目录
一、Pod节点亲和性
1.1 案例演示:pod 节点亲和性——podAffinity
1.2 案例演示:pod 节点反亲和性——podAntiAffinity
1.3 案例演示: 换一个 topologykey 值
二、污点和容忍度
2.1 案例演示: 把 node2 当成是生产环境专用的,其他node是测试的
2.2 案例演示:给 node1也打上污点
2.3 案例演示:再次修改
三、Pod 常见的状态和重启策略
3.1 常见的 pod 状态
3.2 pod 重启策略
3.3 测试 Always 重启策略
3.4 测试 Never 重启策略
3.5 测试 OnFailure 重启策略(生产环境中常用)
一、Pod节点亲和性
pod自身的亲和性调度有两种表示形式
- podAffinity:pod和pod更倾向腻在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率;
- podAntiAffinity:pod和pod更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个pod随机选则一个节点,做为评判后续的pod能否到达这个pod所在的节点上的运行方式,这就称为pod亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义pod亲和性时需要有一个前提,哪些pod在同一个位置,哪些pod不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
# 查看pod亲和性帮助命令
[root@k8s-master01 ~]# kubectl explain pods.spec.affinity.podAffinity
KIND: Pod
VERSION: v1
RESOURCE: podAffinity <Object>
DESCRIPTION:
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
Pod affinity is a group of inter pod affinity scheduling rules.
FIELDS:
# 软亲和性
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
······
# 硬亲和性
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
······
# 查看pod硬亲和性帮助命令
[root@k8s-master01 ~]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to a pod label update), the system may or
may not try to eventually evict the pod from its node. When there are
multiple elements, the lists of nodes corresponding to each podAffinityTerm
are intersected, i.e. all terms must be satisfied.
······
FIELDS:
labelSelector <Object>
A label query over a set of resources, in this case pods.
namespaceSelector <Object>
······
namespaces <[]string>
······
topologyKey <string> -required-
······- topologyKey:位置拓扑的键,这个是必须字段。
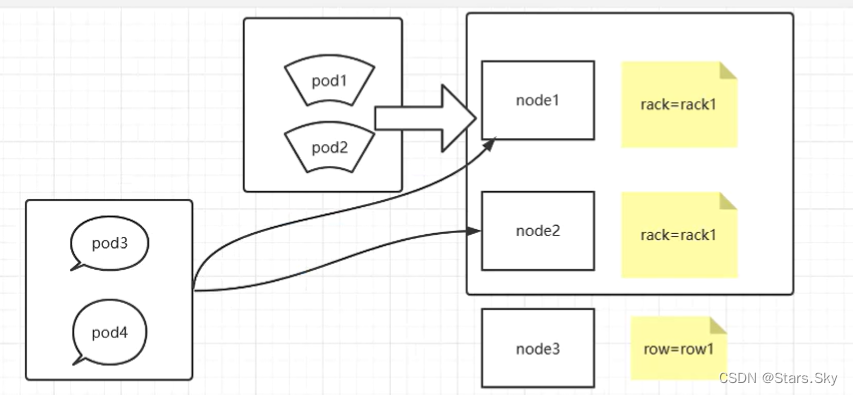
那怎么判断是不是同一个位置:给两个节点分别打上 rack=rack1、row=row1 标签,使用rack的键是同一个位置,使用row的键是同一个位置。
- labelSelector:
我们要判断pod跟别的pod亲和,跟哪个pod亲和,需要靠labelSelector,通过labelSelector选则一组能作为亲和对象的pod资源。
- namespace:
labelSelector需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过namespace指定,如果不指定namespaces,那么就是当前创建pod的名称空间 。
1.1 案例演示:pod 节点亲和性——podAffinity
定义两个pod,第一个pod做为基准,第二个pod跟着它走。
[root@k8s-master01 pod-yaml]# vim pod-required-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app2: myapp2
tier: frontend
spec:
containers:
- name: myapp
image: tomcat:latest
imagePullPolicy: IfNotPresent
# 下面表示创建的pod必须与拥有app2=myapp2标签的pod在一个节点上
[root@k8s-master01 pod-yaml]# vim pod-required-affinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app2, operator: In, values: ["myapp2"]}
topologyKey: kubernetes.io/hostname
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-required-affinity-demo-1.yaml
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-required-affinity-demo-2.yaml
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 12m 10.244.169.146 k8s-node2 <none> <none>
pod-second 1/1 Running 0 7s 10.244.169.147 k8s-node2 <none> <none>
上面说明第一个pod调度到哪,第二个pod也调度到哪,这就是pod节点亲和性。
1.2 案例演示:pod 节点反亲和性——podAntiAffinity
定义两个pod,第一个pod做为基准,第二个pod跟它调度节点相反。
# 把前面案例的两个pods 删除
[root@k8s-master01 pod-yaml]# kubectl delete pods pod-first pod-second
# 创建第一个pod
[root@k8s-master01 pod-yaml]# vim pod-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: nginx:latest
imagePullPolicy: IfNotPresent
# 创建第二个pod
[root@k8s-master01 pod-yaml]# vim pod-required-anti-affinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app1, operator: In, values: ["myapp1"]}
topologyKey: kubernetes.io/hostname
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-required-anti-affinity-demo-2.yaml
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-required-anti-affinity-demo-2.yaml
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 5m47s 10.244.169.149 k8s-node2 <none> <none>
pod-second 0/1 ContainerCreating 0 5s <none> k8s-node1 <none> <none>上面显示两个pod不在一个node节点上,这就是pod节点反亲和性。
1.3 案例演示: 换一个 topologykey 值
# 删除前面案例的pods
[root@k8s-master01 pod-yaml]# kubectl delete pods pod-first pod-second
# 查看集群中node节点的所有标签
[root@k8s-master01 pod-yaml]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master01 Ready control-plane 42d v1.25.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s-node1 Ready work 42d v1.25.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1,kubernetes.io/os=linux,node-role.kubernetes.io/work=work
k8s-node2 Ready work 42d v1.25.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disk=ceph,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node2,kubernetes.io/os=linux,node-role.kubernetes.io/work=work
# 下面我们创建两个pod,选取一个相同标签为 kubernetes.io/os=linux 作为 topologykey
[root@k8s-master01 pod-yaml]# vim pod-first-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app3: myapp3
tier: frontend
spec:
containers:
- name: myapp
image: nginx:latest
imagePullPolicy: IfNotPresent
[root@k8s-master01 pod-yaml]# vim pod-first-required-anti-affinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app3 ,operator: In, values: ["myapp3"]}
topologyKey: kubernetes.io/os
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-first-required-anti-affinity-demo-1.yaml
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-first-required-anti-affinity-demo-2.yaml
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 11m 10.244.169.150 k8s-node2 <none> <none>
pod-second 0/1 Pending 0 14s <none> <none> <none> <none>
[root@k8s-master01 pod-yaml]# kubectl describe pods pod-second
第二个pod是pending,因为两个节点的标签是相同的,是同一个位置,而且我们要求反亲和性,所以就会处于pending状态,如果在反亲和性这个位置把required改成preferred,或者变为pod亲和性那么也会运行。
二、污点和容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的pod就运行(调度)不上来,污点就是定义在节点上的键值属性数据,可以决定拒绝哪些pods。
- taints 是键值数据,用在节点上,定义污点;
- tolerations 是键值数据,用在pod上,定义容忍度,能容忍哪些污点。
pod亲和性是pod属性;但是污点是节点的属性,污点定义在k8s集群的节点上的一个字段。
# 查看控住节点定义的污点
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-master01 | grep Taints
Taints: node-role.kubernetes.io/control-plane:NoSchedule
# 两个工作节点是没有定义污点
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node1 | grep Taints
Taints: <none>
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node2 | grep Taints
Taints: <none>
那么,如何给节点定义污点呢?
# 查看帮助命令
[root@k8s-master01 pod-yaml]# kubectl explain node.spec
······
taints <[]Object>
If specified, the node's taints.
[root@k8s-master01 pod-yaml]# kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required-
Required. The effect of the taint on pods that do not tolerate the taint.
Valid effects are NoSchedule, PreferNoSchedule and NoExecute.
Possible enum values:
- `"NoExecute"` Evict any already-running pods that do not tolerate the
taint. Currently enforced by NodeController.
- `"NoSchedule"` Do not allow new pods to schedule onto the node unless
they tolerate the taint, but allow all pods submitted to Kubelet without
going through the scheduler to start, and allow all already-running pods to
continue running. Enforced by the scheduler.
- `"PreferNoSchedule"` Like TaintEffectNoSchedule, but the scheduler tries
not to schedule new pods onto the node, rather than prohibiting new pods
from scheduling onto the node entirely. Enforced by the scheduler.
key <string> -required-
Required. The taint key to be applied to a node.
timeAdded <string>
TimeAdded represents the time at which the taint was added. It is only
written for NoExecute taints.
value <string>
The taint value corresponding to the taint key.taints 的 effect 用来定义对pod对象的排斥等级(效果):
- NoSchedule:
仅影响pod调度过程,当pod能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前已经调度到这个节点的pod不能容忍了,但对已经运行的这个pod对象不产生影响,不会被驱逐。但是后面新创建的pod如果不能容忍则不会调度到这个节点来。
- NoExecute:
既影响调度过程,又影响现存的pod对象,如果现存的pod不能容忍节点后来加的污点,这个pod就会被驱逐。
- PreferNoSchedule:
是NoSchedule的柔性版本。假如node1、node2节点都定义了污点这个排斥等级,但是pod没有定义容忍度,依然会被随机调度到这两个节点中。
# 可以看到master这个节点的污点是Noschedule。所以我们之前创建的pod都不会调度到master上,因为我们创建的pod的时候没有定义容忍度。
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-master01 | grep Taints
Taints: node-role.kubernetes.io/control-plane:NoSchedule
# 查看哪些pod被调度到master节点
[root@k8s-master01 pod-yaml]# kubectl get pods -A -o wide
# 可以看到这个pod的容忍度是NoExecute,则可以调度到xianchaomaster1上
[root@k8s-master01 pod-yaml]# kubectl describe pods kube-apiserver-k8s-master01 -n kube-system | grep Tolerations
Tolerations: :NoExecute op=Exists
# 查看节点污点帮助命令
[root@k8s-master01 pod-yaml]# kubectl taint --help2.1 案例演示: 把 node2 当成是生产环境专用的,其他node是测试的
# 给 node2 打污点,pod如果不能容忍就不会调度过来
[root@k8s-master01 pod-yaml]# kubectl taint node k8s-node2 node-type=production:NoSchedule
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node2 | grep Taints
Taints: node-type=production:NoSchedule
# 创建一个没有定义容忍度的pod
[root@k8s-master01 pod-yaml]# vim pod-taint.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:latest
imagePullPolicy: IfNotPresent
# 可以看到都被调度到 node1上了,因为 node2这个节点打了污点,而我们在创建pod的时候没有容忍度,所以node2上不会有pod调度上去的
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-taint.yaml
pod/taint-pod created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-pod 1/1 Running 0 7s 10.244.36.87 k8s-node1 <none> <none>2.2 案例演示:给 node1也打上污点
[root@k8s-master01 pod-yaml]# kubectl taint node k8s-node1 node-type=dev:NoExecute
node/k8s-node1 tainted
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node1 | grep Taints
Taints: node-type=dev:NoExecute
# 可以看到已经存在的pod节点都被撵走了
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-pod 1/1 Running 0 2m43s 10.244.36.87 k8s-node1 <none> <none>
taint-pod 1/1 Terminating 0 3m1s 10.244.36.87 k8s-node1 <none> <none>
taint-pod 1/1 Terminating 0 3m1s 10.244.36.87 k8s-node1 <none> <none>
taint-pod 0/1 Terminating 0 3m2s 10.244.36.87 k8s-node1 <none> <none>
taint-pod 0/1 Terminating 0 3m2s 10.244.36.87 k8s-node1 <none> <none>
taint-pod 0/1 Terminating 0 3m2s 10.244.36.87 k8s-node1 <none> <none>
^C您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
No resources found in default namespace.
# 查看定义pod容忍度的帮助命令
[root@k8s-master01 pod-yaml]# kubectl explain pods.spec.tolerations
# 创建一个容忍度为的pod
[root@k8s-master01 pod-yaml]# vim pod-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
tolerations:
- key: "node-type"
operator: "Equal"
value: "production"
effect: "NoExecute"
tolerationSeconds: 3600 # 3600 秒后驱逐
# 还是显示pending,因为我们使用的是equal(等值匹配),所以key和value,effect必须和node节点定义的污点完全匹配才可以。
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 0/1 Pending 0 9s <none> <none> <none> <none>
# 把上面配置 effect: "NoExecute"变成 effect: "NoSchedule"成;tolerationSeconds: 3600 这行去掉。要先删除原来的,因为不能在修改容忍度后去动态更新pod状态
[root@k8s-master01 pod-yaml]# kubectl delete pods myapp-deploy
pod "myapp-deploy" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 1/1 Running 0 93s 10.244.169.151 k8s-node2 <none> <none>
上面就可以调度到 node2上了,因为在pod中定义的容忍度能容忍node节点上的污点。
2.3 案例演示:再次修改
# node的污点
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node2 | grep Taints
Taints: node-type=production:NoSchedule
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node1 | grep Taints
Taints: node-type=dev:NoExecute
# pod-demo-1.yaml 修改如下部分:
tolerations:
- key: "node-type"
operator: "Exists"
value: ""
effect: "NoSchedule"
# 只要对应的键是存在的,exists,其值被自动定义成通配符。发现还是调度到 node2上
[root@k8s-master01 pod-yaml]# kubectl delete pods myapp-deploy
pod "myapp-deploy" deleted
您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 1/1 Running 0 7s 10.244.169.152 k8s-node2 <none> <none>
# 再次修改:
tolerations:
- key: "node-type"
operator: "Exists"
value: ""
effect: ""
# 有一个node-type的键,不管值是什么,不管是什么效果,都能容忍。可以看到 node2 和 node1节点上都有可能有pod被调度。
[root@k8s-master01 pod-yaml]# kubectl delete pods myapp-deploy
pod "myapp-deploy" deleted
您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 0/1 ContainerCreating 0 1s <none> k8s-node1 <none> <none>删除 pod 和污点:
[root@k8s-master01 pod-yaml]# kubectl delete pods myapp-deploy
pod "myapp-deploy" deleted
您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl get pods
No resources found in default namespace.
[root@k8s-master01 pod-yaml]# kubectl taint node k8s-node1 node-type-
node/k8s-node1 untainted
[root@k8s-master01 pod-yaml]# kubectl taint node k8s-node2 node-type-
node/k8s-node2 untainted
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node1 | grep Taints
Taints: <none>
您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl describe nodes k8s-node2 | grep Taints
Taints: <none>三、Pod 常见的状态和重启策略
3.1 常见的 pod 状态
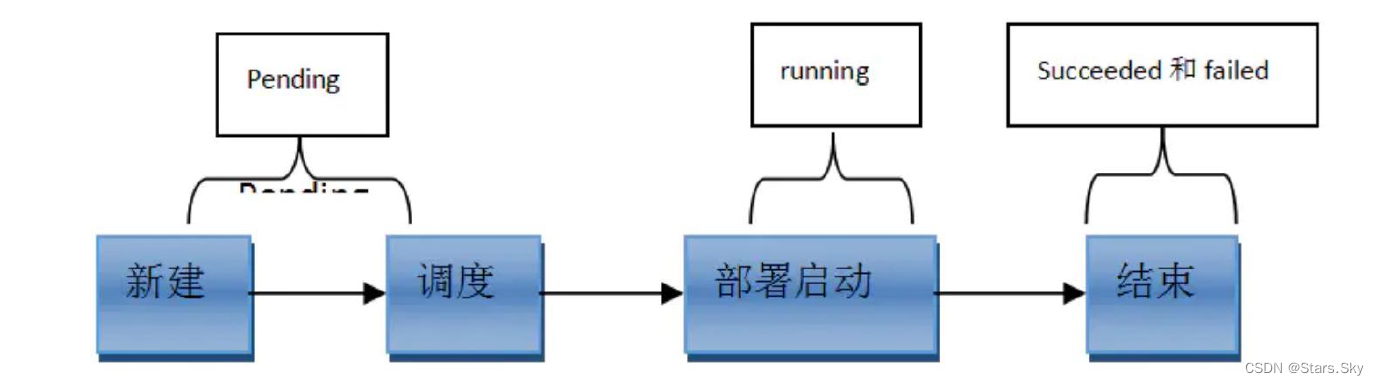
第一阶段:
- 挂起(Pending):
- 正在创建Pod,但是Pod中的容器还没有全部被创建完成,处于此状态的Pod应该检查Pod依赖的存储是否有权限挂载、镜像是否可以下载、调度是否正常等;
- 我们在请求创建pod时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了pod但是没有适合它运行的节点叫做挂起,调度没有完成。
- 失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止。
- 未知(Unknown):未知状态,所谓pod是什么状态是apiserver和运行在pod节点的kubelet进行通信获取状态信息的,如果节点之上的kubelet本身出故障,那么apiserver就连不上kubelet,得不到信息了,就会看Unknown,通常是由于与pod所在的node节点通信错误。
- Error 状态:Pod 启动过程中发生了错误
- 成功(Succeeded):Pod中的所有容器都被成功终止,即pod里所有的containers均已terminated。
第二阶段:
- Unschedulable:Pod不能被调度, scheduler没有匹配到合适的node节点 PodScheduled:pod正处于调度中,在scheduler刚开始调度的时候,还没有将pod分配到指定的node,在筛选出合适的节点后就会更新etcd数据,将pod分配到指定的node
- Initialized:所有pod中的初始化容器已经完成了
- ImagePullBackOff:Pod所在的node节点下载镜像失败
- Running:Pod内部的容器已经被创建并且启动。
扩展:还有其他状态,如下:
- Evicted状态:出现这种情况,多见于系统内存或硬盘资源不足,可df-h查看docker存储所在目录的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
- CrashLoopBackOff:容器曾经启动了,但可能又异常退出了。如pod一直在重启
3.2 pod 重启策略
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,当某个容器异常退出或者健康检查失败时,kubelet将根据 重启策略来进行相应的操作。
Pod 的 spec 中包含一个 restartPolicy 字段,其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
- Always:只要容器异常退出,kubelet就会自动重启该容器。(这个是默认的重启策略)
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。(生产环境中常用)
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
3.3 测试 Always 重启策略
[root@k8s-master01 pod-yaml]# vim pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
spec:
restartPolicy: Always
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat:latest
imagePullPolicy: IfNotPresent
[root@k8s-master01 pod-yaml]# kubectl apply -f pod.yaml
pod/demo-pod created
您在 /var/spool/mail/root 中有新邮件
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod 1/1 Running 0 10s 10.244.169.153 k8s-node2 <none> <none>
# 动态显示pod状态信息
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
demo-pod 1/1 Running 0 22s 10.244.169.153 k8s-node2 <none> <none>
# 另起一个终端会话,进入pod内部容器,正常停止 tomcat 容器服务。-c 指定容器名称。
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# ls
root@demo-pod:/usr/local/tomcat# bin/shutdown.sh 可以看到,容器服务停止后被重启了一次,,pod又恢复正常了:

# 非正常停止容器里的tomcat服务
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# ps -ef | grep tomcat
root@demo-pod:/usr/local/tomcat# kill 1
可以看到容器终止了,并且又重启一次,重启次数增加了一次:

3.4 测试 Never 重启策略
# 修改 pod.yaml,把 Always 改为 Never
[root@k8s-master01 pod-yaml]# kubectl delete pods demo-pod
pod "demo-pod" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f pod.yaml
pod/demo-pod created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
# 在另一个终端进入容器,正常停止服务
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# bin/shutdown.sh 查看pod状态,发现正常停止容器里的tomcat服务,pod正常运行,但容器没有重启。

# 非正常停止容器里的tomcat服务
[root@k8s-master01 pod-yaml]# kubectl delete pods demo-pod
pod "demo-pod" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f pod.yaml
pod/demo-pod created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
# 在另一终端进入容器内容
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# kill 1
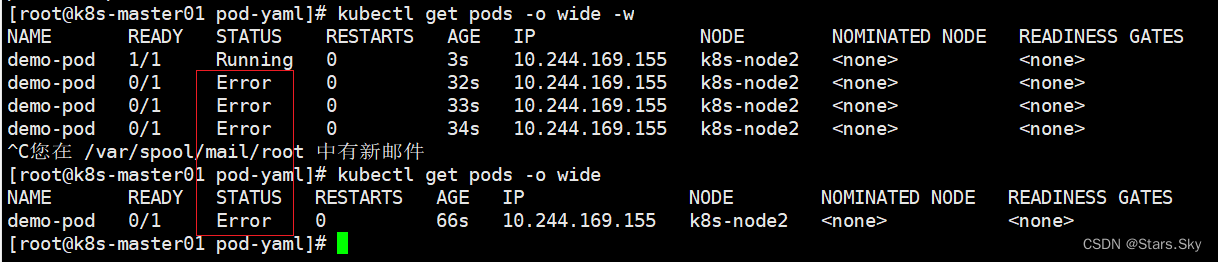
可以看到容器状态是error,并且没有重启,这说明重启策略是never,那么pod里容器服务无论如何终止,都不会重启:
3.5 测试 OnFailure 重启策略(生产环境中常用)
# 修改 pod.yaml 文件,把 Never 改为 OnFailure
[root@k8s-master01 pod-yaml]# kubectl delete pods demo-pod
pod "demo-pod" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f pod.yaml
pod/demo-pod created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
# 在另一终端进入容器内部,正常停止服务
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# bin/shutdown.sh发现正常停止容器里的tomcat服务,退出码是0,pod里的容器不会重启:

# 非正常停止容器里的tomcat服务
[root@k8s-master01 pod-yaml]# kubectl delete pods demo-pod
pod "demo-pod" deleted
[root@k8s-master01 pod-yaml]# kubectl apply -f pod.yaml
pod/demo-pod created
[root@k8s-master01 pod-yaml]# kubectl get pods -o wide -w
# 在另一终端进入容器内部
[root@k8s-master01 pod-yaml]# kubectl exec -it demo-pod -c tomcat-pod-java -- bash
root@demo-pod:/usr/local/tomcat# kill 1
可以看到非正常停止pod里的容器,容器退出码不是0,那就会重启容器:

上一篇文章:【云原生 | Kubernetes 实战】05、Pod高级实战:基于污点、容忍度、亲和性的多种调度策略(上)_Stars.Sky的博客-CSDN博客



![[附源码]JAVA毕业设计计算机组成原理教学演示软件(系统+LW)](https://img-blog.csdnimg.cn/6ba456fff5cb4967b843accee6a2d4fc.png)