在了解缓存雪崩、击穿、穿透这三个问题前,我们需要知道为什么我们需要缓存。在了解这三个问题后,我们也必须知道使用Redis时,如何解决这些问题。
所以我将按照"为什么我们需要缓存"、"什么是缓存雪崩、击穿、穿透"、"如何解决这些问题"三部分,带你学懂缓存雪崩、击穿、穿透。
为什么我们需要缓存
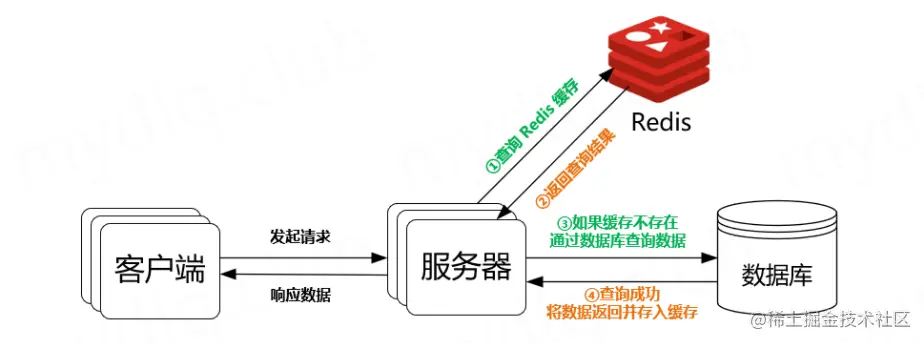
用户的数据一般都是存储于数据库,数据库的数据是落在磁盘上的,磁盘的读写速度可以说是计算机里最慢的硬件了。当用户的请求都访问数据库的话,可想而知,我们整个系统的并发量肯定是比较低的,而且如果一旦并发量上来了,数据库也很容易崩溃。
那我们可以怎么样来解决这个问题呢?
-
我们可以多用几台机器,进行负载均衡,提高系统的并发量。
-
也可以加一个中间层(缓存),避免用户直接访问数据库。
-
......
很显然,使用缓存是比较简单且经济的方案。其实,在现在的服务端开发中,缓存中间件已经是我们所离不开的了。其中Redis就是比较著名的key-value内存数据库。故本文章基于Redis编写。
什么是缓存雪崩、击穿、穿透
缓存雪崩
通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存。
这样的流程乍一看很正确,没有任何问题。实际上隐藏着一些问题,这样做将可能导致有大量的key在同一时间失效,如果此时有大量的用户请求,那就会去访问数据库,从而导致数据库的压力骤增,如果数据库顶不住当前的压力,则会导致宕机,进而引起一系列问题,最后导致系统崩溃,这就是缓存雪崩。
引发缓存雪崩有以下几种可能:
- 大量key同时失效
- 充当缓存的Redis宕机了
缓存击穿
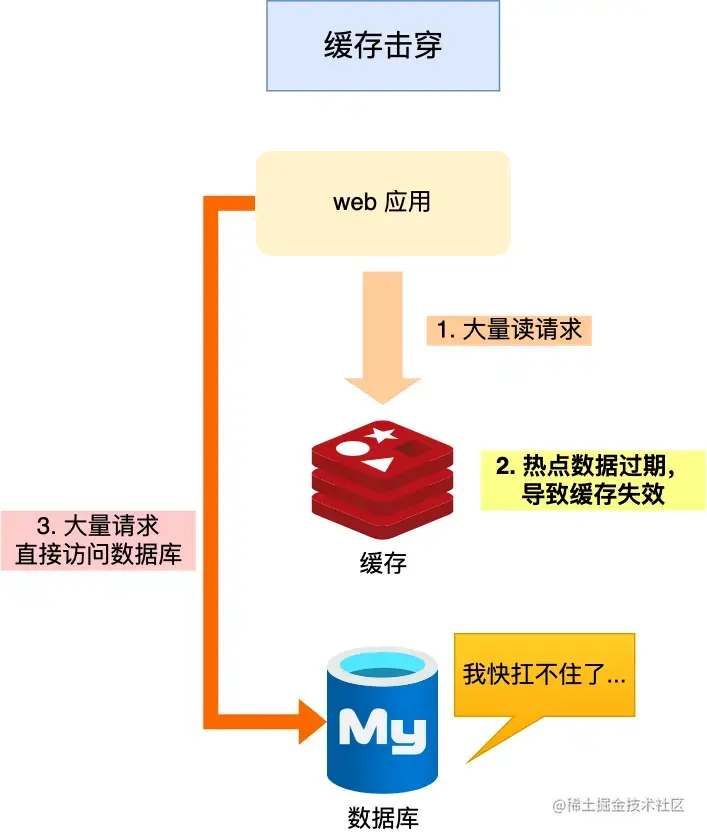
我们的业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。如果热点key在某个时间过期了,此时大量请求会打到数据库上,数据库很容易被击穿,这就是缓存击穿。
实际上缓存击穿与缓存穿透都是key失效的问题,你也可以认为缓存击穿是缓存穿透的子集。
缓存穿透
缓存雪崩和击穿都是key失效或者Redis不可用的场景,缓存穿透与它们不同。缓存穿透是当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增。
发生的原因有:
- 业务操作错误,缓存的数据或数据库的数据被删除,或者意外被用户访问到不存在的数据
- 黑客恶意攻击
如何应对
缓存雪崩应对
缓存雪崩有两种诱因,不同诱因应对的策略是不同的。
针对大量数据同时过期:
- 均匀设置过期时间
- 互斥锁
- 后台更新缓存
- ......
1.均匀设置过期时间
目的是要避免大量数据设置成同时过期。给这些设置了过期时间的key加上一个随机数,让他们尽量不同时过期。尤其是在缓存预热的时候,更需要这样做。
2.互斥锁
当业务线程在处理用户请求时,如果发现访问的数据不在Redis里,就加一个互斥锁(setnx命令可以达到这个效果),保证同一个时间内只有一个请求来构建缓存(从数据库中读,再更新到Redis),构建完后释放锁,未能获取到锁的请求,要么等锁释放后重新读取缓存,要么返回空或默认值。
java
复制代码
public class RedisTool { private static final String LOCK_SUCCESS = "OK"; private static final String SET_IF_NOT_EXIST = "NX"; private static final String SET_WITH_EXPIRE_TIME = "PX"; /** * 尝试获取分布式锁 * @param jedis Redis客户端 * @param lockKey 锁 * @param requestId 请求标识 * @param expireTime 超期时间 * @return 是否获取成功 */ public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) { String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime); if (LOCK_SUCCESS.equals(result)) { return true; } return false; } }
第一个为key,我们使用key来当锁,因为key是唯一的。
第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?分布式锁有一个条件,谁上的锁就必须谁解开,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。requestId可以使用多种方法生成,只要能保证在一段时间内不重复。
第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:1. 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。2. 已有锁存在,不做任何操作。
不过这种方法就要注意一下死锁问题,然后我代码这样写的原因是,只有一个操作,是原子性的,如果把加锁和设置过期时间分开,可能会发生一些意想不到的问题。
3.后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。虽然不设置有效期,但是其实有一个逻辑过期的标识,一旦业务线程发现这个缓存过期,就把它交给后台线程去处理。业务线程返回”过期值“。
这种方法适合用于对于缓存一致性要求不会特别严格的场景
针对Redis宕机:
- 服务熔断或进行请求限流
- 构建Redis主从或集群来保证可靠
1.服务熔断或进行请求限流
暂停业务,直接返回错误。等Redis恢复正常后,再允许业务进行。目的是保护数据库。
也可以启用限流,只允许少部分请求访问数据库,大于能承受的压力的请求直接拒绝服务。等到Redis正常且预热完毕,再解除限流。
2.构建Redis主从和哨兵或集群
主从能够分担主节点压力,有了哨兵的话,能够在Redis主节点故障时,即使切换主节点,避免Redis故障导致的缓存雪崩问题。
Redis集群(cluster)也是同理。
缓存击穿应对
上面提到缓存击穿是缓存雪崩的子集(数据过期导致的)
所以缓存击穿的解决方法与因为数据过期导致的雪崩基本一致,可以采用:
- 互斥锁方案(与上面讲的相同)
- 后台更新缓存方案(与上面讲的相同)
缓存穿透应对
应对缓存穿透的方案,常见的方案有三种:
- 非法请求的限制
- 缓存空值或者默认值
- 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
1.非法请求的限制
当不用访问数据库就能知道请求的数据是否合法时,这个方式很合适。可以直接在API的入口处做判断,避免非法请求访问缓存和数据库
2.缓存空值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
要注意缓存的空值必须设置合适的过期时间,太短则会导致缓存没有阻挡住大多数的非法请求,太长则会导致浪费内存空间。
3.使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。
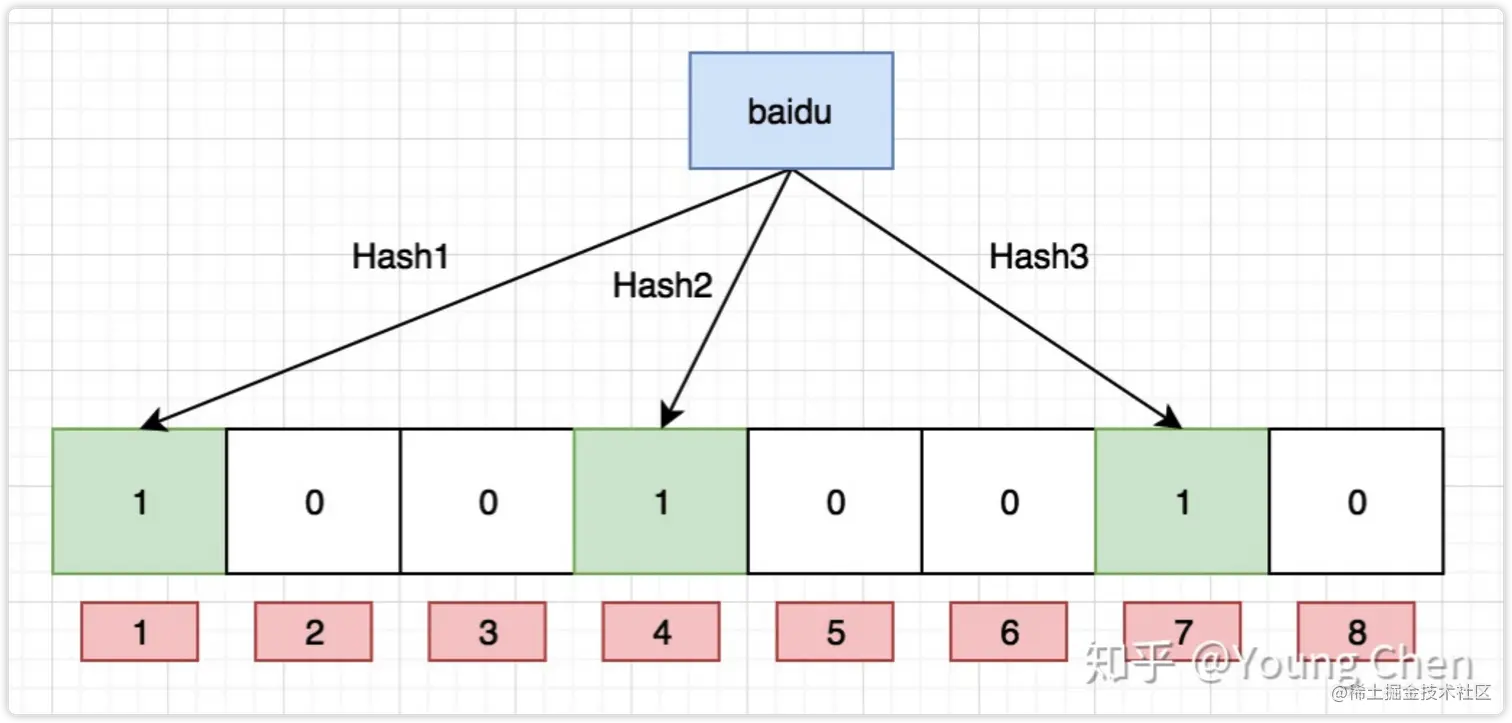
可能有部分童鞋不了解布隆过滤器,我简单的描述一下。
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记(对N个哈希函数逐一进行使用,得到的结果对数组长度取余得到最后结果,并且把最后结果对应的下标值为1)。下次查询数据在不在数据库时,可以用相同的方法,如果得到N个位置的值都为1,则这个请求大概率是合法的(即使会有部分非法请求还是会访问到数据库,但是布隆过滤器已经过滤了绝大多数了)
总结
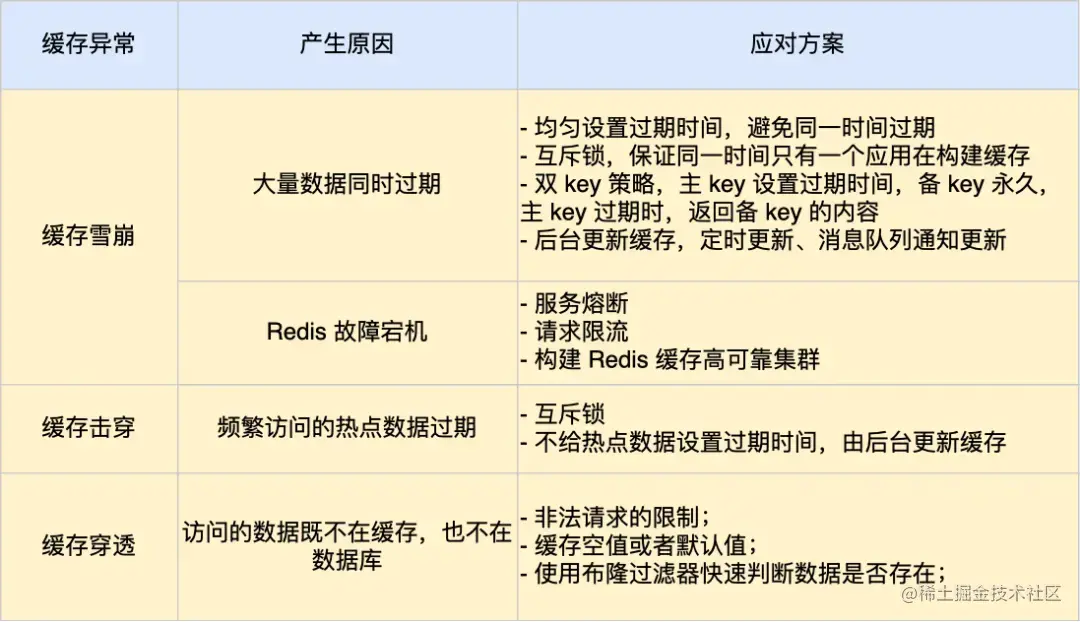
在网上找到的这张表格对上述内容进行了不错的总结。