,所以因为库的数量不多,本人选择单独一个个安装库,并记录版本。
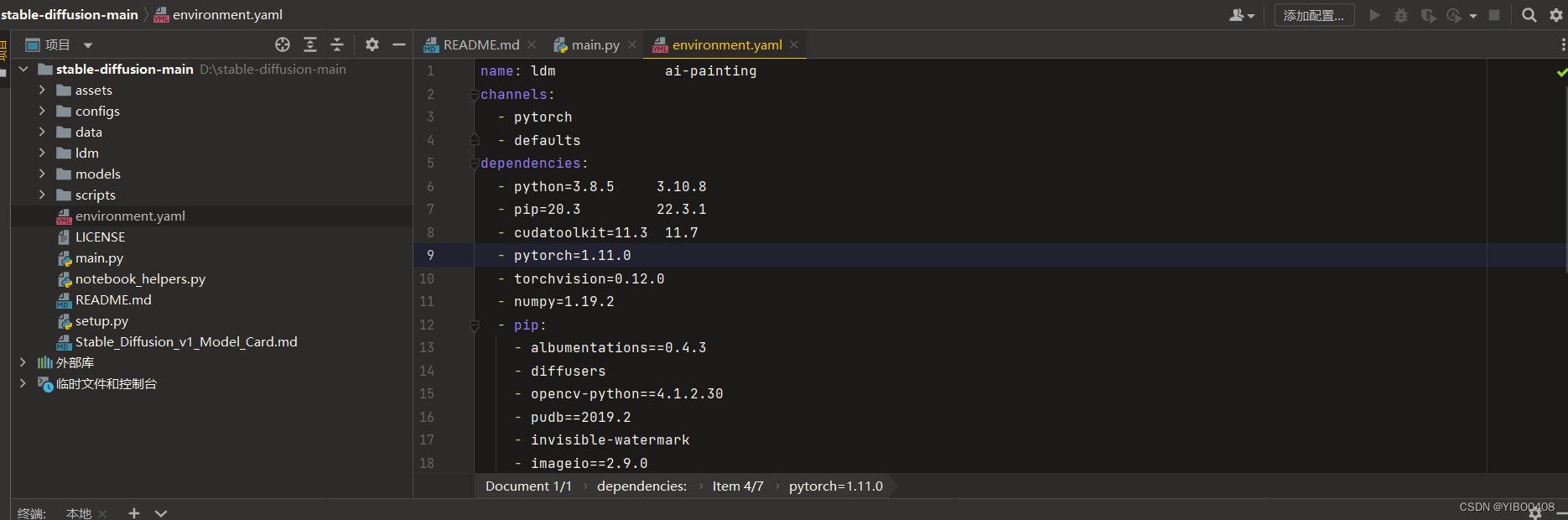
1.numpy库安装:
打开如下Anaconda终端,激活创建的环境:
conda activate ai-painting
底下要安装的库都会安装在这个环境(容器)里,这样一个项目一个环境,很舒服。
执行如下代码安装numpy库:
pip install numpy
再次介绍一下pip工具,是下载python库的工具,但是有的时候会遇到网速问题,可以参考我以前的博客pip配置镜像源。国内常用pip镜像源地址及使用+永久修改_YIBO0408的博客-CSDN博客_pip 资源
2.Pytorch下载与安装:
Pytorch下载踩坑特别多,比如根据官网指令下载没有反应、网速慢等问题,在此本人选择如下方法可避坑。
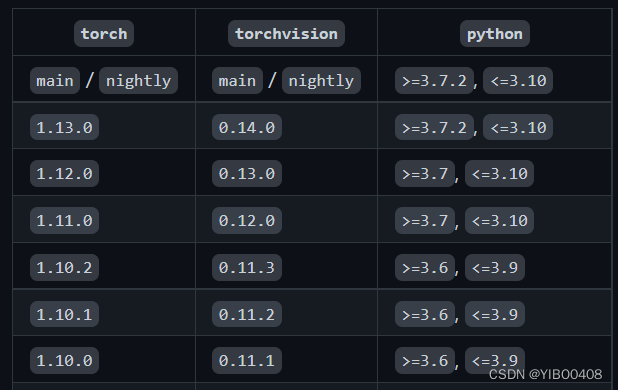
首先去官方版本匹配网址查看版本https://github.com/pytorch/vision/blob/main/README.rst
下图是torch与torchvision以及python版本的对应关系:
https://github.com/pytorch/audio
下图是torch与torchaudio的对应关系:

从上图可总结出我们要下载的torch、torchvision、torchaudio版本分别为:torch 1.13.0, torchaudio 0.13.0, torchvison 0.14.0。torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型;torchaudio 支持以 wav 和 mp3 格式加载声音文件,有加载声音、数据增强、特征提取等功能。此项目对于torchaudio可下载可不下载,但总体完整的pytorch是需要的。
由于在线下载的不确定性,我们选择离线下载,速度快而且下载安装简单。以下是torch离线安装包下载地址:
https://download.pytorch.org/whl/torch_stable.html
我们找到以下三个whl文件,文件名cu117代表CUDA11.7版本,cp310代表python3.10版本,win_amd86_64代表Windows版本。

下载完需要安装,同样需要在环境ai-painting里的终端指令行输入指令,打开Anaconda Powershell Prompt,激活ai-painting环境,此时需要cd(切换)到下载的目录下,我是默认下载到Downloads里的,于是直接cd Downloads即可。

此处教一下怎么切盘,切到D盘:
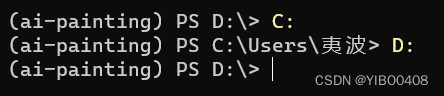
返回上一级:(中间有空格)

于是,安装三个torch的whl文件指令为:
pip install .\torch-1.13.0+cu117-cp310-cp310-win_amd64.whl
pip install .\torchvision-0.14.0+cu117-cp310-cp310-win_amd64.whl
pip install .\torchaudio-0.13.0+cu117-cp310-cp310-win_amd64.whl
至此Pytorch框架全部安装完毕!
最后来验证一下Pytorch是否成功安装:
python
import torch
torch.cuda.is_available()
如果结果是True,代表安装完毕啦!
3.其他库的安装:
大部分库只需要如下一键pip install就好了,前提是配置好pip源,这样底下下载就不会卡住了,方法是提前在指令行输入如下:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple之后可以输入以下指令一键安装。
pip install albumentations diffusers opencv-python pudb invisible-watermark imageio imageio-ffmpeg pytorch-lightning omegaconf test-tube streamlit einops torch-fidelity transformers torchmetrics kornia我自己一个个试完发现无阻碍无错误,所以大家也可以直接根据environment.yaml文件来一键配置环境。要cd到项目目录下(因为下面还要把另外两个项目克隆配置到本项目目录下):

一键配置指令如下:
conda env create -f environment.yaml最后还需把另外两个项目克隆到本地项目新建的src工作目录中,运行指令如下:
pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformerspip install -e git+https://github.com/openai/CLIP.git@main#egg=clip 此处两个指令需要kexue上网才能成功,想了解可私信我。全部配置完项目目录如下:
可以发现新建了src目录,目录下有clip和taming-transformers两个文件夹。
4.模型的下载:
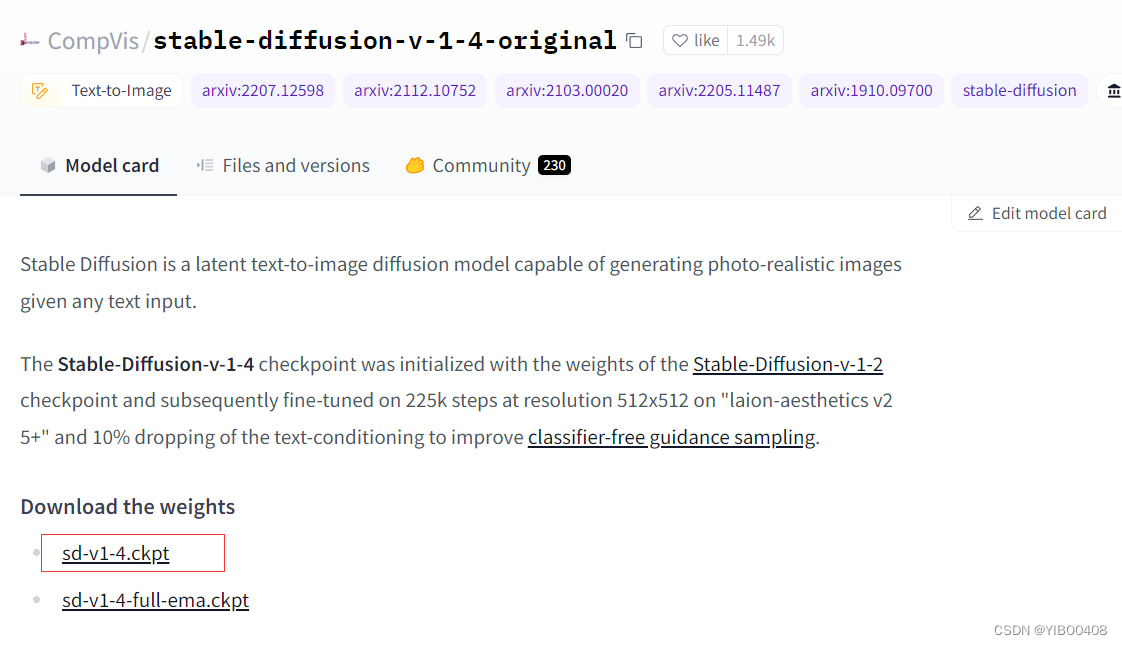
模型下载地址:CompVis (CompVis)
这里我们下载的版本是stable-diffusion-v-1-4-original(也可下载其他版本),点击下载权重:sd-v1-4.ckpt,此处同样需要kexue上网才可下载,如需要模型下载ckpt文件,本人已存百度网盘,可私信自取。
接下来,在项目目录models/ldm下手动创建stable-diffusion-v1文件夹,用来存放下载好的权重文件,即需要把下载文件夹里的sd-v1-4.ckpt文件改名为model.ckpt,然后粘贴到手动创建的stable-diffusion-v1文件夹下即可。(注意文件名遵照原作者的名称来,否则下面运行代码会找不到文件)操作完项目目录如下图所示。
权重文件介绍:Stable-Diffusion-v-1-4 checkpoint使用 Stable-Diffusion-v-1-2 checkpoint的权重进行初始化,随后在“laion-aesthetics v25+”分辨率为 512x512 的 225k steps上进行微调,下降 10% 改进无分类器指导抽样的文本调节。
至此,调试代码前的所有准备工作完成!
4.运行代码以及效果展示
1.文本转图片(Txt To Image(Txt2Img)):
打开终端,激活环境,cd到项目目录,运行如下官方基础代码:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
BUG解决:
(1)ModuleNotFoundError: No module named 'ldm'
解决方式:在txt2img.py第二行添加如下代码,旨在获取当前工作目录加入路径。
sys.path.append(os.getcwd())(2)在huggingface_hub下载文件时出现使用警告如下:
UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\XX\.cache\huggingface\hub. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.
解决方式:如果想从Windows11的基于符号链接的缓存系统中受益,需要激活开发者模式或以管理员身份运行Python。
激活开发者模式:打开设置-->点击隐私与安全性-->点击开发者选项-->开发人员模式-开
以管理员身份运行Python:右击Anaconda Powershell Prompt (Anaconda3)终端-->点击以管理员身份运行
(3)torch.cuda.OutOfMemoryError: CUDA out of memory.
解决方式:换大显存的显卡,我的是6G显存的3060笔记本GPU,按照官方基础代码运行会出现如上情况,我们需要调整batch size,也就是后缀说明里的--n_samples,设置其值为1;还需要把生成图片的尺寸大小(默认512*512)改为256*256。以上是我在github问题里搜集到的,亲测无效。
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms --n_samples 1 --H 256 --W 256
以上对于我的显存依旧不够,大家有比我更好的条件的可以试试以上代码。适当地增加batch size(1,2,4,8,16,32...)以及图片尺寸大小(512*512...)
经过各种资料调研,只为降低显存占用,
一种有效的解决方式(对于我的6G笔记本GPU显存):打开pycharm,打开txt2img.py文件,找到如下代码,添加一行:
model.half()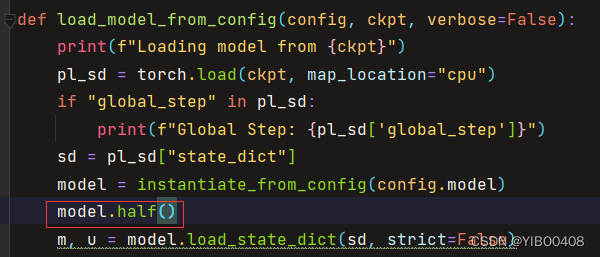
它的原理是:保存模型时,调用model.half(),将算子存储为fp16(半精度)格式,低精度带来了性能和功耗的优势,但需要解决量化误差问题。这是Pytorch框架提供的一个方便好用的trick:开启半精度。直接可以加快运行速度、减少GPU占用,并且只有不明显的accuracy损失。对于本项目误差图片差别属实不大,本人认为可忽略。
添加完一行代码,后输入如下指令可实现跑图:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms --n_samples 1 --H 512 --W 512 --n_iter 50
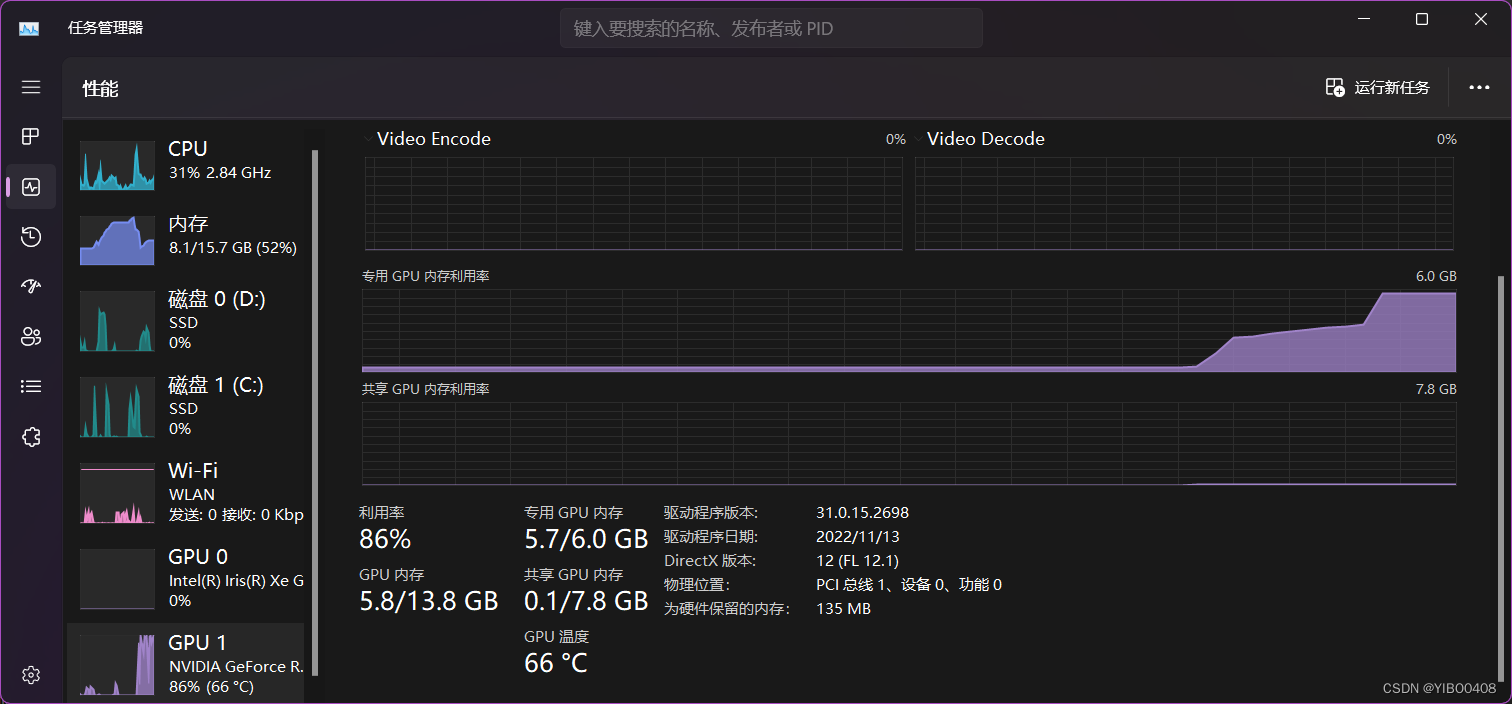
以上是显存使用情况,可以看出刚好快占满显存。
prompt可以自定义一段英文或者关键单词以英文逗号分开,尺寸可根据显卡自行设置512*512,生成图片50张。下图可以看出效果还是很不错的。
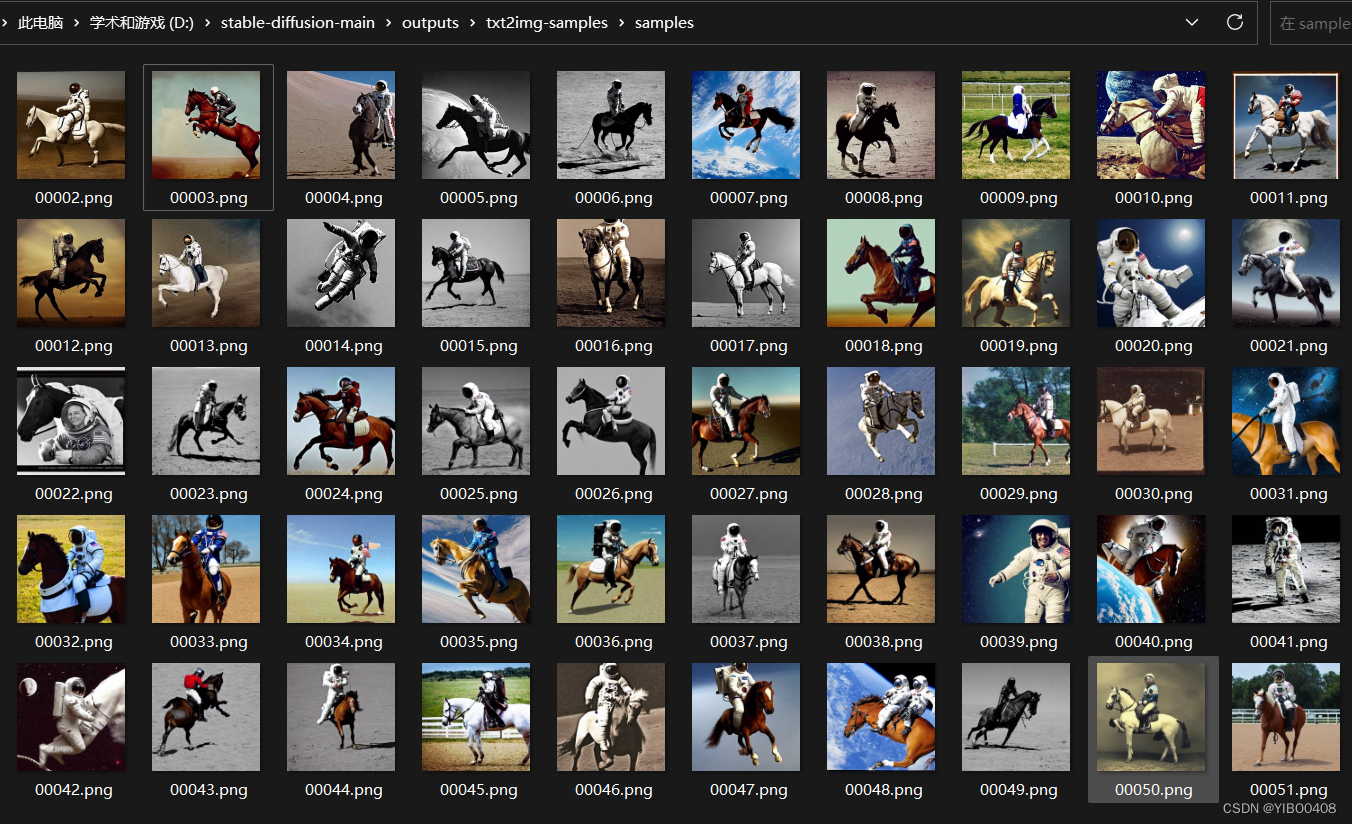
以下是txt2img.py的使用后缀说明:
usage: txt2img.py
optional arguments:
-h, --help show this help message and exit 显示此帮助信息并退出
--prompt [PROMPT] the prompt to render 要渲染的提示信息
--outdir [OUTDIR] dir to write results to 渲染结果路径
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples 不保存网格,仅保存单个样本,在评估大量样品时很有用
--skip_save do not save individual samples. For speed measurements. 不保存单个样本,用于速度测量。
--ddim_steps DDIM_STEPS
number of ddim sampling steps ddim采样的steps数量
--plms use plms sampling 使用plms采样
--laion400m uses the LAION400M model 使用LAION400M模型
--fixed_code if enabled, uses the same starting code across samples 如果支持,跨样本使用相同的起始代码
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space 图片高度
--W W image width, in pixel space 图片宽度
--C C latent channels 潜在通道
--f F downsampling factor 下采样因子
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size 每个给定prompt要生成多少样本。又名batch size(批大小)
--n_rows N_ROWS rows in the grid (default: n_samples) 网格中的行(默认值:n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file 如果指定,从该文件加载提示
--config CONFIG path to config which constructs model 构造模型的配置路径
--ckpt CKPT path to checkpoint of model 模型checkpoint的路径
--seed SEED the seed (for reproducible sampling) 种子(用于可重复采样)
--precision {full,autocast}
evaluate at this precision 以此精度进行评估2.图片转图片(Image To Image(Img2Img)):
以下是官方基础代码,同样我的显卡跑不动:
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
strength是一个介于 0.0 和 1.0 之间的值,它控制添加到输入图像的噪声量。 接近 1.0 的值允许很多变化,但也会产生与输入在语义上不一致的图像。
以下是img2img.py的使用后缀说明:
usage:img2img.py
options:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--init-img [INIT_IMG]
path to the input image
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save indiviual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--fixed_code if enabled, uses the same starting code across all samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--C C latent channels
--f F downsampling factor, most often 8 or 16
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--strength STRENGTH strength for noising/unnoising. 1.0 corresponds to full destruction of information in init image
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
目前原作者的开源代码并没有对GPU显存消耗量大的问题进行优化,经搜索有另外的分支,另一个作者对项目进行了优化,具体地址如下:https://github.com/basujindal/stable-diffusion
大家可去自行下载,复制粘贴相关模型去model文件夹就行,出现bug,上述已经提及并解决,其他都一样。他把显存消耗降到了一半,经检测我的降到3GB,而效果可以说是同样的好。这个项目你可以用docker也提供了GUI图形界面,如果你不想在交互式终端执行,可以用GUI方便操作。
要想使用GUI,需要下载一个库:
pip install gradio要想运行Txt2Img:
python optimizedSD/txt2img_gradio.py要想运行Img2Img:
python optimizedSD/img2img_gradio.py出现一个地址,点击地址即可进入GUI:
以下是GUI界面,各种参数可以方便在上面调节:
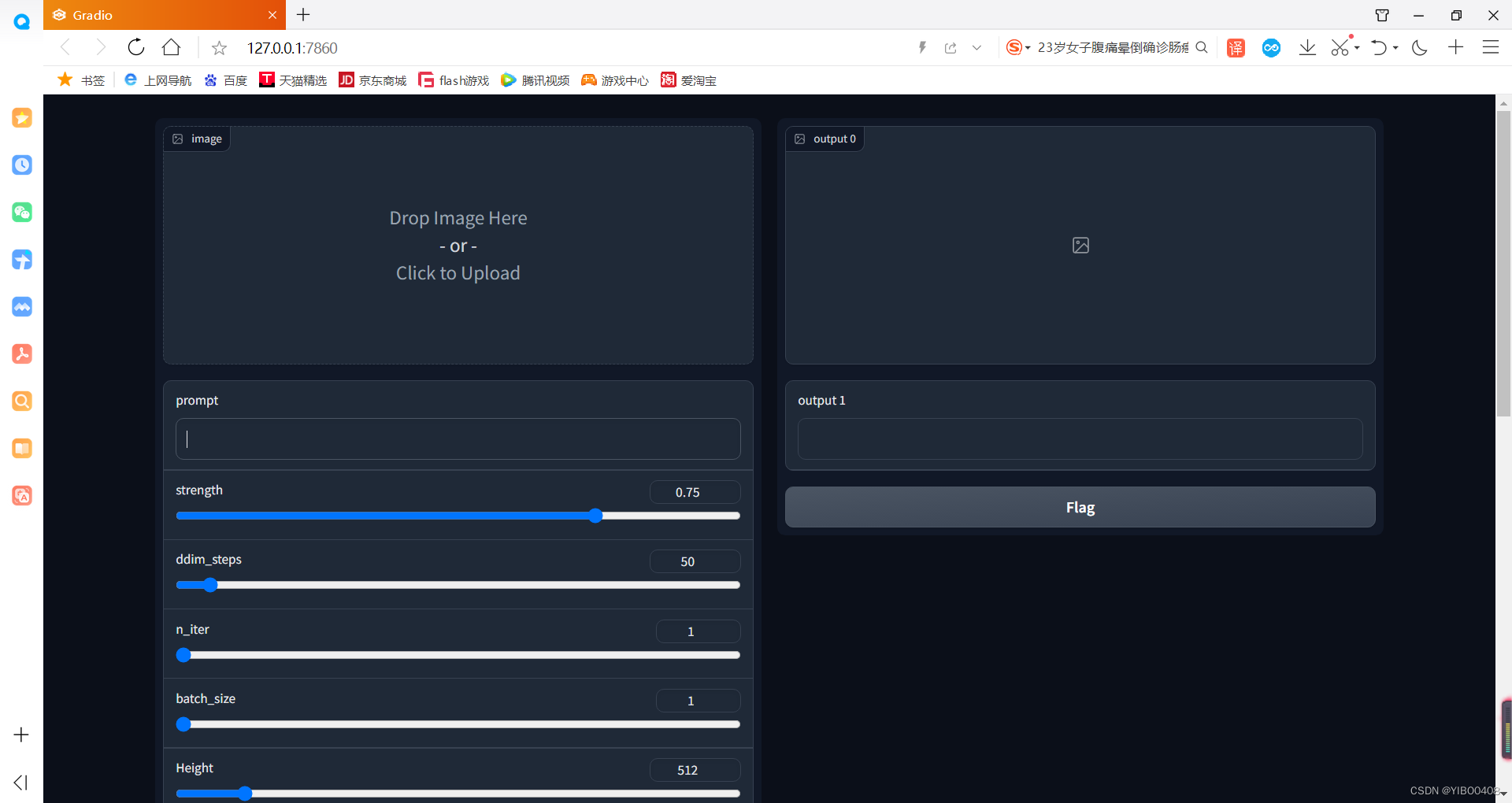
以下是我根据我的证件照跑出来的图,可以看到效果不错,与现在市场上的AI绘画程序效果相当。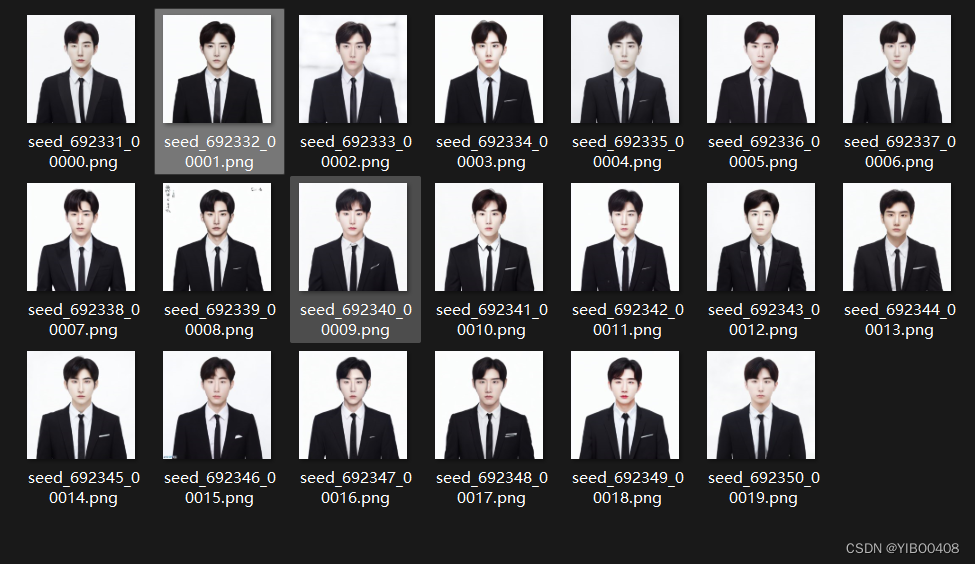
至此,AI绘画 Stable Diffusion本地部署以及初步功能实现完成!制作不易,望喜欢!
最后放一张俺女朋友的初中证件照,咱就是说妥妥的二次元美少女哇!!!