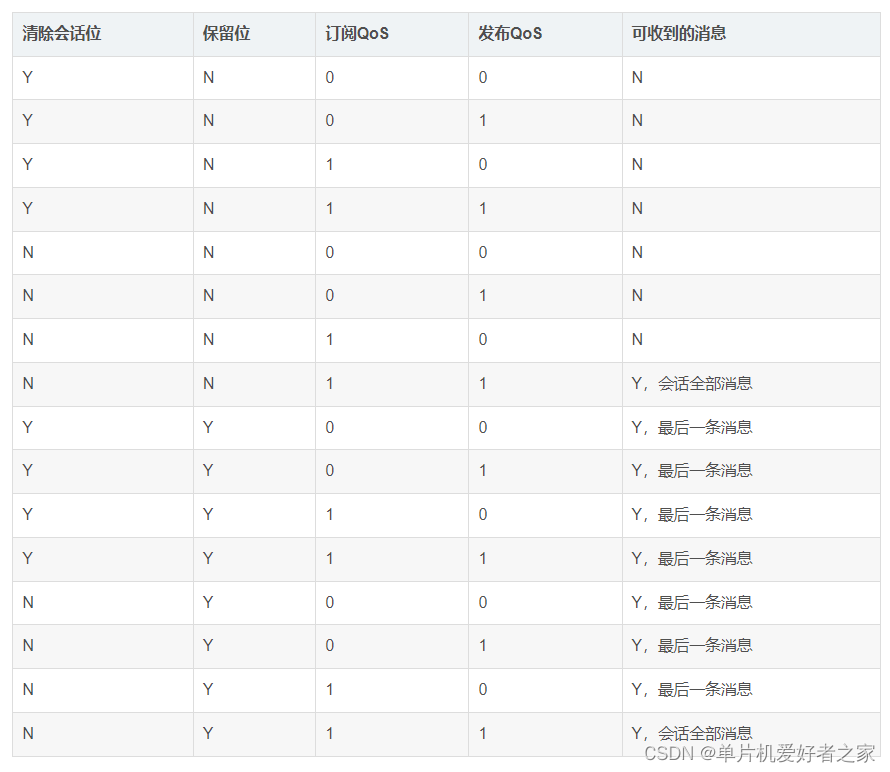
在crack缺陷检测项目原始0.739提升至 0.772 ,涨点明显,博主多个数据集亲测有效,实现暴力涨点;
现有博客都是将MobileViT作为backbone引入Yolov5,因此存在的问题点是训练显存要求巨大,本文引入自注意力的Vision Transformer(ViTs):MobileViTAttention
1. MobileViT介绍

论文:https://arxiv.org/abs/2110.02178
MobileViT是一种基于Transformers的轻量级模型,它可以用于图像分类任务。相比于传统的卷积神经网络,MobileViT使用了轻量级的注意力机制来提取特征,从而在保证较高精度的同时,具有更快的推理速度和更小的模型体积。它在移动设备上的应用具有很大的潜力。

自从2020年 ViT 网络被提出并取得和传统 CNN 网络差别不大的性能表现之后,越来越多的研究者开始探究 Transformer 架构在计算机视觉领域的