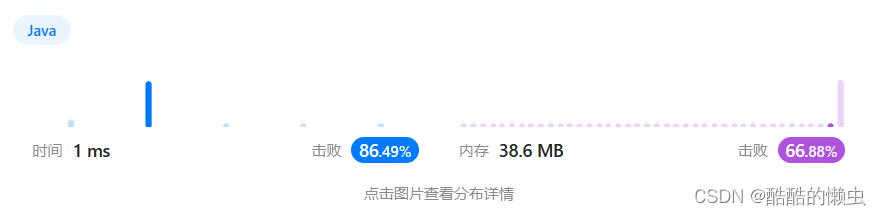
交叉访问是全局内存中最糟糕的访问模式,因为它浪费总线带宽
使用多个线程块对基于交叉的全局内存访问重新排序到合并访问
https://mp.weixin.qq.com/s/h2XKth1bTujnrxyXTJ2fwg
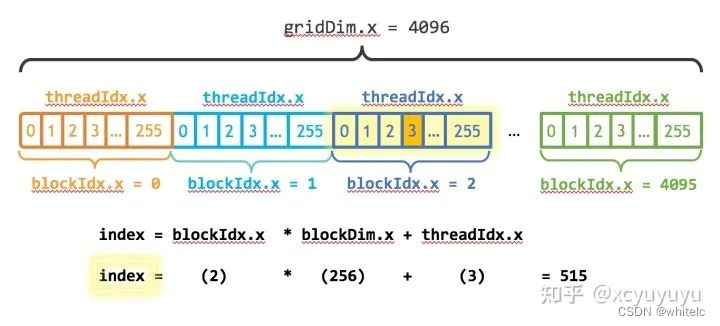
<<<numBlocks, blockSize>>> 的两个参数应该怎么设置好呢。首先,CUDA GPU 使用大小为 32 的倍数的线程块运行内核,因此 blockSize 的大小应该设置为32的倍数,例如128、256、512等。确定 blockSize 之后,可以根据for循环的总个数N确定 numBlock 的大小(注意四舍五入的误差):
int numBlock = (N + blockSize - 1) / blockSize;
这是我项目的路径
F:\E_cuda\3D_PML_share\3d_share2\3d_share2
- 打开 cmd
- 输入
cd F:\E_cuda\3D_PML_share\3d_share2\3d_share2 - 输入
f:因为我是F盘,你们是E盘就输入 e: 以此类推 - 输入
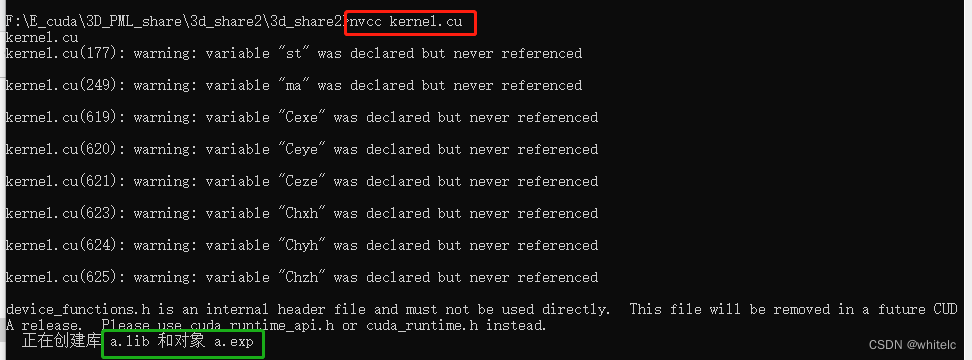
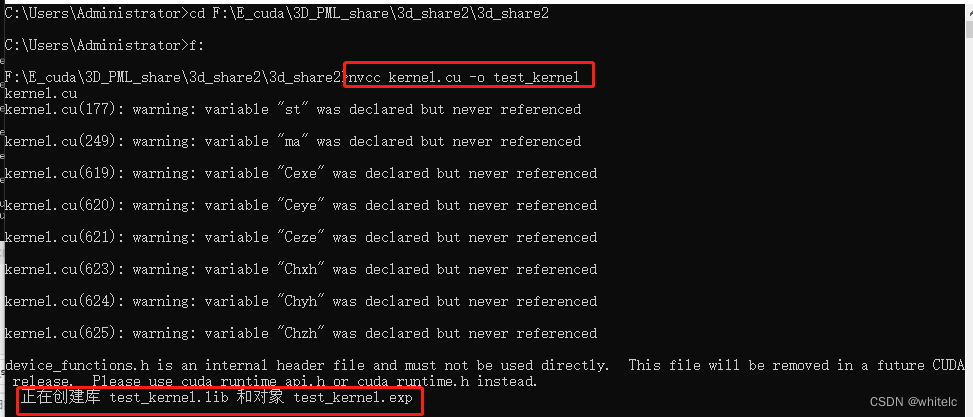
nvcc kernel.cu - 或者输入
nvcc kernel.cu -o test_kernel可以自己命名test的名字,这里我文件夹下面命名的为test_kernel
6. 输入 nvprof a

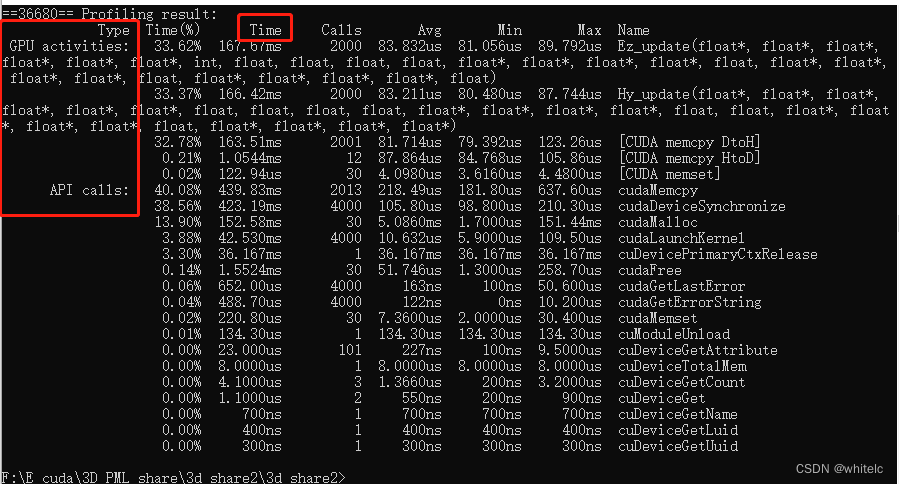
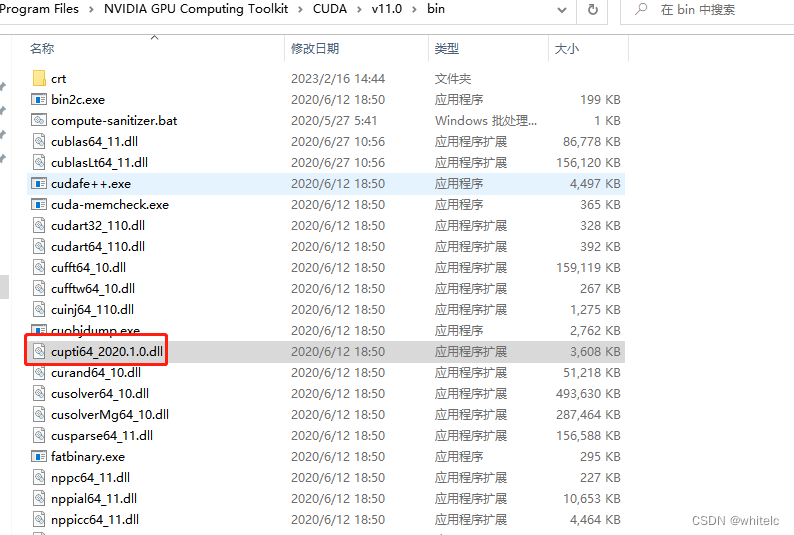
用nvcc+nvprof ,windows10下要把nvcc.exe和nvprof.exe添加到系统环境变量中:
这两个默认路径为:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin

https://blog.csdn.net/yangjinyi1314/article/details/124833846
可以根据https://www.cnblogs.com/AIxiaodi/p/13766461.html
将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\CUPTI\lib64下的文件cupti64_2020.1.1.dll 复制到路径 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin中即可,如下: