谷歌提出的衡量 DevOps 质量的 DORA 指标让 MTTR(平均恢复时间) 名声大振。在本文中,你将了解到 MTTR 的作用、为什么它对行业研究很有用、你可能被它误导的原因以及如何避免 MTTR 产生的弊端。
MTTR 究竟是在测量什么?
MTTR 指平均恢复时间,既是 Mean Time to Recovery,有时也是 Mean Time to Restore。它是指在发生故障后使系统恢复运行所需的时间,它是 DORA 指标的一部分,目前已经成为软件交付性能的标准。
当你的所有 DORA 指标都表现良好,那么就会拥有快速交付的高质量软件、更满意的员工,从而在所处的行业中取得竞争优势。
如何计算 MTTR
收集 MTTR 需要收集每个故障从开始到结束的持续时间,然后将这些时间相加,并用总数除以数量。一些团队会对所有事件进行排序,并选择中间值来计算恢复时间的中位数。
软件交付过程会影响恢复时间,尤其是:
- 软件架构
- 文档
- 可观测性
- 部署流水线性能
当你可以快速恢复,事件的影响就会降低,客户也会更满意。因此,企业应该检查和调整流程以快速恢复并降低风险。
为什么 MTTR 对行业研究很有用?
DevOps 研究和评估(DORA)将调查作为研究方法的一部分。需要各类数据和性能水平不同的企业对问题进行回答。DORA quick check 将 MTTR 问题表述为:
对于您开发的主要应用程序或服务,当发生影响用户的服务事件或故障(例如,计划外中断、服务受损)时,通常需要多长时间才能恢复服务?
- 超过6个月
- 1-6个月之间
- 1周到1个月之间
- 1天到1周之间
- 小于1天
- 小于1个小时
大多数从事软件交付工作的人对故障持续时间都有大概的感觉,因此在调查中使用宽泛的选项可以让人们很容易选择答案。研究人员利用这些信息来寻找数据中的性能组,他们还寻找各种实践之间的关系以及对业务成果的影响,并利用这些发现搭建 DevOps 结构方程模型。
为什么 MTTR 数据可能误导你的团队?
虽然 MTTR 在研究中对性能组有帮助,但这并不是你在团队中使用故障信息的方式。你应该利用这些信息从服务中断中学习,并改进今后的处理方式。最终目标并不是与其他团队或组织进行攀比。
如果要持续优化软件开发和交付流程,只关注平均数可能忽略了一些重要信号。因此需要更细化的信息来了解故障处理的情况,并找到其原因。
Verica 事件数据库(VOID)包含了由近600个组织共享的超过10000个事件,他们在 VOID 报告中分析了这些事件。在2022年的报告中对 MTTR 做出如下评论:
MTTR 不是衡量复杂软件系统可靠性的可行指标,原因有很多,其中突出的原因是其存在潜在的差异性。
当数据量很大时,平均数所带来的差异性会变得平缓,但一般而言企业的故障频率不太可能会达到每月数千起(即在这个数量级才使平均数有效)。如果事件数量较少,平均数则成为一个不稳定的指标。甚至尽管在事件管理方面有所改进,但平均数依旧在增加。
VOID 数据库还发现,大多数事件在2小时内得到解决,但存在一些长尾数据导致平均值被推高或推低,进而无法代表客户看待系统可靠性的方式。
组织可以通过排除异常值来消除这种差异性,但那样就会隐藏一些有价值的信息。因此需要一个更好的方法使用这些数据来改善整个流程。
恢复时长的用武之地
与其把事件恢复时间压缩成一个平均数,不如把每个持续时间绘制在图表上。使用散点图或箱线图(Box-and-whisker chart),在不失真实性的情况下将持续时间可视化。这可以显示趋势和异常值,这比平均数更有价值。
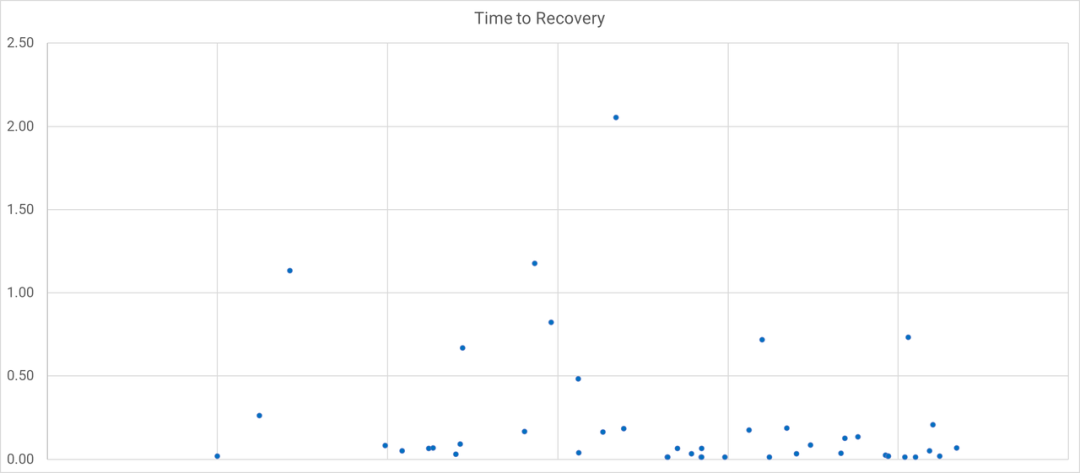
你现在可以清晰地了解修复时长的趋势,看看是否随着时间的推移而改善。还可以识别出异常值,并充分讨论如何更好地处理它们,进而利用它们来改善事件管理和系统稳定性。
如果事件需要代码修复,恢复时间取决于部署流水线的性能。能够快速、安全地部署软件新版本也有助于进行事件管理。另外,引入监控和告警工具有助于帮助企业在影响客户之前发现问题。
明确事件的定义
要获取大部分事件持续时间的数据,你需要对此有统一的定义:
- 什么是事件
- 什么是开始时间
- 什么是结束时间
对于事件,企业内部需要有一个清晰、一致的定义。它应该包括当系统可以优雅地处理一个故障时,组织是否将其算作一个事件。例如,团队可以认为只有对客户产生影响的故障才是事件。
对于开始时间和结束时间也是一样的。是在导致事件发生的条件首次出现时开始计时,还是在问题对客户可见时开始计时?根据定义,甚至可能出现负的事件持续时间,即在故障影响到客户之前就解决了它。
就事件的定义和如何衡量其持续时间达成一致,使你的衡量标准更具可比性。当长期使用 DORA 指标时,它们可能不再能激发你进行下一步改进。你可以用 SPACE 框架设计一个新的衡量系统。
使用 SPACE 框架来衡量事件响应
你可以通过 SPACE 框架来全面了解事件响应和管理,其将测量结果分为5个类别:
- 满意度和幸福感(Satisfaction and wellbeing)
- 表现(Performance)
- 活跃度(Activity)
- 沟通与协作(Communication and collaboration)
- 效率与流程(Efficiency and flow)
企业不必一次性采用所有指标。SPACE 框架建议至少在3个维度上进行测量,如果能涵盖个人、团队和系统层面则更好。最终目标是建议一套合理的测量方法来帮助企业改进流程。
满意度和幸福感
定性调查在这里最有效,可以调查事件管理者,看他们对事件发生后恢复的满意程度:
- 事件管理流程
- On-call 排期
- 在事件发生期间升级或访问专家以提供帮助的难易程度
还可以去查看相关数据以确定 On-call 排期的合理性:
- 当地时间几点电话响起
表现
使用以下指标可以衡量事件管理表现:
- 系统是否按照其可靠性目标执行
- 事故条件和察觉到事故发生之前的时长
- 解决事故所需的时间
活跃度
事件活跃度并不仅仅是事件数量,其他指标也可以纳入参考。大部分数据其实已经在你的现有系统之中:
- 监控工具发出的告警数量
- 事件发生的数量
- 同时发生事件的数量
沟通与协作
信息透明对事件管理至关重要。你应该把这个维度纳入事件测量策略中。拥有高质量的沟通将减少解决故障所需的时间,可以衡量以下指标:
- 每个事件所牵涉的人员数量
- 每个事件涉及多少个不同的团队
- 为处理一个事件建群的数量
- 查看事件报告的次数(或给予积极评价,或在其他事件中提到它)
效率及流程
当采用效率和流程的指标时,就会发现系统中的浪费。如果反复“踢皮球”,那么处理事件的进度就会停滞不前,解决时间更长。以下指标可以帮你发现瘟疫:
- 重新分配事件的频率
- 每个事件尝试缓解的次数
SPACE 框架总结
当需要获得各种洞察并改进系统时,团队应该自由构建并根据实际情况调整指标。企业可能会发现从满意度、沟通和效率这3类指标开始是有帮助的,因为通过测量这些指标并对相关情况进行优化会带来立竿见影的效果。
如果你已经对客户进行调查,不妨问问他们如何为你的系统可靠性评分。
SPACE 框架提供了一种构建衡量体系的方法,它可以直接对事件管理产生影响。
不囿于数字,解决问题才是硬道理
衡量相关指标可以通过明确的数据来帮助团队做出调整。如果没有数字,可能会把一个实际发生很频繁的事件当作一次性事件处理。
尽管数字发挥了作用,但它们只能告诉你问题所在,而无法解决它。因此,不要囿于数字,充分利用事件复盘和 review 来研究如何优化企业中的事件管理。
数字并不能推动持续改进,但它可以消除讨论中的偏见和逻辑谬误,以帮助团队处理好眼前的现实问题。
团队应该形成在事件发生后立刻对其进行复盘,以防止回归到日常工作之后缺少了上下文环境而无法正确分析出事件发生的原因。
对于根本原因的分析要谨慎,因为软件系统发生事故很少只有单一的原因,它通常是几个因素共同促成的。根本原因分析侧重于最接近事件的人,而不是更广泛的系统性问题。另外,需要进行事件后的 review,详细说明发生的一切以及您为减轻和解决它所做的工作。
事件复盘的成果可以提供给处理未来事件的人使用,有助于缩短解决时间。
安全是吸取事故教训的能力,而不是没有故障,事故复盘是最佳的学习机会。
—— Adrian Cockcroft
导致事故发生的原因从来不是单个员工,而是整个工作系统。如果有人登录服务器,不小心选择了“关闭”而不是“登出”导致服务器关闭,这本质上是系统的故障——为什么不隐藏“关闭”选项?为什么他们需要直接访问服务器?我们可以用 runbook 来做这个吗?
定期 review 来复盘最近的事件,可以在冷静理智的情况下找到模式并思考改进方式。从事件中学习比围绕恢复时间制定目标更重要。
参考链接:
https://octopus.com/blog/how-to-measure-mean-time-to-resolve