论文题目:《Well-classified Examples are Underestimated in Classification with Deep Neural Networks》
论文地址:https://arxiv.org/pdf/2110.06537.pdf
1.背景
深度分类模型背后的一般常识是专注于分类错误的样本,而忽略远离决策边界的分类良好的样本。例如,在使用交叉熵损失进行训练时,具有较高可能性的样本(即分类良好的样本)在反向传播中贡献较小的梯度。然而,我们从理论上表明,这种常见做法阻碍了representation learning、energy optimization和margin growth。为了弥补这一缺陷,我们建议用additive bonuses来奖励分类良好的示例,以恢复它们对学习过程的贡献。这个反例从理论上解决了这三个问题。我们通过在不同任务(包括图像分类、图形分类和机器翻译)直接验证这一观点。此外,本文表明我们可以处理复杂的场景,例如不平衡分类、OOD检测和对抗性攻击下的应用。
CELoss的三个局限性:
1)Normalization function brings a gradient vanishing problem to CE loss and hinders the representation learning.(归一化函数给 CE 损失带来梯度消失问题并阻碍表征学习)
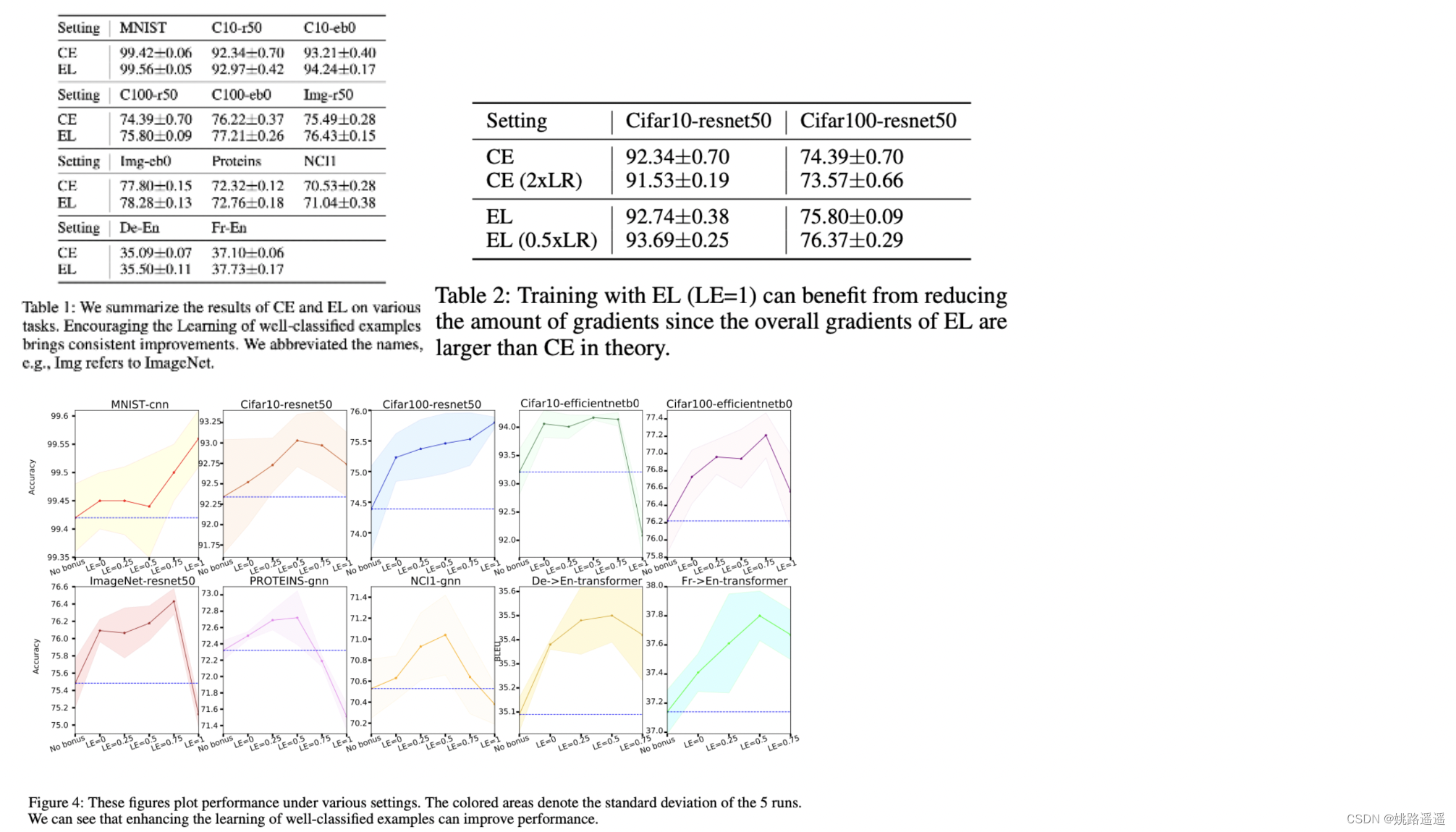
最近对不平衡学习的研究表明,对分类相对较好的数据丰富类的学习进行down-weighting会严重损害表征学习(Kang et al. 2020; Zhou et al. 2020)。这些研究启发我们反思在样本层面是否也是这种情况,我们验证了对分类良好的样本的学习降低权重也会降低性能(表3)

2)CE loss has insufficient power in reducing the energy on the data manifold.(CE loss在降低数据流行上的能量方面没有足够的力量)
Energy-Based模型 (EBM) (LeCun et al. 2006),a sharper energy surface is desired。但是,我们发现energy surface trained with CE loss is not sharp,如图 1 所示。可能的原因是CE loss只要低于负例的energy,就没有足够的energy来push down正例的energy。我们在图 5 中的验证表明,对分类良好的样本进行加权会返回a sharper surface。
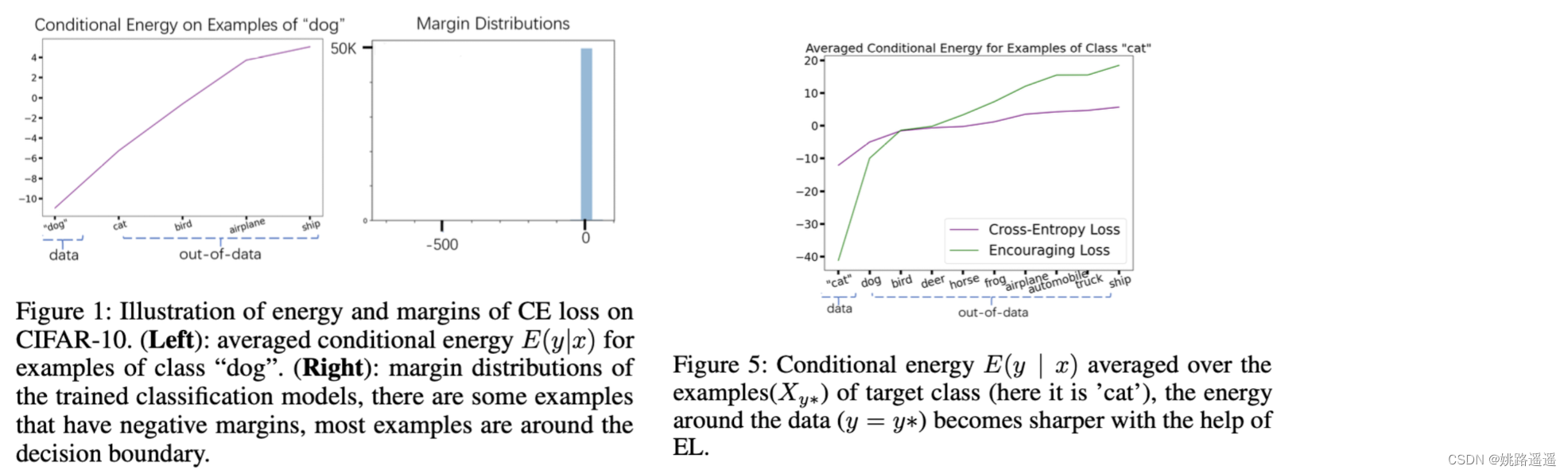
3)CE loss is not effective in enlarging margins.(CE loss在增大margin方面是无效的)
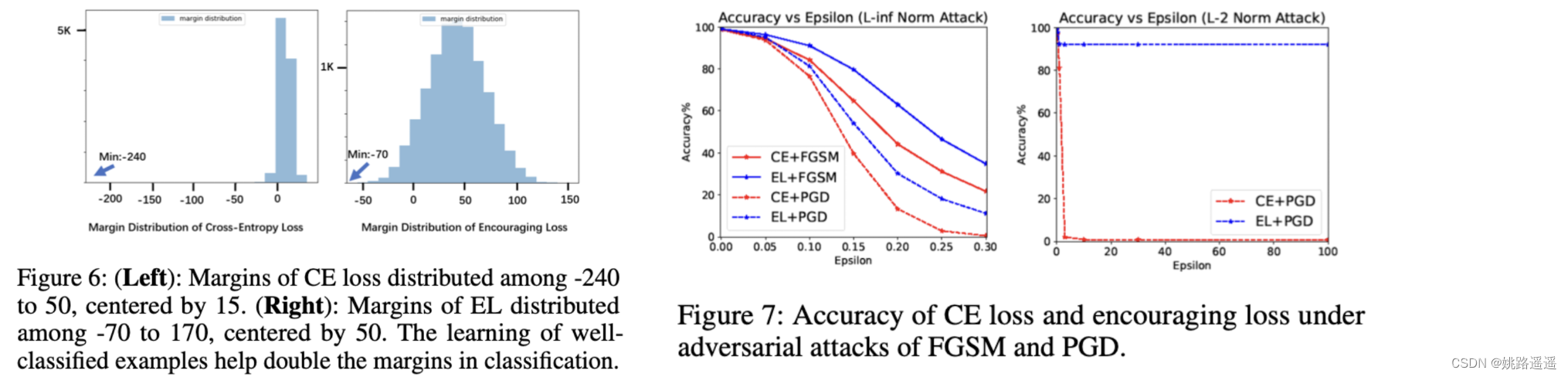
关于分类,公认建立具有大margin的分类模型会导致良好的泛化性(Bartlett 1997;Jiang et al. 2019)和良好的鲁棒性(Elsayed et al. 2018;Matyasko and Chau 2017; Wu and Yu 2019),但我们发现带有 CE 损失的学习会导致更小的margin(如图 1 所示)。原因可能是进一步扩大margin的动机是有限的,因为分类良好的样本不太优化。我们在图 6 和图 7 中的结果表明,对分类样本进行加权会扩大margin并有助于提高对抗性的鲁棒性。
2. Encouraging Loss
 如图 2 所示,EL= CE loss + 额外损失(bonus),当 p 变高时,损失再次变得更steeper。normal bonus是 CE 损失的镜像翻转:bonus = log(1 - p),我们将对数中的值限制为一个小 epsilon(例如 1e-5)以避免数值不稳定。normal bonus的EL如下:
如图 2 所示,EL= CE loss + 额外损失(bonus),当 p 变高时,损失再次变得更steeper。normal bonus是 CE 损失的镜像翻转:bonus = log(1 - p),我们将对数中的值限制为一个小 epsilon(例如 1e-5)以避免数值不稳定。normal bonus的EL如下:
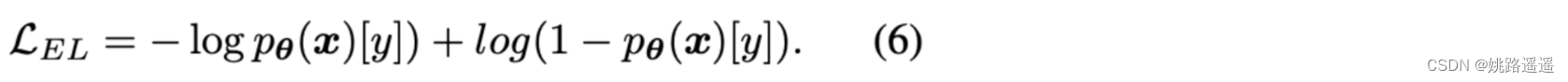
我们将其命名为Encouraging Loss,因为它通过奖励这些接近正确的预测来鼓励模型给出更准确的预测。只要额外的奖励是凹的,它对于较大 p 的steepness就更大,这表明具有该奖励的 EL 比 CE 损失更关注分类良好的示例。
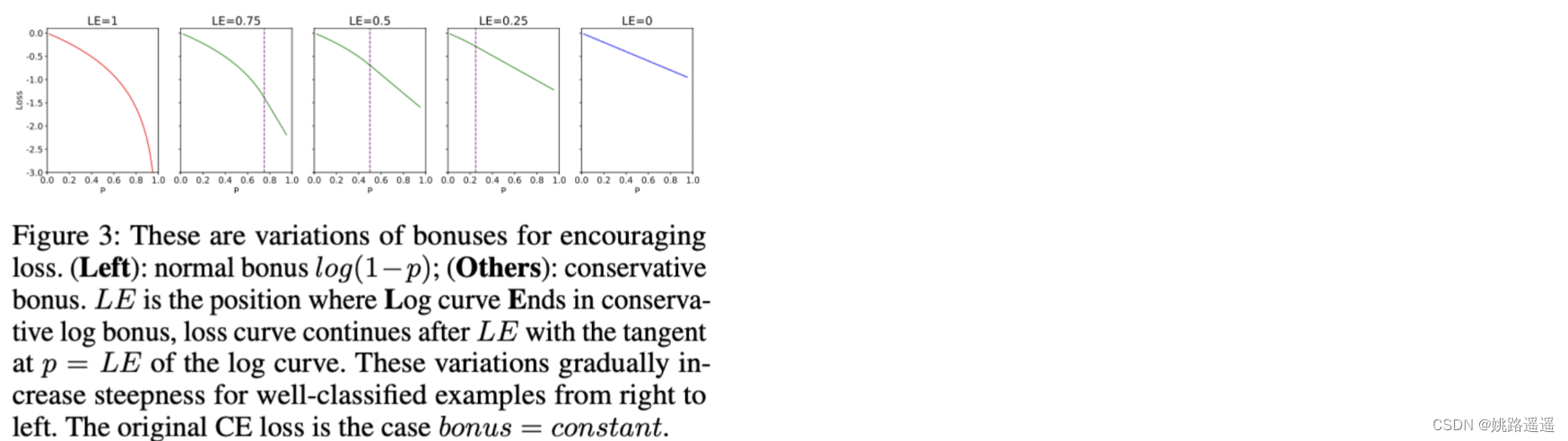
为了使EL的梯度更接近CE以适应现有的优化系统,并研究与其他样本相比,分类良好样本学习的相对重要性。我们可以调整额外bonus的相对steepness。我们设计了许多类型的conservative bonus,它们接近正常bonus,但更保守,并在图 3 中显示。这些变体的log curve Ends(EL)在高似然区域的早期,并将log曲线替换为endpoint。对分类良好的样本在EL通过这些奖励进行优化的相对重要性大于 CE,并且从右到左逐渐增加。

bonus可以设计的比normal bonus更aggressive。
3. 实验结果
![[附源码]计算机毕业设计springboot中小学课后延时服务管理系统](https://img-blog.csdnimg.cn/2af78fdbad6647ec8b3960c5679c18e8.png)





![[附源码]JAVA毕业设计计算机组成原理教学演示软件(系统+LW)](https://img-blog.csdnimg.cn/6ba456fff5cb4967b843accee6a2d4fc.png)