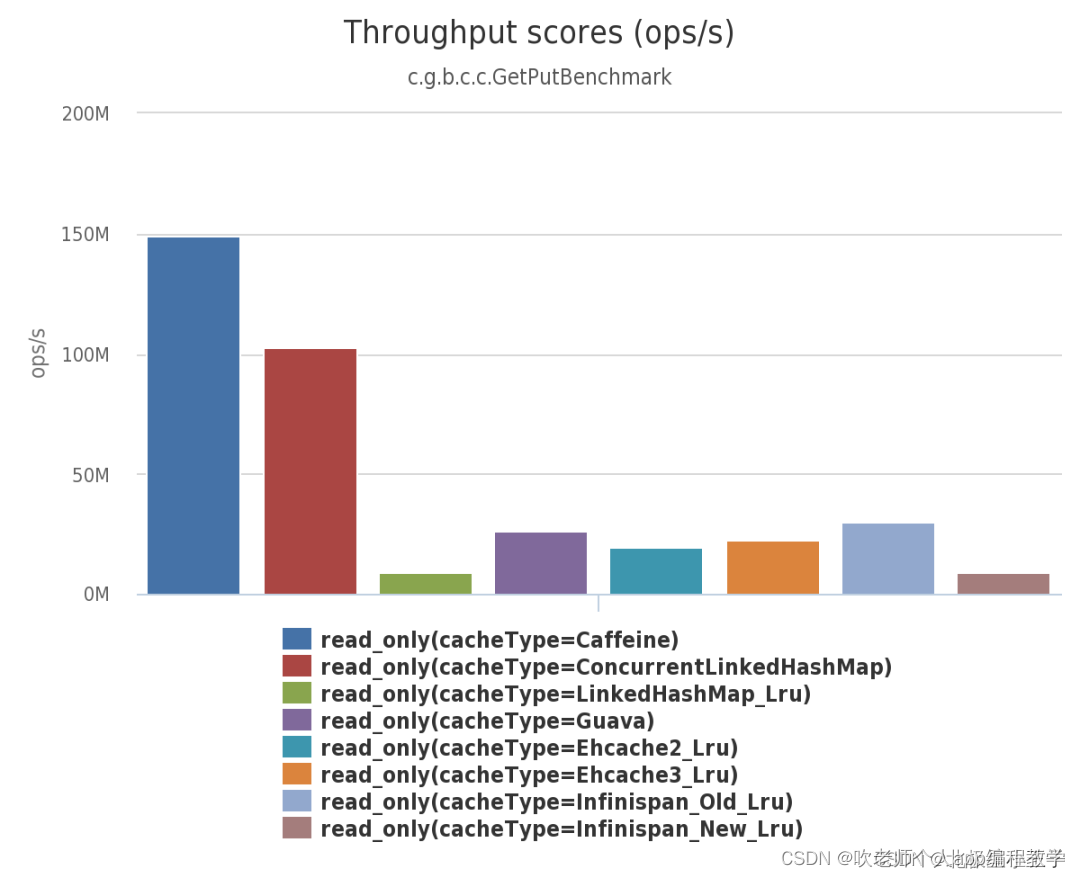
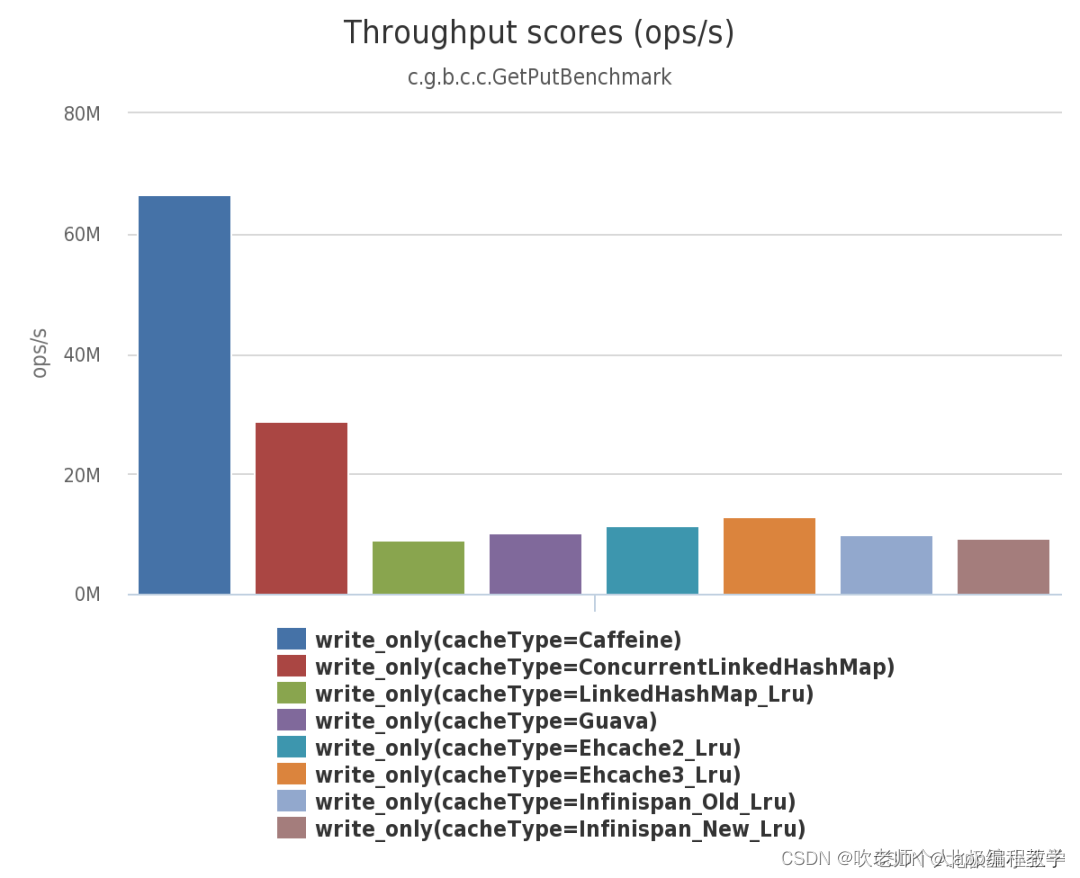
1、Caffine简介
简单说,Caffine 是一款高性能的本地缓存组件
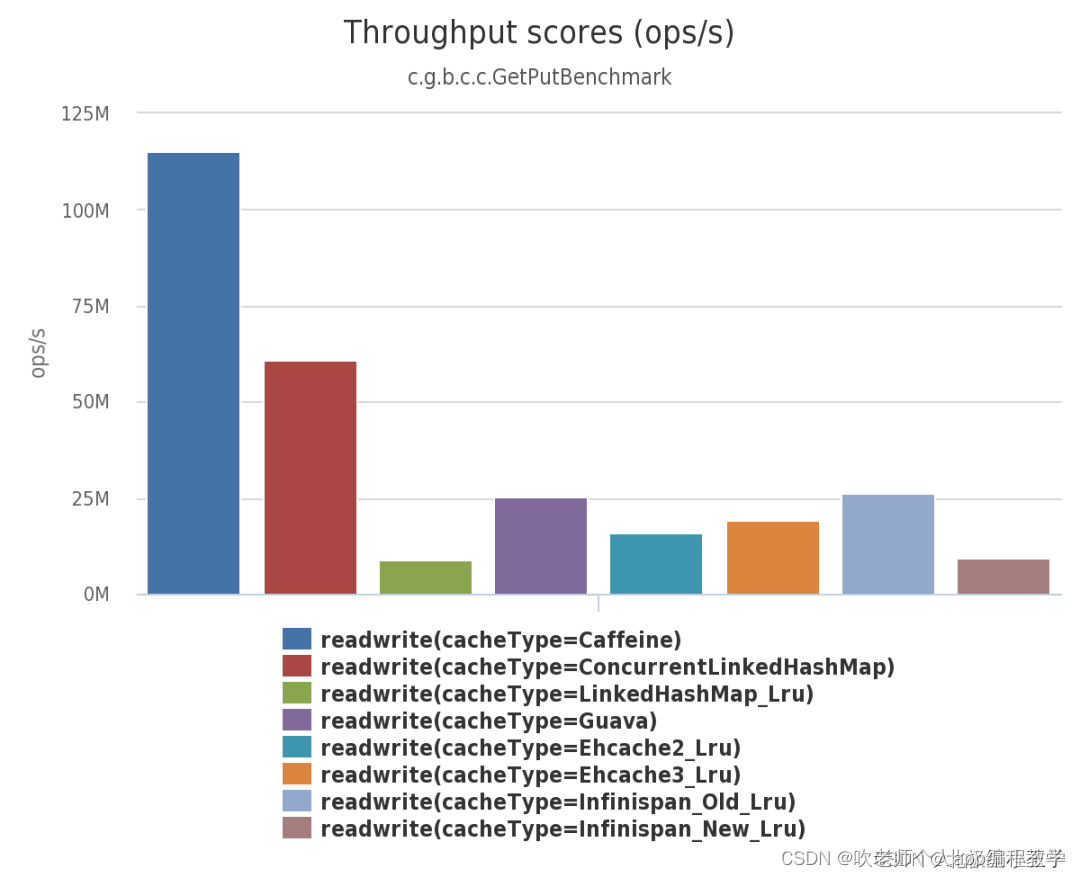
由下面三幅图可见:不管在并发读、并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件
2、常见的缓存淘汰算法
2.1、FIFO
它是优先淘汰掉最先缓存的数据、是最简单的淘汰算法。缺点是如果先缓存的数据使用频率比较高的话,那么该数据就不停地进进出出,因此它的缓存命中率比较低
2.2、LRU
它是优先淘汰掉最久未访问到的数据。缺点是不能很好地应对偶然的突发流量。比如一个数据在一分钟内的前 59 秒访问很多次,而在最后 1 秒没有访问,但是有一批冷门数据在最后一秒进入缓存,那么热点数据就会被冲刷掉
2.3、LFU
最近最少频率使用。它是优先淘汰掉最不经常使用的数据,需要维护一个表示使用频率的字段,缺点主要有两个:
需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销
对突发性的稀疏流量响应迟钝,因为历史的数据已经积累了很多次计数,新来的数据肯定是排在后续的
比如某个歌手的老歌播放历史较多,新出的歌如果和老歌一起排序的话,就永无出头之日
2.4、W-TinyLFU
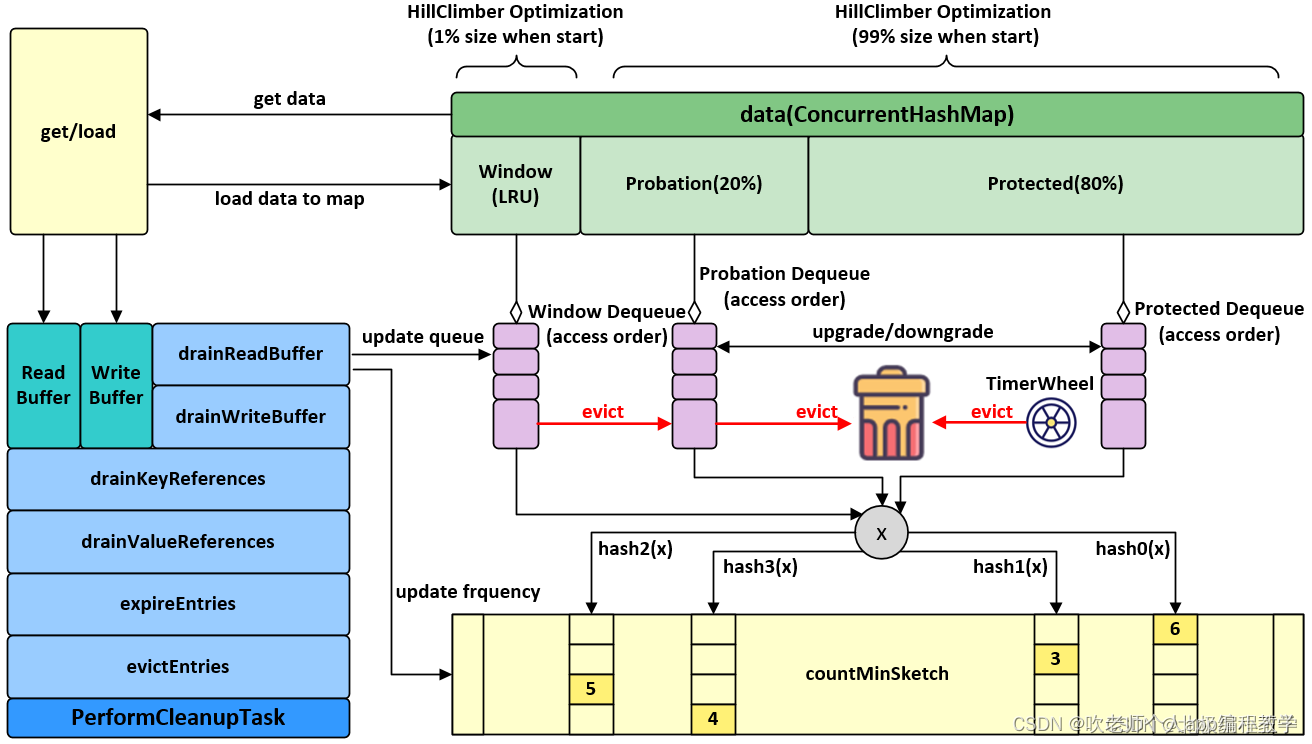
采用 Count–Min Sketch 算法降低频率信息带来的内存消耗
传统的频率统计算法
问题:如果老板让你统计一个实时的数据流中元素出现的频率,并且准备随时回答某个元素出现的频率,不需要的精确的计数,那该怎么办?
直觉告诉我们可能需要一个巨大的 HashMap 来统计各个元素的出现频率,但由于不同的元素的个数可能非常大,以至于是个天文数字,要求的内存可能会非常大,从而不切实际。同时,又要求我们实时计算,实时回答,当 HashMap 的冲突很高时,最坏的情况的时间复杂度可能无法满足实时的要求
Count–Min Sketch算法
Count-min Sketch算法是一个可以用来计数的算法,在数据大小非常大时,一种高效的计数算法,通过牺牲准确性提高的效率
基本的思路:
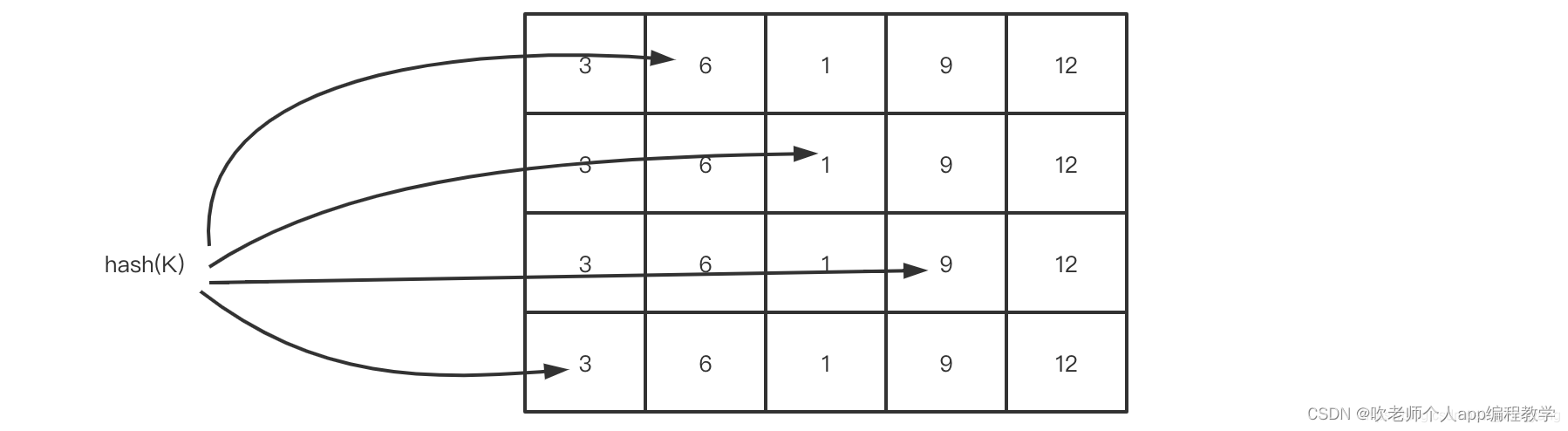
创建一个长度为 x 的数组,用来计数,初始化每个元素的计数值为 0;对于一个新来的元素,哈希到 0 到 x 之间的一个数,比如哈希值为i,作为数组的位置索引;这时,数组对应的位置索引 i 的计数值加 1;那么,这时要查询某个元素出现的频率,只要简单的返回这个元素哈希望后对应的数组的位置索引的计数值即可;考虑到使用哈希,会有冲突,即不同的元素哈希到同一个数组的位置索引,这样,频率的统计都会偏大
如何优化
使用多个数组,和多个哈希函数,来计算一个元素对应的数组的位置索引;那么,要查询某个元素的频率时,返回这个元素在不同数组中的计数值中的最小值即可;
————————————————
Count–Min Sketch 算法类似布隆过滤器 (Bloom Filter)思想,对于频率统计我们其实不需要一个精确值。存储数据时,对 key 进行多次 hash 函数运算后,二维数组不同位置存储频率(Caffeine 实际实现的时候是用一维 long 型数组,每个 long 型数字切分成 16 份,每份 4 bit,默认 15 次为最高访问频率,每个 key 实际 hash 了四次,落在不同 long 型数字的 16 份中某个位置)。读取某个 key 的访问次数时,会比较所有位置上的频率值,取最小值返回。为了解决数据访问模式随时间变化的问题,也为了避免计数无限增长,对于所有 key 的访问频率之和有个最大值,当达到最大值时,会进行 reset 即对各个缓存 key 的频率除以 2
2、窗口设计
对同一对象的 “稀疏突发” 的场景下,TinyLFU 会出现问题。在这种情况下,新突发的 key 无法建立足够的频率以保留在缓存中,从而导致不断的 cache miss。通过设计称为 Window Tiny LFU(W-TinyLFU)的策略(包含两个缓存区域),Caffeine 解决了这个问题
缓存访问频率存储主要分为两大部分,即 LRU 和 Segmented LRU 。新访问的数据会进入第一个 LRU,在 Caffeine 里叫 WindowDeque。当 WindowDeque 满时,会进入 Segmented LRU 中的 ProbationDeque,在后续被访问到时,它会被提升到 ProtectedDeque。当 ProtectedDeque 满时,会有数据降级到 ProbationDeque 。数据需要淘汰的时候,对 ProbationDeque 中的数据进行淘汰。具体淘汰机制:取 ProbationDeque 中的队首和队尾进行 PK,队首数据是最先进入队列的,称为受害者,队尾的数据称为攻击者,比较两者频率大小,大胜小汰;
————————————————
三、使用
加载
先说一下什么是“加载”,当查询缓存时,缓存未命中,那就需要去第三方数据库中查询,然后将查询出的数据先存入缓存,再返回给查询者,这个过程就是加载
Caffeine 提供了四种缓存添加策略:手动加载,自动加载,手动异步加载和自动异步加载
添加 Maven 依赖
<!-- caffeine缓存框架 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.8.8</version>
</dependency>
手动加载
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
public class TestCache {
public static void main(String[] args) {
// 初始化缓存,设置了 1 分钟的写过期,100 的缓存最大个数
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES)
.maximumSize(100)
.build();
int key = 1;
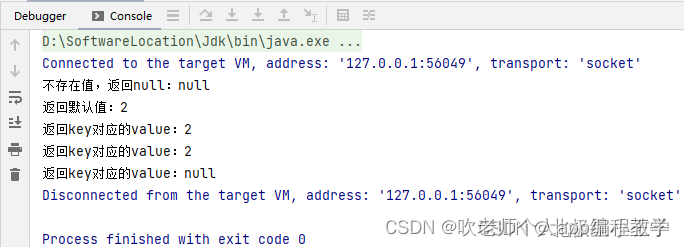
// 使用 getIfPresent 方法从缓存中获取值。如果缓存中不存指定的值,则方法将返回 null
System.out.println("不存在值,返回null:" + cache.getIfPresent(key));
// 也可以使用 get 方法获取值,该方法将一个参数为 key 的 Function 作为参数传入。
// 如果缓存中不存在该 key 则该函数将用于提供默认值,该值在计算后插入缓存中:
System.out.println("返回默认值:" + cache.get(key, a -> 2));
// 校验 key 对应的 value 是否插入缓存中
System.out.println("返回key对应的value:" + cache.getIfPresent(key));
// 手动 put 数据填充缓存中
int value = 2;
cache.put(key, value);
// 使用 getIfPresent 方法从缓存中获取值。如果缓存中不存指定的值,则方法将返回 null
System.out.println("返回key对应的value:" + cache.getIfPresent(key));
// 移除数据,让数据失效
cache.invalidate(key);
System.out.println("返回key对应的value:" + cache.getIfPresent(key));
}
}
Cache 接口提供了显式搜索查找、更新和移除缓存元素的能力
缓存元素可以通过调用 cache.put(key, value)方法被加入到缓存当中。如果缓存中指定的 key 已经存在对应的缓存元素的话,那么先前的缓存的元素将会被直接覆盖掉。因此,通过 cache.get(key, k -> value) 的方式将要缓存的元素通过原子计算的方式 插入到缓存中,以避免和其他写入进行竞争
自动加载
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
public class TestCache {
public static void main(String[] args) {
// 自动加载
LoadingCache<String, Object> cache2 = Caffeine
.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(TestCache::createObject);
String key2 = "dragon";
// 查找缓存,如果缓存不存在则生成缓存元素, 如果无法生成则返回 null
Object value = cache2.get(key2);
System.out.println(value);
List<String> keys = new ArrayList<>();
keys.add("dragon1");
keys.add("dragon2");
// 批量查找缓存,如果缓存不存在则生成缓存元素
Map<String, Object> objectMap = cache2.getAll(keys);
System.out.println(objectMap);
}
private static Object createObject(String key) {
return "hello caffeine 2022";
}
}
异步手动
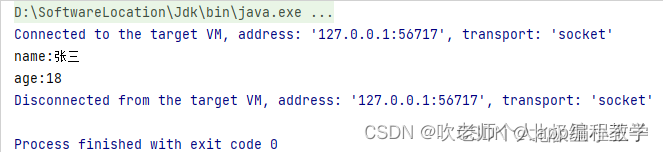
@Test
public void test() throws ExecutionException, InterruptedException {
AsyncCache<String, Integer> cache = Caffeine.newBuilder().buildAsync();
// 会返回一个 future对象, 调用 future 对象的 get 方法会一直卡住直到得到返回,和多线程的 submit 一样
CompletableFuture<Integer> ageFuture = cache.get("张三", name -> {
System.out.println("name:" + name);
return 18;
});
Integer age = ageFuture.get();
System.out.println("age:" + age);
}
异步自动
import com.github.benmanes.caffeine.cache.AsyncLoadingCache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.TimeUnit;
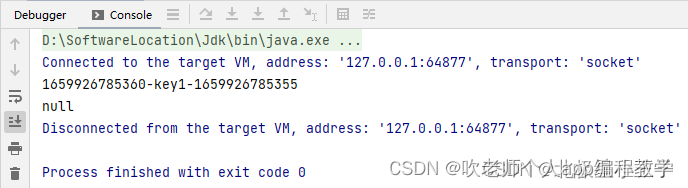
public class TestCache {
public static void main(String[] args) throws InterruptedException {
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.buildAsync(key -> key + "-" + System.currentTimeMillis());
// 获取不存在的 key 时,会使用 buildAsync() 方法中的算法计算出 value,存入缓存
// 异步获取的结果存放在 CompletableFuture 对象中,可以使用 thenAccept() 获取结果
CompletableFuture<Object> future = cache.get("key1");
future.thenAccept(o -> System.out.println(System.currentTimeMillis() + "-" + o));
TimeUnit.SECONDS.sleep(3);
// 不存在则返回 null
CompletableFuture<Object> key2 = cache.getIfPresent("key2");
System.out.println(key2);
}
}
3.2、属性
1、缓存初始容量
initialCapacity :整数,表示能存储多少个缓存对象
2、最大容量
maximumSize :最大容量,如果缓存中的数据量超过这个数值,Caffeine 会有一个异步线程来专门负责清除缓存,按照指定的清除策略来清除掉多余的缓存。注意:比如最大容量是 2,此时已经存入了 2 个数据了,此时存入第 3 个数据,触发异步线程清除缓存,在清除操作没有完成之前,缓存中仍然有 3 个数据,且 3 个数据均可读,缓存的大小也是 3,只有当缓存操作完成了,缓存中才只剩 2 个数据,至于清除掉了哪个数据,这就要看清除策略了
3、最大权重
maximumWeight:最大权重,存入缓存的每个元素都要有一个权重值,当缓存中所有元素的权重值超过最大权重时,就会触发异步清除
package caffeineTest;
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class Person {
Integer age;
String name;
}
测试类
package caffeineTest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
public class Test {
public static void main(String[] args) throws InterruptedException {
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("three", new Person(1, "three"));
Thread.sleep(10);
System.out.println(cache.estimatedSize());
System.out.println(cache.getIfPresent("one"));
System.out.println(cache.getIfPresent("two"));
System.out.println(cache.getIfPresent("three"));
}
}
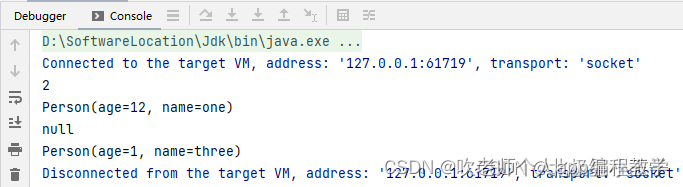
要使用权重来衡量的话,就要规定权重是什么,每个元素的权重怎么计算,weigher 方法就是设置权重规则的,它的参数是一个函数,函数的参数是 key 和 value,函数的返回值就是元素的权重
比如上述代码中,caffeine 设置了最大权重值为 30,然后将每个 Person 对象的 age 年龄作为权重值,所以整个意思就是:缓存中存储的是 Person 对象,但是限制所有对象的 age 总和不能超过 30,否则就触发异步清除缓存。
特别要注意一点:最大容量 和 最大权重 只能二选一作为缓存空间的限制
4、缓存状态
默认情况下,缓存的状态会用一个 CacheStats 对象记录下来,通过访问 CacheStats 对象就可以知道当前缓存的各种状态指标,那究竟有哪些指标呢?
totalLoadTime:总共加载时间
loadFailureRate:加载失败率 = 总共加载失败次数 / 总共加载次数
averageLoadPenalty :平均加载时间,单位,纳秒
evictionCount:被淘汰出缓存的数据总个数
evictionWeight:被淘汰出缓存的那些数据的总权重
hitCount:命中缓存的次数
hitRate:命中缓存率
loadCount:加载次数
loadFailureCount:加载失败次数
loadSuccessCount:加载成功次数
missCount:未命中次数
missRate:未命中率
requestCount:用户请求查询总次数
a、默认的缓存状态收集器 CacheStats
CacheStats 类包含了 2 个方法,了解一下:
CacheStats minus(@Nonnull CacheStats other):当前 CacheStats 对象的各项指标减去参数 other 的各项指标,差值形成一个新的 CacheStats 对象
CacheStats plus(@Nonnull CacheStats other):当前 CacheStats 对象的各项指标加上参数 other 的各项指标,和值形成一个新的 CacheStats 对象
实践出真知
package caffeineTest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.stats.CacheStats;
public class Test {
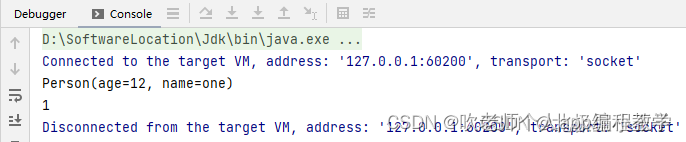
public static void main(String[] args) throws InterruptedException {
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.recordStats()
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put(“one”, new Person(12, “one”));
cache.put(“two”, new Person(18, “two”));
cache.put(“three”, new Person(1, “three”));
Person one = cache.getIfPresent(“one”);
System.out.println(one);
CacheStats stats = cache.stats();
System.out.println(stats.hitCount());
}
}
b、自定义的缓存状态收集器
自定义的缓存状态收集器的作用:每当缓存有操作发生时,不管是查询,加载,存入,都会使得缓存的某些状态指标发生改变,哪些状态指标发生了改变,就会自动触发收集器中对应的方法执行,如果我们在方法中自定义的代码是收集代码,比如将指标数值发送到 kafka,那么其它程序从 kafka 读取到数值,再进行分析与可视化展示,就能实现对缓存的实时监控了
收集器接口为 StatsCounter ,我们只需实现这个接口的所有抽象方法即可
package caffeineTest;
import com.github.benmanes.caffeine.cache.stats.CacheStats;
import com.github.benmanes.caffeine.cache.stats.StatsCounter;
public class MyStatsCounter implements StatsCounter {
@Override
public void recordHits(int i) {
System.out.println("命中次数:" + i);
}
@Override
public void recordMisses(int i) {
System.out.println("未命中次数:" + i);
}
@Override
public void recordLoadSuccess(long l) {
System.out.println("加载成功次数:" + l);
}
@Override
public void recordLoadFailure(long l) {
System.out.println("加载失败次数:" + l);
}
@Override
public void recordEviction() {
System.out.println("因为缓存大小限制,执行了一次缓存清除工作");
}
@Override
public void recordEviction(int weight) {
System.out.println("因为缓存权重限制,执行了一次缓存清除工作,清除的数据的权重为:" + weight);
}
@Override
public CacheStats snapshot() {
return null;
}
}
特别需要注意的是:收集器中那些方法得到的状态值,只是当前缓存操作所产生的结果,比如当前 cache.getIfPresent() 查询一个值,查询到了,说明命中了,但是 recordHits(int i) 方法的参数 i = 1,因为本次操作命中了 1 次
package caffeineTest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
public class Test {
public static void main(String[] args) throws InterruptedException {
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.recordStats(MyStatsCounter::new)
.weigher((String key, Person value) -> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("three", new Person(1, "three"));
cache.getIfPresent("ww");
Thread.sleep(1000);
}
}
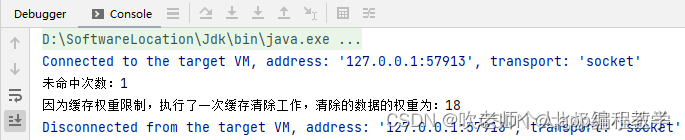
5、线程池
Caffeine 缓冲池总有一些异步任务要执行,所以它包含了一个线程池,用于执行这些异步任务,默认使用的是 ForkJoinPool.commonPool() 线程池;如果一定要用其它的线程池,可以通过 executor() 方法设置,方法参数是一个 线程池对象

6、数据过期策略
a、expireAfterAccess
最后一次访问之后,隔多久没有被再次访问的话,就过期。访问包括了 读 和 写。举个例子:
package caffeineTest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) throws InterruptedException {
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfterAccess(2, TimeUnit.SECONDS)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put(“one”, new Person(12, “one”));
cache.put(“two”, new Person(18, “two”));
System.out.println(cache.getIfPresent(“one”));
System.out.println(cache.getIfPresent(“two”));
Thread.sleep(3000);
System.out.println(cache.getIfPresent(“one”));
System.out.println(cache.getIfPresent(“two”));
}
}
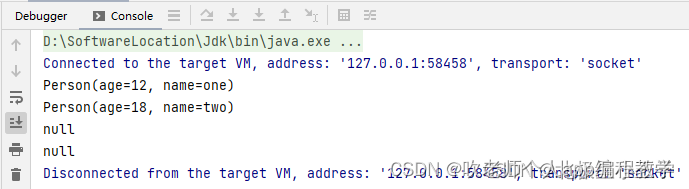
b、expireAfterWrite
某个数据在多久没有被更新后,就过期。举个例子
package caffeineTest;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) throws InterruptedException {
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfterWrite(2, TimeUnit.SECONDS)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put(“one”, new Person(12, “one”));
cache.put(“two”, new Person(18, “two”));
Thread.sleep(1000);
System.out.println(cache.getIfPresent(“one”).getName());
Thread.sleep(2000);
System.out.println(cache.getIfPresent(“one”));
}
}

只能是被更新,才能延续数据的生命,即便是数据被读取了,也不行,时间一到,也会过期
c、expireAfter
自定义缓存策略,满足多样化的过期时间要求
4、SpringBoot Caffeine
引入依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>
在 SpringBoot 结构的项目内部的 application.properties 配置文件中加入以下内容
spring.cache.cache-names=userCache
spring.cache.caffeine.spec=initialCapacity=50,maximumSize=500,expireAfterWrite=10s
server.port=8080
启动类
package example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
@SpringBootApplication
@EnableCaching
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class,args);
}
}
配置类
package example.config;
import com.github.benmanes.caffeine.cache.CacheLoader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class CacheConfig {
@Bean
public CacheLoader<String,Object> cacheLoader(){
return new CacheLoader<String, Object>() {
@Override
public Object load(String s) throws Exception {
return null;
}
@Override
public Object reload(String key, Object oldValue) throws Exception {
return oldValue;
}
};
}
}
package example;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.annotation.CacheEvict;
import org.springframework.cache.annotation.CachePut;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import java.util.concurrent.TimeUnit;
@Service
public class UserDao {
private Cache<Long, User> userCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(100, TimeUnit.SECONDS)
.build();
public User queryByUserIdV2(long userId) {
userCache.get(userId, aLong -> {
System.out.println("用户本地缓存不存在,重新计算");
return new User();
});
return userCache.getIfPresent(userId);
}
public boolean insertUser(int userId) {
User user = new User();
user.setId(userId);
user.setTel("11111");
userCache.put((long) userId, user);
return true;
}
@Cacheable(value = "userCache", key = "#userId", sync = true)
public User queryByUserId(int userId) {
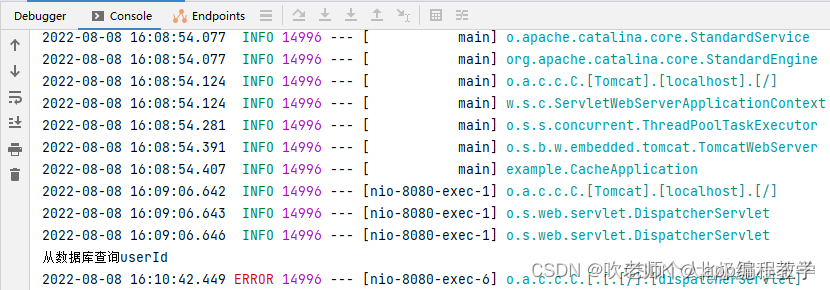
System.out.println("从数据库查询userId");
User user = new User();
user.setId(1001);
user.setTel("18971823123");
user.setUsername("idea");
return user;
}
/**
* sync 用于同步的,在缓存失效(过期不存在等各种原因)的时候,如果多个线程同时访问被标注的方法
* 则只允许一个线程通过去执行方法
*/
@CachePut(value = "userCache", key = "#user.id")
public void saveUser(User user) {
System.out.println("插入数据库一条用户记录");
}
@CacheEvict(value = "userCache", key = "#userId")
public void delUser(int userId) {
System.out.println("删除用户本地缓存");
}
}
解释一下 UserDao 内部所采用的各个注解的实际含义:
@Cacheable
每次执行查询之后,数据都会被存放在一个本地的 Map 集合中,然后第二次请求的时候,如果对应的 key 存在于本地缓存中,那么就不会处罚实际的查询方法
@CachePut
每次触发带有 CachePut 注解的方法,都会将请求参数放入到本地缓存中,不过要注意内部的一个 sync 配置属性,当缓存在本地不存在的时候,请求便会进入到对应声明注解的方法体内部去执行,在多线程情况下有可能会存在多个线程并发请求对应的方法。这个时候可以通过使用 sync 属性去进行限制。
sync = true:并发访问下只能有一个线程将本地缓存进行更新。
sync = false:并发更新本地缓存
@CacheEvict
用于删除指定的缓存配置,删除的依据是对应的 key 属性
User 对象的基本属性如下所示:
package example;
public class User {
private int id;
private String username;
private String tel;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getTel() {
return tel;
}
public void setTel(String tel) {
this.tel = tel;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", tel='" + tel + '\'' +
'}';
}
}
Controller
package example;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.UUID;
import java.util.concurrent.ThreadLocalRandom;
@RestController
public class UserController {
@Resource
private UserDao userDao;
@GetMapping(value = "/queryUser")
public String queryUser(int id) {
User user = userDao.queryByUserId(id);
return user.toString();
}
@GetMapping(value = "/insertUser")
public String insertUser(int id) {
User user = new User();
user.setId(id);
user.setUsername(UUID.randomUUID().toString());
user.setTel(String.valueOf(ThreadLocalRandom.current().nextInt()));
userDao.saveUser(user);
return "success";
}
@GetMapping(value = "/delUser")
public String delUser(int id) {
userDao.delUser(id);
return "delete-success";
}
@GetMapping(value = "/queryUser-02")
public String queryUser_02(long userId) {
User user = userDao.queryByUserIdV2(userId);
return user.toString();
}
@GetMapping(value = "/insertUser-02")
public String insertUser_02(int userId) {
try {
} catch (Exception e) {
e.printStackTrace();
}
userDao.insertUser(userId);
return "success";
}
}
测试本地缓存是否有生效:
请求接口 UserController#queryUser,请求地址如下:
http://localhost:8080/queryUser?id=1001
首次请求会发现在控制台有相关的关键字输出:
在这里插入图片描述
然后第二次请求就会发现逻辑不会再次触发到 UserDao 的 queryByUserId 函数执行。这是因为在 UserDao 的 queryByUserId 函数顶部加入了 @Cacheable 注解