一)SDS
在redis中,保存key的是字符串,value往往是字符串或者是字符串的集合,可见字符串是redis中最常用的一种数据结构:
但是在redis中并没有直接使用C语言的字符串,因为C语言的字符串存在很多问题
1)获取字符串的长度需要通过运算
2)非二进制安全,想要获取字符串的长度,恰好有一个字符是/0,那么会读取一半就结束了
3)字面值不可修改,因为这样的字符串保存在字符串常量池中
所以Redis构建了一种新的字符串结构,称之为简单动态字符串,Simple Dynamic String,简称为SDS,如果执行了命令set name zhangsan 那么会构建一个是name的SDS,还有一个是zhangsan的SDS

1)len:表示无符号整型8个比特位表示的数据范围是0-255,允许的最长的字符串长度是255个字节
2)alloc:因为在C语言里面,要是想创建任意类型的结构,内存空间必须要程序员手动进行申请,但是申请的字节数不一定是和字符串申请的总字节数一样大

前三个是对结构体的描述信息,真正读字符串的时候是根据len来进行读取的

SDS的优点:
1)获取字符串长度的时间复杂度是O(1),因为SDS中已经保存了字符串的长度,不需要重新计算
2)支持动态扩容
3)减少内存分配次数
4)二进制安全


二)IntSet
IntSet是Redis中set集合实现的一种方式,是基于整数数组来实现的,并且具备长度可变,有序等特征
为了方便查找,Redis会将inset中的所有的整数按照升序依次存放到contents数组中
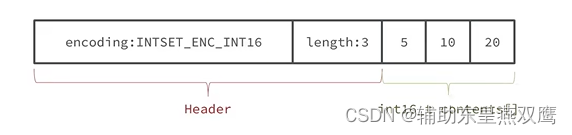
现在数组中每一个数字都是在int_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,那么每一个部分所占用的字节大小就是14字节,contents中每一个元素大小都是统一的为了方便寻址
encoding:4个字节,length:4个字节,contents:2*3=6字节(为了方便寻址,找到对应的元素)
假设现在有一个inset,元素是{5,10,15},采用的编码是INTSET_ENC_INT16,每一个整数占2个字节
现在我们向其中添加一个数字,50000,这个数字超出了int16_t的范围,intset就会自动将编码方式调到合适的大小,以当前案例来说,流程如下:
1)升级编码为INTSET_ENC_INT32,每一个整数占用4个字节,并按照新的编码方式以及元素个数进行扩容数组
2)倒序依次按照数组中的元素拷贝到扩容时的正确位置,先设置20的位置,2*4=8,从8位置开始进行设置20元素,否则按照正序会出现元素覆盖
3)将带添加的元素放到数组末尾


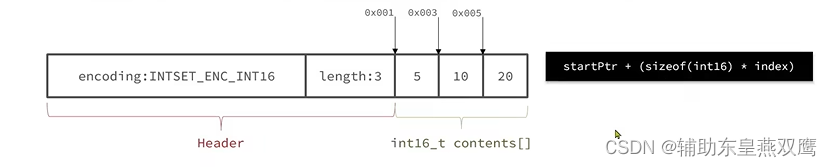

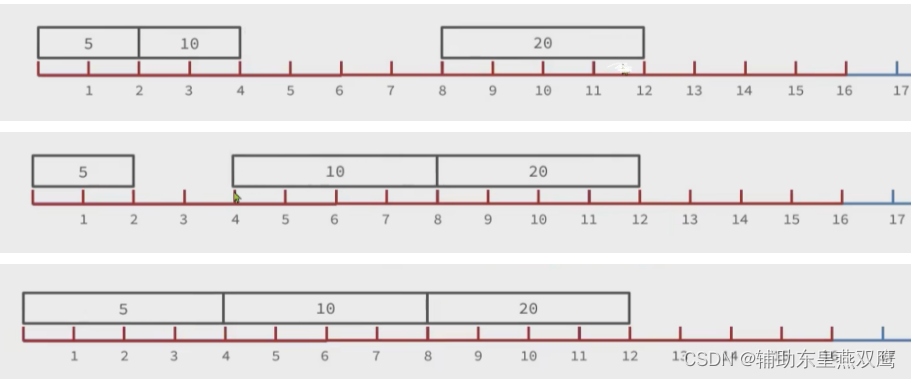
4)最后将inset中的encoding属性改成INTSET_ENC_INT32,并将length属性改成4
/* Insert an integer in the intset */ 第一个参数是当前你要插入的元素,第二个参数是你要向哪一个intset中插入 第三个参数标识插入成功还是失败 intset *intsetAdd(intset *is, int64_t value, uint8_t *success) { // 获取当前要插入的元素的编码 uint8_t valenc = _intsetValueEncoding(value); // 要插入到setint的位置 uint32_t pos; if (success) *success = 1; /* Upgrade encoding if necessary. If we need to upgrade, we know that * this value should be either appended (if > 0) or prepended (if < 0), * because it lies outside the range of existing values. */ if (valenc > intrev32ifbe(is->encoding)) { 判断要插入的值的编码是不是超过了当前inset的编码 /* This always succeeds, so we don't need to curry *success. */ 当前插入的值的编码超出当前inset编码则需升级 return intsetUpgradeAndAdd(is,value); } else { /* Abort if the value is already present in the set. * This call will populate "pos" with the right position to insert * the value when it cannot be found. */ if (intsetSearch(is,value,&pos)) { 在当前inset中查找值与value一样的元素的角标pos if (success) *success = 0; 如果找到了,则无需插入,直接结束并返回失败 return is; } 除了循环之后pos的位置是恰好是intset中的元素比当前要插入的新元素大的位置 数组扩容 is = intsetResize(is,intrev32ifbe(is->length)+1); 移动数组中pos之后的元素到pos+1,给新元素腾出空间 if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); } 在pos位置插入新元素 _intsetSet(is,pos,value); is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is; }既然要插入的新的元素已经超出了原有的编码范围了,那么新插入的元素相比数组中的元素是大还是小呢?是都有可能的,因为这个数字可能是正数,比数组中的所有元素都大,要么是负数,比数组中的所有元素都小,所以说最后的元素要么插入在所有元素之后,要么插入在所有元素之前;
/* Upgrades the intset to a larger encoding and inserts the given integer. */ static intset *intsetUpgradeAndAdd(intset *is, int64_t value) { // 获取当前intset编码 uint8_t curenc = intrev32ifbe(is->encoding); // 获取当前要插入的值的编码,也就是未来intset新的编码 uint8_t newenc = _intsetValueEncoding(value); // 获取inset中的元素个数 int length = intrev32ifbe(is->length); / 判断新元素是大于0还是小于0,小于0插入队首,大于0插入队尾 int prepend = value < 0 ? 1 : 0; /* First set new encoding and resize */ // 重置编码为新编码 is->encoding = intrev32ifbe(newenc); // 重置数组大小,尝试申请数组空间 is = intsetResize(is,intrev32ifbe(is->length)+1); /* Upgrade back-to-front so we don't overwrite values. * Note that the "prepend" variable is used to make sure we have an empty * space at either the beginning or the end of the intset. */ while(length--) /* 倒序便利,逐个搬运元素到新的位置 _intsetGetEncoded按照旧编码方式查找旧元素 _intsetSet按照新编码方式插入新元素 */ 第一个参数时intset 第二个参数是角标也就是元素的位置,如果是1表示当前这个要插入的数字是负数,就意味着要查在数组的第一个位置,所以当前角标数+1,如果是0那么意味着这个元素是正数,一定是将来插入数组的最后一个元素,那么对应的交标数就不会发生变化 第三个参数是要调整的元素(先通过_intsetGetEncodedc查找旧的元素在intset中的位置) _intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* Set the value at the beginning or the end. */ if (prepend) // 插入新元素,prepend决定是队首还是队尾,为0表示向0号位置插入 _intsetSet(is,0,value); else _intsetSet(is,intrev32ifbe(is->length),value); // 修改数组长度 is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is; }/* Search for the position of "value". Return 1 when the value was found and * sets "pos" to the position of the value within the intset. Return 0 when * the value is not present in the intset and sets "pos" to the position * where "value" can be inserted. */ static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) { // 初始化二分查找需要的min,max,mid int min = 0, max = intrev32ifbe(is->length)-1, mid = -1; int64_t cur = -1; // mid对应的值 /* The value can never be found when the set is empty */ if (intrev32ifbe(is->length) == 0) { // 如果数组为空则不用找 if (pos) *pos = 0; return 0; } else { // 数组不为空则判断value是否大于最大值,小于最小值 /* Check for the case where we know we cannot find the value, * but do know the insert position. */ if (value > _intsetGet(is,max)) { // 大于最大值则直接插入队尾 if (pos) *pos = intrev32ifbe(is->length); return 0; } else if (value < _intsetGet(is,0)) { // 小于最小值则插入队首 if (pos) *pos = 0; return 0; } } // 二分查找 while(max >= min) { mid = ((unsigned int)min + (unsigned int)max) >> 1; cur = _intsetGet(is,mid); if (value > cur) { min = mid+1; } else if (value < cur) { max = mid-1; } else { break; } } if (value == cur) { if (pos) *pos = mid; return 1; } else { if (pos) *pos = min; return 0; } }intset可以看作是特殊的整数数组,是具备一些特点的:
1)Redis会保证IntSet中的数组元素的个数是唯一的
2)具备类型升级机制,可以节省内存空间
3)底层使用二分查找的方式进行查询
Dict:
redis是一个键值型的数据库,可以根据键快速实现增删改查功能,而键和值的映射关系是通过Dict来实现的
Dict由三部分组成,分别是哈希表,哈希节点,字典
//相当于是哈希表中的节点 typedef struct dictEntry{ //键,SDS结构 void *key; //值,可以是指针,或者是整数 union{ void *val; unit64_tu64; int64_ts64; }v; //指针,指向下一个dictEntry,形成链表 struct dictEntry *next; }dictEntry;//相当于是哈希表 typedef struct dictht{ //table数组,存放dickEntry dickEntry **table; //记录哈希表的大小,即table数组的大小 unsigned long size; //哈希表掩码,等于size - 1,用来和哈希值做&运算,运算更快 unsigned long sizemask; //哈希表中哈希表节点的数量 unsigned long used; }dictht;typedef struct dict{ //类型函数 dickType *type; //私有数据 void *privdata; //哈希表 dictht ht[2]; //rehash索引 //-1时表示没有在进行rehash in trehashidx; }dict;当向Dict添加键值对的时候,Redis首先会根据Key计算出hash值,然后再来利用哈希值&sizemark来计算出元素存储到哈希表的位置;

字典:
type:不同的场景下使用不同的dictType也就是不同的哈希函数




Dict的扩容:
1)Dict中的HashTable就是使用数组和双向链表的实现,当集合中元素个数比较多的时候,必然会导致哈希冲突增多,链表过长,还会导致查询效率大大降低
2)Dict在进行新增键值对的时候都会检查负载因子(used/size),在满足下面两种情况的时候会触发扩容:
2.1)哈希表的负载因子大于1,况且服务器没有执行bgsave或者AOF重写操作等后台进程,因为执行这些进程会使CPU的使用是非常高,而且还会有大量IO的读写,会影响redis主进程的阻塞;
2.2)哈希表的负载因子大于5
dict_can_size是redis内部维护的一个变量,表示如果bgsave或者AOF重写操作执行,会把这个变量变成0,如果没有执行后台进程,那么会把这个值变成1
dict_force_resize_ratio是5

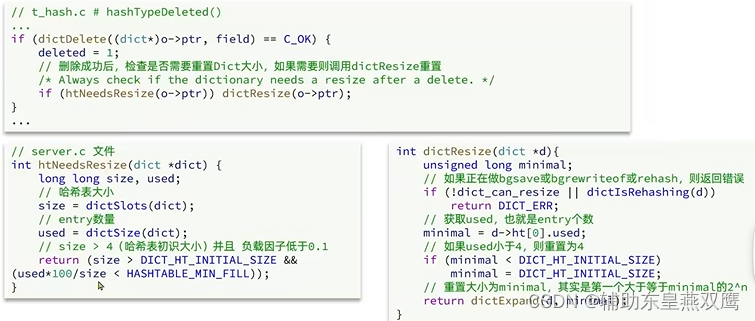
Dict的收缩
Dict除了做扩容之外,每一次删除元素的时候也会对负载因子做检查,当负载因子小于0.1并且哈希表中的元素个数大于4才会做收缩