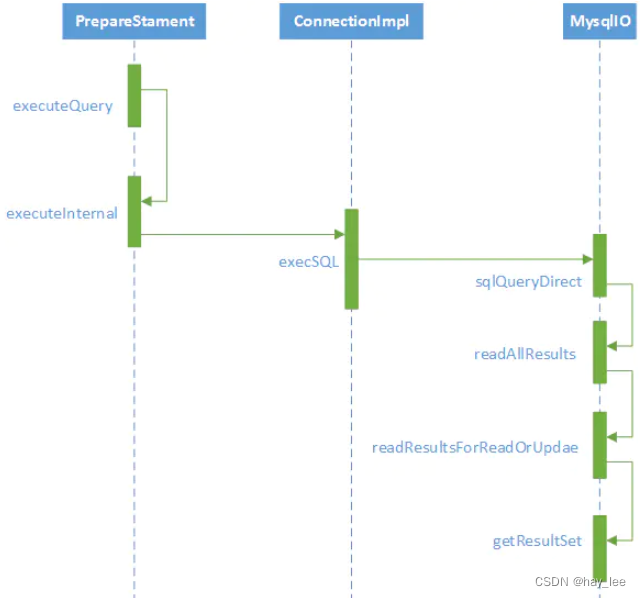
如:天空

coco包含pascal voc 的所有类别,并且对每个类别的标注目标个数也比pascal voc的多。
一般使用coco数据集预训练好的权重来迁移学习。

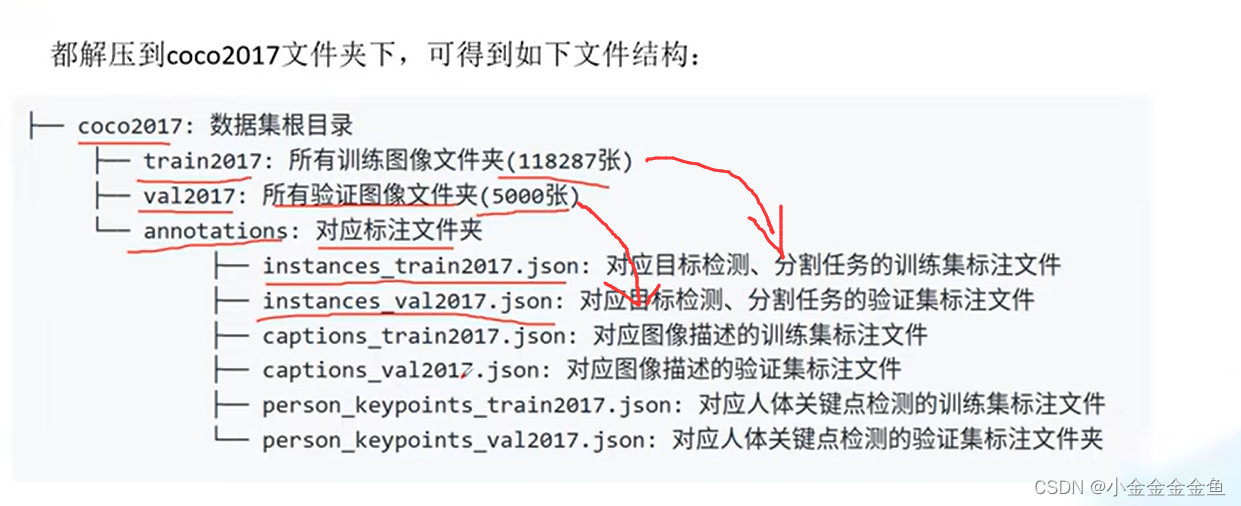
如果仅仅针对目标检测object80类而言,有些图片并没有标注信息,或者有错误标注信息。所以在实际的训练过程中,需要对这些数据进行简单筛选。
为什么之前那些都没在测试集上测试?
自己去训练自己数据的话,只需要训练集和验证集测试就行,并不需要单独划分一个测试集。
因为基本都是在同样的数据分布下进行划分的,测试集的数据分布与验证集的数据分布一样。没有必要单独划分测试集。
一般在大型的比赛中会用到测试集。为防止作弊,一般不告诉测试集数据分布信息。所以对自己的数据单独划分测试集没有意义。

通过python的json库来看json文件中存储的标注形式
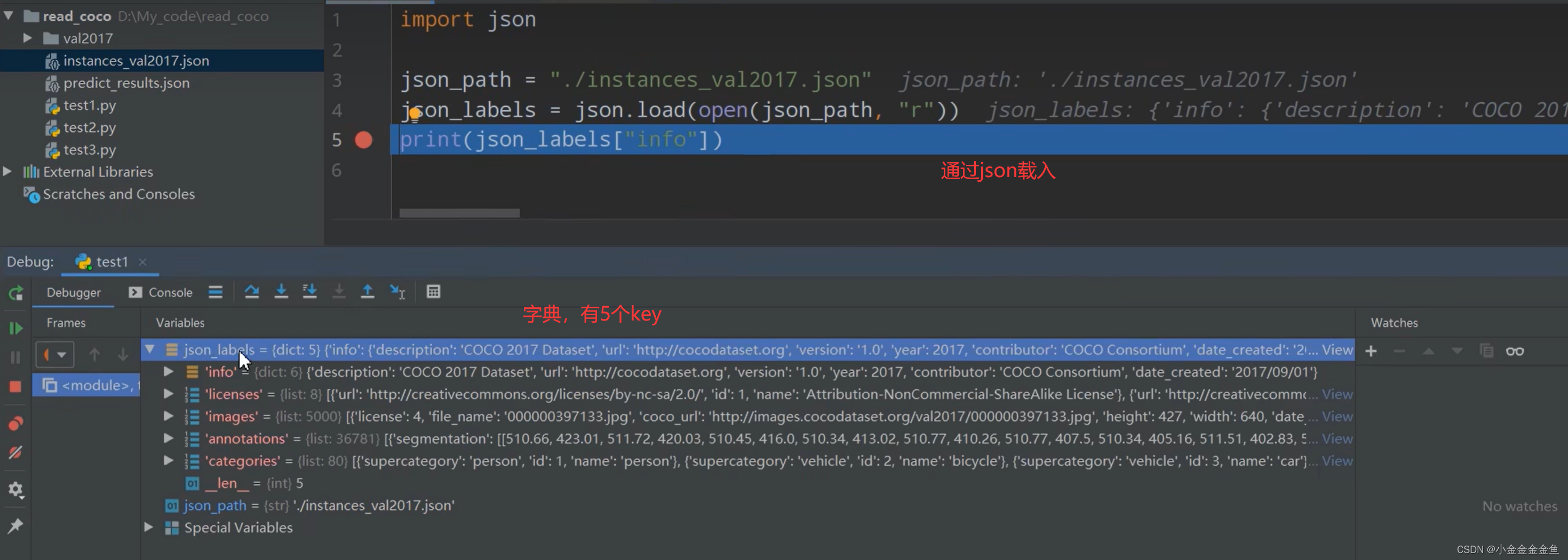

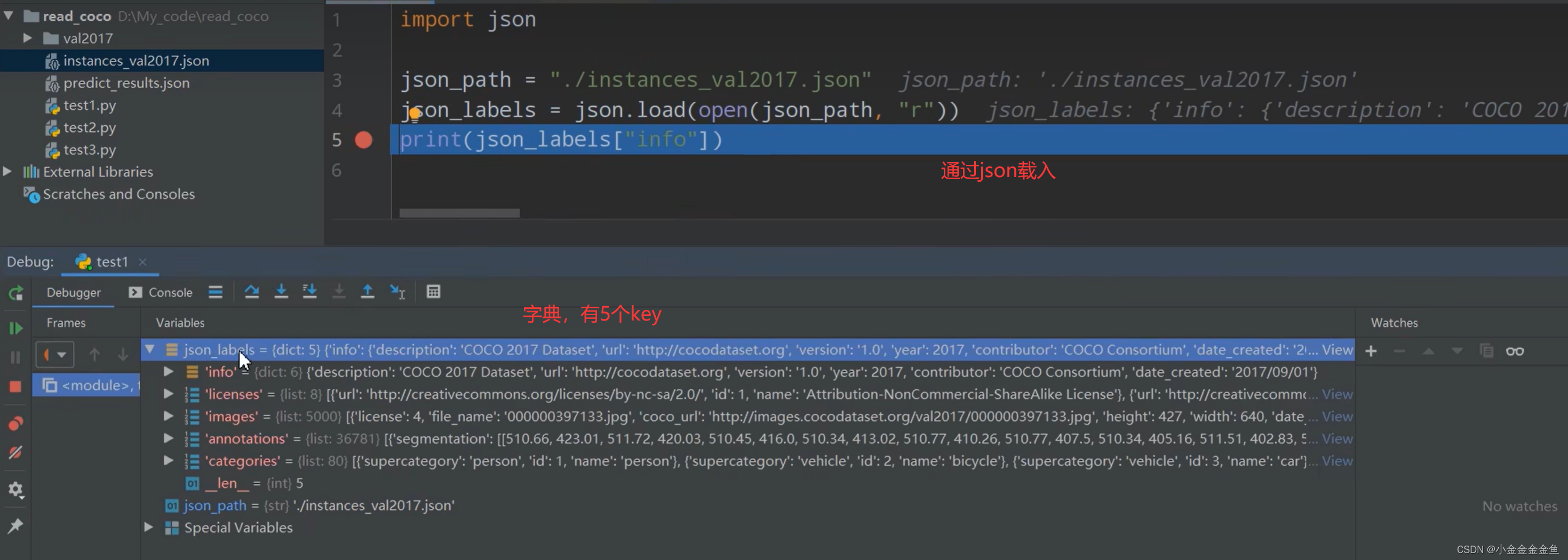
images:
可以看到有5000张图片(读取的验证集),每个元素对应的是一张图片的信息。
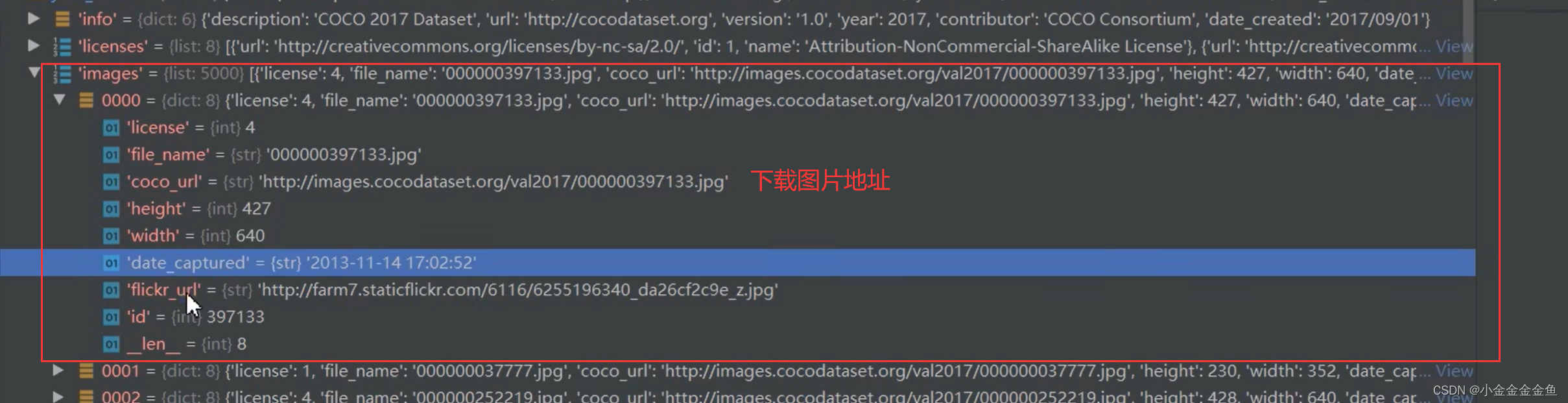
annotations:
36781个,每个元素对应的是一个目标,并不是一张图片下所有目标。
也就是说,在这5000个图像中共有36781个目标。
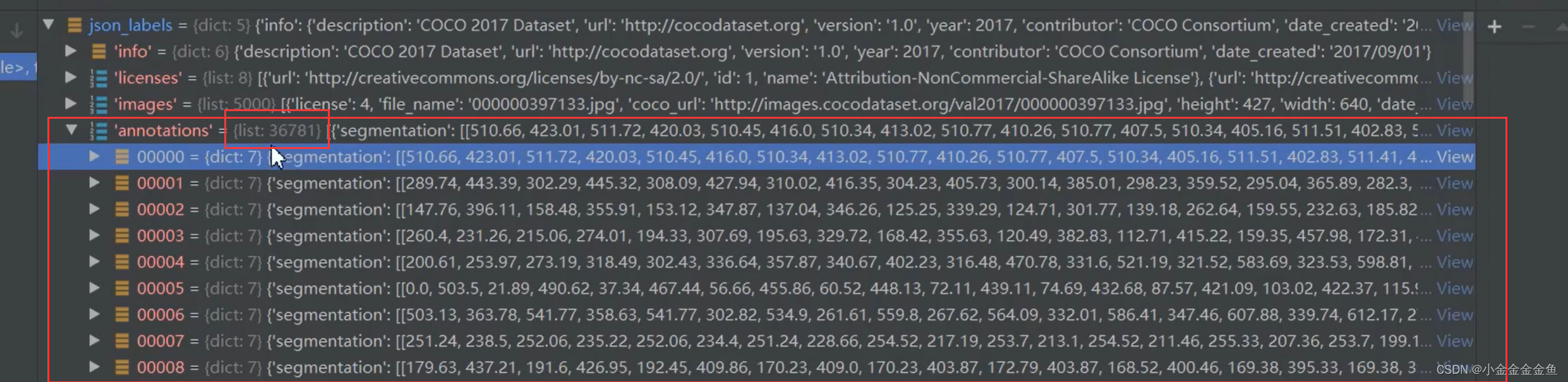
对于每个目标:


category_id所对应的是在stuff91类的目标中的索引。
categories:
总共有80个元素,对应object80的80个类别。
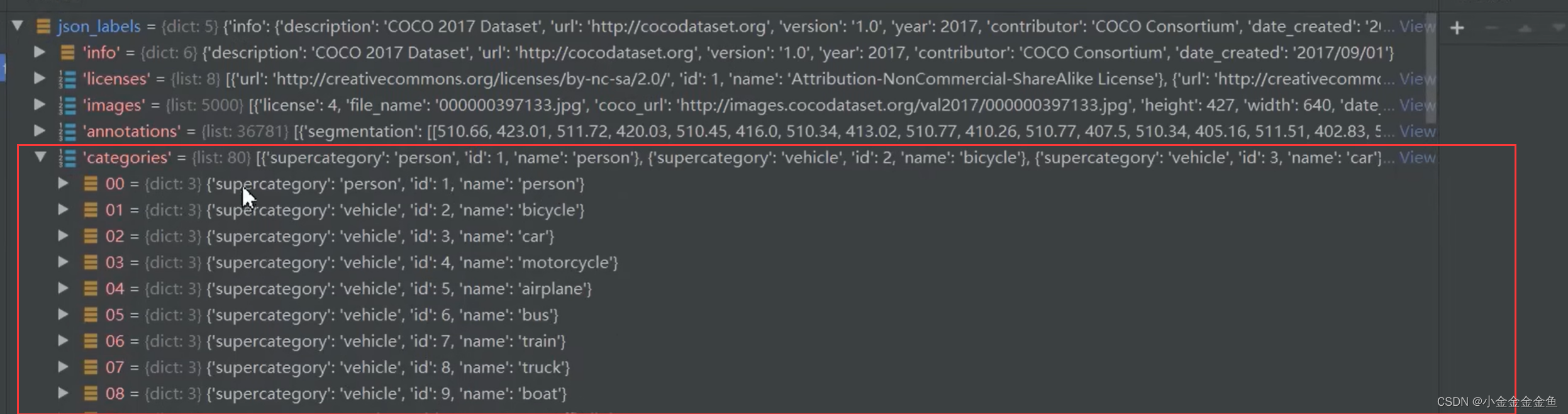
对于每个类别:
超类 一些类别的统称
id:stuff91类中的索引,仔细看并不是1 ~ 80。所以如果后面要去训练80个类别的目标检测的话,需要做一个映射,把这些索引映射到1 ~ 80当中。
使用pycocotools读取标注文件
可对数据进行读取、对预测结果计算mAP
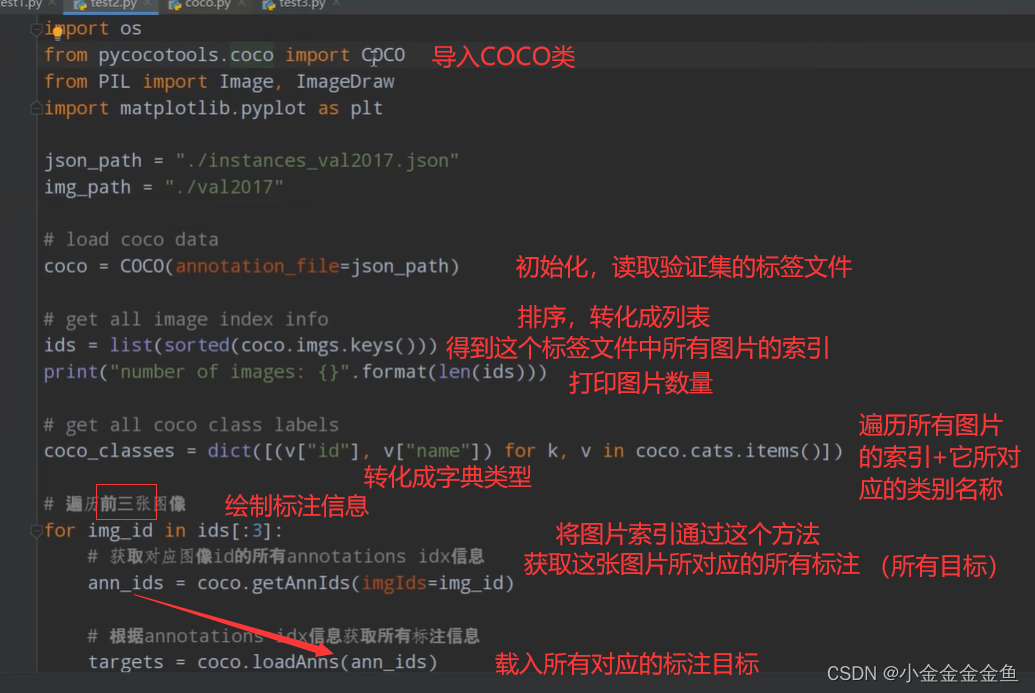
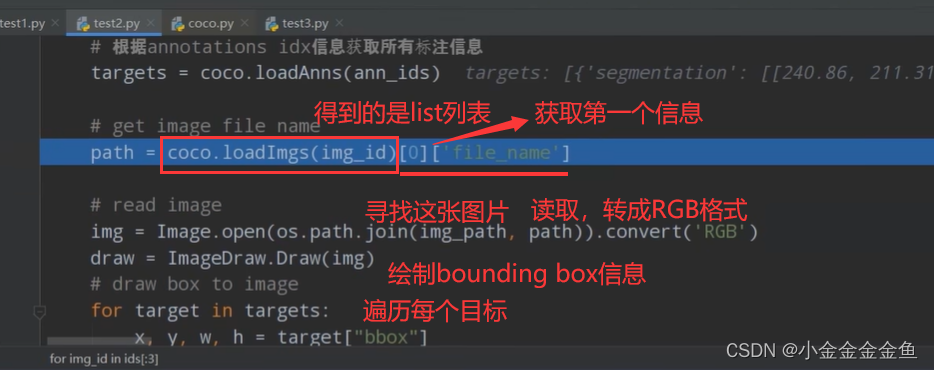
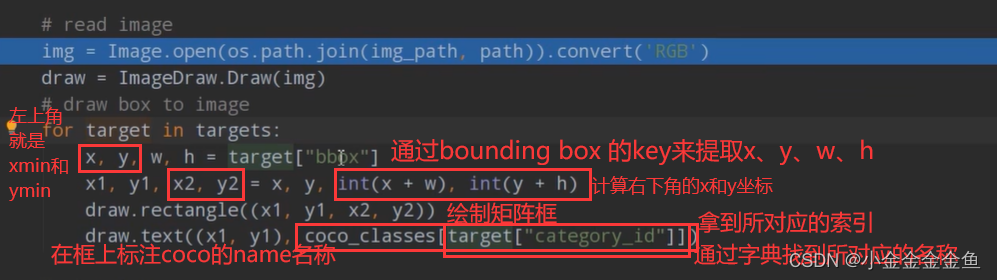

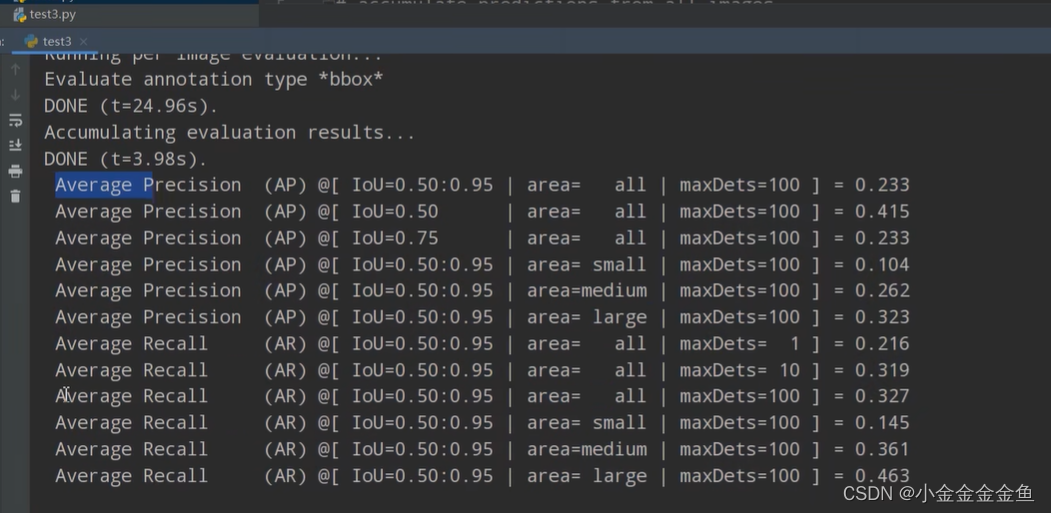
运行得到:
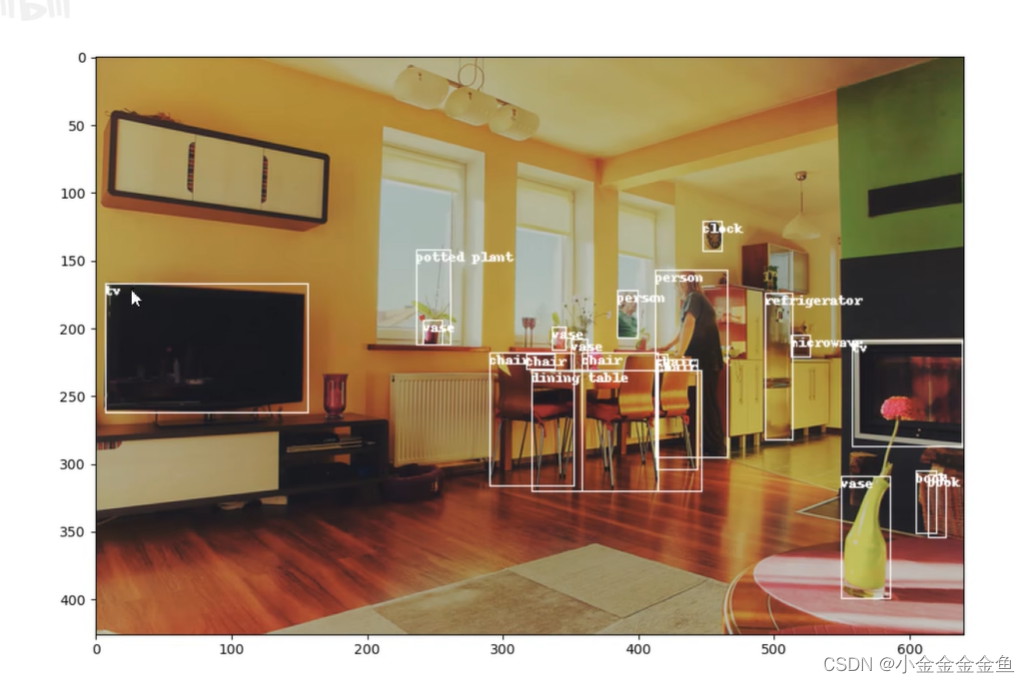
验证集所对应图片+这个图片对应的标注信息+将标注信息绘制在图片上。
验证mAP

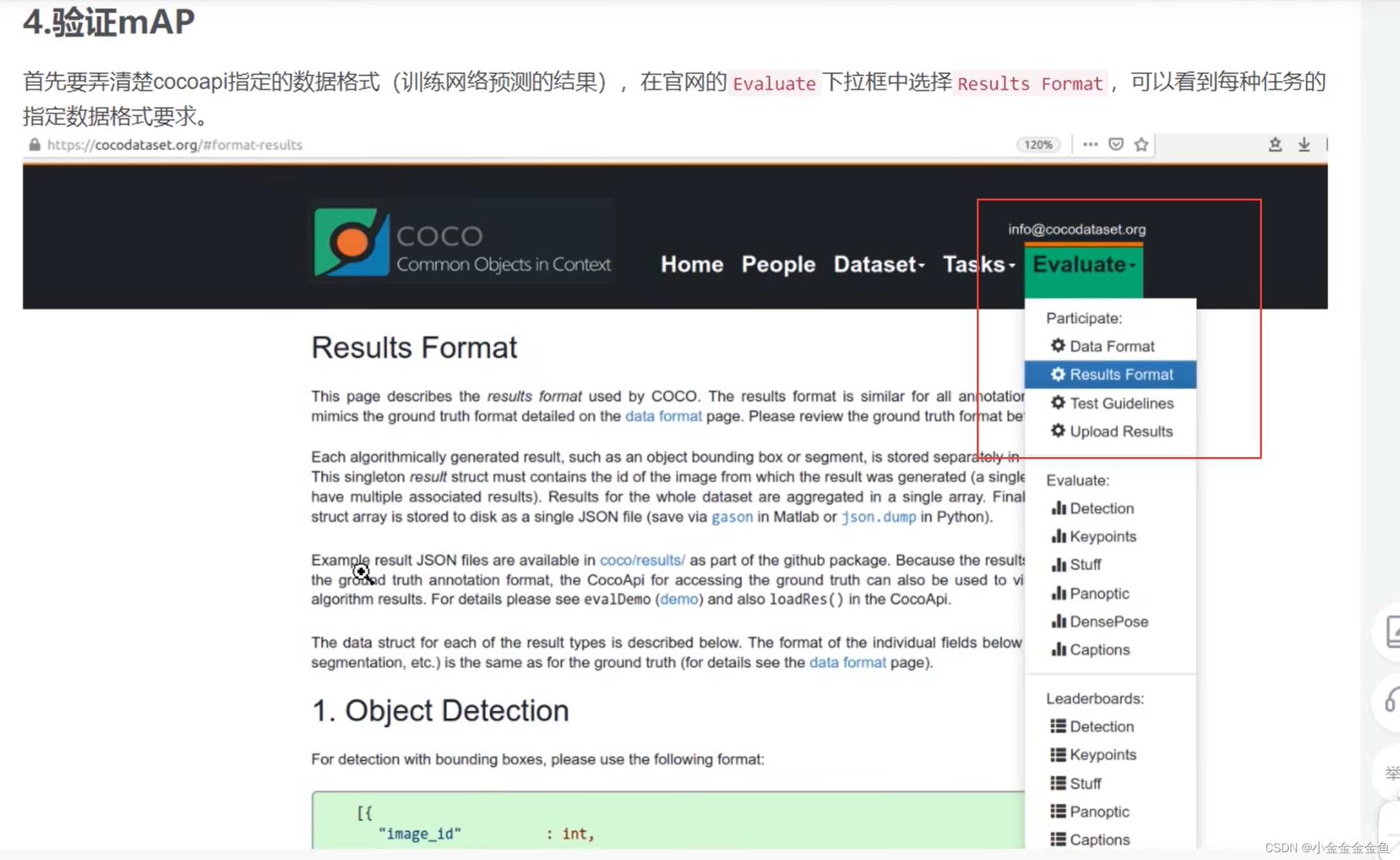
给出了每种任务指定的数据保存格式要求。
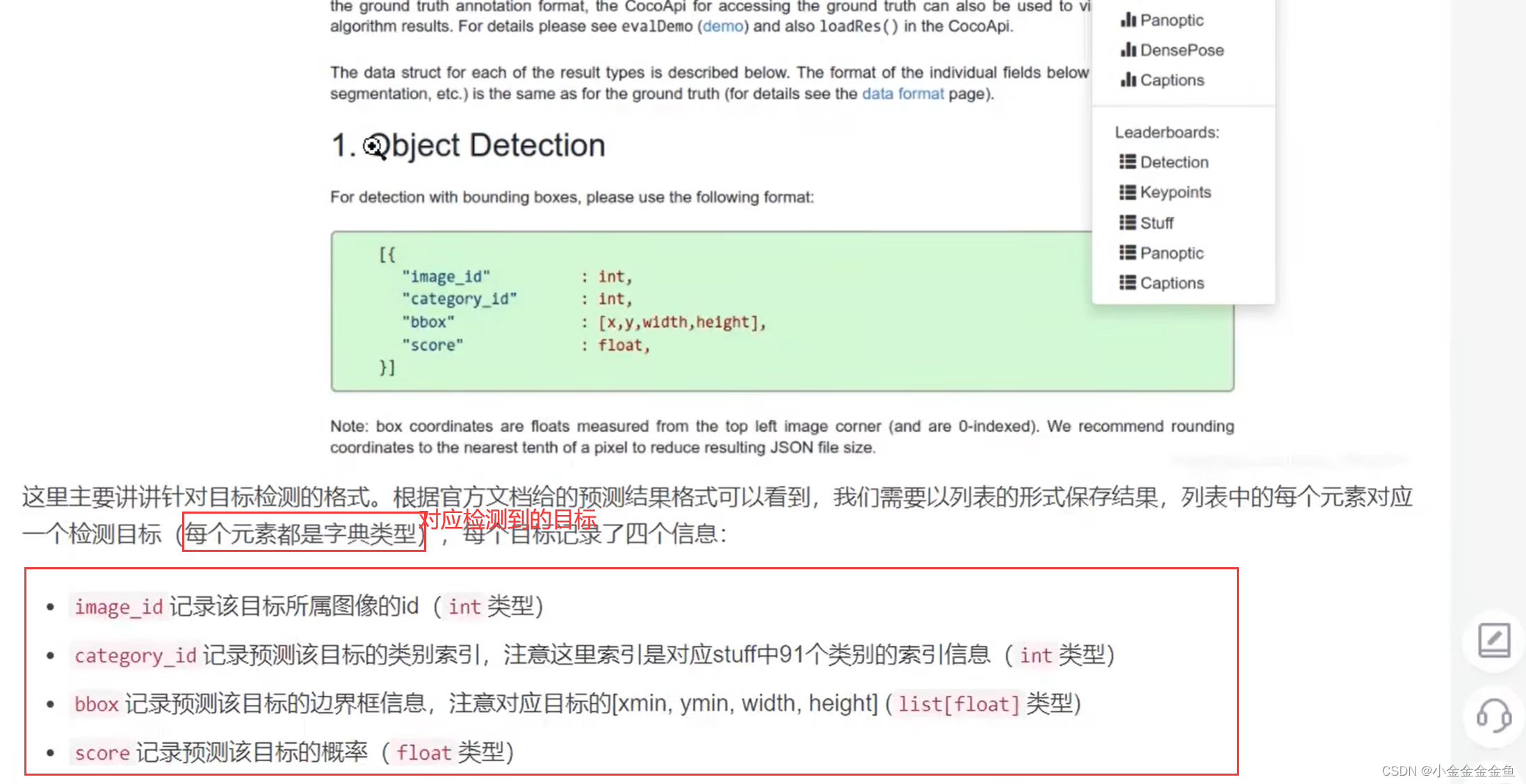
将每一个预测结果都写成了字典形式,将它们全部放入一个列表当中,写成一个json的文件。
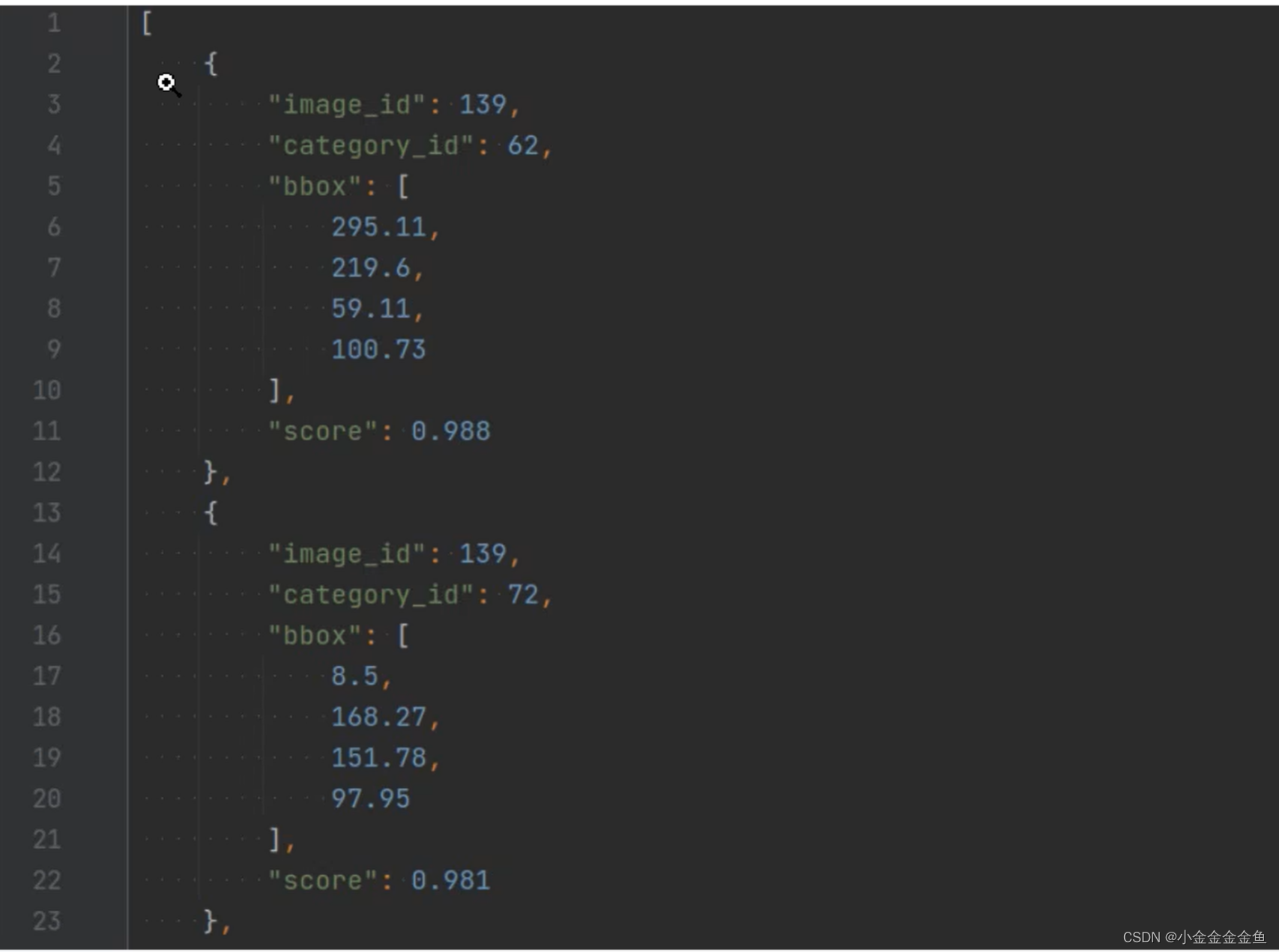
得到文件后,通过对比coco2017中标注好的文件来计算mAP。
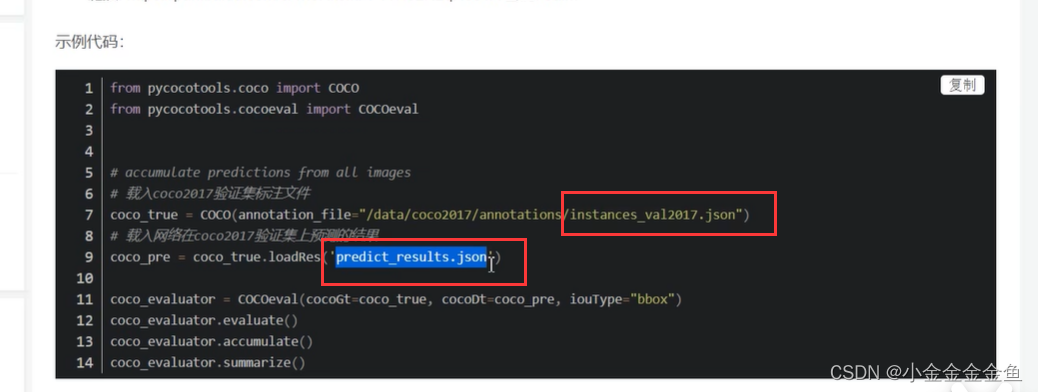
计算方法:
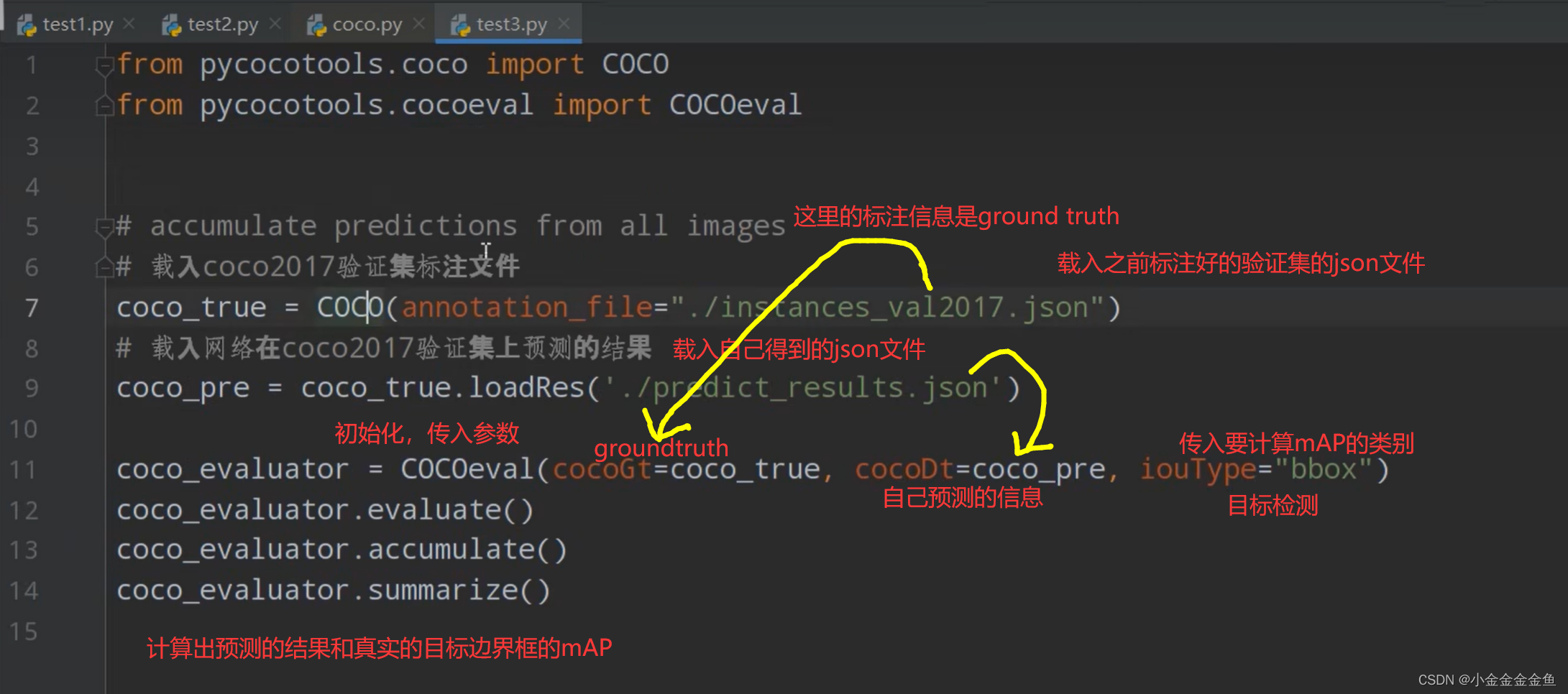
打印出验证集上的coco指标: