目录
- 1.1.Pandas概述
- 2.Pandas索引结构
- 3.groupby学习
- 5.Pandas数值运算
- 二元统计
- 6.对象操作
- 7.merge合并
- 显示设置
- 9.pivot操作
- 10. 时间操作
- 11.常用操作
- 12.groupby操作
- 13.字符串操作
- 14.索引操作
- 15.pandas绘图操作
1.1.Pandas概述
Python的pandas库是一个数据处理和数据分析库,提供了很多强大的数据结构和处理工具,使得数据处理更加高效,同时也提供了丰富的功能和灵活的接口。pandas的两个核心数据结构是Series和DataFrame。Series是一个一维数组,可以保存任何数据类型,而DataFrame则是一个表格型数据结构,它包含了一系列的行和列,每列是Series类型。pandas提供了很多数据分析和处理工具,例如各种形式的数据清洗、数据过滤、数据筛选、数据分组、数据合并、数据重塑、时间序列数据处理、统计分析等。
- 先导入pandas库
import pandas as pd
df=pd.read_csv('../teachercode/Pandas/data/titanic.csv') # 读入文件中的表格数据
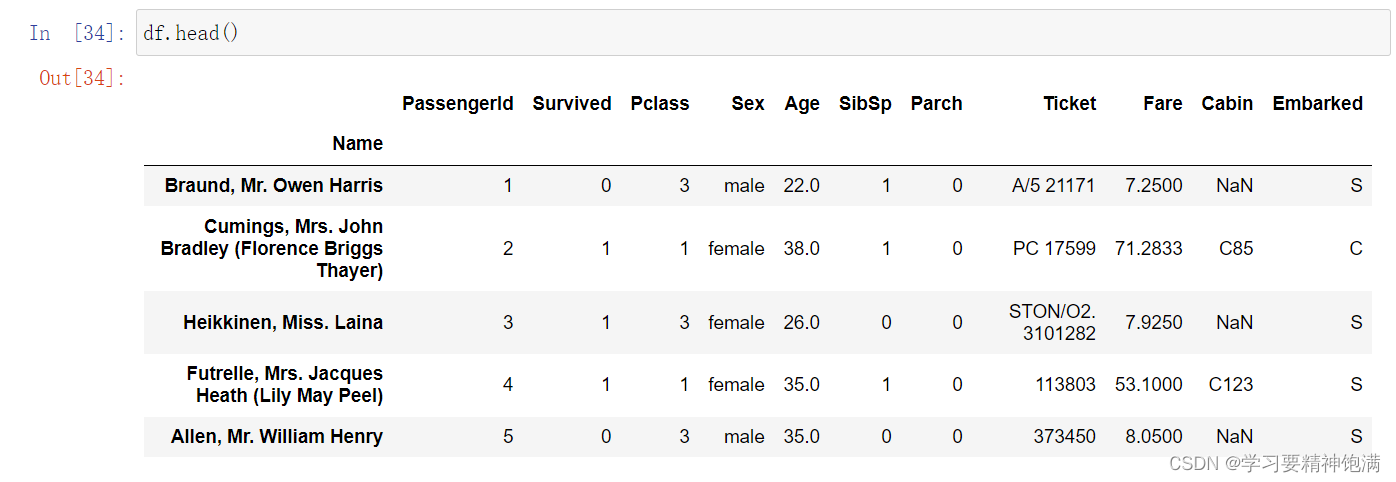
df.head() # 使用此方法 默认显示前5行数据
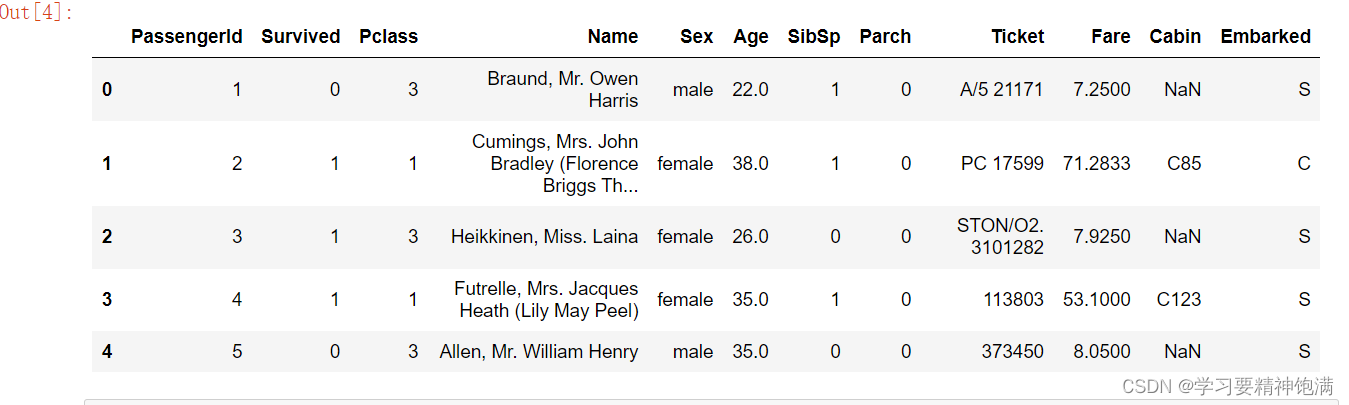
df.head(10)# 可以选择显示前多上行
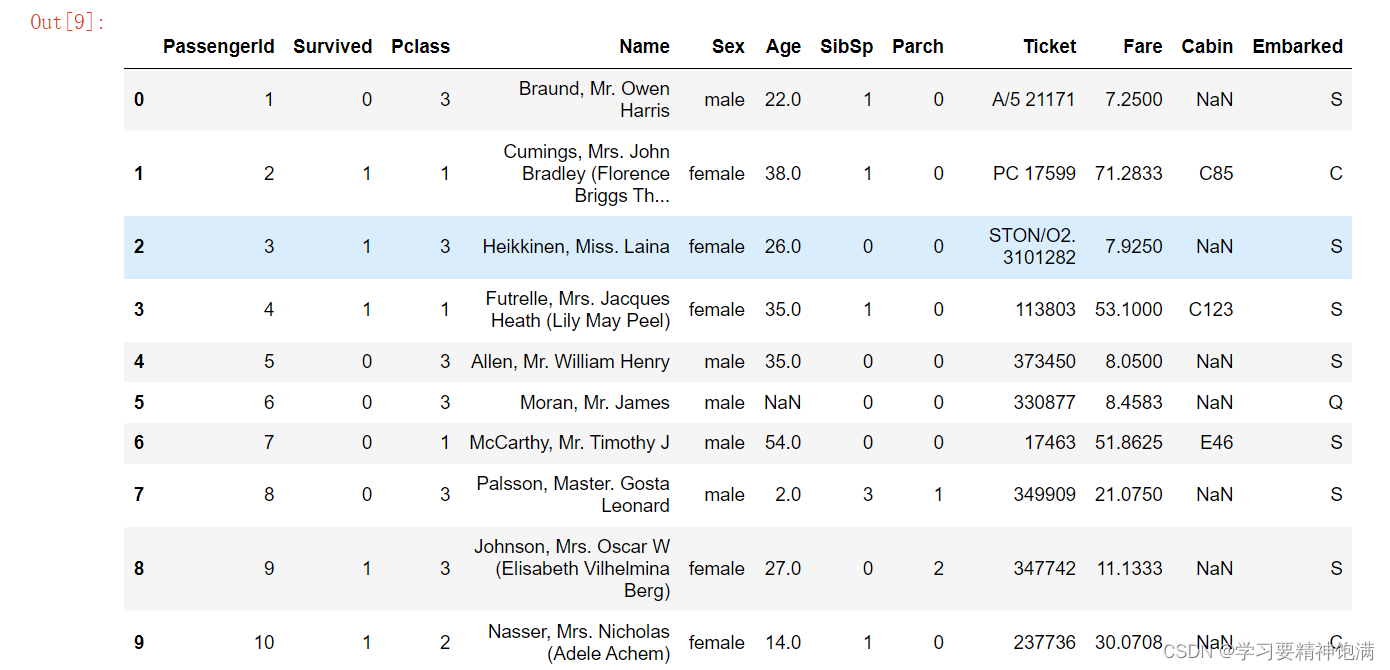
- 查看我读入的表格数据在python中是什么类型数据

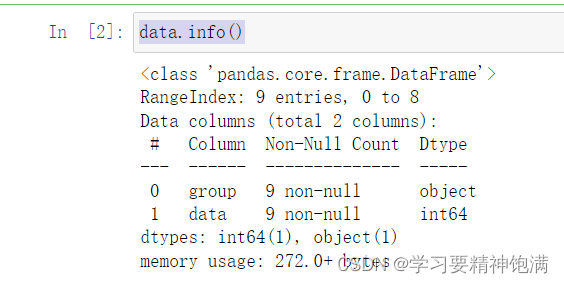
- info()函数获取这个DataFrame类型数据的具体信息
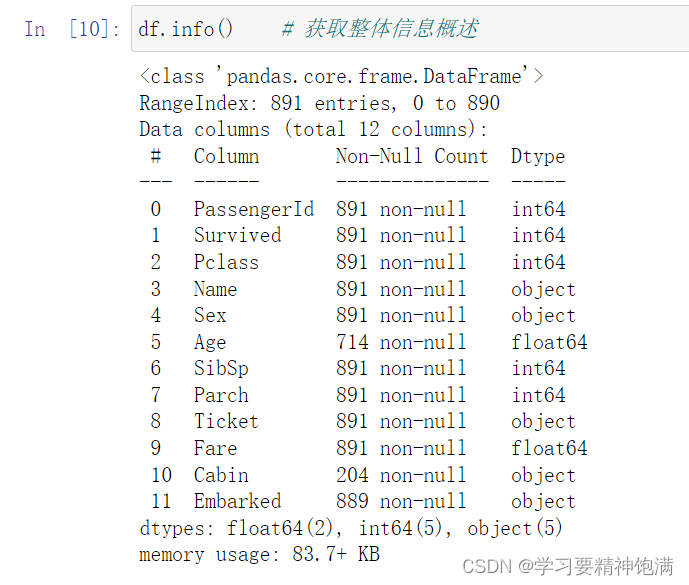
显示了有多少列,列名,每列非空数据数量,每列数据的类型,使用了多少内存。
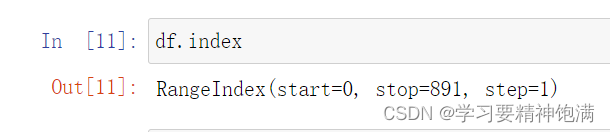
- 显示索引
默认是显示行数n,索引就是0到n-1 我们可以自己指定一个标签列表设置为索引
- 显示列名

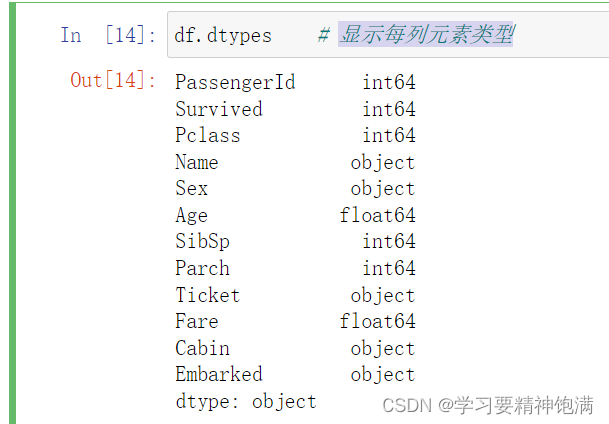
- 显示每列元素类型
- 简略的打印数据

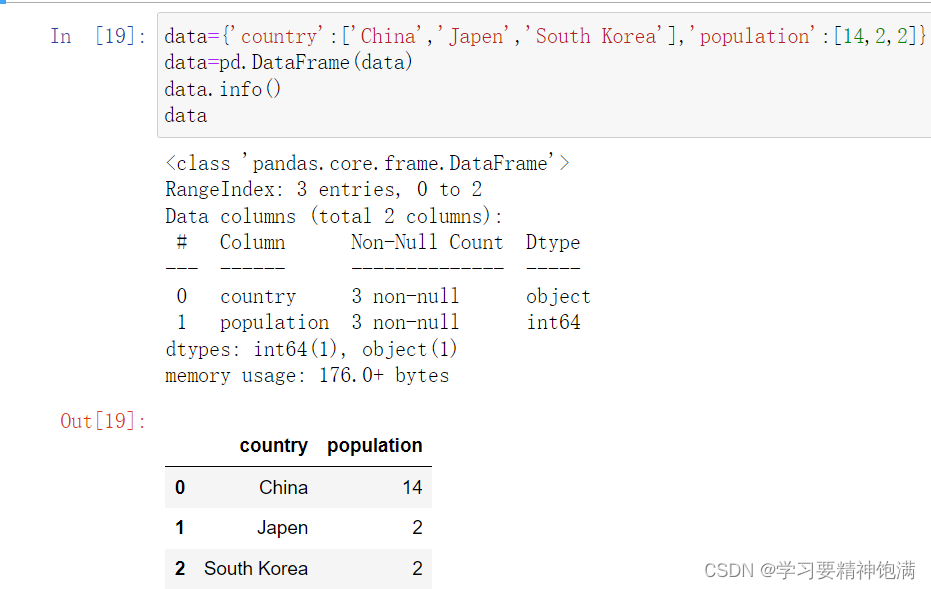
- 自己创建一个简略的dataframe结构
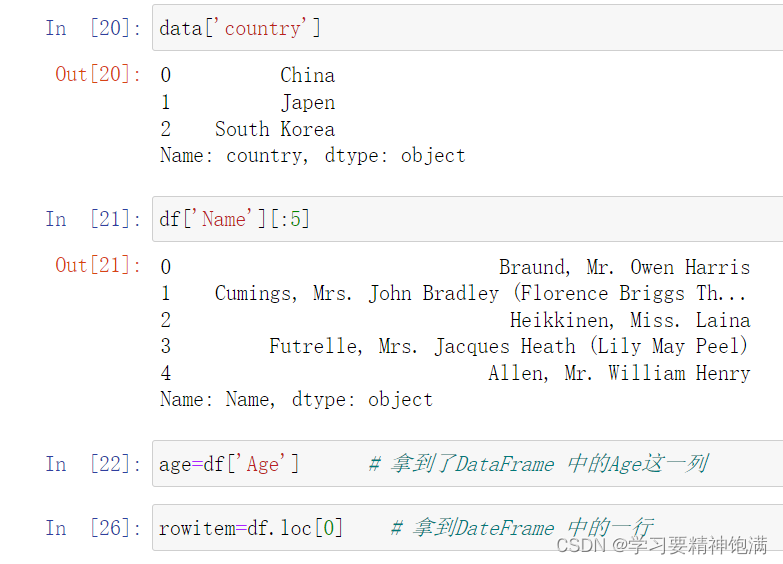
- 取指定的数据,可以取指定的列 ,用列名做索引

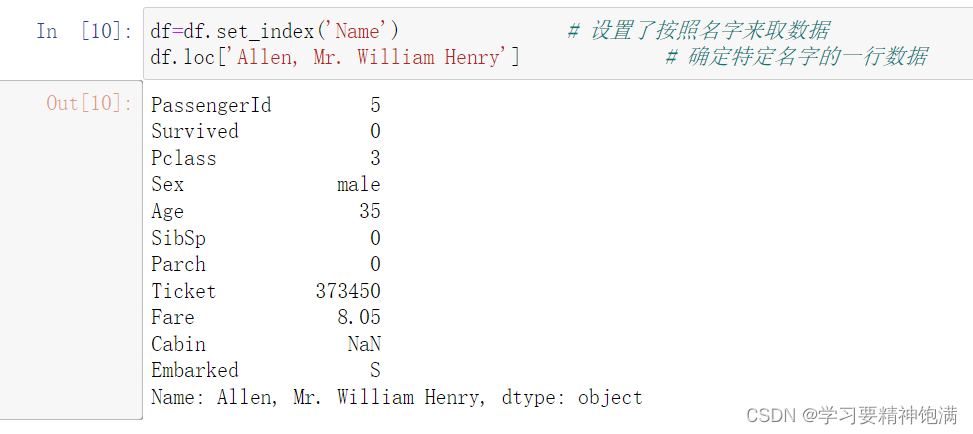
- 我们自己指定索引df.set_index()
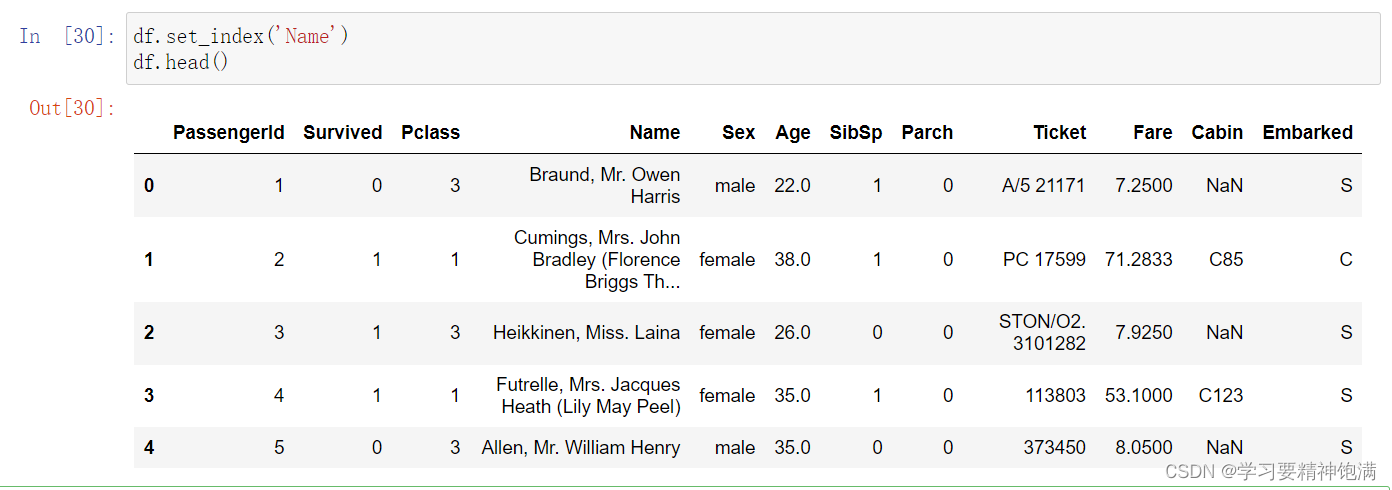
这样并没有改变索引结果
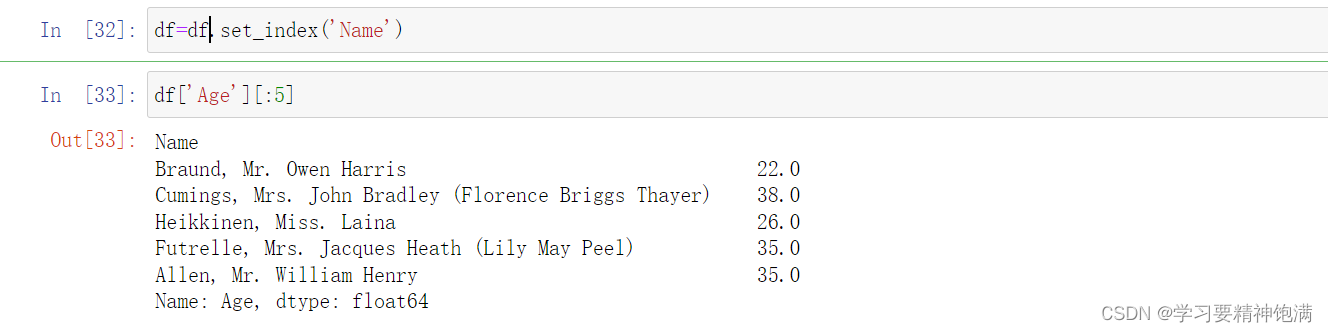
使用df.set_intdex()后使用一个比变量来接受
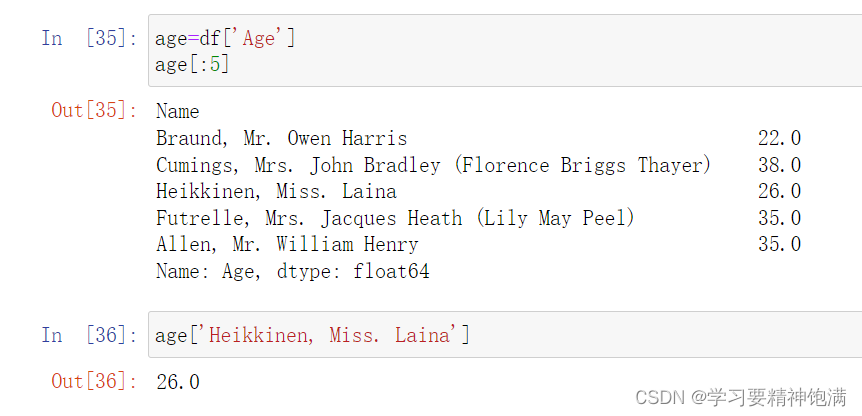
- 对拿到的列数据进行操作



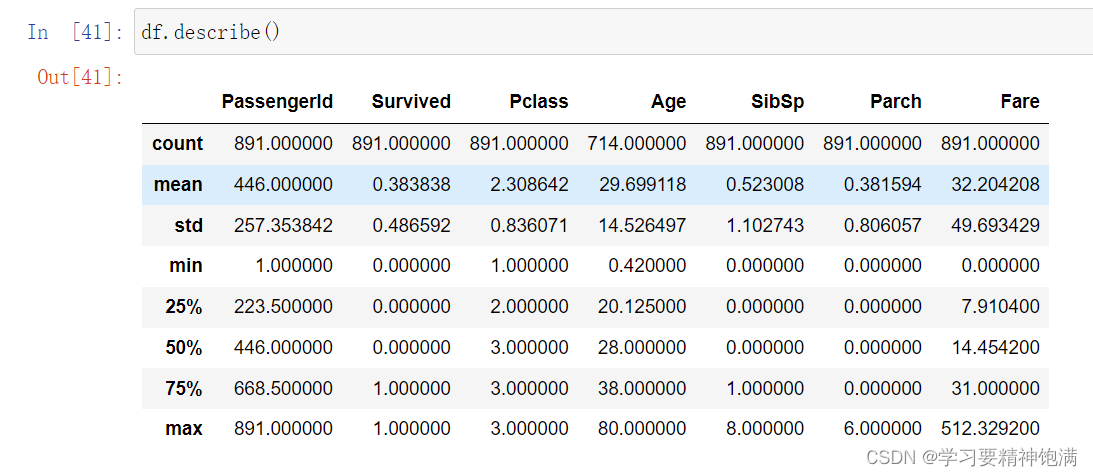
- describe 可以获取数据统计的基本统计信息特性
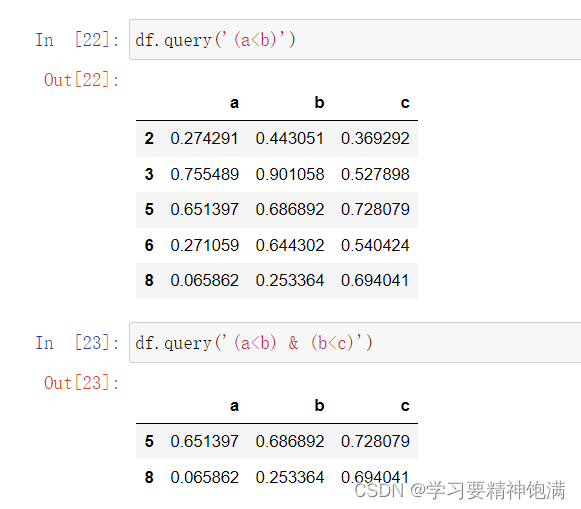
2.Pandas索引结构
- 可以按照列名取出特定列
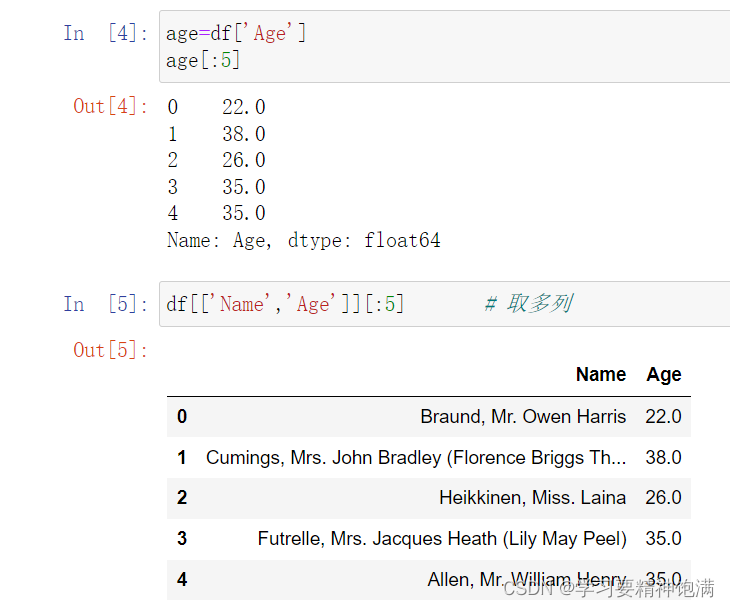
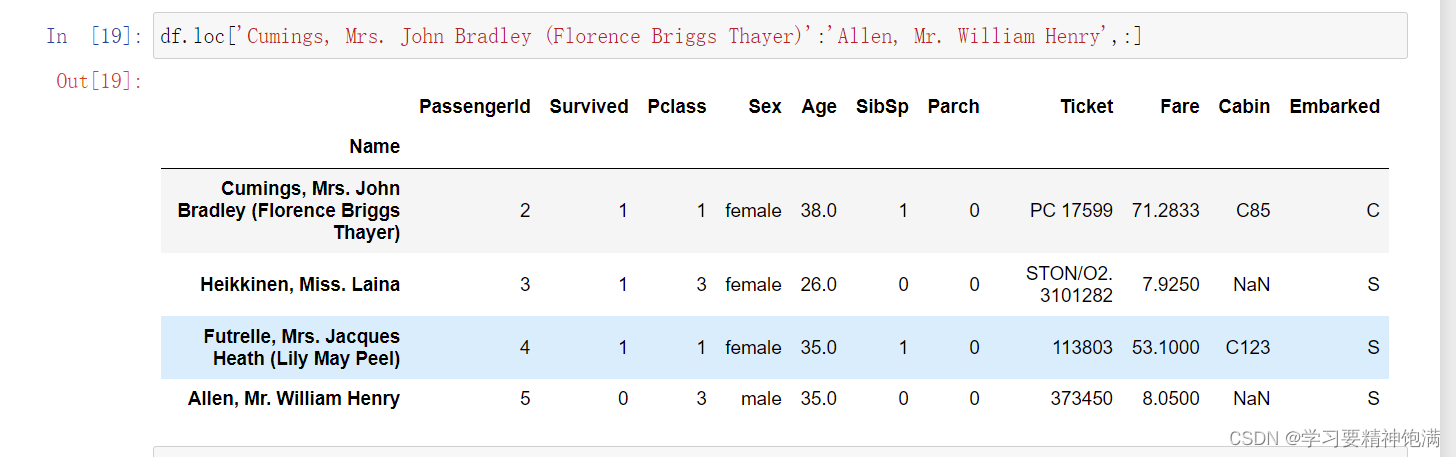
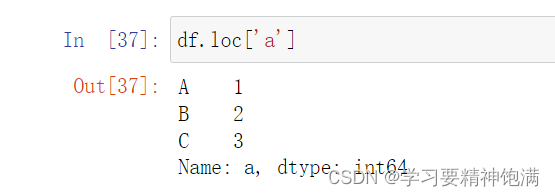
- loc 使用标签来定位
- iloc 使用位置来定位
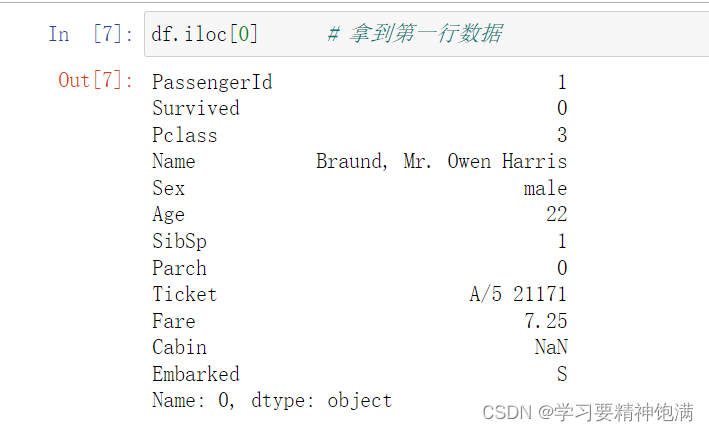
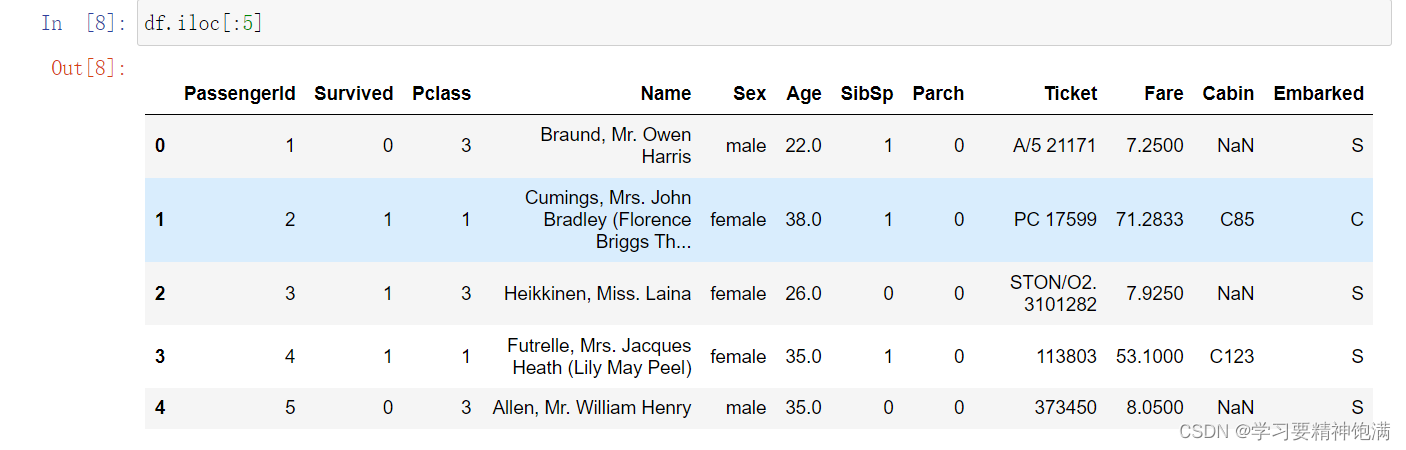
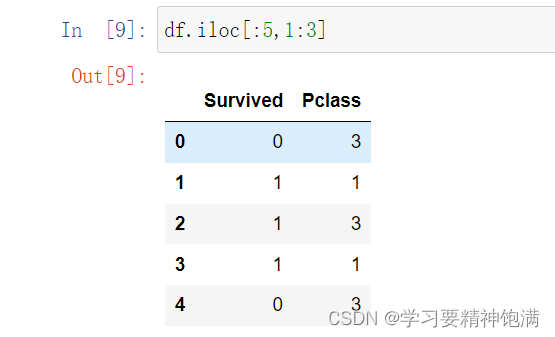

- 可以改变特定位置的数据

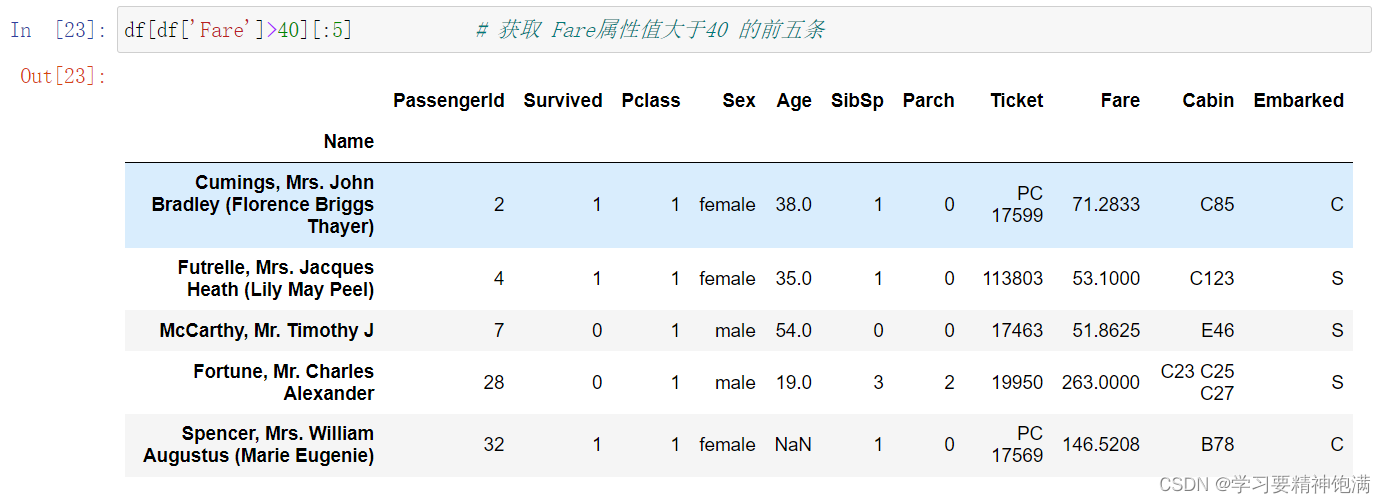
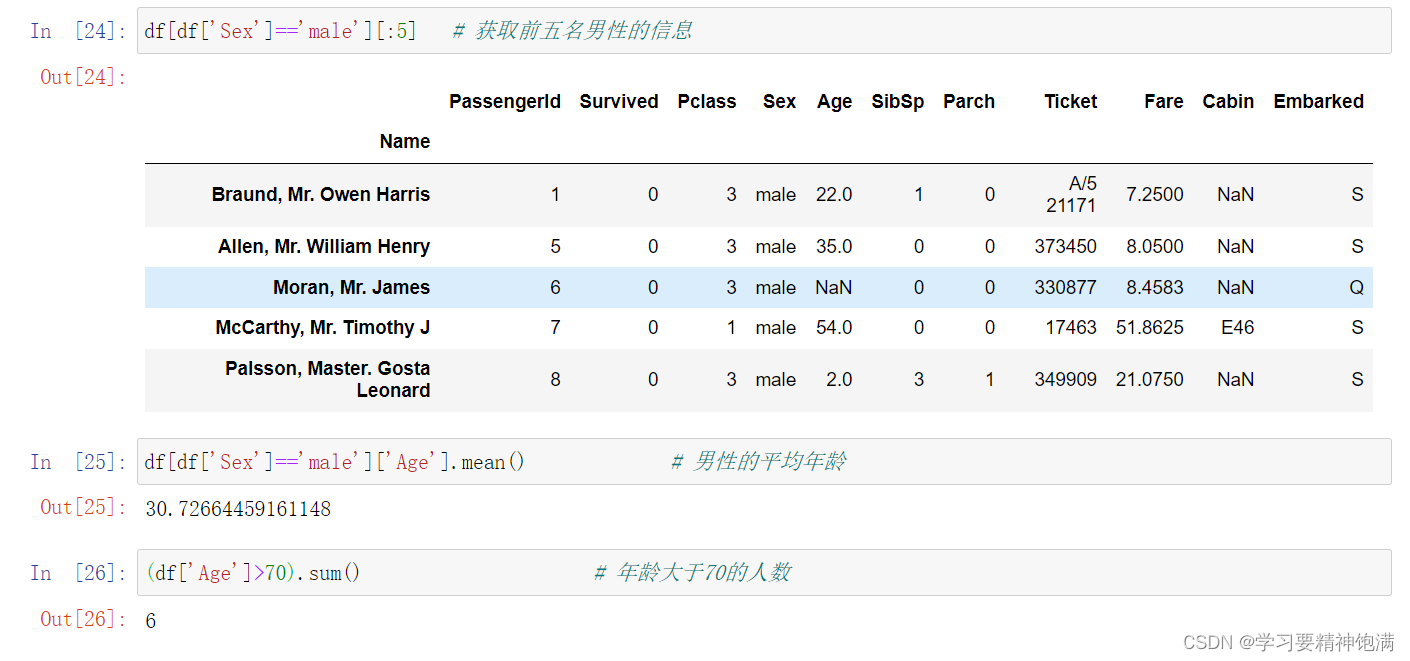
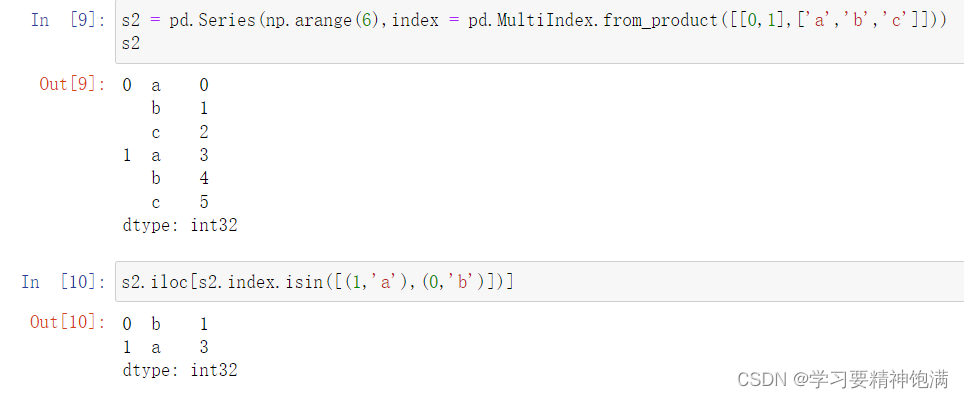
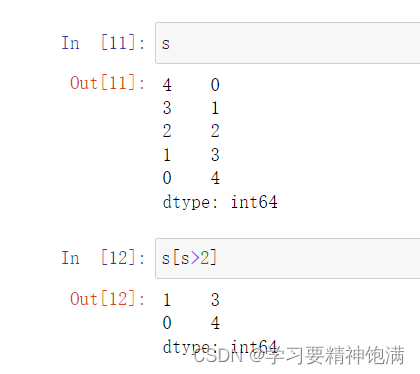
- bool类型的索引

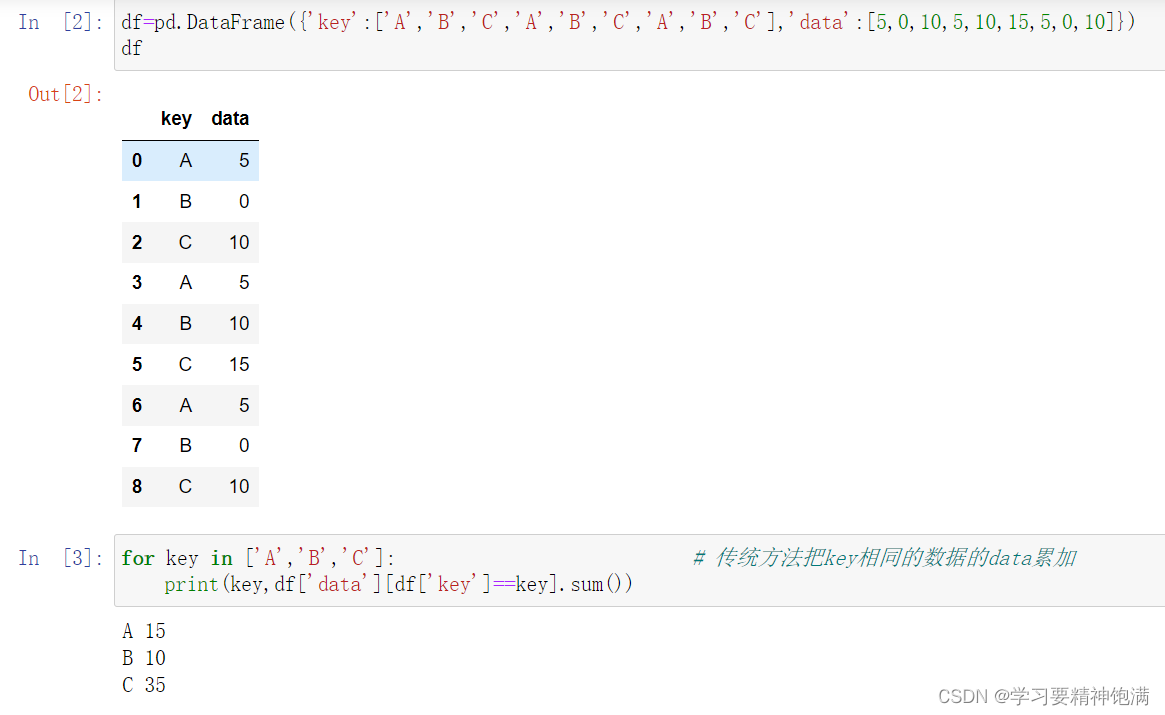
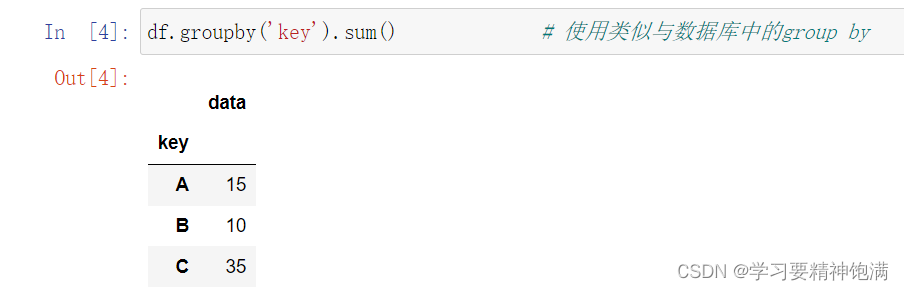
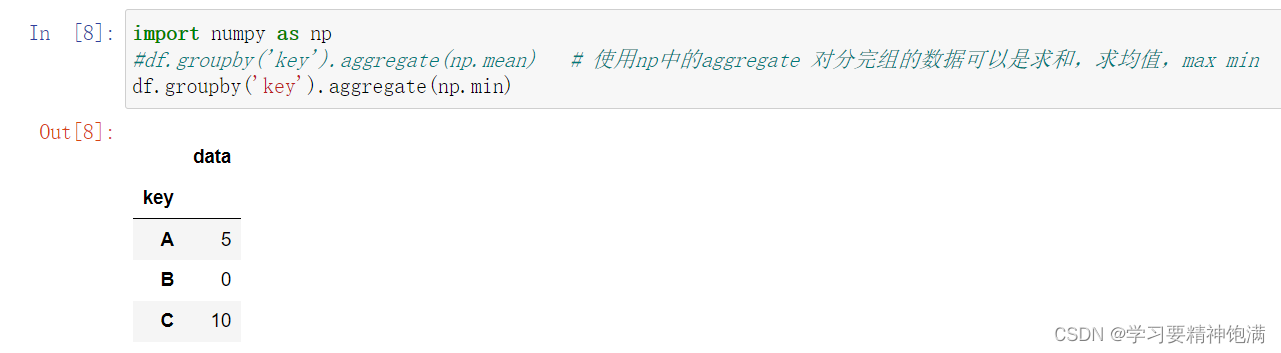
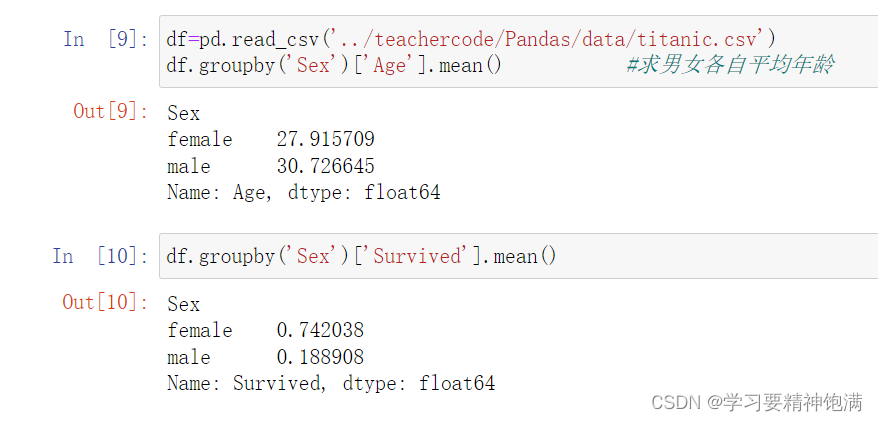
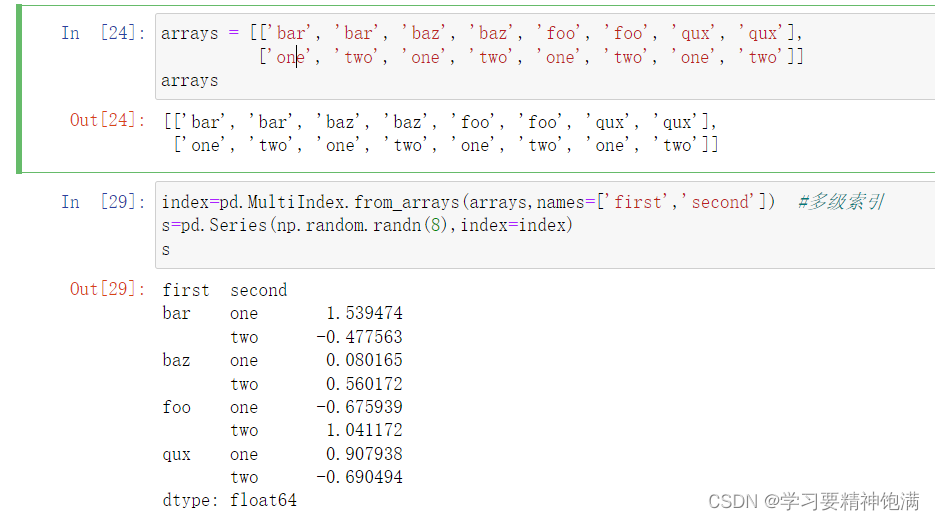
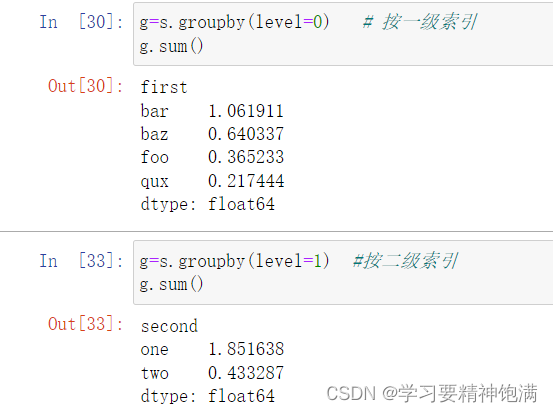
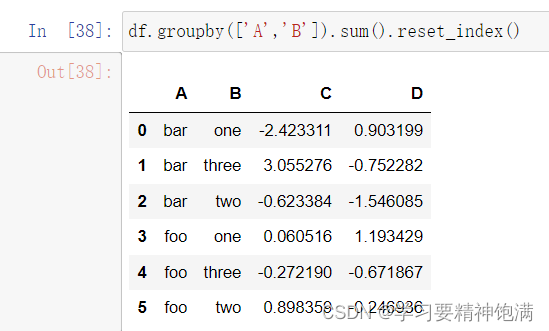
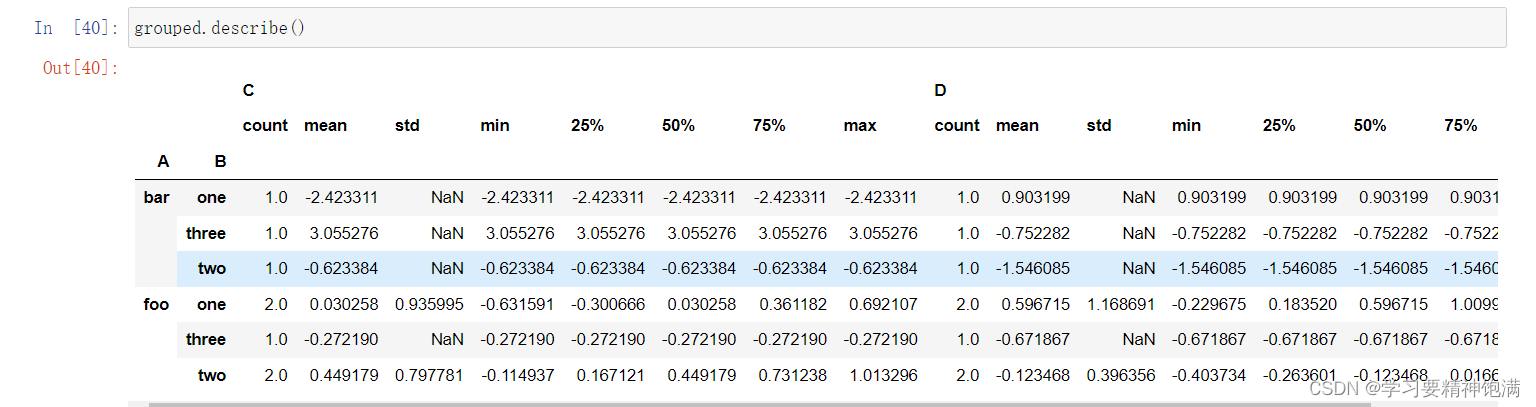
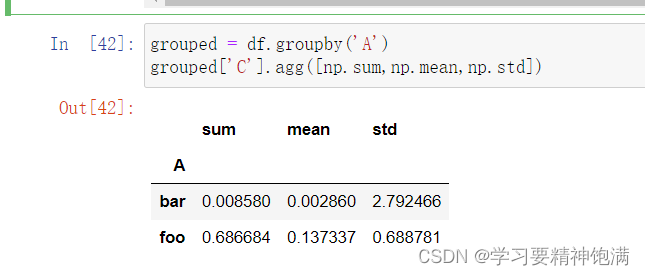
3.groupby学习
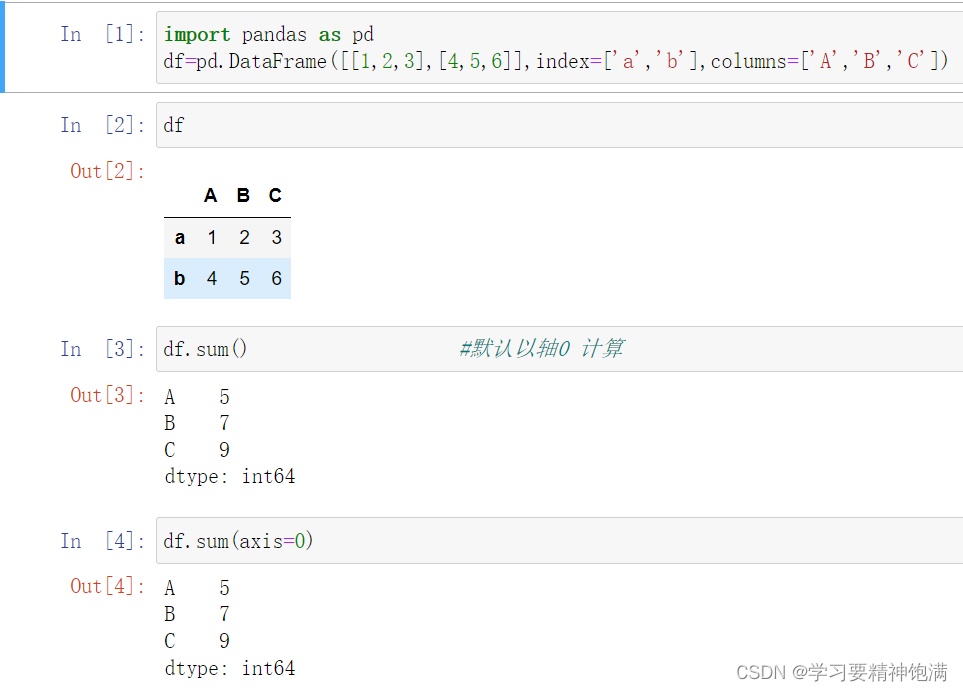
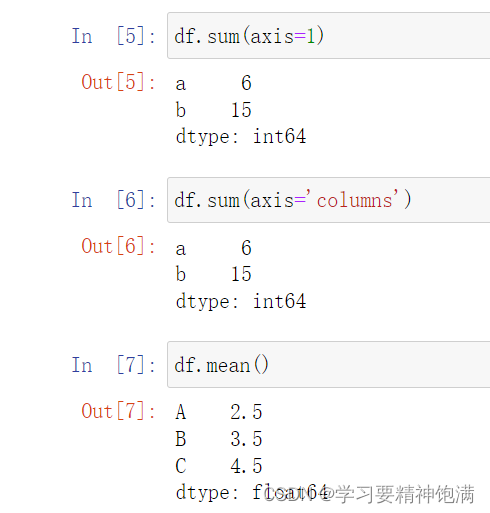
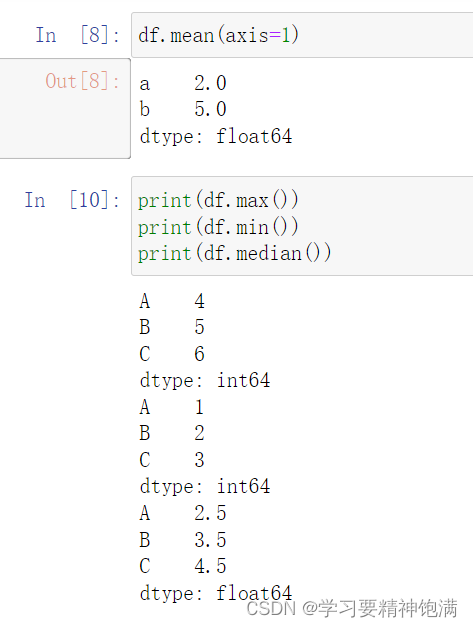
5.Pandas数值运算
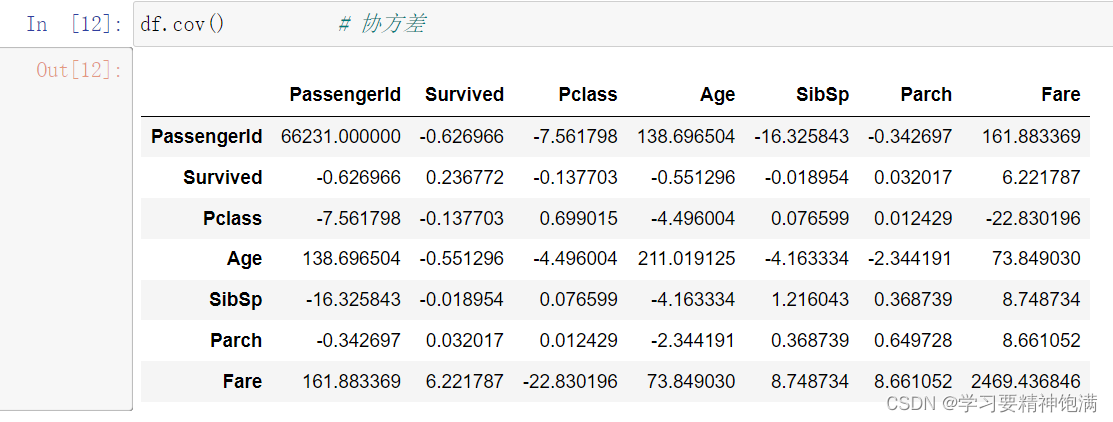
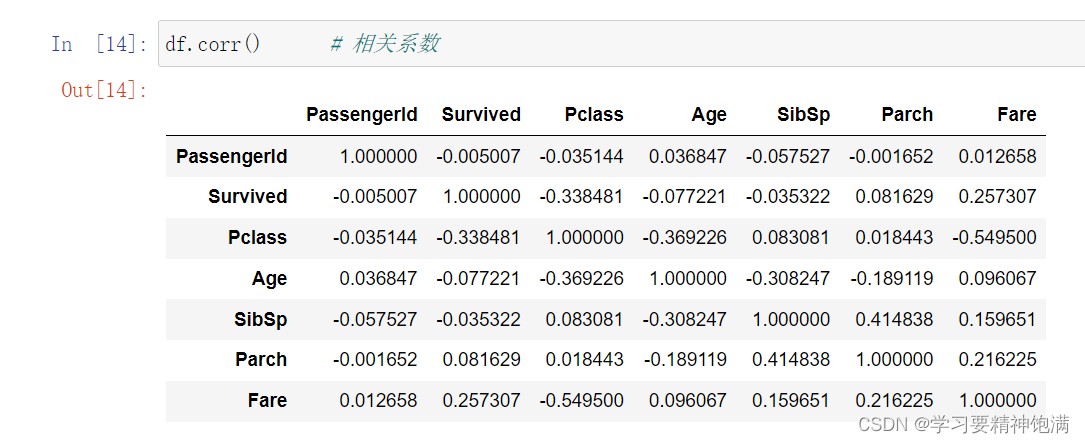
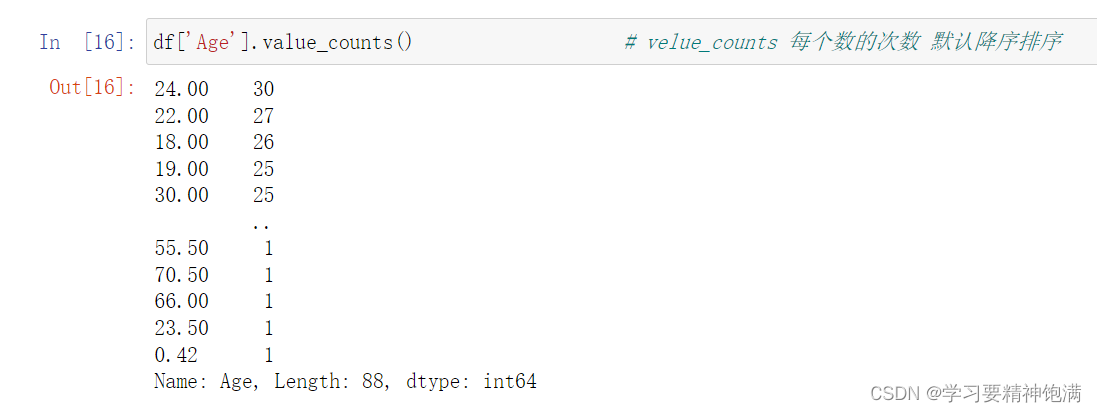
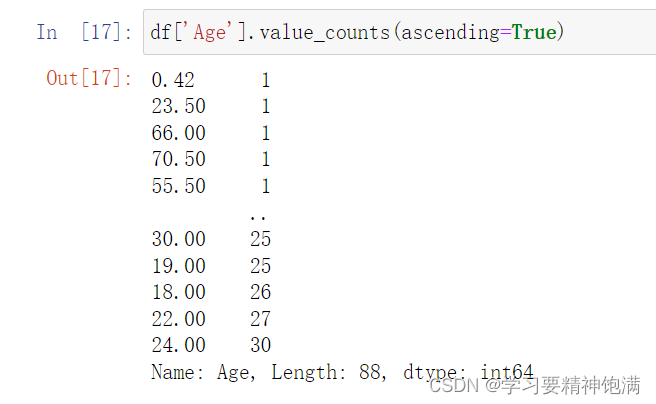
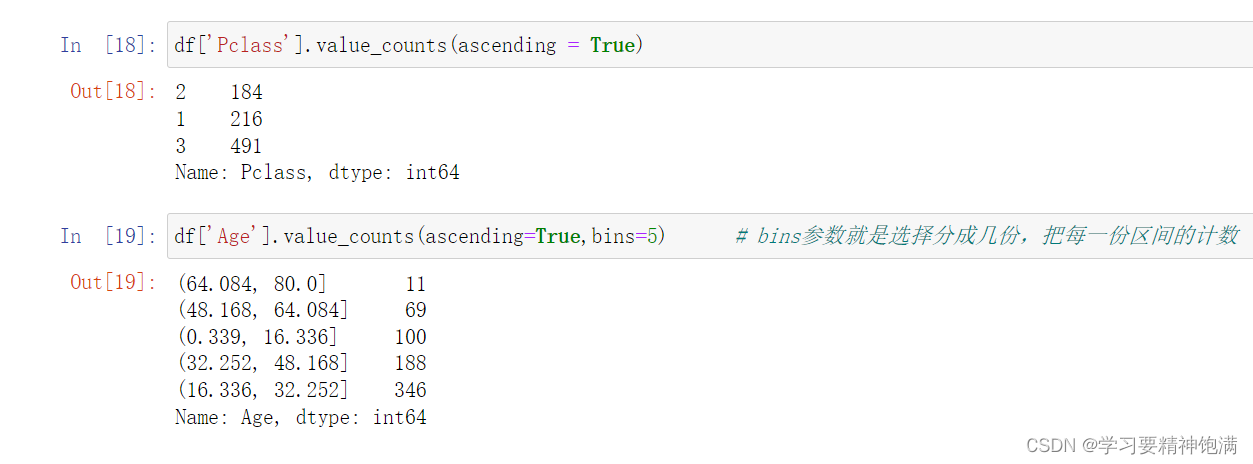
二元统计
6.对象操作
-
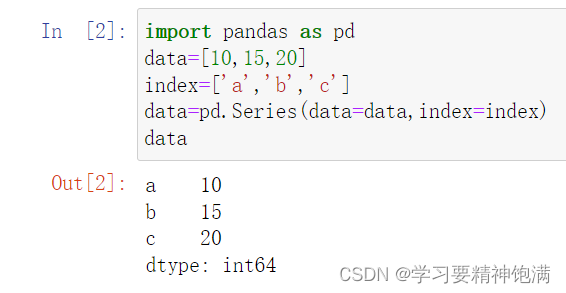
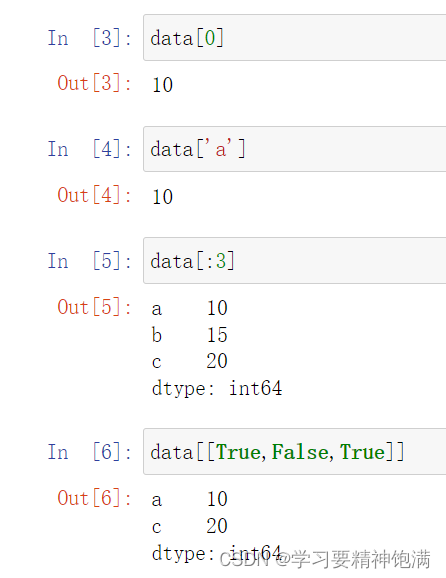
对象查操作

-
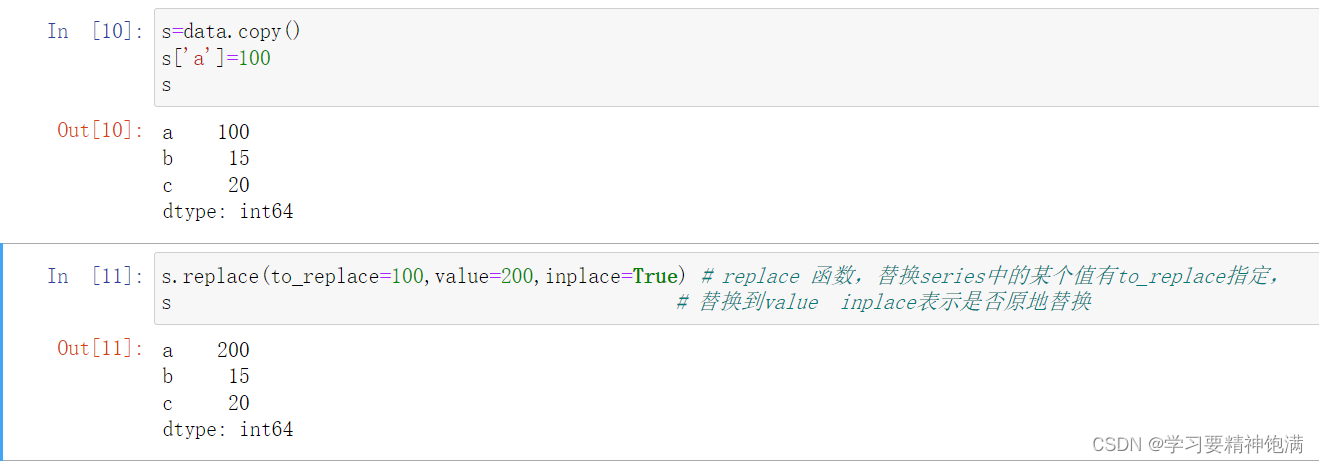
改操作

-
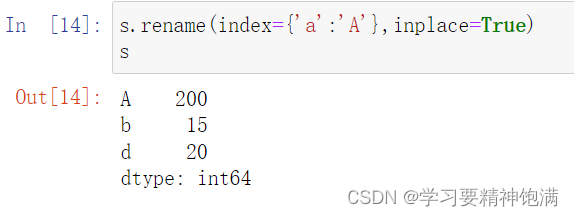
Pandas 中的 rename() 函数用于重命名 DataFrame 或 Series 的行名称或列名称。它可以通过字典的方式来指定哪些行或列需要重命名
-
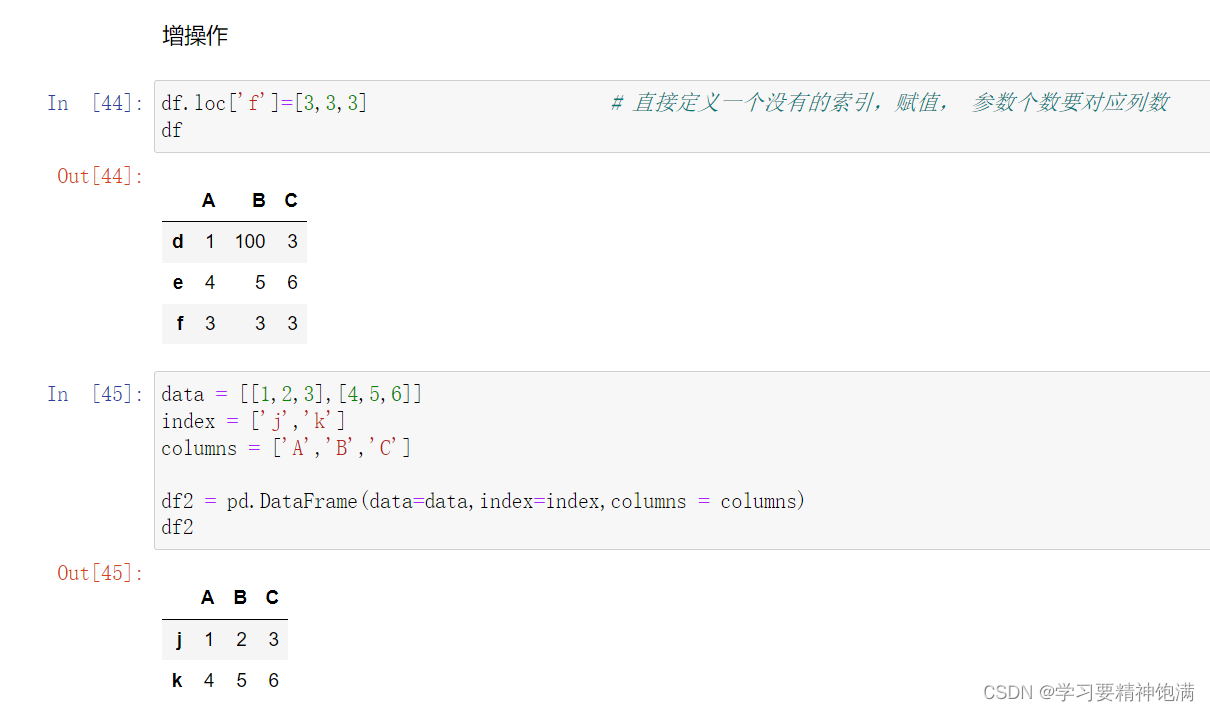
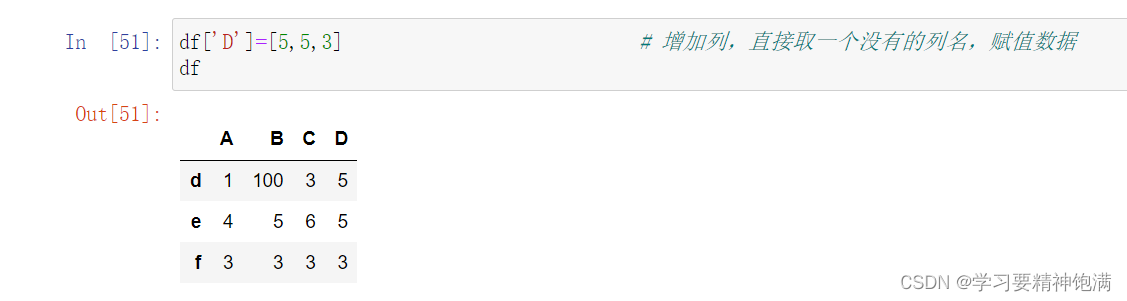
增操作

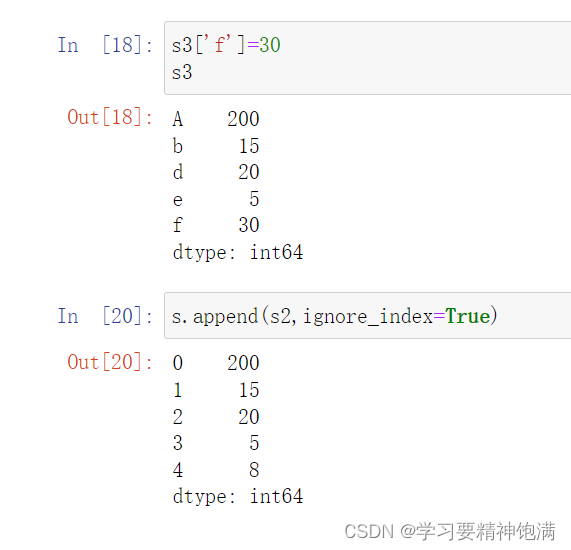
-
删操作
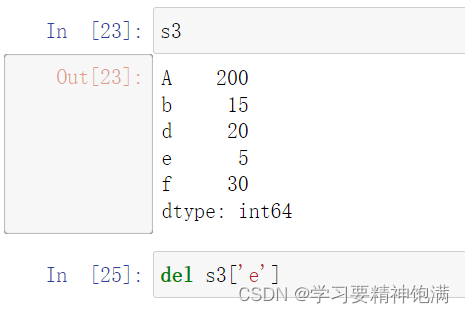
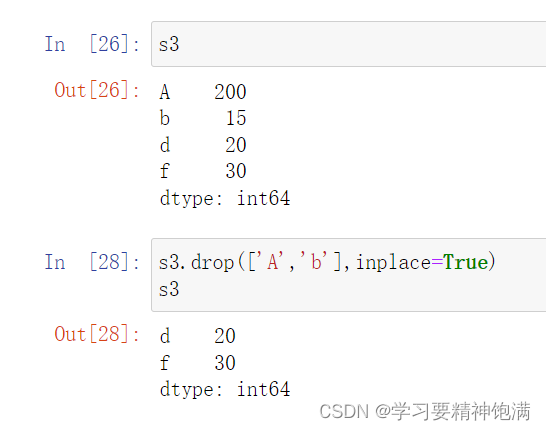
-
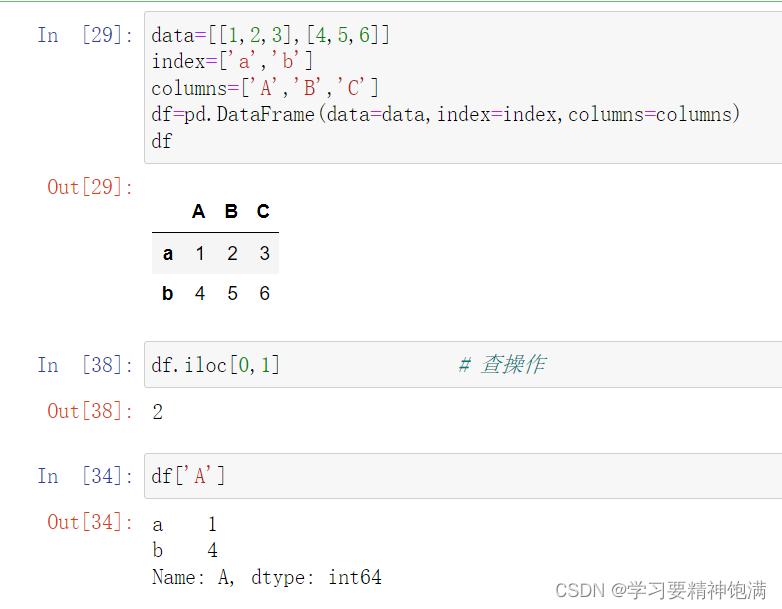
DataFrame结构的增删改查

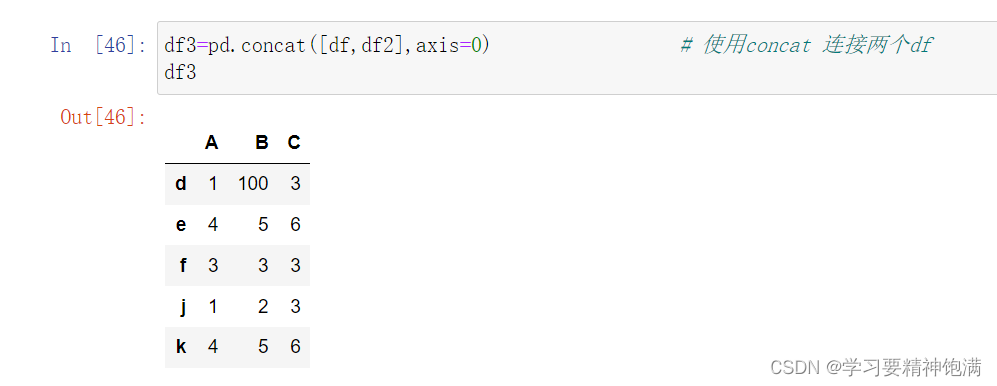
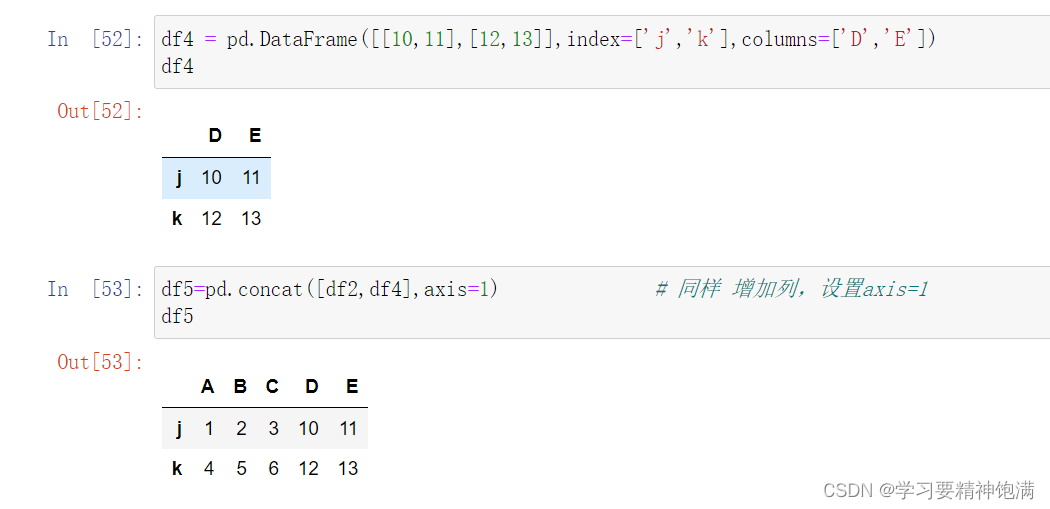
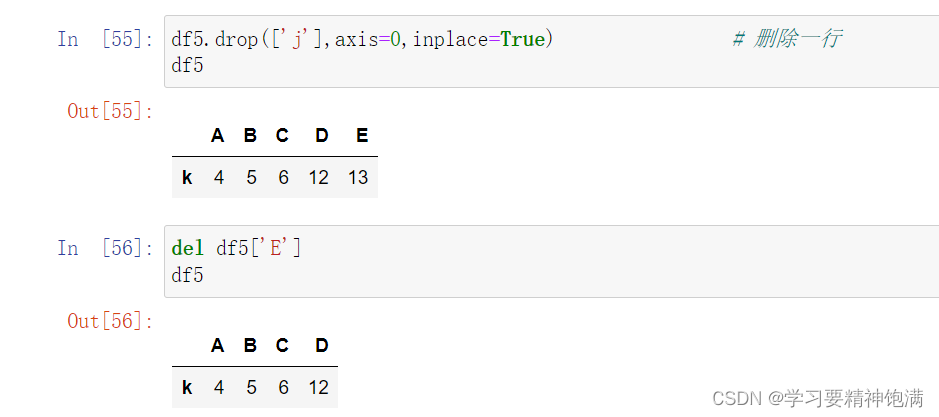

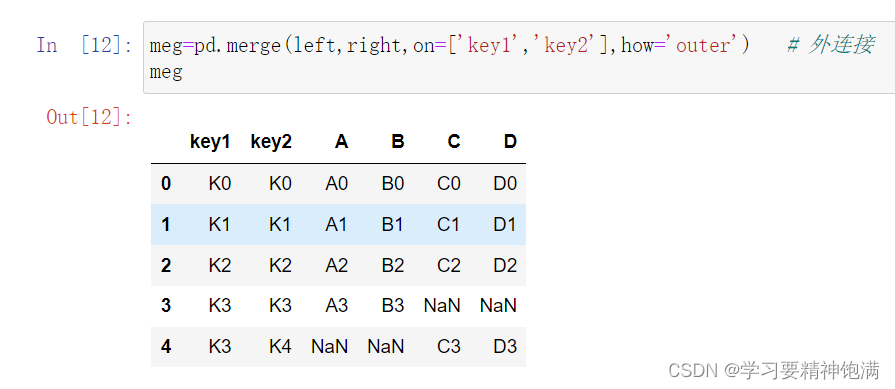
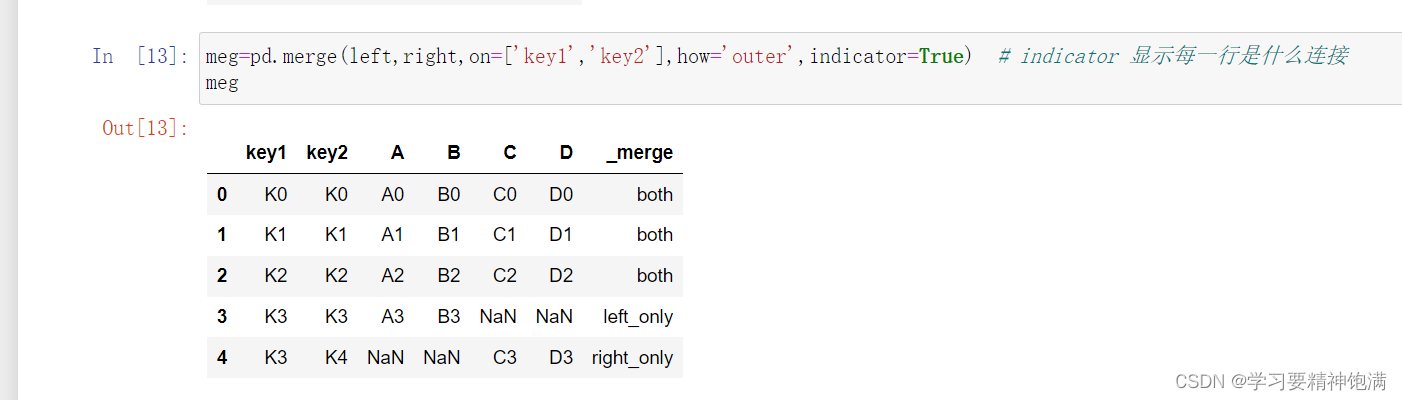
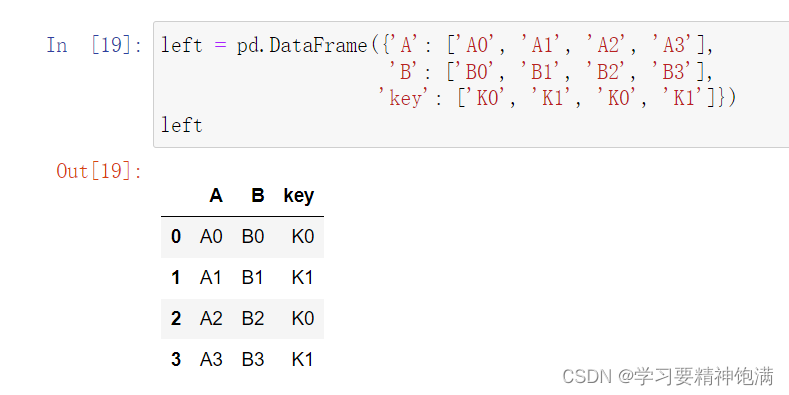
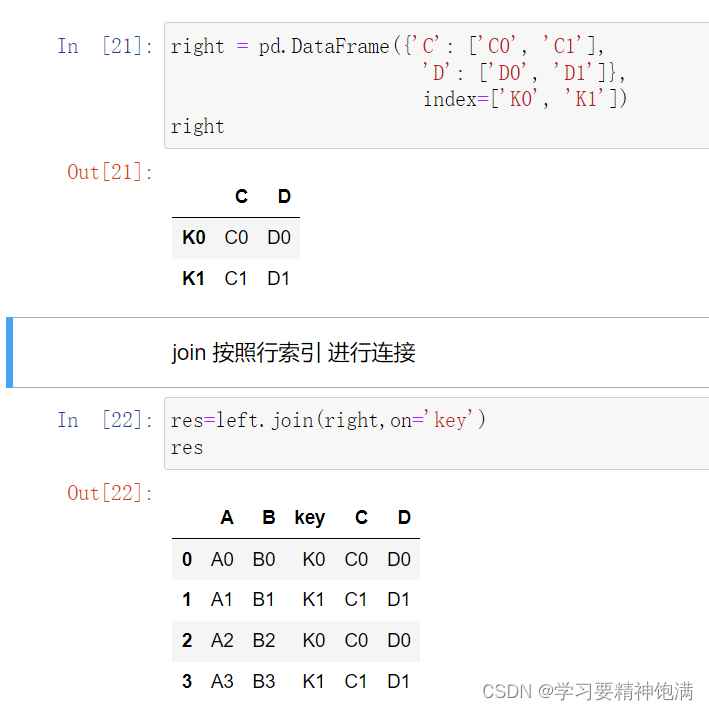
7.merge合并
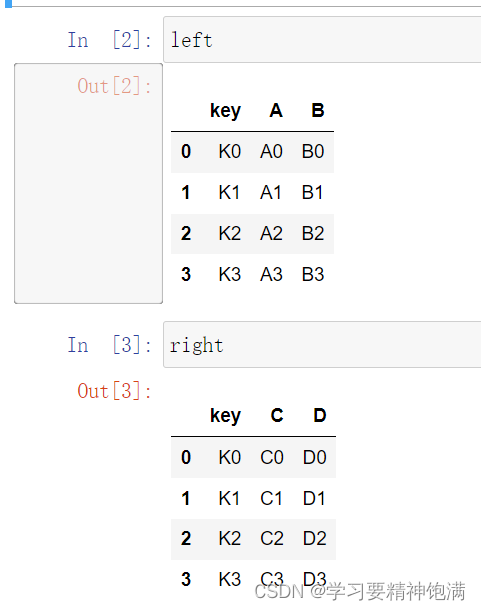

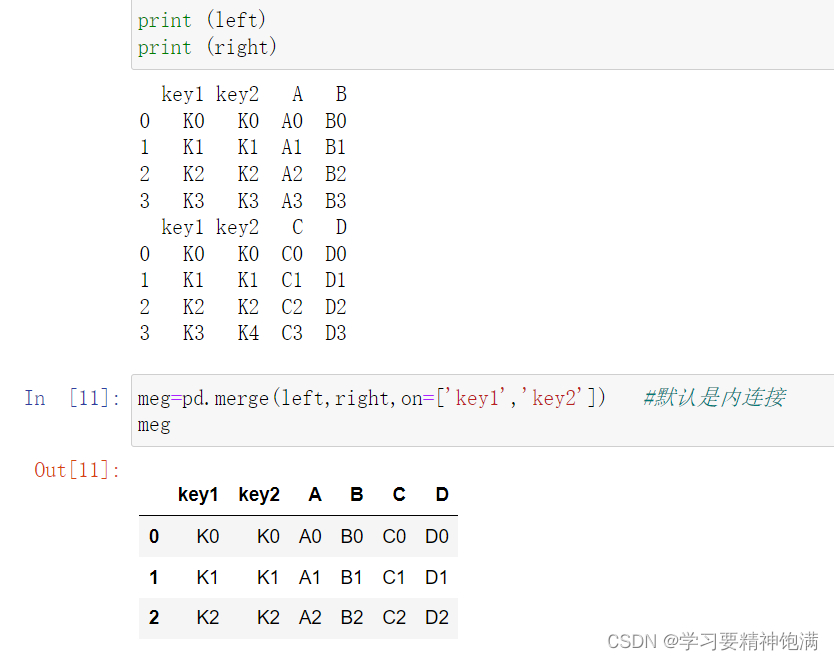

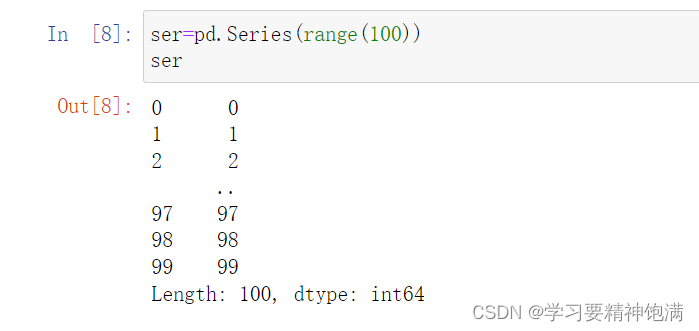
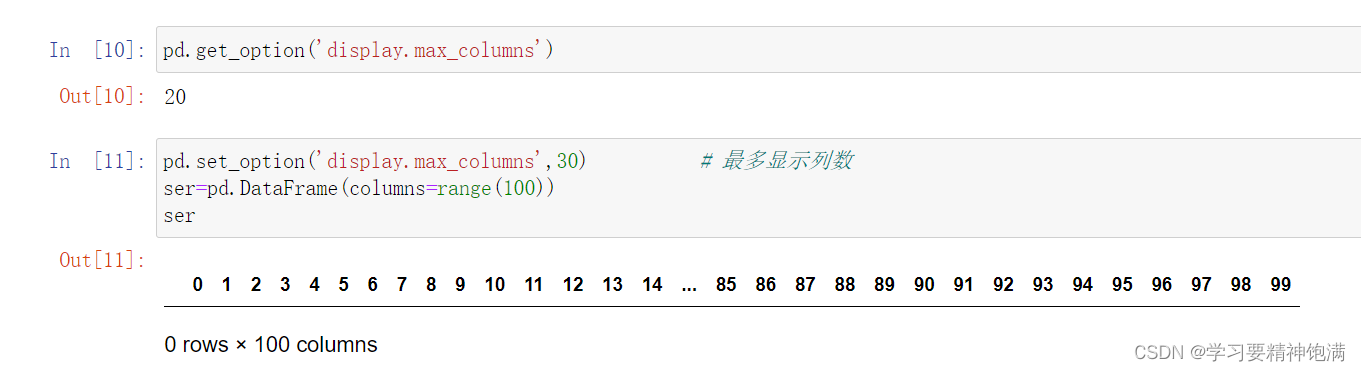
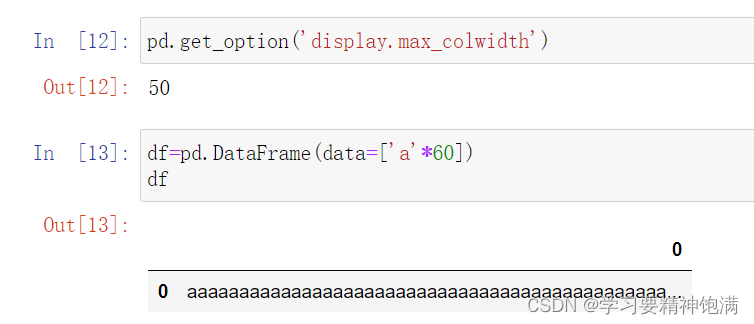
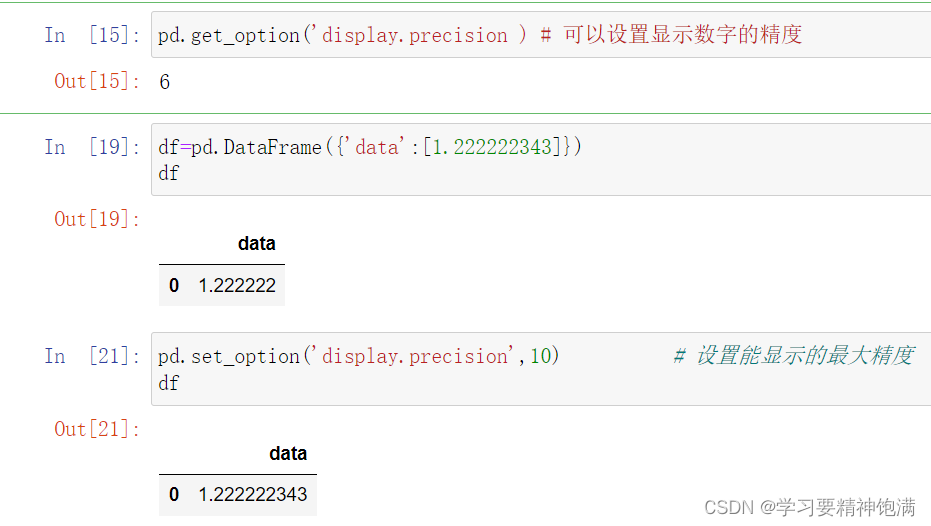
显示设置


9.pivot操作
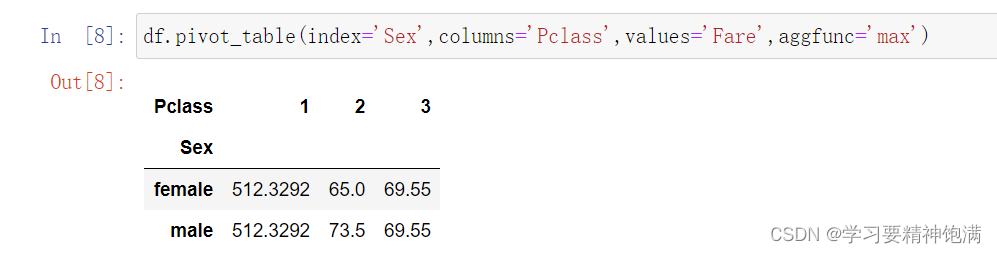
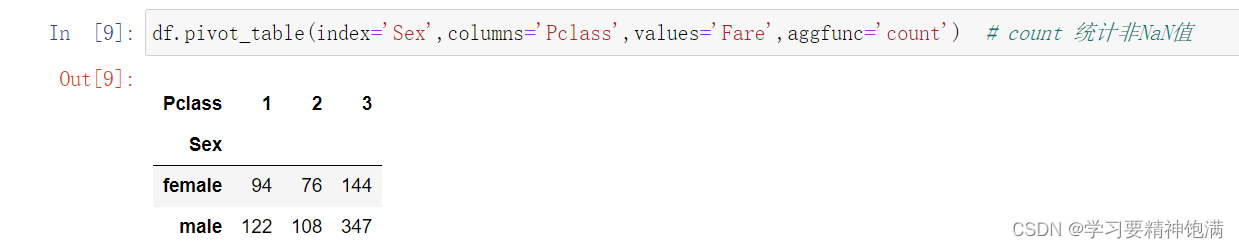
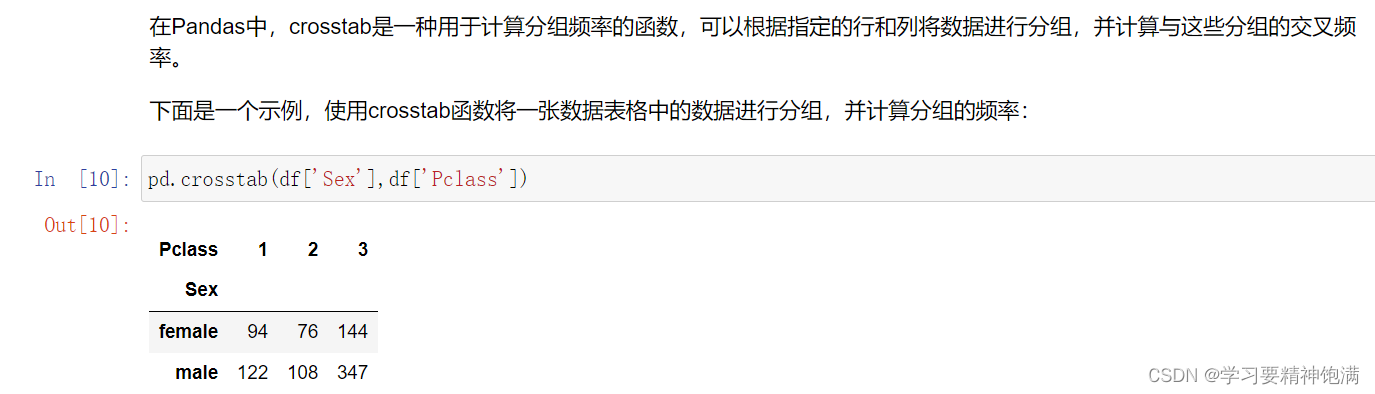
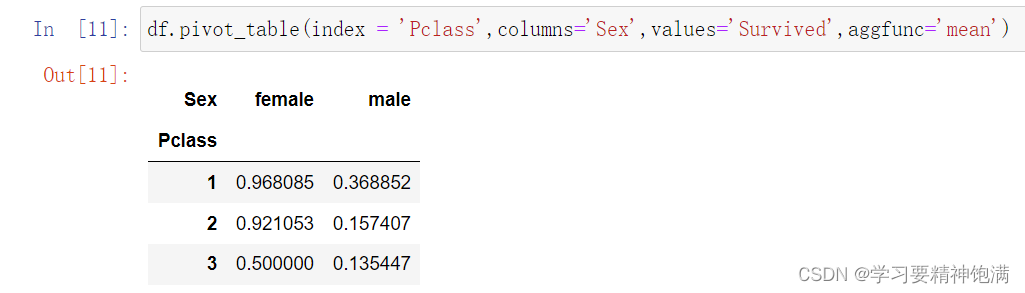
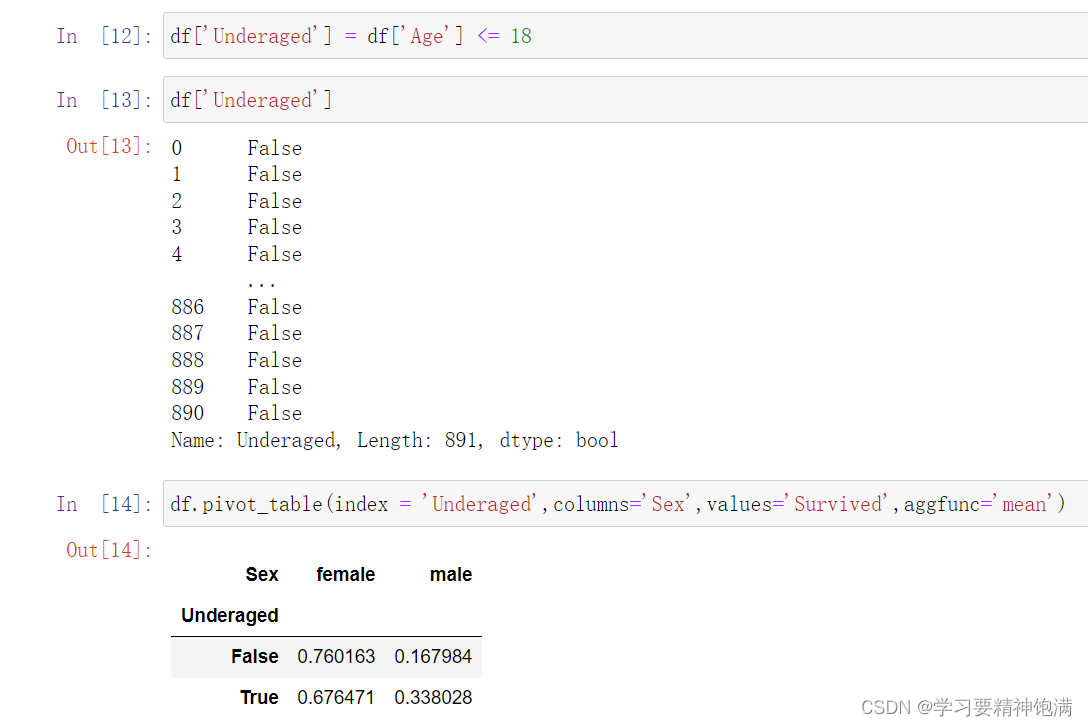
在Pandas中,pivot是一种数据重塑的操作,可以通过某些列作为行索引、某些列作为列索引和某些列来填充新创建的表格。
下面是一个示例,使用Pandas的pivot函数将一张数据表格重塑为一个新的表格。

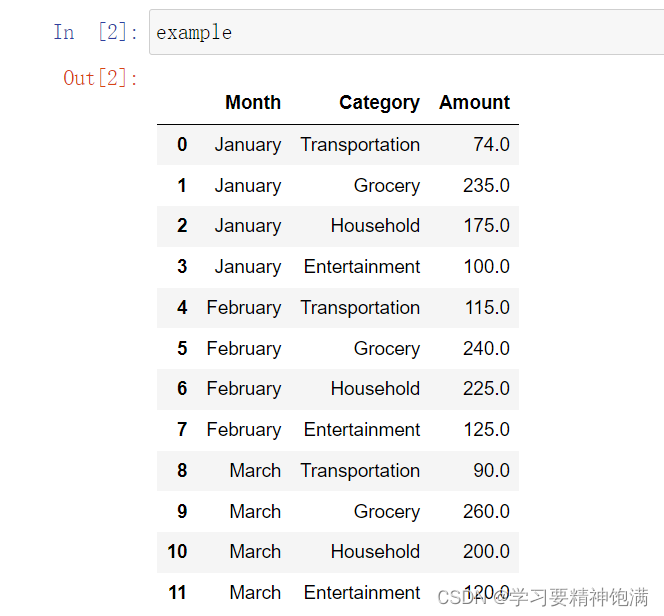
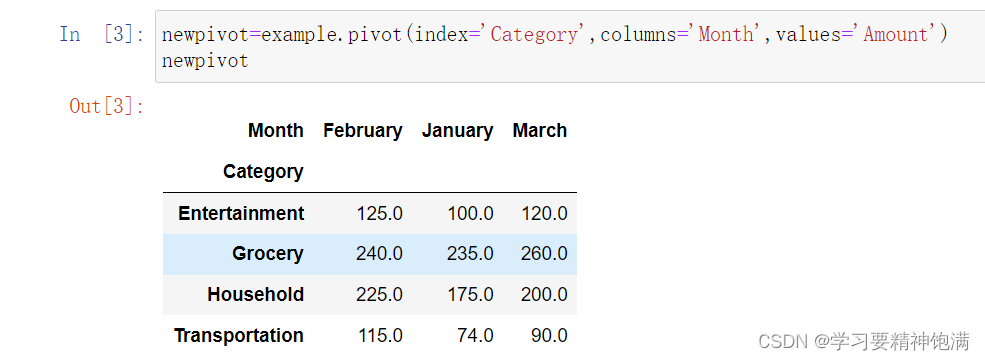
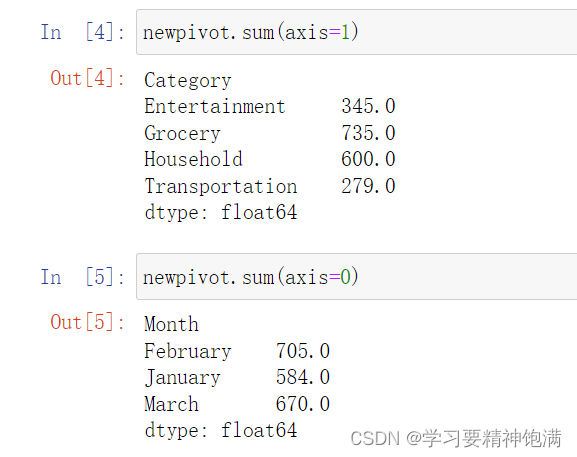

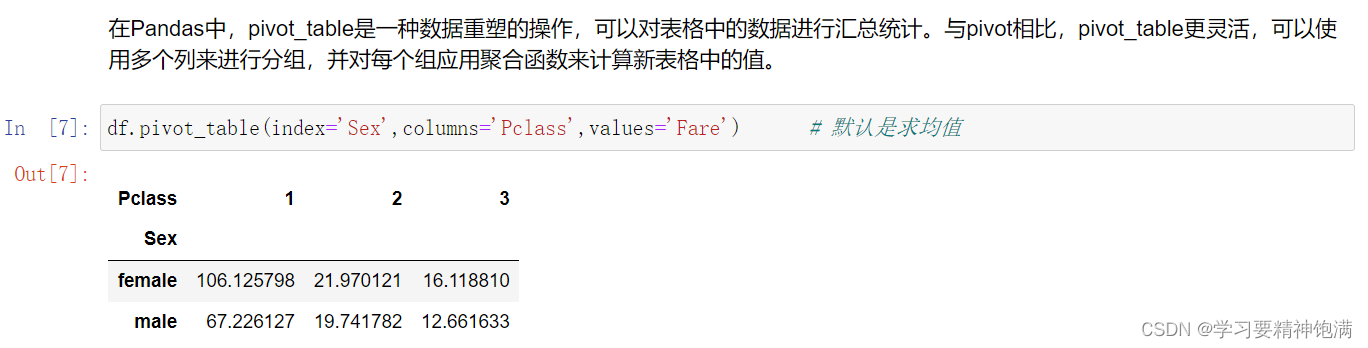
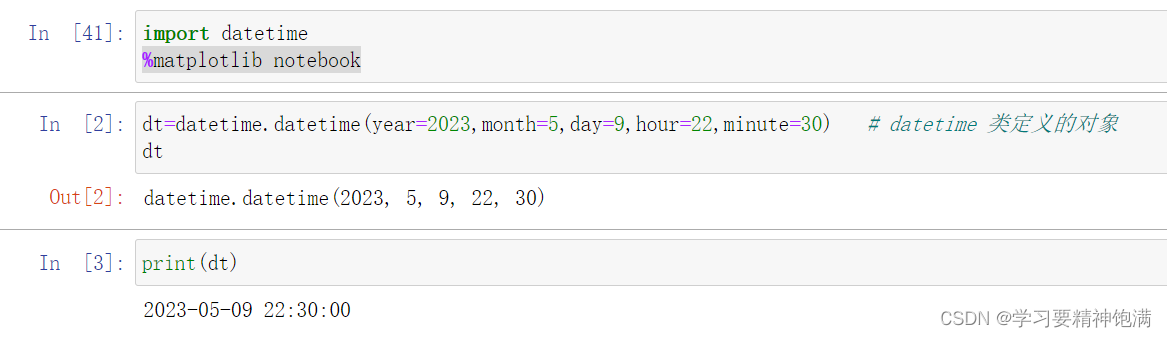
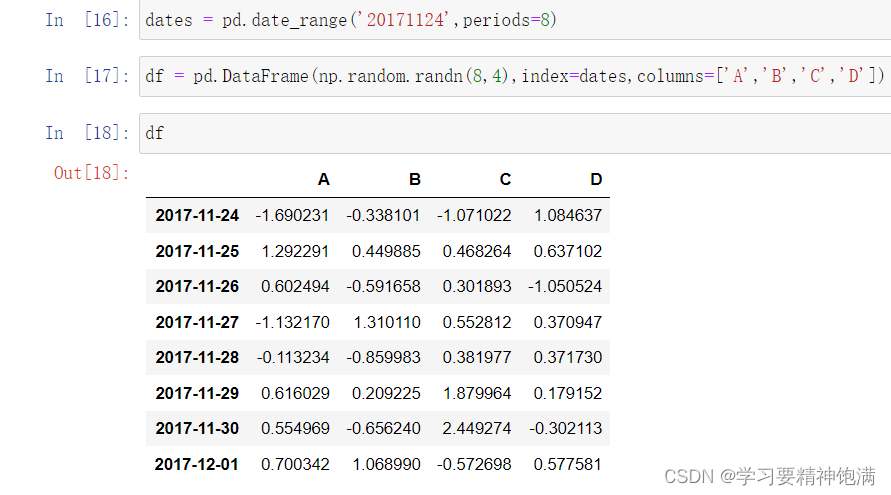
10. 时间操作
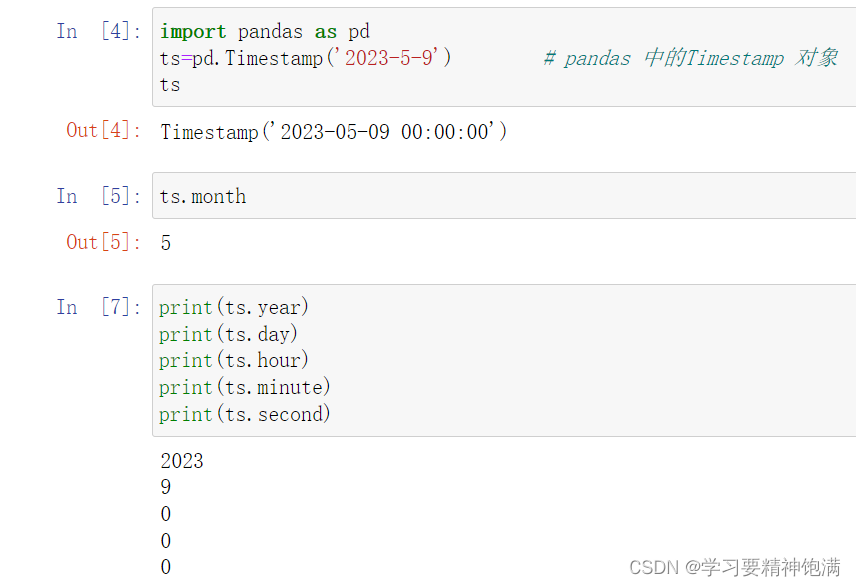
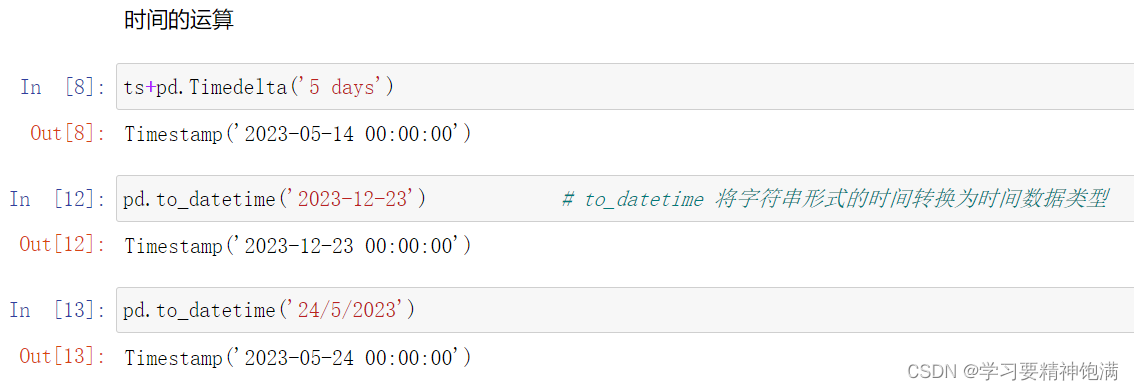
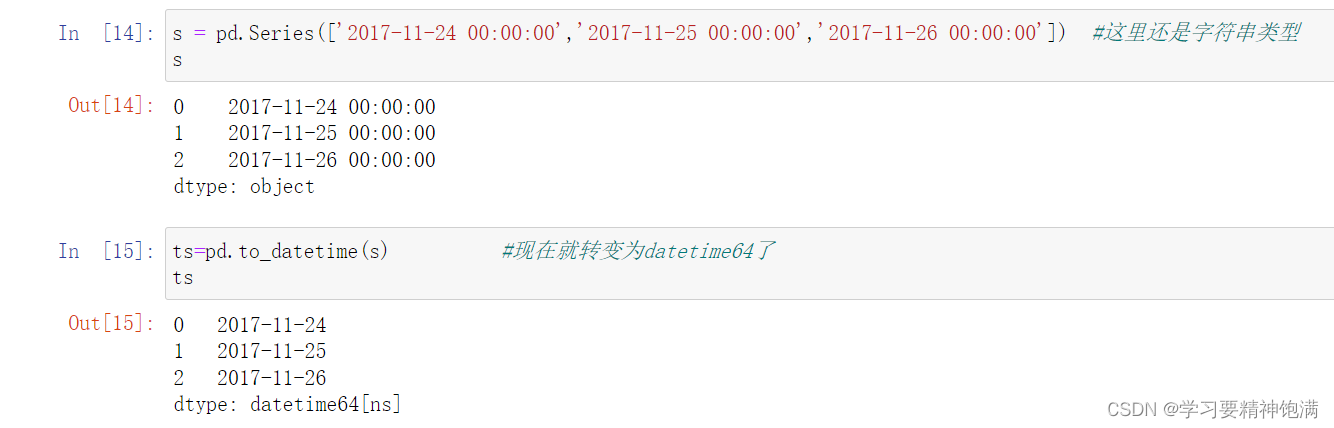

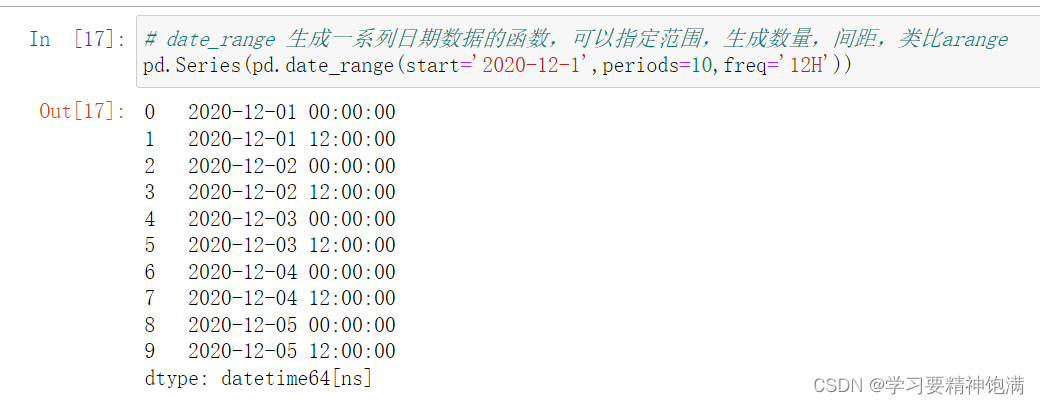
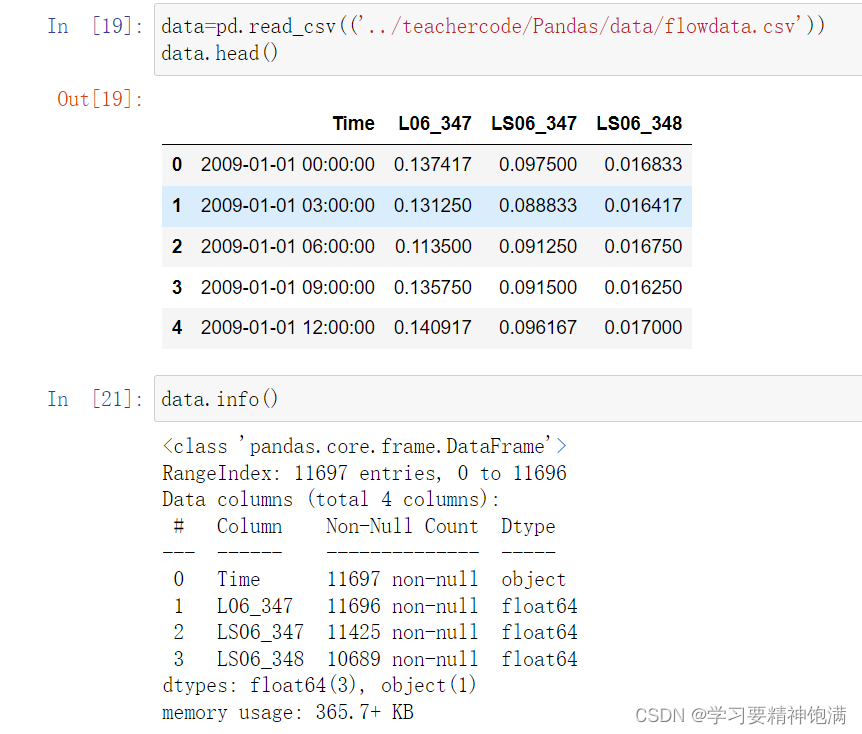
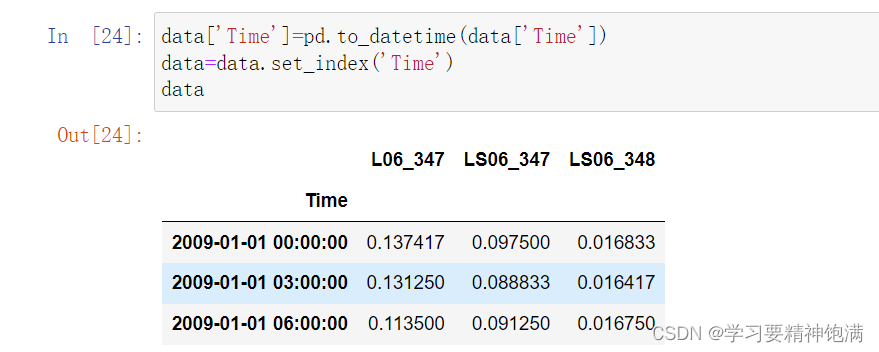
下面在pd.read_csv()中直接指定0列为索引并且本来这一类是字符串类型 直接设置parse_dates=True 就把字符串解析成Pandas中的时间类型
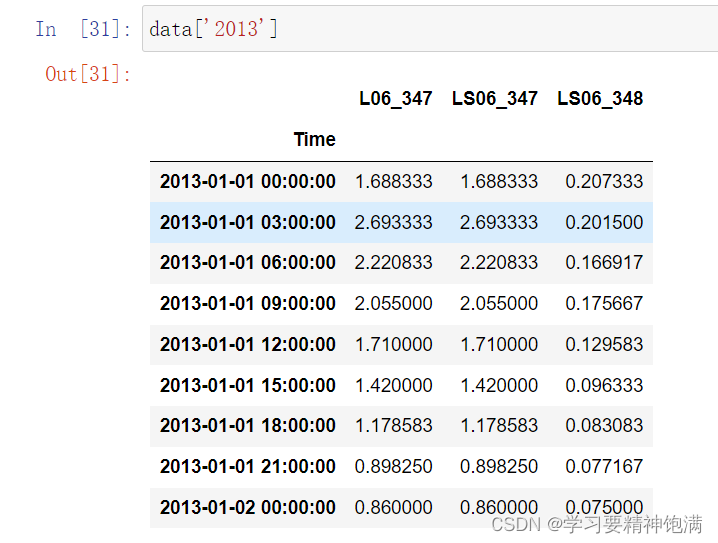
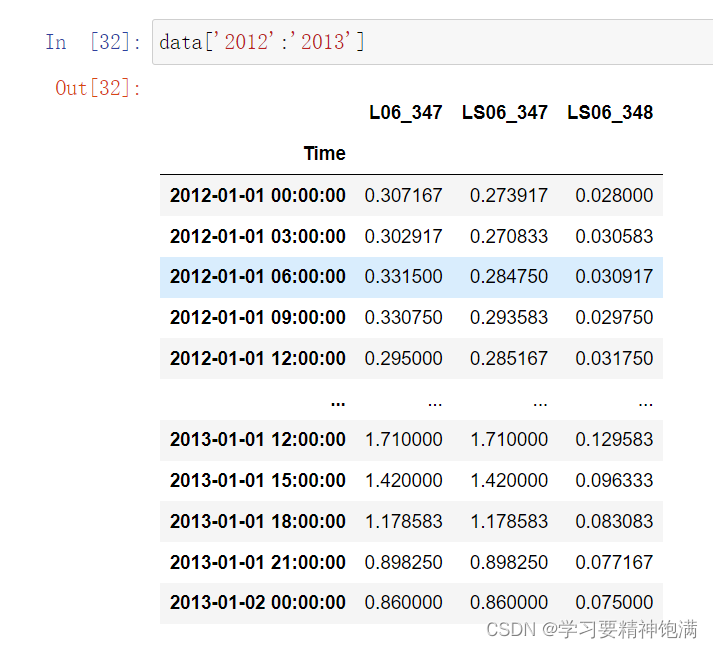
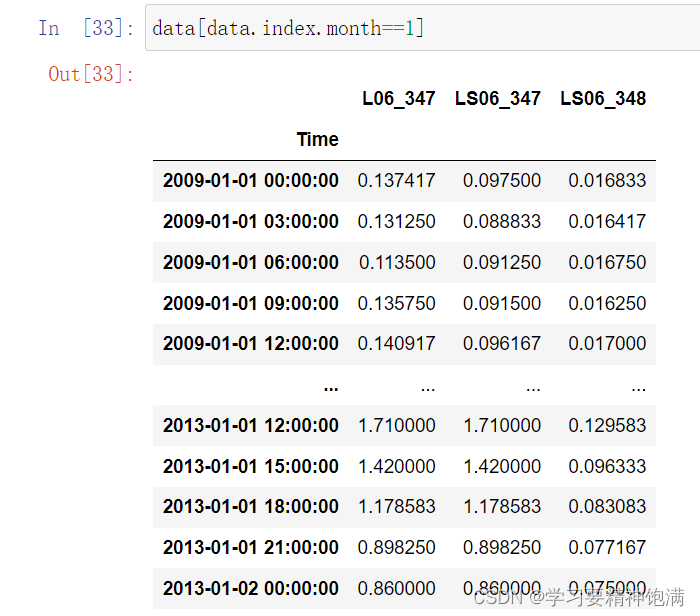
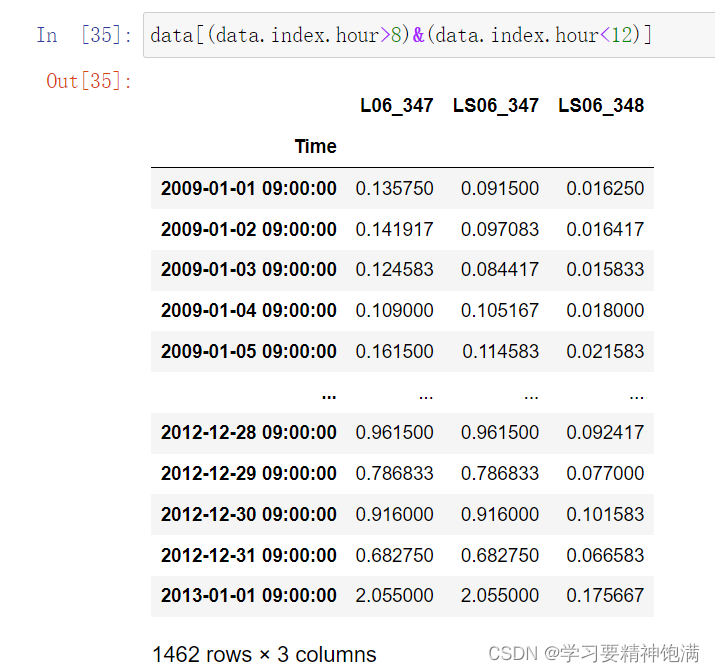
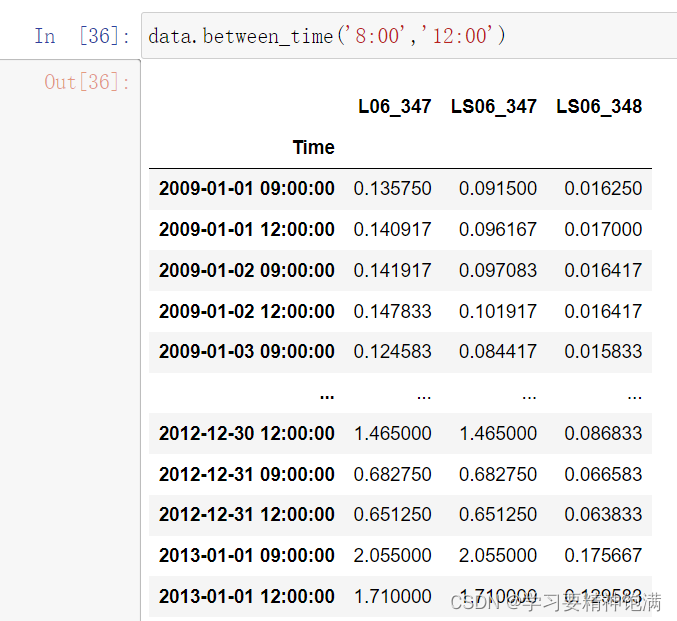
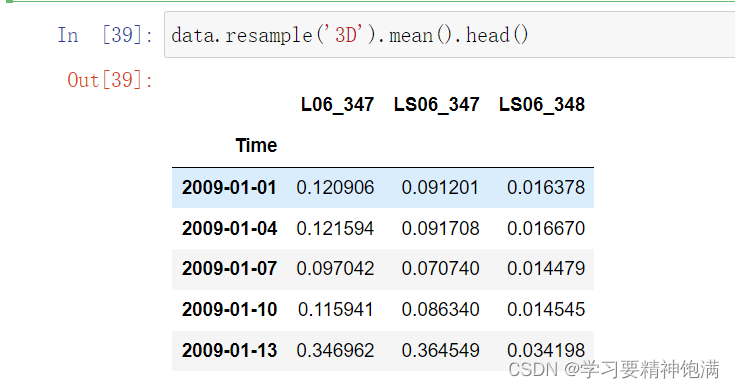
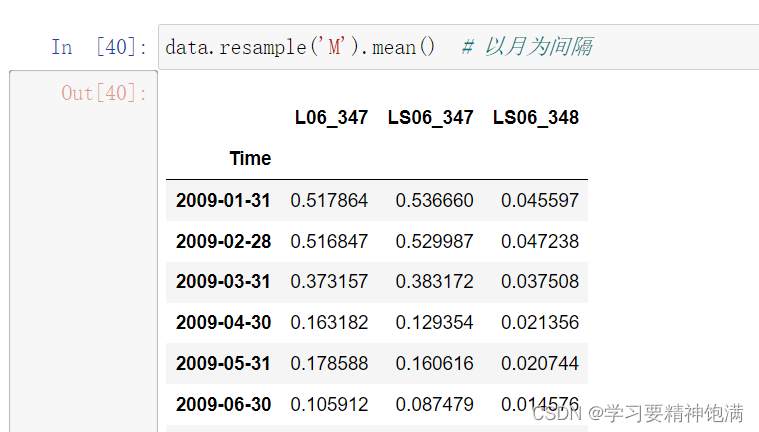
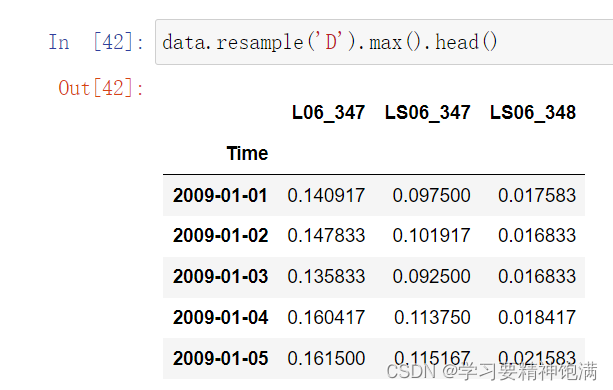
resample 重采样函数,对时间数据重新编排

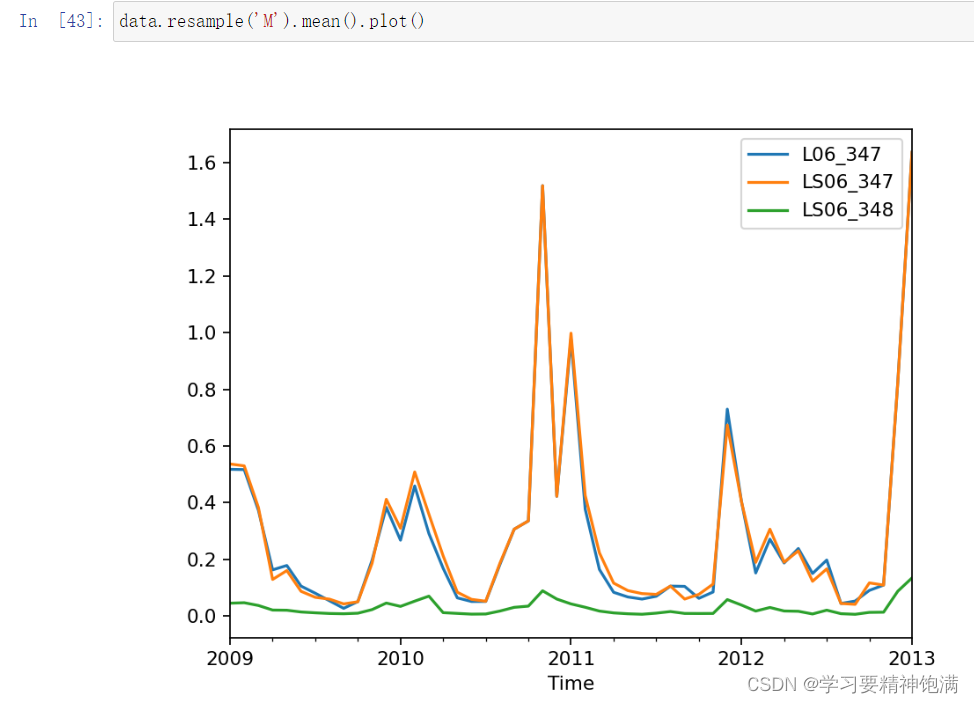
11.常用操作
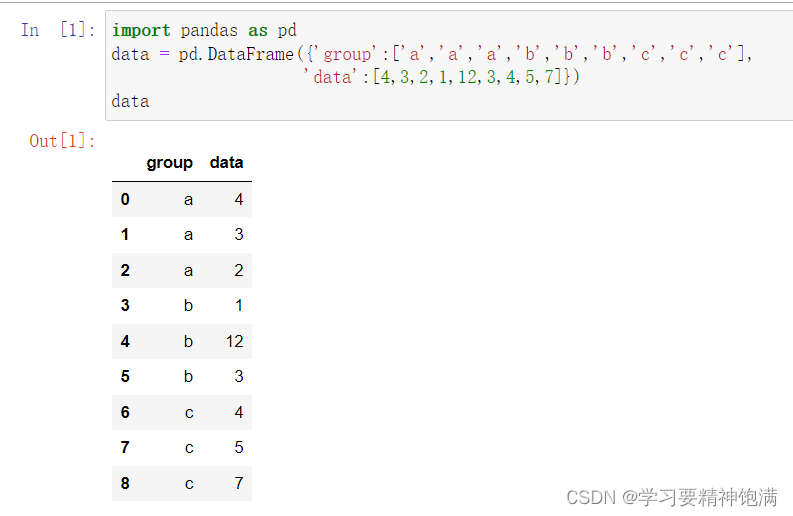
- DataFrame.info()
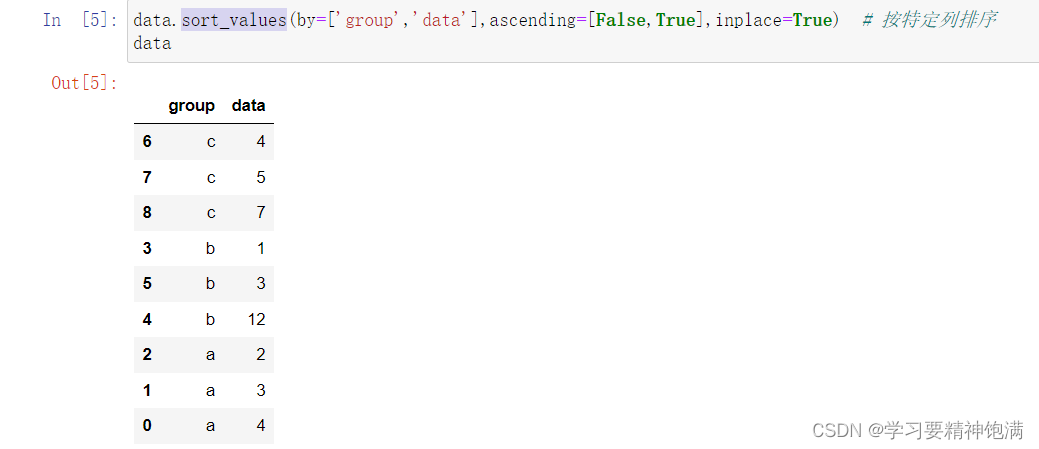
- DataFrame.sort_values()
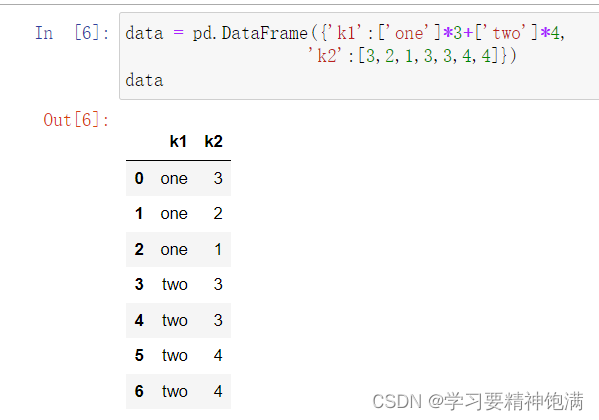


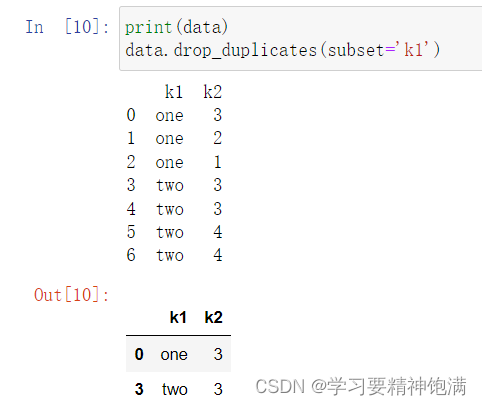
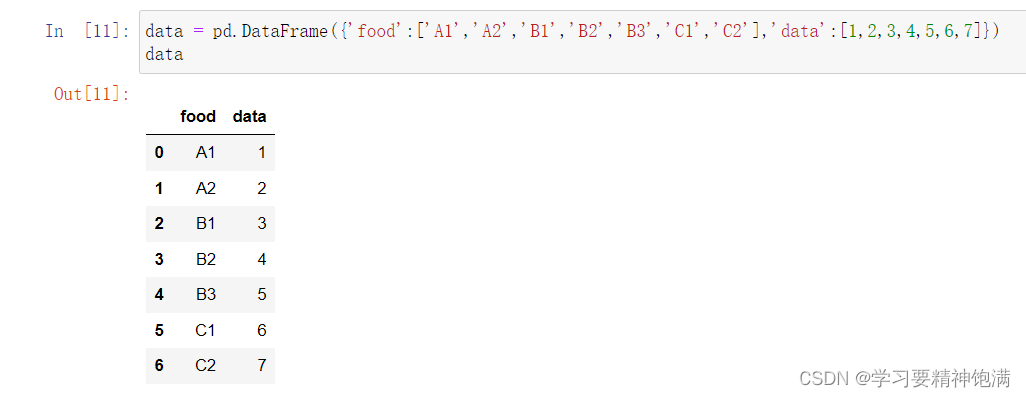
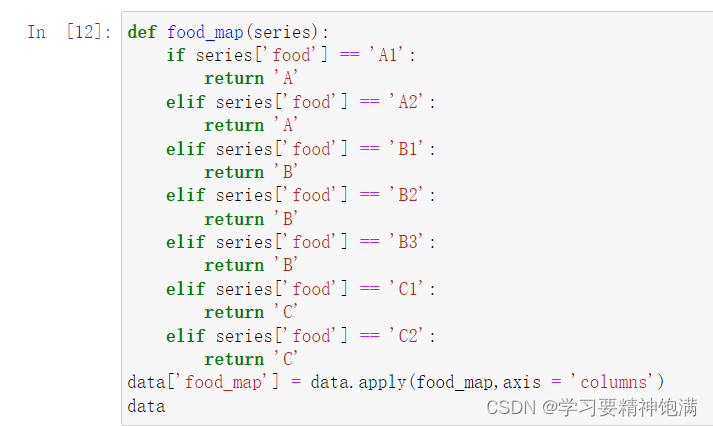
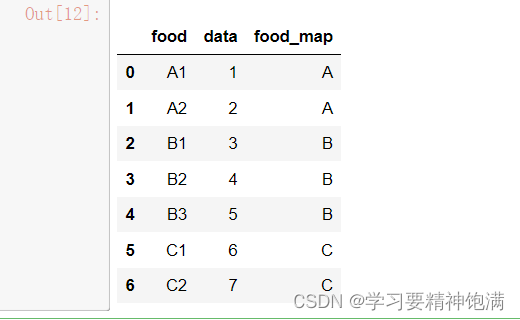
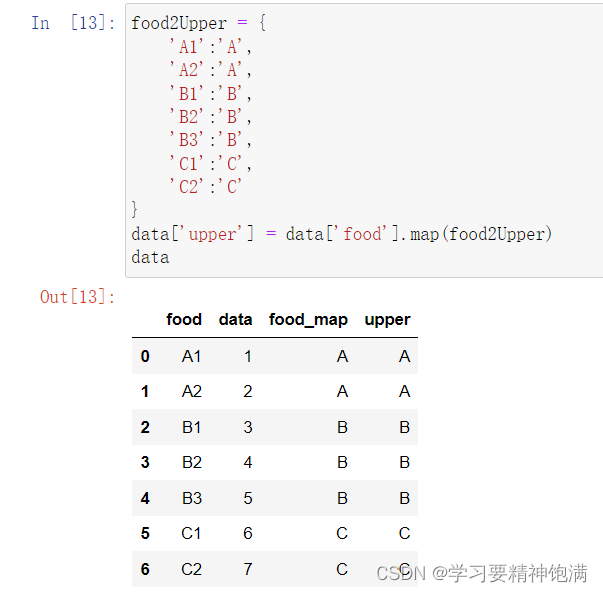
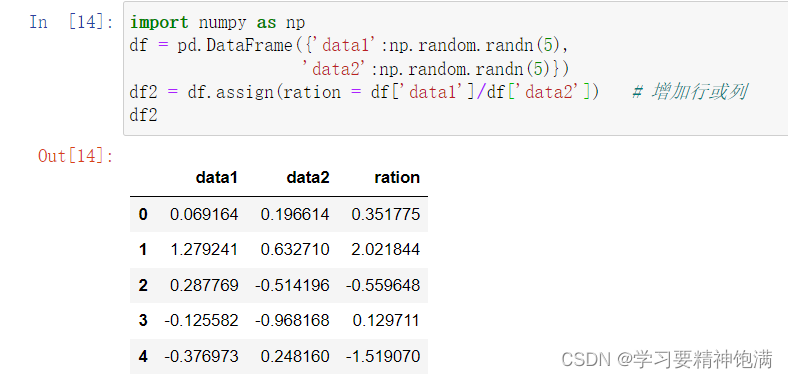
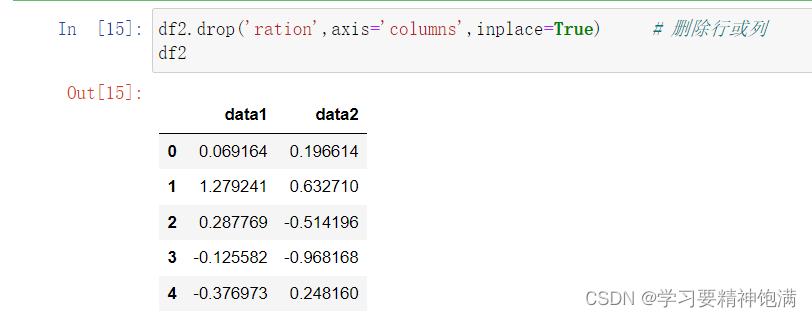



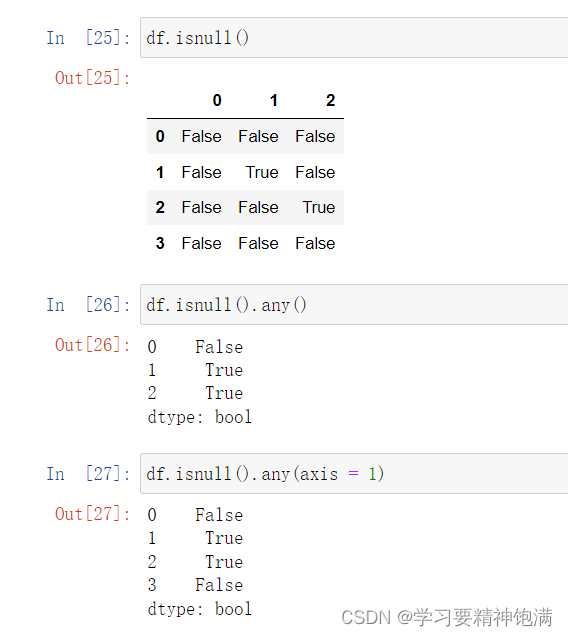
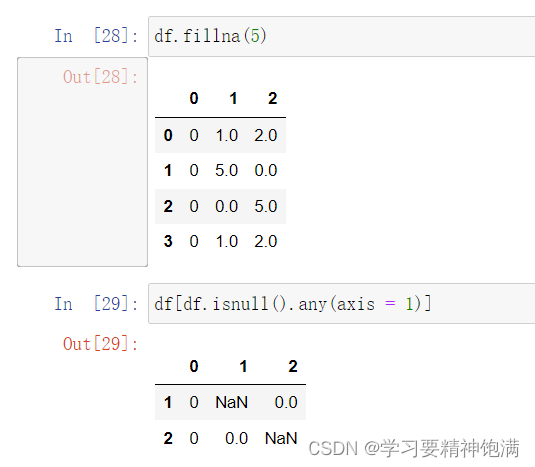
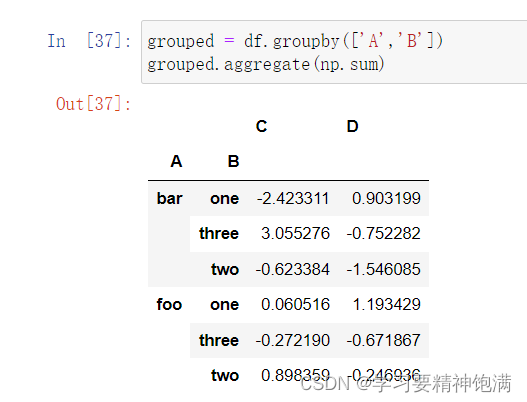
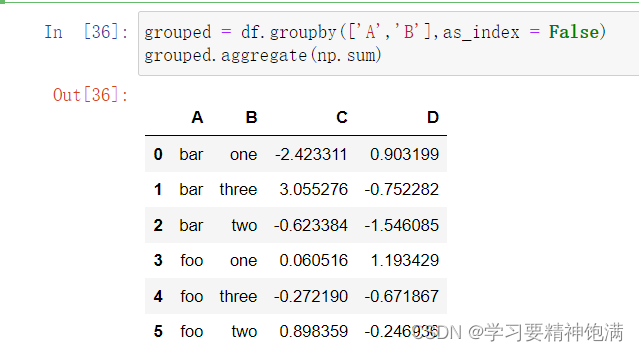
12.groupby操作
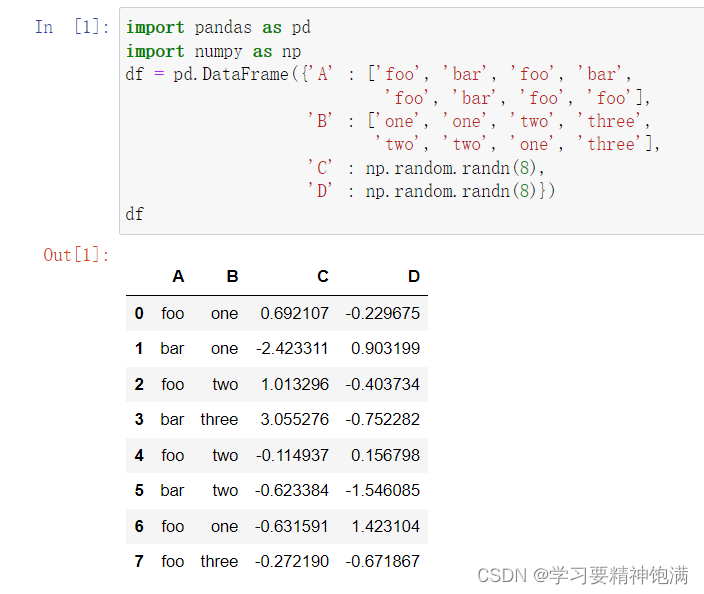
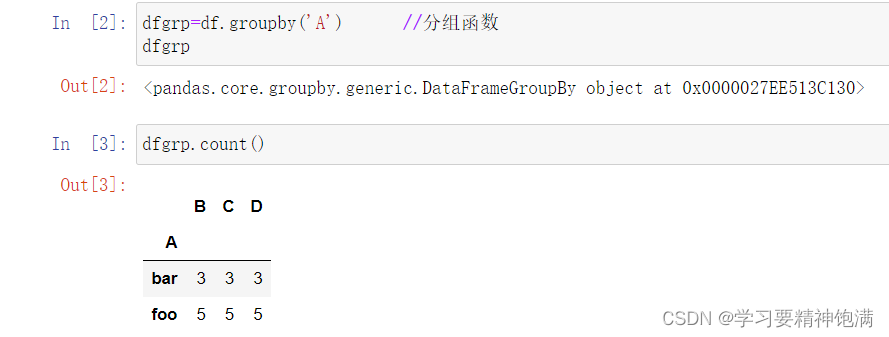
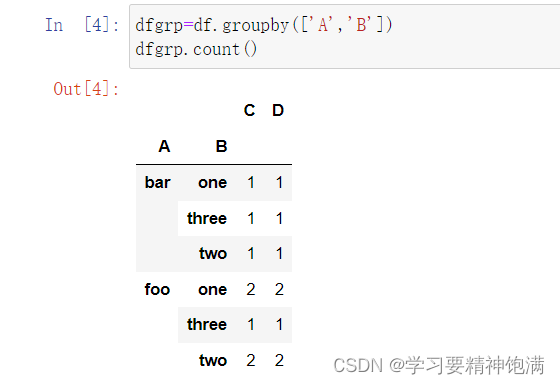

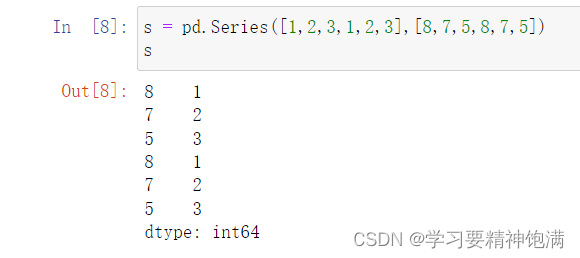
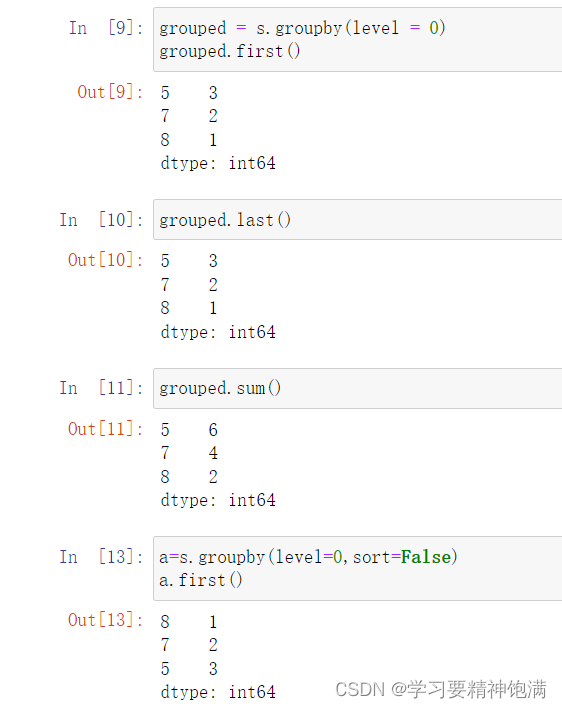
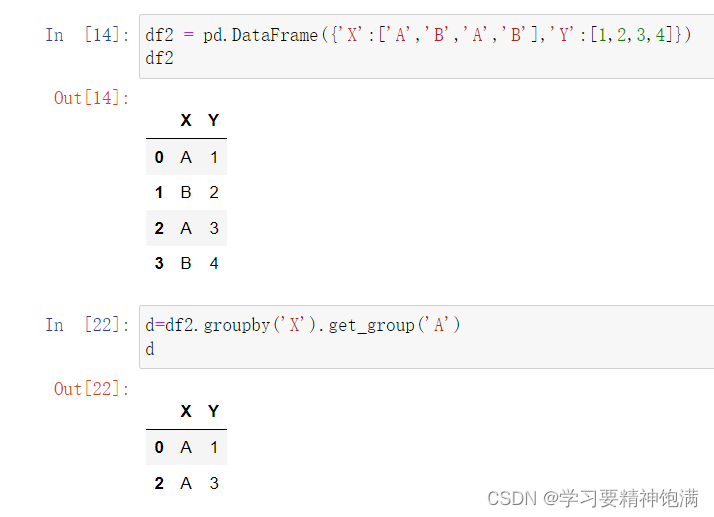



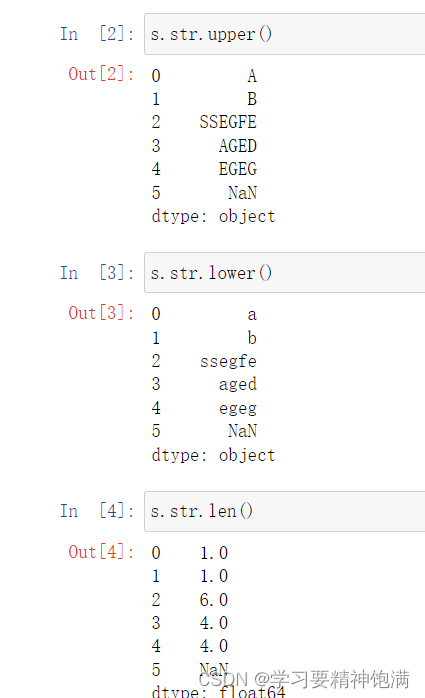
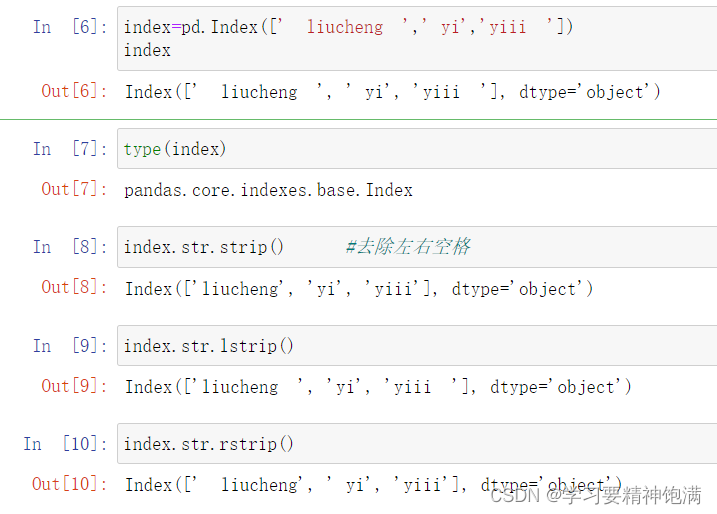
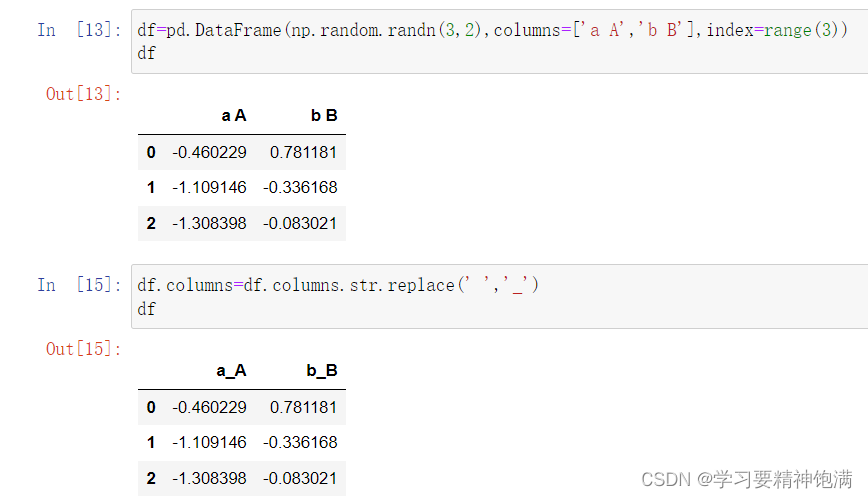
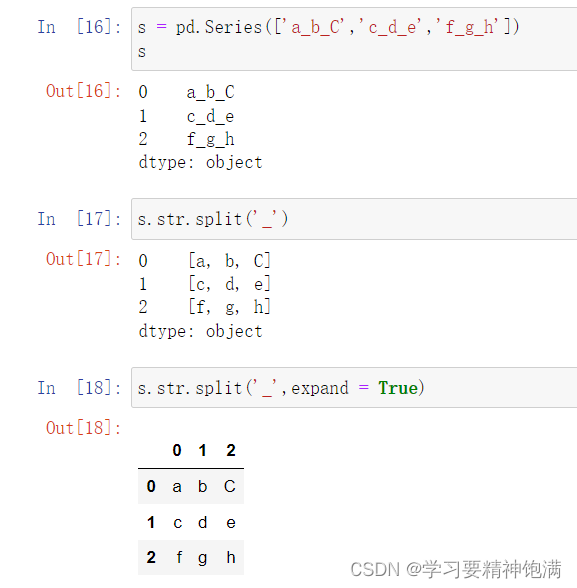
13.字符串操作
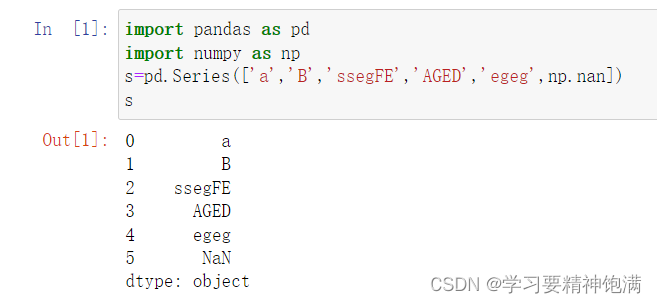
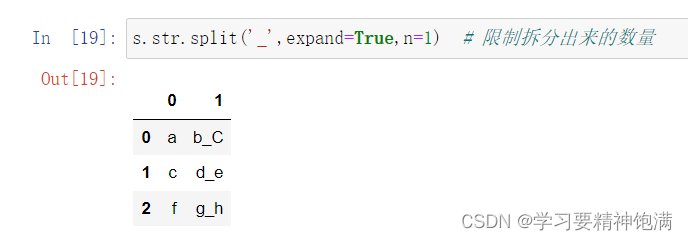
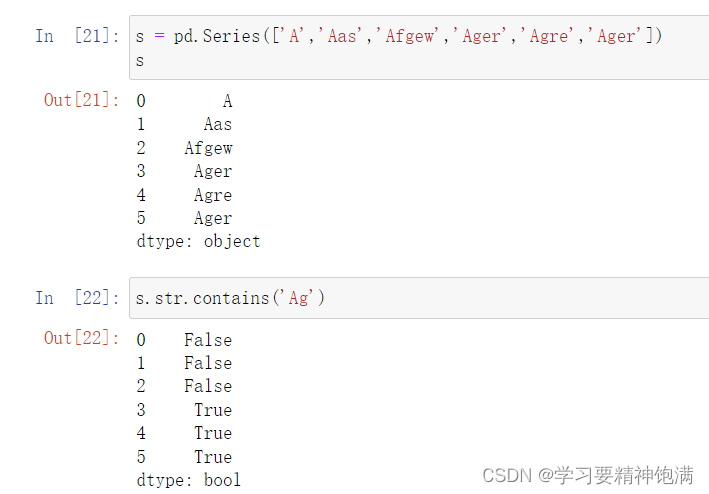
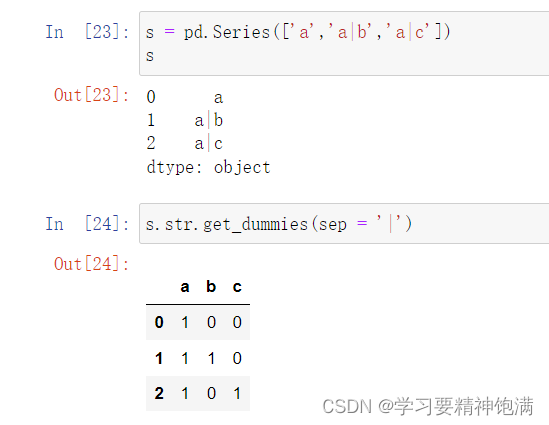
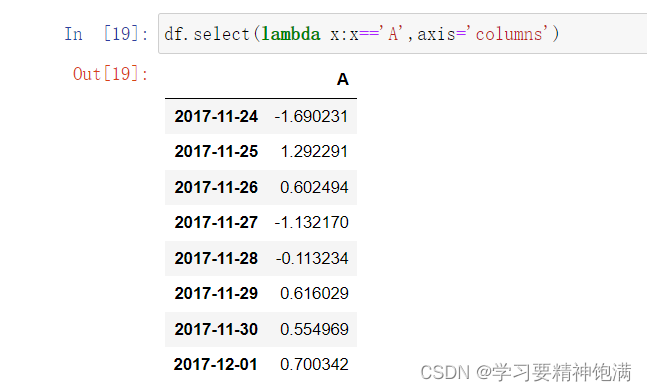
14.索引操作
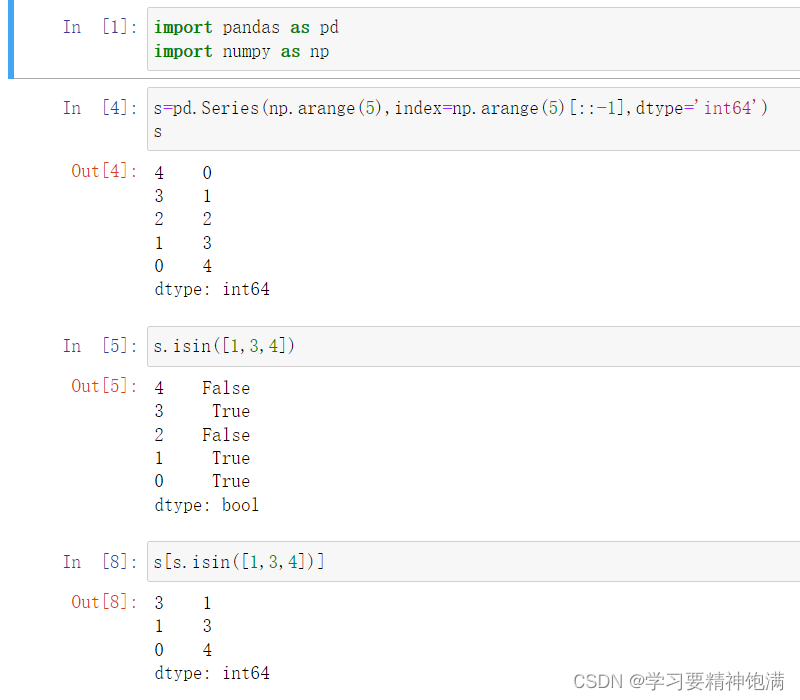
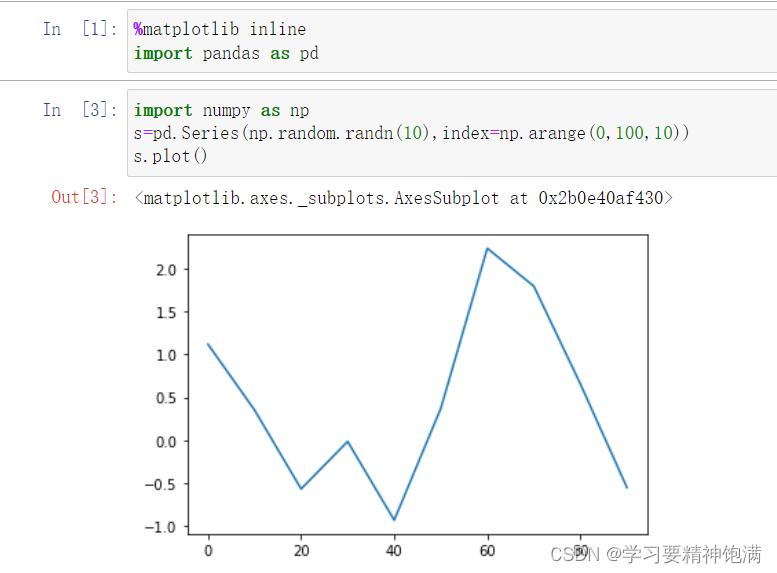
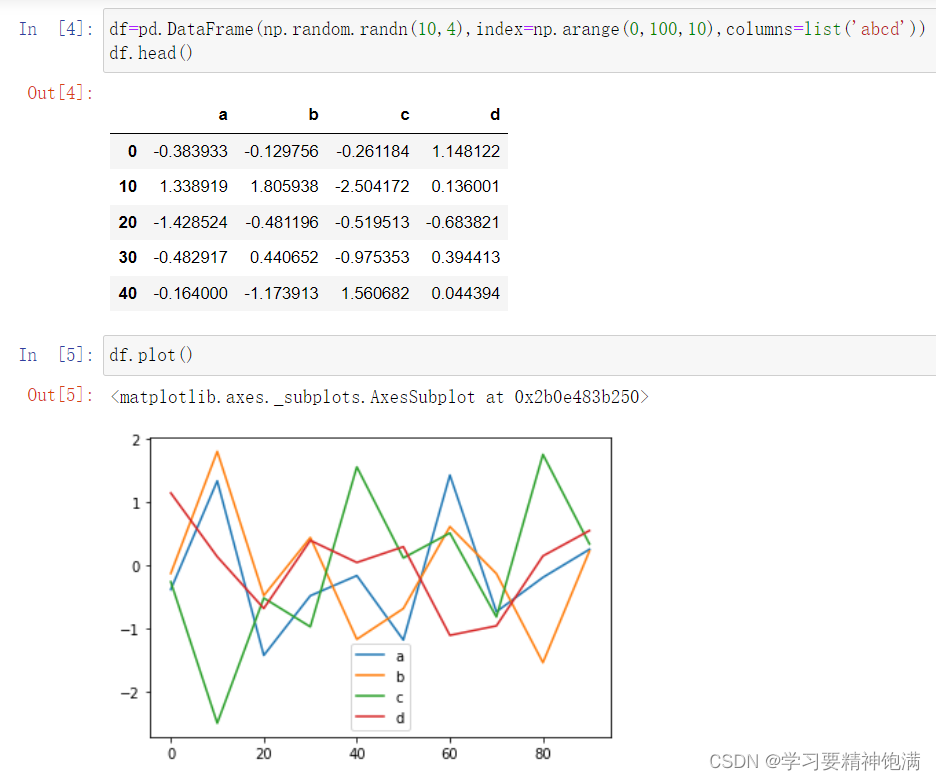
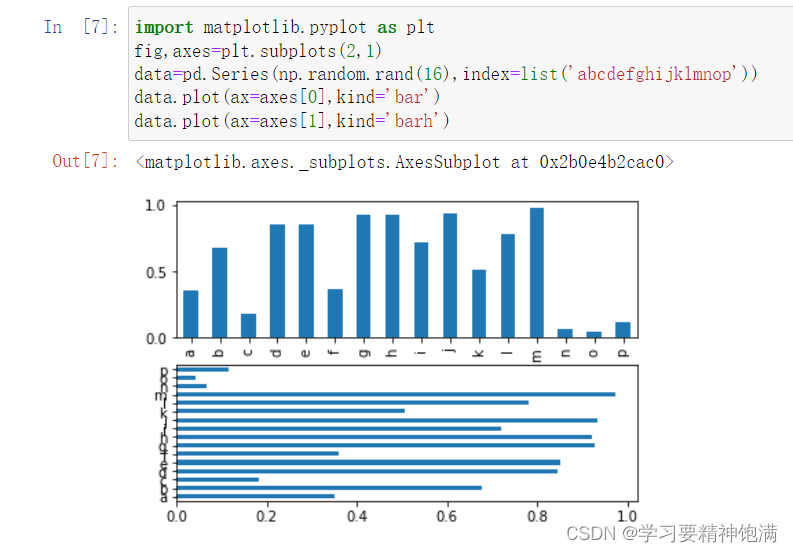
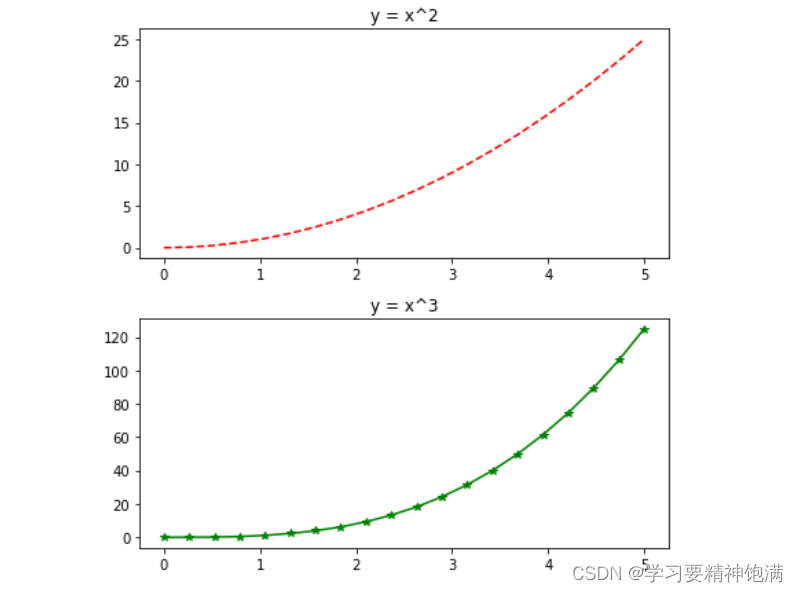
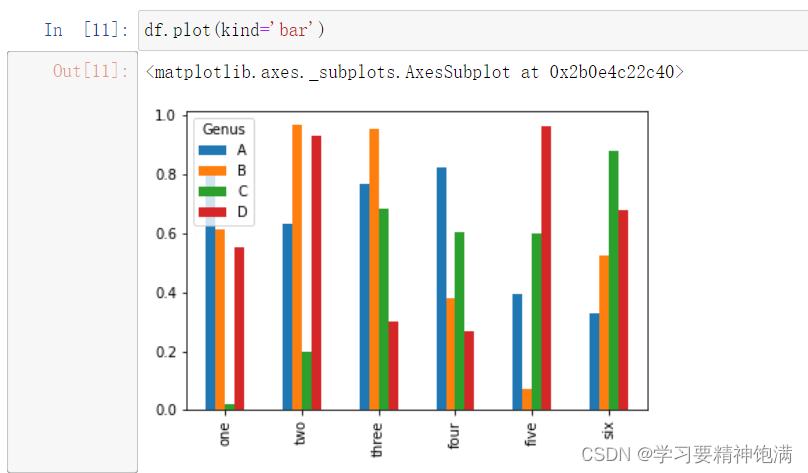
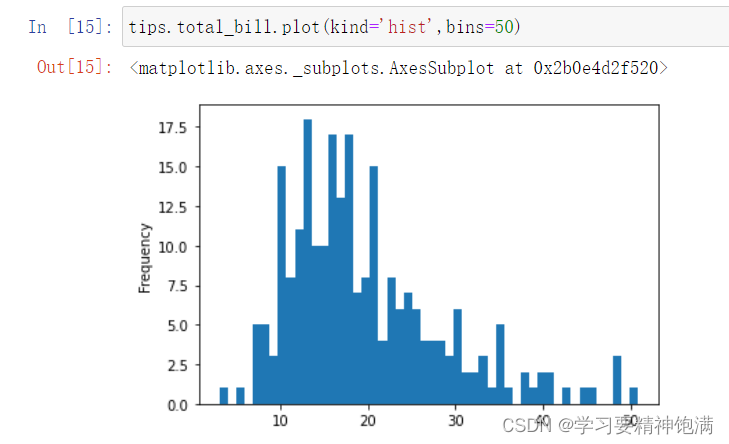
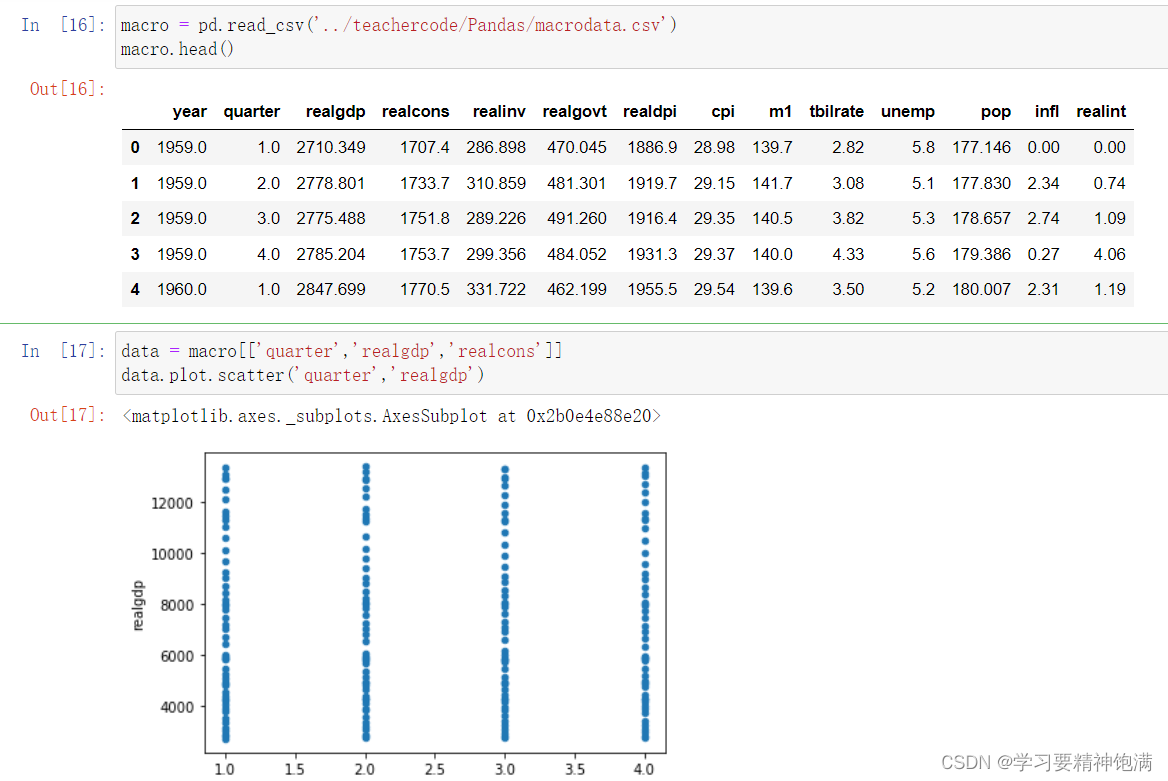
15.pandas绘图操作