一、检测慢订阅者(自杀的蜗牛模式)
在使用发布-订阅模式的时候,最常见的问题之一是如何处理响应较慢的订阅者。理想状况下,发布者能以全速发送消息给订阅者,但现实中,订阅者会需要对消息做较长时间的处理,或者写得不够好,无法跟上发布者的脚步。
如何处理慢订阅者?最好的方法当然是让订阅者高效起来,不过这需要额外的工作。以下是一些处理慢订阅者的方法:
1、在发布者中贮存消息。这是Gmail的做法,如果过去的几小时里没有阅读邮件的话,它会把邮件保存起来。但在高吞吐量的应用中,发布者堆积消息往往会导致内存溢出,最终崩溃。特别是当同是有多个订阅者时,或者无法用磁盘来做一个缓冲,情况就会变得更为复杂。
2、在订阅者中贮存消息。这种做法要好的多,其实ZMQ默认的行为就是这样的。如果非得有一个人会因为内存溢出而崩溃,那也只会是订阅者,而非发布者,这挺公平的。然而,这种做法只对瞬间消息量很大的应用才合理,订阅者只是一时处理不过来,但最终会赶上进度。但是,这还是没有解决订阅者速度过慢的问题。
3、暂停发送消息。这也是Gmail的做法,当我的邮箱容量超过7.554GB时,新的邮件就会被Gmail拒收或丢弃。这种做法对发布者来说很有益,ZMQ中若设置了阈值(HWM),其默认行为也就是这样的。但是,我们仍不能解决慢订阅者的问题,我们只是让消息变得断断续续而已。
4、断开与满订阅者的连接。这是hotmail的做法,如果连续两周没有登录,它就会断开,这也是为什么我正在使用第十五个hotmail邮箱。不过这种方案在ZMQ里是行不通的,因为对于发布者而言,订阅者是不可见的,无法做相应处理。
看来没有一种经典的方式可以满足我们的需求,所以我们就要进行创新了。我们可以让订阅者自杀,而不仅仅是断开连接。这就是“自杀的蜗牛”模式。当订阅者发现自身运行得过慢时(对于慢速的定义应该是一个配置项,当达到这个标准时就大声地喊出来吧,让程序员知道),它会哀嚎一声,然后自杀。
订阅者如何检测自身速度过慢呢?一种方式是为消息进行编号,并在发布者端设置阈值。当订阅者发现消息编号不连续时,它就知道事情不对劲了。这里的阈值就是订阅者自杀的值。
这种方案有两个问题:一、如果我们连接的多个发布者,我们要如何为消息进行编号呢?解决方法是为每一个发布者设定一个唯一的编号,作为消息编号的一部分。二、如果订阅者使用ZMQ_SUBSRIBE选项对消息进行了过滤,那么我们精心设计的消息编号机制就毫无用处了。
有些情形不会进行消息的过滤,所以消息编号还是行得通的。不过更为普遍的解决方案是,发布者为消息标注时间戳,当订阅者收到消息时会检测这个时间戳,如果其差别达到某一个值,就发出警报并自杀。
当订阅者有自身的客户端或服务协议,需要保证最大延迟时间时,自杀的蜗牛模式会很合适。撤销一个订阅者也许并不是最周全的方案,但至少不会引发后续的问题。如果订阅者收到了过时的消息,那可能会对数据造成进一步的破坏,而且很难被发现。
以下是自杀的蜗牛模式的最简实现:
suisnail: Suicidal Snail in C
//
// 自杀的蜗牛模式
//
#include "czmq.h"
// ---------------------------------------------------------------------
// 该订阅者会连接至发布者,接收所有的消息,
// 运行过程中它会暂停一会儿,模拟复杂的运算过程,
// 当发现收到的消息超过1秒的延迟时,就自杀。
#define MAX_ALLOWED_DELAY 1000 // 毫秒
static void
subscriber (void *args, zctx_t *ctx, void *pipe)
{
// 订阅所有消息
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_connect (subscriber, "tcp://localhost:5556");
// 获取并处理消息
while (1) {
char *string = zstr_recv (subscriber);
int64_t clock;
int terms = sscanf (string, "%" PRId64, &clock);
assert (terms == 1);
free (string);
// 自杀逻辑
if (zclock_time () - clock > MAX_ALLOWED_DELAY) {
fprintf (stderr, "E: 订阅者无法跟进, 取消中\n");
break;
}
// 工作一定时间
zclock_sleep (1 + randof (2));
}
zstr_send (pipe, "订阅者中止");
}
// ---------------------------------------------------------------------
// 发布者每毫秒发送一条用时间戳标记的消息
static void
publisher (void *args, zctx_t *ctx, void *pipe)
{
// 准备发布者
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5556");
while (1) {
// 发送当前时间(毫秒)给订阅者
char string [20];
sprintf (string, "%" PRId64, zclock_time ());
zstr_send (publisher, string);
char *signal = zstr_recv_nowait (pipe);
if (signal) {
free (signal);
break;
}
zclock_sleep (1); // 等待1毫秒
}
}
// 下面的代码会启动一个订阅者和一个发布者,当订阅者死亡时停止运行
//
int main (void)
{
zctx_t *ctx = zctx_new ();
void *pubpipe = zthread_fork (ctx, publisher, NULL);
void *subpipe = zthread_fork (ctx, subscriber, NULL);
free (zstr_recv (subpipe));
zstr_send (pubpipe, "break");
zclock_sleep (100);
zctx_destroy (&ctx);
return 0;
}几点说明:
1、示例程序中的消息包含了系统当前的时间戳(毫秒)。在现实应用中,你应该使用时间戳作为消息头,并提供消息内容。
2、示例程序中的发布者和订阅者是同一个进程的两个线程。在现实应用中,他们应该是两个不同的进程。示例中这么做只是为了演示的方便。
二、高速订阅者(黑箱模式)
发布-订阅模式的一个典型应用场景是大规模分布式数据处理。如要处理从证券市场上收集到的数据,可以在证券交易系统上设置一个发布者,获取价格信息,并发送给一组订阅者。如果我们有很多订阅者,我们可以使用TCP。如果订阅者到达一定的量,那我们就应该使用可靠的广播协议,如pgm。
假设我们的发布者每秒产生10万条100个字节的消息。在剔除了不需要的市场信息后,这个比率还是比较合理的。现在我们需要记录一天的数据(8小时约有250GB),再将其传入一个模拟网络,即一组订阅者。虽然10万条数据对ZMQ来说很容易处理,但我们需要更高的速度。
假设我们有多台机器,一台做发布者,其他的做订阅者。这些机器都是8核的,发布者那台有12核。
在我们开始发布消息时,有两点需要注意:
1、即便只是处理很少的数据,订阅者仍有可能跟不上发布者的速度;
2、当处理到6M/s的数据量时,发布者和订阅者都有可能达到极限。
首先,我们需要将订阅者设计为一种多线程的处理程序,这样我们就能在一个线程中读取消息,使用其他线程来处理消息。一般来说,我们对每种消息的处理方式都是不同的。这样一来,订阅者可以对收到的消息进行一次过滤,如根据头信息来判别。当消息满足某些条件,订阅者会将消息交给worker处理。用ZMQ的语言来说,订阅者会将消息转发给worker来处理。
这样一来,订阅者看上去就像是一个队列装置,我们可以用各种方式去连接队列装置和worker。如我们建立单向的通信,每个worker都是相同的,可以使用PUSH和PULL套接字,分发的工作就交给ZMQ吧。这是最简单也是最快速的方式:
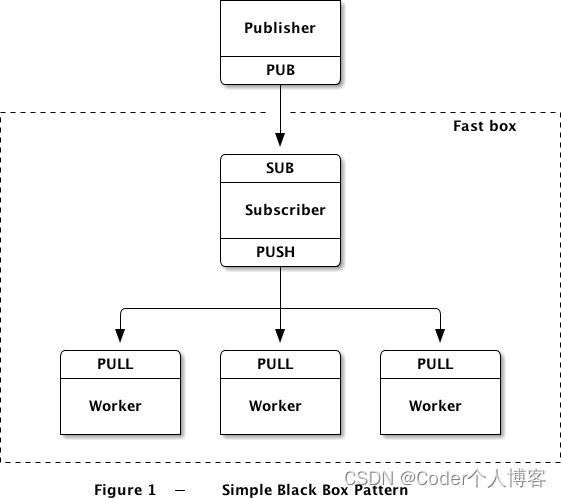
订阅者和发布者之间的通信使用TCP或PGM协议,订阅者和worker的通信由于是在同一个进程中完成的,所以使用inproc协议。
下面我们看看如何突破瓶颈。由于订阅者是单线程的,当它的CPU占用率达到100%时,它无法使用其他的核心。单线程程序总是会遇到瓶颈的,不管是2M、6M还是更多。我们需要将工作量分配到不同的线程中去,并发地执行。
很多高性能产品使用的方案是分片,就是将工作量拆分成独立并行的流。如,一半的专题数据由一个流媒体传输,另一半由另一个流媒体传输。我们可以建立更多的流媒体,但如果CPU核心数不变,那就没有必要了。
让我们看看如何将工作量分片为两个流:
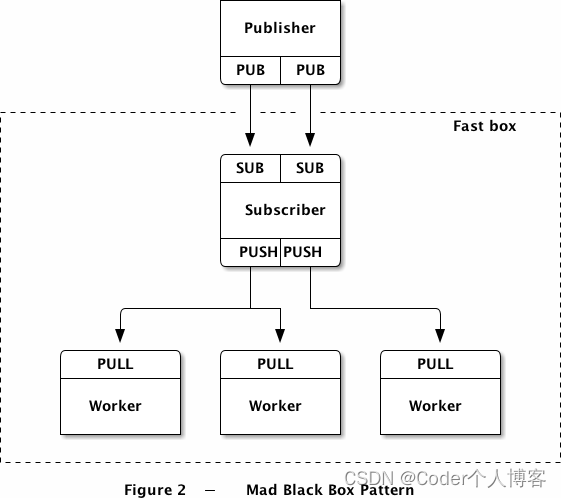
要让两个流全速工作,需要这样配置ZMQ:
1、使用两个I/O线程,而不是一个;
2、使用两个独立的网络接口;
3、每个I/O线程绑定至一个网络接口;
4、两个订阅者线程,分别绑定至一个核心;
5、使用两个SUB套接字;
6、剩余的核心供worker使用;
7、worker线程同时绑定至两个订阅者线程的PUSH套接字。
创建的线程数量应和CPU核心数一致,如果我们建立的线程数量超过核心数,那其处理速度只会减少。另外,开放多个I/O线程也是没有必要的。




![[附源码]计算机毕业设计疫情网课管理系统Springboot程序](https://img-blog.csdnimg.cn/9cb6ba6bb352464cabb23d4fa07935c1.png)



![[附源码]JAVA毕业设计计算机在线学习管理系统-(系统+LW)](https://img-blog.csdnimg.cn/223f5c8f83854fe4a82a17c636ea7c0a.png)