手把手带你快速上手OpenHGNN
- 1. 评估新的数据集
- 1.1 如何构建一个新的数据集
- 2. 使用一个新的模型
- 2.1 如何构建一个新模型
- 3. 应用到一个新场景
- 3.1 如何构建一个新任务
- 3.2 如何构建一个新的trainerflow
- 内容来源
1. 评估新的数据集
如果需要,可以指定自己的数据集。本节中,我们使用HGBn-ACM作为节点分类数据集的示例。
1.1 如何构建一个新的数据集
第一步:预处理数据集
这里给出了一个处理HGBn-ACM的演示,这是一个节点分类数据集。
首先,下载HGBn-ACM数据集:HGB数据集。下载完成后,需要将其处理为一个dgl.heterograph。
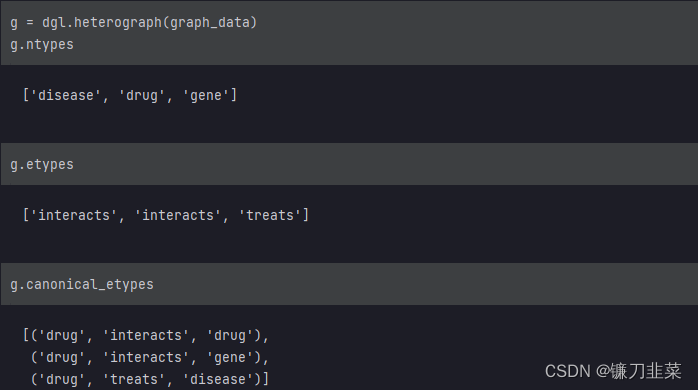
以下代码片段是在DGL中创建异构图的示例。
import dgl
import torch as th
graph_data = {
('drug','interacts', 'drug'): (th.tensor([0,1]), th.tensor([1,2])),
('drug','interacts', 'gene'): (th.tensor([0,1]), th.tensor([2,3])),
('drug','treats','disease'): (th.tensor([1]), th.tensor([2]))
}
graph_data

推荐将feature name设置为h:
g.nodes['drug'].data['h'] = th.ones(3, 1)
DGL提供了dgl.save_graphs()和dgl.load_graphs()分别表示保存和加载二进制形式的异质图。因此,这里使用dgl.save_graphs保存graphs到磁盘中:
dgl.save_graphs('demo_graph.bin',g)
第二步:增加额外的信息
经过第一步,得到一个demo_graph.bin的二进制文件,然后我们将其移动到openhgnn/dataset/目录下,下一步的具体信息在NodeClassificationDataset.py
例如,我们将category,num_classes和multi_label(if necessary) 设置为paper,3和True,分别表示要预测类的节点类型、类的数量以及任务是否为多标签分类。有关详细信息,请参阅基本节点分类数据集。
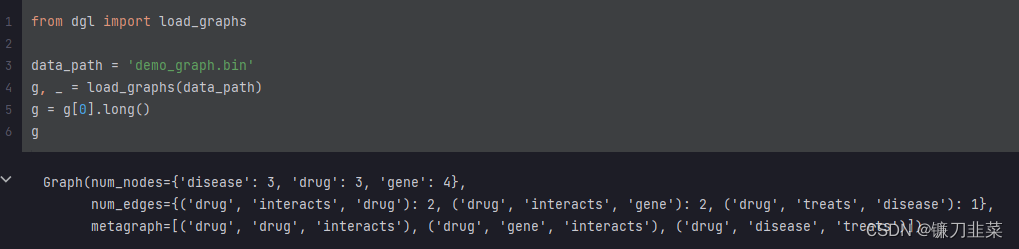
增加额外的信息:
if name_dataset == 'demo_graph':
data_path = './openhgnn/dataset/demo_graph.bin'
g, _ = load_graphs(data_path)
g = g[0].long()
self.category = 'author' # 增加额外的信息
self.num_classes = 4
self.multi_label = False
第三步:可选
使用demo_graph作为数据集,评估一个存在的模型:
python main.py -m GTN -d demo_graph -t node_classification -g 0 --use_best_config
如果有另一个数据集名称,那需要修改代码build_dataset
2. 使用一个新的模型
这一部分,我们创建一个模型,名为RGAT,它不在我们的模型package <api-model>。
2.1 如何构建一个新模型
第一步:注册器模型
我们创建一个继承基本模型(Base Model)的类RGAT,并使用@register_model(str)注册该模型。
from openhgnn.models import BaseModel, register_model
@register_model('RGAT')
class RGAT(BaseModel):
...
第二步:实现函数
必须实现类方法build_model_from_args,其他函数像__init__,forward等
...
class RGAT(BaseModel):
@classmethod
def build_model_from_args(cls, args, hg):
return cls(in_dim=args.hidden_dim,
out_dim=args.hidden_dim,
h_dim=args.out_dim,
etypes=hg.etypes,
num_heads=args.num_heads,
dropout=args.dropout)
def __init__(self, in_dim, out_dim, h_dim, etypes, num_heads, dropout):
super(RGAT, self).__init__()
self.rel_names = list(set(etypes))
self.layers = nn.ModuleList()
self.layers.append(RGATLayer(
in_dim, h_dim, num_heads, self.rel_names, activation=F.relu, dropout=dropout))
self.layers.append(RGATLayer(
h_dim, out_dim, num_heads, self.rel_names, activation=None))
return
def forward(self, hg, h_dict=None):
if hasattr(hg, 'ntypes'):
# full graph training,
for layer in self.layers:
h_dict = layer(hg, h_dict)
else:
# minibatch training, block
for layer, block in zip(self.layers, hg):
h_dict = layer(block, h_dict)
return h_dict
这里我们没有给出RGATLayer的实现细节。有关更多阅读,请查看:RGATLayer。
在OpenHGNN中,我们在模型之外对数据集的特征进行预处理。具体来说,使用每个节点类型都有偏差的线性层来将所有节点特征映射到共享特征空间。因此,模型中forward的参数h_dict不是原始特征,您的模型不需要进行特征预处理。
第三步:添加到支持的模型字典
我们应该在 model/init.py中向 SUPPORTED _ MODELS 添加一个新条目。
3. 应用到一个新场景
在本节中,我们将应用于一个推荐场景,该场景涉及构建一个新任务和训练流。
3.1 如何构建一个新任务
第一步:注册任务
创建一个类Recommendation,继承内置的BaseTask并用@register_task(str)注册它。
from openhgnn.tasks import BaseTask, register_task
@register_task('recommendation')
class Recommendation(BaseTask):
...
第二步:实现方法
我们应该实现与评估指标和损失函数相关的方法。
class Recommendation(BaseTask):
"""Recommendation tasks."""
def __init__(self, args):
super(Recommendation, self).__init__()
self.n_dataset = args.dataset
self.dataset = build_dataset(args.dataset, 'recommendation')
self.train_hg, self.train_neg_hg, self.val_hg, self.test_hg = self.dataset.get_split()
self.evaluator = Evaluator(args.seed)
def get_loss_fn(self):
return F.binary_cross_entropy_with_logits
def evaluate(self, y_true, y_score, name):
if name == 'ndcg':
return self.evaluator.ndcg(y_true, y_score)
最后
在task/init.py中,增加一个新的实体到SUPPORTED_TASKS.
3.2 如何构建一个新的trainerflow
第一步:注册trainerflow
创建一个类,继承BaseFlow,并用@register_trainer(str)去注册trainerflow。
from openhgnn.trainerflow import BaseFlow, register_flow
@register_flow('Recommendation')
class Recommendation(BaseFlow):
...
第二步:实现方法
我们将函数train()声明为一个抽象方法。因此,train()必须被重写,否则trainerflow就无法实例化。下面给出了一个训练循环的示例。
...
class Recommendation(BaseFlow):
def __init__(self, args=None):
super(Recommendation, self).__init__(args)
self.target_link = self.task.dataset.target_link
self.model = build_model(self.model).build_model_from_args(self.args, self.hg)
self.evaluator = self.task.get_evaluator(self.metric)
def train(self,):
for epoch in epoch_iter:
self._full_train_step()
self._full_test_step()
def _full_train_step(self):
self.model.train()
logits = self.model(self.hg)[self.category]
loss = self.loss_fn(logits[self.train_idx], self.labels[self.train_idx])
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
def _full_test_step(self, modes=None, logits=None):
self.model.eval()
with torch.no_grad():
loss = self.loss_fn(logits[mask], self.labels[mask]).item()
metric = self.task.evaluate(pred, name=self.metric, mask=mask)
return metric, loss
最终
在trainerflow/init.py中增加一个新的实体到SUPPORT_FLOWS。
内容来源
- Developer_Guide