SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
摘要
Generating talking head videos through a face image and a piece ofspeech audio still contains many challenges. i.e., unnatural head movement, distorted expression, and identity modification. We argue that these issues are mainly because oflearning from the coupled 2D motion fields. On the other hand, explicitly using 3D information also suffers problems ofstiffexpression and incoherent video. We present SadTalker, which generates 3D motion coefficients (head pose, expression) of the 3DMM from audio and implicitly modulates a novel 3D-aware face render for talking head generation. To learn the realistic motion coefficients, we explicitly model the connections between audio and different types ofmotion coefficients individually. Precisely, we present ExpNet to learn the accurate facial expression from audio by distilling both coefficients and 3D-rendered faces. As for the head pose, we design PoseVAE via a conditional VAE to synthesize head motion in different styles. Finally, the generated 3D motion coefficients are mapped to the unsupervised 3D keypoints space ofthe proposed face render, and synthesize the final video. We conducted extensive experiments to demonstrate the superiority ofour method in terms ofmotion and video quality.
通过人脸图像和一段语音音频生成说话的头部视频仍然包含许多挑战。也就是说,不自然的头部运动、扭曲的表情和身份修改。我们认为,这些问题主要是因为oflearning从耦合的二维运动场。另一方面,明确地使用3D信息也遭受僵硬的表达和不连贯的视频的问题。我们提出了SadTalker,它产生的3D运动系数(头部姿势,表达)的3DMM从音频和隐式调制一个新的3D感知的面部渲染说话的头部生成。为了学习真实的运动系数,我们明确地建模音频和不同类型的运动系数之间的连接。准确地说,我们提出ExpNet学习准确的面部表情从音频中提取系数和3D渲染的脸。至于头部姿态,我们设计了PoseVAE通过条件VAE合成不同风格的头部运动。最后,生成的三维运动系数映射到建议的人脸渲染的无监督三维关键点空间,并合成最终的视频。我们进行了大量的实验来证明我们的方法在运动和视频质量方面的优越性.
方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FkU3zE6M-1685335353879)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230517143810030.png)]](https://img-blog.csdnimg.cn/8726251e5cf042d788afd27947003439.png)
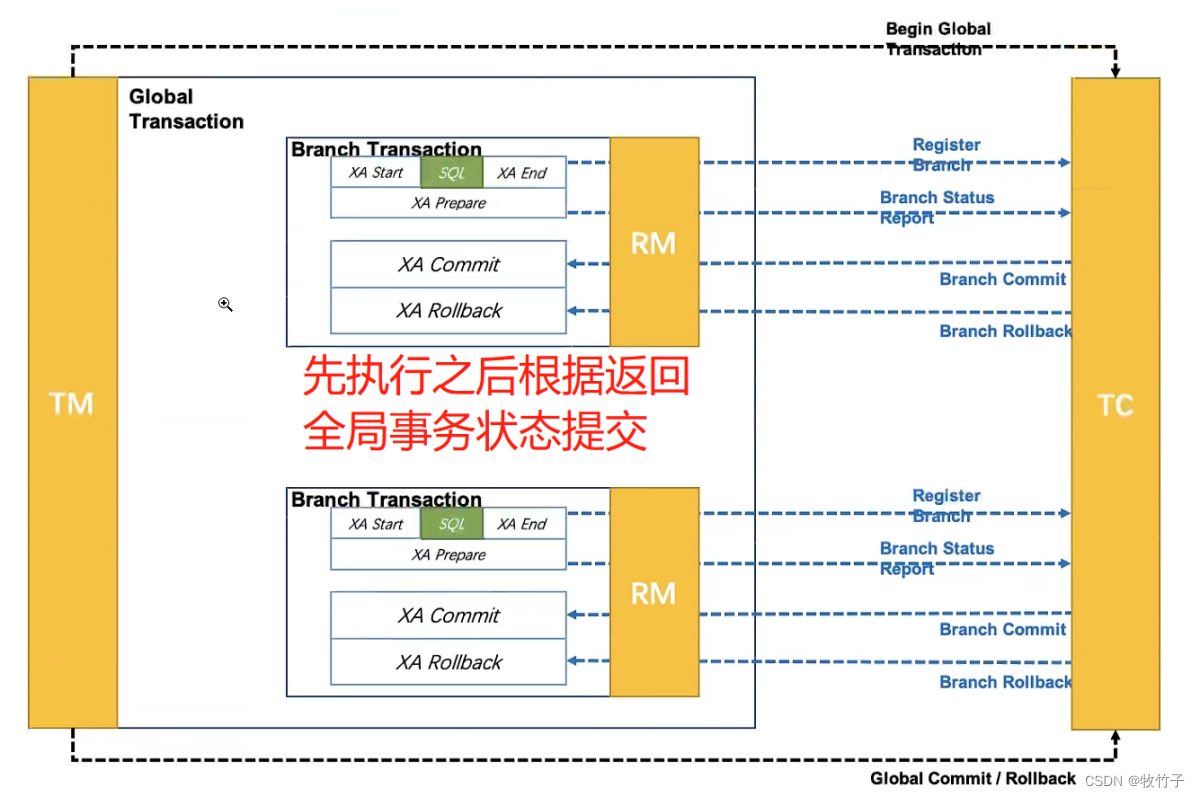
图2.pipeline。我们的方法使用3DMM的系数作为中间运动表示。为此,我们首先从音频生成真实的3D运动系数(面部表情β、头部姿势P),然后这些系数用于隐式地调制3D感知面部渲染以用于最终视频生成。
即,该系统使用的3D运动系数作为中间表示的讲话头部生成。首先从原始图像中提取系数。然后分别用ExpNet和PoseVAE生成真实感的3DMM运动系数。最后,提出了一种3D感知的人脸渲染来产生说话的头部视频。
三维人脸模型的初步研究
由于真实视频是在3D环境中捕获的,因此3D信息对于提高所生成的视频的真实性至关重要。然而,先前的工作很少在3D空间中被考虑,因为难以从单个图像获得精确的3D系数,并且高质量的面部渲染也难以设计。受最近的单图像深度3D重建方法[5]的启发,我们将预测的3D变形模型(3DMM)的空间视为我们的中间表示。在3DMM中,3D面部形状S可以被解耦为:
S
=
S
‾
+
α
U
i
d
+
β
U
e
x
p
,
(1)
\mathbf{S}=\overline{\mathbf{S}}+\alpha\mathbf{U}_{id}+\beta\mathbf{U}_{exp},\tag{1}
S=S+αUid+βUexp,(1)
其中
S
‾
\overline{\mathbf{S}}
S是3D人脸的平均形状,
U
i
d
U_{id}
Uid和
U
e
x
p
U_{exp}
Uexp是LSFM可变形模型的恒等式和表达式的正交基[1]。系数
α
∈
R
80
\alpha\in\mathbb{R}^{80}
α∈R80和
β
∈
R
64
\beta\in\mathbb{R}^{64}
β∈R64分别描述了人的身份和表达。为了保持姿态方差,系数
r
∈
S
O
(
3
)
r \in SO(3)
r∈SO(3)和
t
∈
R
3
t \in\mathbb{R}^{3}
t∈R3表示头部旋转和平移。为了实现身份无关系数生成,我们仅将运动参数建模为
{
β
,
r
,
t
}
\{\beta,\mathbf{r},\mathbf{t}\}
{β,r,t}。如前所述,我们从驾驶音频中分别学习头部姿势
ρ
=
[
r
,
t
]
\rho = [r,t]
ρ=[r,t]和表情系数
β
\beta
β。然后,这些运动系数被用来隐式地调制我们的脸渲染最终的视频合成。
通过音频生成运动系数
如上所述,3D运动系数包含头部姿势和表达式,其中头部姿势是全局运动,并且表达式是相对局部的。为此,学习所有内容将在网络中造成巨大的不确定性,因为头部姿势与音频的关系相对较弱,而嘴唇运动则高度相关。我们使用下面分别介绍的所提出的PoseVAE和ExpNet来生成头部姿势和表情的运动。
ExpNet
学习一个从音频中产生精确表达式系数的通用模型是非常困难的,原因有两个:
- 音频到表情不是针对不同身份的一对一映射任务。
- 在表达式系数中存在一些与音频无关的运动,这将影响预测的准确性。我们的ExpNet旨在减少这些不确定性。至于身份问题,我们通过第一帧的表情系数 β 0 \beta_0 β0将表情运动与特定人联系起来。为了减少自然谈话中其他面部组件的运动权重,我们通过Wav2Lip 和深度3D重建的预训练网络使用嘴唇运动系数作为系数目标。然后,其他次要面部运动(例如,眨眼)可以经由渲染图像上的附加界标损失来利用。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-63TQCnDs-1685335353880)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230517145254865.png)]](https://img-blog.csdnimg.cn/100981be558547ca8a61d8fff966c3f7.png)
图3.ExpNet的结构。我们涉及单目3D人脸重建模型[5](Re和Rd)来学习真实的表情系数。其中Re是预训练的3DMM系数估计器,Rd是没有可学习参数的可微分3D面部渲染。我们使用参考表达式β0来减少身份的不确定性,并且从预训练的Wav2Lip [30]和第一帧生成的帧作为目标表达式系数,因为它仅包含与嘴唇相关的运动。
如图3中所示,我们从音频窗口
a
{
1
,
…
,
t
}
a\{1,\dots,t\}
a{1,…,t},其中每个帧的音频特征是0.2s梅尔频谱图。对于训练,我们首先设计基于ResNet的音频编码器
Φ
A
\Phi_A
ΦA以将音频特征嵌入到潜在空间。然后,添加线性层作为映射网络
Φ
M
\Phi_M
ΦM以对表达式系数进行解码。这里,我们还添加来自参考图像的参考表达式
β
0
\beta_0
β0以减少如上所述的身份不确定性。由于我们在训练中使用仅嘴唇系数作为基础事实,因此我们显式地添加眨眼控制信号
z
b
l
i
n
k
∈
[
0
,
1
]
z_{blink} \in [0,1]
zblink∈[0,1]和对应的眼睛界标丢失以生成可控的眼睛眨眼。形式上,网络可以写为:
β
{
1
,
.
.
.
,
t
}
=
Φ
M
(
Φ
A
(
a
{
1
,
.
.
.
,
t
}
)
,
z
b
l
i
n
k
,
β
0
)
,
(2)
\beta_{\{1,...,t\}}=\Phi_M(\Phi_A(a_{\{1,...,t\}}),z_{blink},\beta_0),\tag{2}
β{1,...,t}=ΦM(ΦA(a{1,...,t}),zblink,β0),(2)
对于损失函数,我们首先使用 L d i s t i l l \mathcal{L}_{distill} Ldistill来评估仅唇表达系数 R e ( Wav2Lip ( I 0 , a { 1 , . . . , t } ) ) R_e(\text{Wav2Lip}(I_0,a_{\{1,...,t\}})) Re(Wav2Lip(I0,a{1,...,t}))和生成的 β { 1 , … , t } \beta_{\{1,\ldots,t\}} β{1,…,t}。请注意,我们仅使用wav 2lip的第一帧 I 0 I_0 I0来生成嘴唇同步视频,这减少了姿势变量和除嘴唇移动之外的其他面部表情的影响。此外,我们还涉及可微的三维人脸渲染 R d R_d Rd计算额外的感知损失显式面部运动空间。如图3所示,我们计算界标损失 L l k s \mathcal{L}_{lks} Llks以测量眨眼的范围和整体表达准确度。预先训练的唇阅读网络 Φ r e a d e r \Phi_{reader} Φreader也被用作时间唇读损失 L r e a d \mathcal{L}_{read} Lread以保持感知唇质量。
PoseVAE
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K80juqnG-1685335353880)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230517150259943.png)]](https://img-blog.csdnimg.cn/c70162cea0ff44d38f130b4d358977e8.png)
图4.提供(解释)PoseVAE的管道。我们通过条件VAE结构学习输入头部姿态 ρ 0 \rho_0 ρ0的残差。鉴于以下条件:第一帧 ρ 0 \rho_0 ρ0、风格标识 Z s t y l e Z_{style} Zstyle和音频剪辑 a { 1 , … , t } a\{1,\dots,t\} a{1,…,t},我们的方法学习剩余头部姿势 Δ ρ { 1 , . . . , t } = ρ { 1 , . . . , t } − ρ 0 \Delta\rho_{\{1,...,t\}} = \rho_{\{1,...,t\}} - \rho_0 Δρ{1,...,t}=ρ{1,...,t}−ρ0。训练完成后,我们可以通过姿态解码器和条件(cond.)只有。
基于VAE 的模型被设计为学习真实谈话视频的真实和身份感知的风格化头部运动 ρ ∈ R 6 \rho \in \mathbb{R}^6 ρ∈R6。在训练中,使用基于编码器解码器的结构在固定的 n n n个帧上训练姿态VAE。编码器和解码器都是两层MLP,其中输入包含顺序的t-frame头部姿势,并且我们将其嵌入到高斯分布中。在解码器中,学习网络以从采样的分布生成t帧姿态。我们的PoseVAE不是直接生成姿势,而是学习第一帧的条件姿势 ρ 0 \rho_0 ρ0的残差,这使得我们的方法能够在第一帧的条件下在测试中生成更长,稳定和连续的头部运动。此外,根据CVAE,我们添加相应的音频特征 a { 1 , … , t } a\{1,\dots,t\} a{1,…,t}和风格认同 Z s t y l e Z_{style} Zstyle作为节奏意识和认同风格的条件。KL-散度 L K L \mathcal{L}_{KL} LKL用于测量所生成的运动的分布。均方损失 L M S E \mathcal{L}_{MSE} LMSE和对抗损失 L G A N \mathcal{L}_{GAN} LGAN用于确保生成的质量。
3D感知人脸渲染
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rgnRzAl1-1685335353881)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20230517151906831.png)]](https://img-blog.csdnimg.cn/65a588e09ece42598737659e7b2e81fd.png)
图5. FaceRender以及与facevis2vid的比较。给定源图像 I s I_s Is和驱动图像 I d I_d Id,facevis2vid在 X c \mathcal{X}_c Xc、 X s \mathcal{X}_s Xs和 X d \mathcal{X}_d Xd的无监督3D关键点空间中生成运动。然后,可以经由外观 A 0 A_0 A0和关键点来生成图像。由于我们没有驱动图像,我们使用显式解纠缠的3DMM系数作为代理,并将其映射到无监督的3D关键点空间。
在生成逼真的3D运动系数后,我们通过一个精心设计的3D感知图像动画渲染最终的视频。我们从最近的图像动画方法face-vid 2 vid 中获得灵感,因为它隐式地从单个图像中学习3D信息。然而,在他们的方法中,需要真实的视频作为运动驱动信号。我们的面部渲染使其可通过3DMM系数驱动。如图5所示,我们提出mappingNet来学习显式3DMM运动系数(头部姿势和表情)与隐式无监督3D关键点之间的关系。我们的mappingNet是通过几个1D卷积层构建的。我们使用来自时间窗口的时间系数作为PIRenderer 进行平滑。不同的是,我们发现PIRenderer中的人脸对齐运动系数将极大地影响音频驱动视频生成的运动自然度。
至于训练,我们的方法包含两个步骤。首先,我们像原始论文中一样以自我监督的方式训练face-vid 2 vid 。在第二步中,我们冻结外观编码器、规范关键点估计器和图像生成器的所有参数以进行调整。然后,我们以重建方式在地面实况视频的3DMM系数上训练映射网络。我们使用 L 1 \mathcal{L}_1 L1损失在无监督关键点域中给予监督,并根据其原始实现最终生成视频。更多细节可以在补充材料中找到。
实验
数据集
我们使用VoxCeleb[26]数据集训练包含超过100 k的视频1251科目。我们作物原始视频后之前的图像动画方法[36]和调整到256×256的视频。预处理后的数据是我们FaceRender用来训练。因为一些视频和音频VoxCeleb不一致,我们选择1890对齐的视频和音频的46个科目训练PoseVAE ExpNet。输入音频down-sampled 16赫兹和转换为mel-spectrograms一样设置Wav2lip [30]。为了测试我们的方法,我们使用346视频的第一个8秒视频(总共约70k帧)来自HDTF数据集[49],因为它包含高分辨率和野外说话的头部视频。这些视频也会按照[36]进行裁剪和处理,并将大小调整为256 ×256以进行评估。我们使用每个视频的第一帧作为参考图像来生成视频。
实施细节
所有ExpNet,PoseVAE和FaceRender都是单独训练的,我们使用Adam优化器[20]进行所有实验。在训练之后,我们的方法可以以端到端的方式推断,而无需任何手动干预。所有3DMM参数都是通过预训练的深度3D人脸重建方法提取的[5]。我们在8个A100 GPU上进行所有实验。ExpNet、PoseVAE和FaceRender的学习率分别为2e−5、1e−4和2e−4。至于时间上的考虑,ExpNet使用连续的5帧来学习。PoseVAE通过连续32帧学习。FaceRender中的帧是使用5个连续帧的系数逐帧生成的,以确保稳定性。
结果对比
![[外链图片转存中...(img-u4v0YwdT-1685335353881)]](https://img-blog.csdnimg.cn/d179f24f2a68456b83168f8692d1f06c.png)
表1.与HDTF数据集上的最新方法进行比较。我们在单次设置中评估了Wav 2Lip [30]和PC-AVS [51]。Wav 2Lip * 实现了最佳视频质量,因为它只对嘴唇区域进行动画处理,而其他区域与原始帧相同。PC-AVS** 使用固定参考姿态进行评估,并且在一些样本中失败。