爬虫、反爬虫和反反爬虫是网络爬虫工作过程中一直伴随的问题。
在现实生活中,网络爬虫的程序并不像之前介绍的爬取博客那么简单,运行效果不如意者十有八九。首先需要理解一下“反爬虫”这个概念,其实就是“反对爬虫”。根据网络上的定义,网络爬虫为使用任何技术手段批量获取网站信息的一种方式。“反爬虫”就是使用任何技术手段阻止批量获取网站信息的一种方式。
01、为什么会被反爬虫
对于一个经常使用爬虫程序获取网页数据的人来说,遇到网站的“反爬虫”是司空见惯的。
那么,网站为什么要“反爬虫”呢?
第一,网络爬虫浪费网站的流量,也就是浪费钱。爬虫对于一个网站来说并不算是真正用户的流量,而且往往能够不知疲倦地爬取网站,更有甚者,使用分布式的多台机器爬虫,造成网站浏览量增高,浪费网站流量。
第二,数据是每家公司非常宝贵的资源。在大数据时代,数据的价值越来越突出,很多公司都把它作为自己的战略资源。由于数据都是公开在互联网上的,如果竞争对手能够轻易获取数据,并使用这些数据采取针对性的策略,长此以往,就会导致公司竞争力的下降。因此,有实力的大公司便开始利用技术进行反爬虫。反爬虫是指使用任何技术手段阻止别人批量获取自己网站信息的一种方式。
需要注意的是,大家在获取数据时一定要注意遵守相关法律、法规。我们的爬虫教学仅用于学习、研究用途。
02、反爬虫的方式
在网站“反爬虫”的过程中,由于技术能力的差别,因此不同网站对于网络爬虫的限制也是不一样的。在实际的爬虫过程中会遇到各种问题,可以大致将其分成以下 3 类。
(1) 不返回网页,如不返回内容和延迟网页返回时间。
(2) 返回数据非目标网页,如返回错误页、返回空白页和爬取多页时均返回同一页。
(3) 增加获取数据的难度,如登录才可查看和登录时设置验证码。
1、不返回网页
不返回网页是比较传统的反爬虫手段,也就是在爬虫发送请求给相应网站地址后,网站返回 404 页面,表示服务器无法正常提供信息或服务器无法回应;网站也可能长时间不返回数据,这代表对爬虫已经进行了封杀。
首先,网站会通过 IP 访问量反爬虫。因为正常人使用浏览器访问网站的速度是很慢的,不太可能一分钟访问 100 个网页,所以通常网站会对访问进行统计,如果单个 IP 的访问量超过了某个阈值,就会进行封杀或要求输入验证码。
其次,网站会通过 session 访问量反爬虫。session 的意思“会话控制”, session 对象存储特定用户会话所需的属性和配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在 session 对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。如果一个session 的访问量过大,就会进行封杀或要求输入验证码。
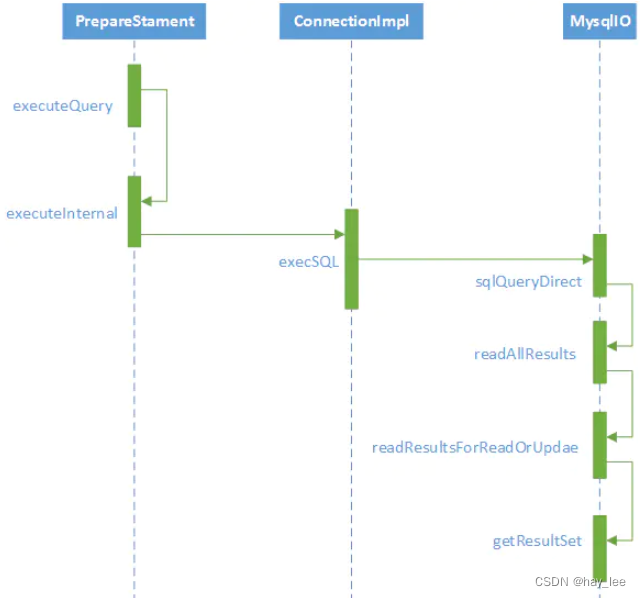
此外,网站也会通过 User-Agent 反爬虫。User-Agent 表示浏览器在发送请求时,附带将当前浏览器和当前系统环境的参数发送给服务器,可以在 Chrome 浏览器的审查元素中找到这些参数。图 1 为 Windows 系统使用 Firefox 访问百度首页的请求头。
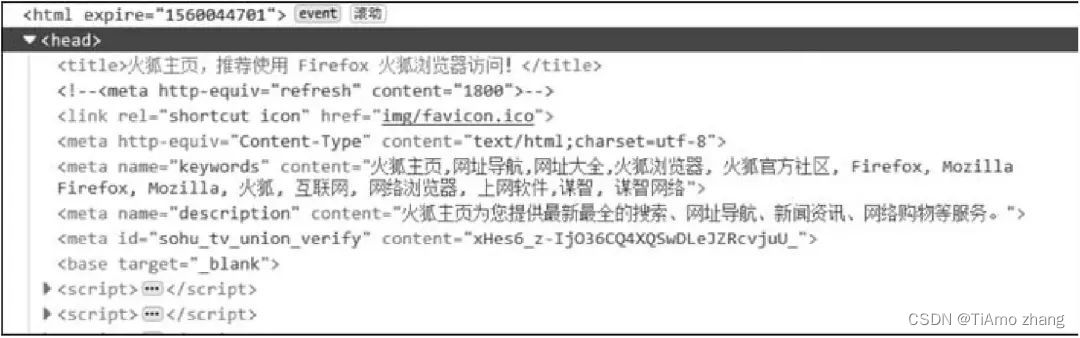
■ 图 1 百度首页请求头
2、返回数据非目标网页
除了不返回网页外,还有爬虫返回非目标网页,也就是网站会返回假数据,如返回空白页或爬取多页的时候返回同一页。当你的爬虫顺利地运行起来,但不久后,如果你发现爬取的每一页的结果都一样,那么这就是获取了假的网站。
3、获取数据变难
网站也会通过增加获取数据的难度反爬虫,一般要登录才可以查看数据,而且会设置验证码。为了限制爬虫,无论是否是真正的用户,网站都可能会要求你登录并输入验证码才能访问。例如,12306 为了限制自动抢票就采用了严格的验证码功能,需要用户在 8 张图片中选择正确的选项。
03、怎样“反反爬虫”
网站利用“反爬虫”阻止别人批量获取自己的网站信息。但是“道高一尺,魔高一丈”,负责写网站爬虫程序的人又针对网站的“反爬虫”进行了“反反爬虫”,也就是突破网站的“反爬虫”限制,让爬虫程序能够运行下去。
对于如何让爬虫顺利运行,其中心思想是让爬虫程序看起来更像正常用户的浏览行为。正常用户是使用一台计算机的一个浏览器浏览,而且速度比较慢,不会在短时间浏览过多的页面。对于一个爬虫程序而言,就需要让爬虫运行得像正常用户一样。常见的反爬虫的原理有:
检查 User-Agent ;检验访问频率次数,封掉异常 IP ;设置验证码;Ajax 异步加载等。下面介绍相应的对策。
1、修改请求头
为了被反爬虫,可以修改请求头,从而实现顺序获取网页的目的。
如果不修改请求头,header 就会是 python-requests ,例如:
import requests
r = requests get('http://www.baidu.com')
print(r.request.headers)运行程序,输出如下:
["User - Agent": 'python - requests/2.19.1,'Accept - Encoding':'gzip,deflate',
'Accept':'*/*',
Connection': keep - alive"]最简单的方法是将请求头改成真正浏览器的格式,例如:
import requests
link = "http://www.baidu.comheaders = ('User - Agent': 'Mozilla/5.0(Windows;U; Windows NT6.1; en - US; rv:1.9.1.6)Gecko/
20230529 Firfox/3.5.6'}
r = requests.get(link,headers = headers)
print(r.request.headers)运行程序,输出如下:
('User - Agent': 'Mozilla/5.0(Windows;U; Windows NT6.1;en - US;rv:1.9.1.6)
Gecko/20230529.Firfox/3.5.6',Accept-Encoding': 'gzip,deflate','Accept':'*/*Connection': 'keepalive}由结果可以看到,header 已经变成使用浏览器的 header 。
此外,也可以做一个 User-Agent 的池,并且随机切换 User-Agent 。但是,在实际爬虫中,针对某个 User-Agent 的访问量进行封锁的网站比较少,所以只将 User-Agent 设置为正常的浏览器 User-Agent 就可以了。
除了 User-Agent ,还需要在 header 中写上 Host 和 Referer。
2、修改爬虫访问周期
爬虫访问太密集,一方面对网站的浏览极不友好;另一方面十分容易招致网站的反爬虫。因此,当访问程序时应有适当间隔;爬虫访问间隔相同也会被识别,应该具有随机性。
import time
t1=time.time()
time.sleep(3)
t2=time.time()
total_time=t2-t1
print(total_time)运行程序,输出如下:
3.0006399154663086你的结果可能和这个不一样,但是应该约等于 3 秒。也就是说,可以使用 time.sleep (3 )让程序休息 3 秒,括号中间的数字代表秒数。
如果使用一个固定的数字作为时间间隔,就可能使爬虫不太像正常用户的行为,因为真正的用户访问不太可能出现如此精准的秒数间隔。所以还可以用 Python 的 random 库进行随机数设置,代码为:
import time
import random
sleep_time=random.randint(1,5)+random.random()
print(sleep_time)
total=time.sleep(sleep_time)运行程序,输出如下:
3.361699347950341你的结果可能和这个不一样,但是应该在 0~5 秒。这里 random.randint ( 0 , 5 )的结果是 0 、1 、 2 、 3 、 4 或 5 ,而 random.random ()是一个 0~1 的随机数。这样获得的时间非常随机,更像真正用户的行为。
3、使用代理
代理(Proxy )是一种网络服务,允许一个网络终端(客户端)与另一个网络终端(服务器)间接连接。形象地说,代理就是网络信息的中转站。代理服务器就像一个大的缓冲,这样能够显著提高浏览速度和效率。可以维护一个代理的 IP 池,从而让爬虫隐藏自己真实的 IP 。虽然有很多代理,但良莠不齐,需要筛选。维护代理 IP 池比较麻烦,而且十分不稳定。以下是使用代理 IP 获取网页的方法:
import requests
link='http://santostang.com'
proxies={'http':'http://xxx.xxx.xxx.xxx'}
resp=requests.get(link,proxies=proxies)
由于代理 IP 很不稳定,这里就不放出代理 IP 的地址了。其实不推荐使用代理 IP 方法,一方面,虽然网络上有很多免费的代理 IP ,但是都很不稳定,可能一两分钟就失效了;另一方面,通过代理 IP 的服务器请求爬取速度很慢。
03、文末送书

《深入理解计算机系统(原书第3版)》 作者:兰德尔 E. 布莱恩特 大卫 R. 奥哈拉伦

《算法导论(原书第3版)》 作者:Thomas H.Cormen, Charles E.Leiserson, Ronald L.Rivest, Clifford Stein

《数据库系统概念(原书第7版)》 作者:亚伯拉罕·西尔伯沙茨 亨利·科思 S. 苏达尔尚

《计算机网络:自顶向下方法(原书第7版)》 作者:詹姆斯·F. 库罗斯、基思·W. 罗斯

《编译原理(原书第2版)》 作者:Alfred V. Aho, Monica S. Lam 等

《现代操作系统(原书第4版)》 作者:安德鲁 S. 塔嫩鲍姆、赫伯特·博斯

《数据结构与算法分析:C语言描述(原书第2版)典藏版》 作者:马克·艾伦·维斯

《TCP/IP详解》 作者:Kevin R. Fall, W. Richard Stevens, Gary R. Wright

《计算机组成与设计:硬件/软件接口(原书第5版)》 作者:戴维·A. 帕特森 约翰·L. 亨尼斯

《C程序设计语言(第2版·新版)典藏版》 作者:[美]布莱恩· W.克尼汉,丹尼斯· M.里奇

《C++程序设计语言(原书第4版)》 作者:(美)本贾尼·斯特劳斯特鲁普

《设计模式:可复用面向对象软件的基础(典藏版)》 作者:[美] 埃里克·伽玛、 理查德·赫尔姆、 拉尔夫·约翰逊、 约翰·威利斯迪斯
了解更多秒杀神书点击:http://h5.dangdang.com/mix_gys_04001_xs0h
参与方式:文章三连并评论,“按时下班,拒绝内卷!”参与抽奖,48小时后,程序自动抽取6位小伙伴获得技术图书一本【以上图书任选】,欢迎大家积极参与!