-
const限定符
-
有时我们希望定义这样一种变量,它的值不能被改变。例如,用一个变量来表示缓冲区的大小。使用变量的好处是当我们觉得缓冲区大小不再合适时,很容易对其进行调整。另一方面,也应随时警惕防止程序一不小心改变了这个值。为了满足这一要求,可以用关键字const对变量的类型加以限定:
-
const int bufSize = 512; //输入缓冲区大小 -
这样就把bufSize定义成了一个常量。任何试图为bufSize赋值的行为都将引发错误。因为const对象一旦创建后其值就不能再改变,所以const对象必须初始化。一如既往,初始值可以是任意复杂的表达式:
-
const int i = get_size(); //正确,运行时候初始化 const int j = 2023; //正确,编译时初始化 const int k; //错误,k是一个的常量
-
-
正如之前反复提到的,对象的类型决定了其上的操作。与非 const类型所能参与的操作相比,const类型的对象能完成其中大部分,但也不是所有的操作都适合。主要的限制就是只能在const类型的对象上执行不改变其内容的操作。例如,const int和普通的int一样都能参与算术运算,也都能转换成一个布尔值,等等。在不改变const对象的操作中还有一种是初始化,如果利用一个对象去初始化另外一个对象,则它们是不是const都无关紧要:
-
int i = 2023; const int ci = i; //正确,i的值被拷贝给了ci int j = ci; //正确,ci的值被拷贝给了j -
尽管ci是整型常量,但无论如何ci中的值还是一个整型数。ci的常量特征仅仅在执行改变ci的操作时才会发挥作用。当用ci去初始化j时,根本无须在意ci是不是一个常量。拷贝一个对象的值并不会改变它,一旦拷贝完成,新的对象就和原来的对象没什么关系了。
-
-
编译器将在编译过程中把用到该变量的地方都替换成对应的值。也就是说,编译器会找到代码中所有用到bufsize的地方,然后用512替换。
-
为了执行上述替换,编译器必须知道变量的初始值。如果程序包含多个文件,则每个用了const对象的文件都必须得能访问到它的初始值才行。要做到这一点,就必须在每一个用到变量的文件中都有对它的定义。为了支持这一用法,同时避免对同一变量的重复定义,默认情况下,const对象被设定为仅在文件内有效。当多个文件中出现了同名的const变量时,其实等同于在不同文件中分别定义了独立的变量。
-
某些时候有这样一种 const变量,它的初始值不是一个常量表达式,但又确实有必要在文件间共享。这种情况下,我们不希望编译器为每个文件分别生成独立的变量。相反,我们想让这类const对象像其他(非常量)对象一样工作,也就是说,只在一个文件中定义const,而在其他多个文件中声明并使用它。解决的办法是,对于 const变量不管是声明还是定义都添加 extern关键字,这样只需定义一次就可以了:
-
//file1.cc定义初始化了一个常量,该常量能被其他文件访问 extern const int bufSize = fcn(); //file1.h extern const int bufSize;//与file1.cc定义的bufSize是同一个 -
如上述程序所示,file1.cc定义并初始化了bufsize。因为这条语句包含了初始值,所以它(显然)是一次定义。然而,因为bufsize是一个常量,必须用extern加以限定使其被其他文件使用。file1.h头文件中的声明也由extern做了限定,其作用是指明bufsize并非本文件所独有,它的定义将在别处出现。
-
-
const的引用
-
可以把引用绑定到const对象上,就像绑定到其他对象上一样,我们称之为对常量的引用(reference to const)。与普通引用不同的是,对常量的引用不能被用作修改它所绑定的对象:
-
const int ci = 2023; const int &r1 = ci; //正确,引用及其对应的对象都是变量 r1 = 2021; //错误,r1是对常量的引用 int &r2 = ci; //错误,试图让一个非常量引用指向一个常量对象 -
因为不允许直接为ci赋值,当然也就不能通过引用去改变ci。因此,对r2的初始化是错误的。假设该初始化合法,则可以通过r2来改变它引用对象的值,这显然是不正确的。
-
-
C++程序员们经常把词组“对 const 的引用”简称为“常量引用”,这一简称还是挺靠谱的,不过前提是你得时刻记得这就是个简称而已。严格来说,并不存在常量引用。因为引用不是一个对象,所以我们没法让引用本身恒定不变。事实上,由于C++语言并不允许随意改变引用所绑定的对象,所以从这层意义上理解所有的引用又都算是常量。引用的对象是常量还是非常量可以决定其所能参与的操作,却无论如何都不会影响到引用和对象的绑定关系本身。
-
引用的类型必须与其所引用对象的类型一致,但是有两个例外。第一种例外情况就是在初始化常量引用时允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可。尤其,允许为一个常量引用绑定非常量的对象、字面值,甚至是个一般表达式:
-
int i = 2023; const int &r1 = i;//允许const int&绑定到一个普通int对象上 const int &r2 = 2021;//正确,r2是一个常量引用 const int &r3 = r1*2;//正确,r3是一个常量引用 int &4 =r1*2;错误,r4是一个非常量引用
-
-
对const 的引用可能引用一个并非const的对象,必须认识到,常量引用仅对引用可参与的操作做出了限定,对于引用的对象本身是不是一个常量未作限定。因为对象也可能是个非常量,所以允许通过其他途径改变它的值:
-
int i =2023; int &r1 = i;//引用ri绑定对象i const int &r2 = i;//r2绑定对象i,但不允许通过r2修改i r1 = 0;//r1并非常量,i值被修改为0 //错误 r2 = 0; -
r2绑定(非常量)整数i是合法的行为。然而,不允许通过r2修改i的值。尽管如此,i的值仍然允许通过其他途径修改,既可以直接给i赋值,也可以通过像r1一样绑定到i的其他引用来修改。
-
-
指针和const:与引用一样,也可以令指针指向常量或非常量。类似于常量引用,指向常量的指针(pointer to const)不能用于改变其所指对象的值。要想存放常量对象的地址,只能使用指向常量的指针:
-
const double pi =3.14 double *ptr = π//错误,ptr是一个普通指针 const double *cptr =π//正确,类型相同 *cptr=2021;//错误,不能给它赋值 -
指针的类型必须与其所指对象的类型一致,但是有两个例外。第一种例外情况是允许令一个指向常量的指针指向一个非常量对象:
-
double val = 3.14; cptr = &val -
和常量引用一样,指向常量的指针也没有规定其所指的对象必须是一个常量。所谓指向常量的指针仅仅要求不能通过该指针改变对象的值,而没有规定那个对象的值不能通过其他途径改变。试试这样想吧:所谓指向常量的指针或引用,不过是指针或引用“自以为是”罢了,它们觉得自己指向了常量,所以自觉地不去改变所指对象的值。
-
-
指针是对象而引用不是,因此就像其他对象类型一样,允许把指针本身定为常量。常量指针(const pointer)必须初始化,而且一旦初始化完成,则它的值(也就是存放在指针中的那个地址)就不能再改变了。把*放在const关键字之前用以说明指针是一个常量,这样的书写形式隐含着一层意味,即不变的是指针本身的值而非指向的那个值:
-
int myNum=0; int *const currErr = &myNum;//curErr将一直指向myNum const double pi = 3.14; const double *const pip = π//pip是一个指向常量对象的常量指针 -
要想弄清楚这些声明的含义最行之有效的办法是从右向左阅读。此例中,离curErr最近的符号是const,意味着curErr本身是一个常量对象,对象的类型由声明符的其余部分确定。声明符中的下一个符号是*,意思是curErr是一个常量指针。最后,该声明语句的基本数据类型部分确定了常量指针指向的是一个int对象。与之相似,我们也能推断出,pip是一个常量指针,它指向的对象是一个双精度浮点型常量。
-
指针本身是一个常量并不意味着不能通过指针修改其所指对象的值,能否这样做完全依赖于所指对象的类型。例如,pip是一个指向常量的常量指针,则不论是 pip所指的对象值还是pip自己存储的那个地址都不能改变。相反的,curErr指向的是一个一般的非常量整数,那么就完全可以用curErr去修改errNumb 的值:
-
*pip = 2.72;//错误,pip是一个指向常量的指针 //如果curErr所指向的对象也就是myNum的值不为0 if(*curErr) { errorHandler(); *curErr = 0;//正确,把curErr所指向的对象重置 }
-
-
顶层const
-
如前所述,指针本身是一个对象,它又可以指向另外一个对象。因此,指针本身是不是常量以及指针所指的是不是一个常量就是两个相互独立的问题。用名词顶层const( top-level const)表示指针本身是个常量,而用名词底层const (low-level const)表示指针所指的对象是一个常量。
-
更一般的,顶层const可以表示任意的对象是常量,这一点对任何数据类型都适用,如算术类型、类、指针等。底层const则与指针和引用等复合类型的基本类型部分有关。比较特殊的是,指针类型既可以是顶层const也可以是底层const,这一点和其他类型相比区别明显:
-
int i = 0; int *const p1 = &i;//不能改变p1的值,这是一个顶层const const int ci = 2023;//不能改变ci的值,这是一个顶层const const int *p2 = &ci;能改变p2的值,这是一个底层const const int *const p3=p2;//靠右的const是顶层const,靠左的是一个底层const const int &r=ci;//用于声明引用的const都是底层const -
当执行对象的拷贝操作时,常量是顶层const还是底层const区别明显。其中,顶层const不受什么影响:
-
i = ci;//正确,拷贝ci的值。ci是顶层,对此无影响 p2=p3;//正确,p2和p3指向的对象类型相同,p3顶层const的部分不影响 -
执行拷贝操作并不会改变被拷贝对象的值,因此,拷入和拷出的对象是否是常量都没什么影响。另一方面,底层 const 的限制却不能忽视。当执行对象的拷贝操作时,拷入和拷出的对象必须具有相同的底层 const资格,或者两个对象的数据类型必须能够转换。一般来说,非常量可以转换成常量,反之则不行:
-
int *p=p3;//错误,p3包含底层const的定义,而p没有 p2=p3;//正确,都是底层const p2=&i;//正确int*可转为const int* int &r=ci;//错,普通int&不能绑定到int常量 const int &r2=i;//对,const int&可以绑定在一个普通int上 -
p3既是顶层const也是底层const,拷贝p3时可以不在乎它是一个顶层const,但是必须清楚它指向的对象得是一个常量。因此,不能用p3去初始化p,因为p指向的是一个普通的(非常量)整数。另一方面,p3的值可以赋给p2,是因为这两个指针都是底层const,尽管p3同时也是一个常量指针(顶层 const),仅就这次赋值而言不会有什么影响。
-
-
constexpr和常量表达式
-
常量表达式(const expression)是指值不会改变并且在编译过程就能得到计算结果的表达式。显然,字面值属于常量表达式,用常量表达式初始化的const对象也是常量表达式。后面将会提到,C++语言中有几种情况下是要用到常量表达式的。一个对象(或表达式)是不是常量表达式由它的数据类型和初始值共同决定,例如:
-
const int max_files = 20;常量表达式 const int limit = max_files+1;//常量表达式 int staff_size=27;//不是常量表达式 const int sz =get_size();//不是常量表达式 -
尽管staff_size的初始值是个字面值常量,但由于它的数据类型只是一个普通int而非const int,所以它不属于常量表达式。另一方面,尽管sz本身是一个常量,但它的具体值直到运行时才能获取到,所以也不是常量表达式。
-
-
在一个复杂系统中,很难(几乎肯定不能)分辨一个初始值到底是不是常量表达式。当然可以定义一个const变量并把它的初始值设为我们认为的某个常量表达式,但在实际使用时,尽管要求如此却常常发现初始值并非常量表达式的情况。可以这么说,在此种情况下,对象的定义和使用根本就是两回事儿。
-
C++11新标准规定,允许将变量声明为constexpr类型以便由编译器来验证变量的值是否是一个常量表达式。声明为constexpr的变量一定是一个常量,而且必须用常量表达式初始化:
-
尽管不能使用普通函数作为constexpr变量的初始值,但是新标准允许定义一种特殊的constexpr函数。这种函数应该足够简单以使得编译时就可以计算其结果,这样就能用constexpr函数去初始化constexpr变量了。一般来说,如果你认定变量是一个常量表达式,那就把它声明成constexpr类型。
-
常量表达式的值需要在编译时就得到计算,因此对声明constexpr时用到的类型必须有所限制。因为这些类型一般比较简单,值也显而易见、容易得到,就把它们称为“字面值类型”( literal type)。到目前为止接触过的数据类型中,算术类型、引用和指针都属于字面值类型。自定义类Sales_ item、 IO库、string 类型则不属于字面值类型,也就不能被定义成constexpr。尽管指针和引用都能定义成constexpr,但它们的初始值却受到严格限制。一个constexpr指针的初始值必须是nullptr或者0,或者是存储于某个固定地址中的对象。
-
函数体内定义的变量一般来说并非存放在固定地址中,因此constexpr指针不能指向这样的变量。相反的,定义于所有函数体之外的对象其地址固定不变,能用来初始化 constexpr指针。允许函数定义一类有效范围超出函数本身的变量,这类变量和定义在函数体之外的变量一样也有固定地址。因此,constexpr引用能绑定到这样的变量上,constexpr指针也能指向这样的变量。
-
指针和constexpr
-
必须明确一点,在constexpr声明中如果定义了一个指针,限定符constexpr仅对指针有效,与指针所指的对象无关:
-
const int *p=nullptr;//p是一个指向整形常量的指针 constexpr int *q = nullptr;//q是一个指向整数的常量指针
-
-
p和q的类型相差甚远,p是一个指向常量的指针,而q是一个常量指针,其中的关键在于constexpr把它所定义的对象置为了顶层const。与其他常量指针类似,constexpr指针既可以指向常量也可以指向一个非常量:
-

-
-
处理类型
-
随着程序越来越复杂,程序中用到的类型也越来越复杂,这种复杂性体现在两个方面。一是一些类型难于“拼写”,它们的名字既难记又容易写错,还无法明确体现其真实目的和含义。二是有时候根本搞不清到底需要的类型是什么,程序员不得不回过头去从程序的上下文中寻求帮助。有两种方法可用于定义类型别名。传统的方法是使用关键字typedef:
-
typedef double wages; //wages是double的同义词 typedef wages base,*p;//base是double同义词,p是double*的同义词 -
其中,关键字typedef作为声明语句中的基本数据类型的一部分出现。含有typedef的声明语句定义的不再是变量而是类型别名。和以前的声明语句一样,这里的声明符也可以包含类型修饰,从而也能由基本数据类型构造出复合类型来。
-
新标准规定了一种新的方法,使用别名声明(alias declaration)来定义类型的别名:
-
using si = Sales_item//si是Sales_item的同义词 -
这种方法用关键字using 作为别名声明的开始,其后紧跟别名和等号,其作用是把等号左侧的名字规定成等号右侧类型的别名。类型别名和类型的名字等价,只要是类型的名字能出现的地方,就能使用类型别名:
-
wages hourly,weekly;//等价于double hourly,weekly; si item;//等价于Sales_item item;
-
-
指针、常量和类型别名
-
如果某个类型别名指代的是复合类型或常量,那么把它用到声明语句里就会产生意想不到的后果。例如下面的声明语句用到了类型pstring,它实际上是类型char*的别名:
-
typedef char *pstring; const pstring cstr=0;//cstr是指向char的常量 const pstring *ps;//ps是一个指针。它的对象是指向char的常量指针 -
上述两条声明语句的基本数据类型都是const pstring,和过去一样,const是对给定类型的修饰。pstring 实际上是指向char的指针,因此,const pstring 就是指向char的常量指针,而非指向常量字符的指针。遇到一条使用了类型别名的声明语句时,人们往往会错误地尝试把类型别名替换成它本来的样子,以理解该语句的含义。
-
声明语句中用到pstring时,其基本数据类型是指针。可是用char*重写了声明语句后,数据类型就变成了char,*成为了声明符的一部分。这样改写的结果是,const char成了基本数据类型。前后两种声明含义截然不同,前者声明了一个指向char的常量指针,改写后的形式则声明了一个指向const char的指针。
-
-
auto类型说明符
-
编程时常常需要把表达式的值赋给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而要做到这一点并非那么容易,有时甚至根本做不到。为了解决这个问题,C++11新标准引入了auto类型说明符,用它就能让编译器替我们去分析表达式所属的类型。和原来那些只对应一种特定类型的说明符(比如 double)不同,auto让编译器通过初始值来推算变量的类型。显然,auto定义的变量必须有初始值:
-
//由val1和val2相加的结果可以判断出item的类型 auto item =val1+val2;//item初始化为val1和val2相加的结果 -
此处编译器将根据val1和 val2相加的结果来推断item的类型。如果val1和val2是类sales_item的对象,则item 的类型就是sales_item;如果这两个变量的类型是double,则item的类型就是double,以此类推。使用auto也能在一条语句中声明多个变量。因为一条声明语句只能有一个基本数据类型,所以该语句中所有变量的初始基本数据类型都必须一样:
-
auto i=0,*p=&i;//正确,i是整数,p是整形指针 auto sz=0,pi=3.14;//错误,sz和pi的类型不一致
-
-
复合类型、常量和 auto
-
编译器推断出来的auto类型有时候和初始值的类型并不完全一样,编译器会适当地改变结果类型使其更符合初始化规则。首先,正如我们所熟知的,使用引用其实是使用引用的对象,特别是当引用被用作初始值时,真正参与初始化的其实是引用对象的值。此时编译器以引用对象的类型作为 auto的类型:
-
int i=0,&r=i; auto a=r;//a是一个整数(r是i的别名,而i是一个整数) -
其次,auto一般会忽略掉顶层const,同时底层const则会保留下来,比如当初始值是一个指向常量的指针时:
-

-
如果希望推断出的auto类型是一个顶层const,需要明确指出:
-
const auto f=ci;//ci的推演类型为int,f是const int -
还可以将引用的类型设为auto,此时原来的初始化规则仍然适用:
-
auto &g=ci;//g是一个整型常量引用,绑定ci auto &h=2023;//错误,不能为非常量引用绑定字面量 const auto &j=2023;//正确,可以为常量引用绑定字面量 -
设置一个类型为auto的引用时,初始值中的顶层常量属性仍然保留。和往常一样,如果我们给初始值绑定一个引用,则此时的常量就不是顶层常量了。要在一条语句中定义多个变量,切记,符号&和*只从属于某个声明符,而非基本数据类型的一部分,因此初始值必须是同一种类型:
-
auto k=ci,&l=i;//k整型。l整型引用 auto &m=ci,*p=&ci;//m是对整型常量的引用,p是指向整型常量的指针 //错误,,i的类型是int,而&ci的类型是const int auto &n=i,*pi=&ci;
-
-
decltype类型指示符
-
有时会遇到这种情况:希望从表达式的类型推断出要定义的变量的类型,但是不想用该表达式的值初始化变量。为了满足这一要求,C++11 新标准引入了第二种类型说明符decltype,它的作用是选择并返回操作数的数据类型。在此过程中,编译器分析表达式并得到它的类型,却不实际计算表达式的值:
-
decltype(f()) sum =x;//sum的类型是函数f的返回类型 -
编译器并不实际调用函数f,而是使用当调用发生时f的返回值类型作为sum的类型。换句话说,编译器为sum 指定的类型是什么呢?就是假如f被调用的话将会返回的那个类型。decltype 处理顶层const和引用的方式与auto有些许不同。如果 decltype使用的表达式是一个变量,则decltype返回该变量的类型(包括顶层const和引用在内):
-
const int ci=0,&cj=ci; decltype(ci) x=0;//x的类型是const int decltype(cj) y=x;//y的类型是const int&,y绑定到变量x decltype(cj) z;//错误,z为一个引用,所以必须初始化 -
因为cj是一个引用,decltype( cj)的结果就是引用类型,因此作为引用的z必须被初始化。需要指出的是,引用从来都作为其所指对象的同义词出现,只有用在 decltype 处是一个例外。
-
-
decltype和引用
-
如果 decltype 使用的表达式不是一个变量,则decltype返回表达式结果对应的类型。有些表达式将向decltype返回一个引用类型。一般来说当这种情况发生时,意味着该表达式的结果对象能作为一条赋值语句的左值:
-
//decltype的结果可以是引用类型 int i=2023,*p=&i,&r=i; decltype(r+0) b;//正确。加法的结果是int,因此b是一个未初始化的int decltype(*p) c;//错误,c是int&,需要初始化 -
因为r是一个引用,因此 decltype ®的结果是引用类型。如果想让结果类型是r所指的类型,可以把r作为表达式的一部分,如r+0,显然这个表达式的结果将是一个具体值而非一个引用。另一方面,如果表达式的内容是解引用操作,则 decltype 将得到引用类型。正如我们所熟悉的那样,*解引用指针可以得到指针所指的对象,而且还能给这个对象赋值。因此,decltype (p)的结果类型就是int&,而非int。
-
decltype和 auto的另一处重要区别是,decltype的结果类型与表达式形式密切相关。有一种情况需要特别注意:对于 decltype 所用的表达式来说,如果变量名加上了一对括号,则得到的类型与不加括号时会有不同。如果 decltype 使用的是一个不加括号的变量,则得到的结果就是该变量的类型;如果给变量加上了一层或多层括号,编译器就会把它当成是一个表达式。变量是一种可以作为赋值语句左值的特殊表达式,所以这样的decltype就会得到引用类型:
-
//decltype的表达式如果加上了括号的变量,结果僵尸引用 decltype((i)) d;//错误,d是int&,必须初始化 decltype(i) e;//正确,e是一个未初始化 -
切记:decltype((variable))(注意是双层括号)的结果永远是引用,而decltype(variable)结果只有当variable本身就是一个引用时才是引用。
-
-
自定义数据结构
- 从最基本的层面理解,数据结构是把一组相关的数据元素组织起来然后使用它们的策略和方法。举一个例子,我们的sales_item类把书本的ISBN编号、售出量及销售收入等数据组织在了一起,并且提供诸如 isbn函数、>>、<<、+、+=等运算在内的一系列操作,sales_item类就是一个数据结构。C++语言允许用户以类的形式自定义数据类型,而库类型string、istream、ostream等也都是以类的形式定义的。C++语言对类的支持甚多。
-
定义Sales_data类型
-
尽管我们还写不出完整的sales_item类,但是可以尝试着把那些数据元素组织到一起形成一个简单点儿的类。初步的想法是用户能直接访问其中的数据元素,也能实现一些基本的操作。既然我们筹划的这个数据结构不带有任何运算功能,不妨把它命名为 sales_data以示与sales_item 的区别。Sales_data初步定义如下:
-
struct Sales_data { std::string bookNo; unsigned units_sold=0; double revenue=0.0; }; -
我们的类以关键字struct开始,紧跟着类名和类体(其中类体部分可以为空)。类体由花括号包围形成了一个新的作用域。类内部定义的名字必须唯一,但是可以与类外部定义的名字重复。类体右侧的表示结束的花括号后必须写一个分号,这是因为类体后面可以紧跟变量名以示对该类型对象的定义,所以分号必不可少:
-
struct Sales_data{...}; Sales_data accum,*salesptr; -
分号表示声明符(通常为空)的结束。一般来说,最好不要把对象的定义和类的定义放在一起。这么做无异于把两种不同实体的定义混在了一条语句里,一会儿定义类,一会儿又定义变量,显然这是一种不被建议的行为。
-
类体定义类的成员,我们的类只有数据成员(( data member)。类的数据成员定义了类的对象的具体内容,每个对象有自己的一份数据成员拷贝。修改一个对象的数据成员,不会影响其他sales_data的对象。
-
定义数据成员的方法和定义普通变量一样:首先说明一个基本类型,随后紧跟一个或多个声明符。我们的类有3个数据成员:一个名为bookNo的 string成员、一个名为units_sold 的unsigned成员和一个名为revenue 的 double 成员。每个Sales_data的对象都将包括这3个数据成员。
-
C++11新标准规定,可以为数据成员提供一个类内初始值(in-class initializer)。创建对象时,类内初始值将用于初始化数据成员。没有初始值的成员将被默认初始化。因此当定义sales_data的对象时,units_sold和revenue都将初始化为0,bookNo将初始化为空字符串。对类内初始值的限制与之前介绍的类似:或者放在花括号里,或者放在等号右边,记住不能使用圆括号。用户可以使用C++语言提供的另外一个关键字class来定义自己的数据结构,到时也将说明现在我们使用struct的原因。
-
-
使用Sales_data类
- 和 sales_item类不同的是,我们自定义的sales_data类没有提供任何操作,sales_data类的使用者如果想执行什么操作就必须自己动手实现。例如,写一段程序实现求两次交易相加结果的功能。每笔交易记录着图书的ISBN编号、售出数量和售出单价。
-
添加两个Sales_data对象
-
因为sales_data类没有提供任何操作,所以我们必须自己编码实现输入、输出和相加的功能。假设已知sales_data类定义于sales_data.h文件内。
-
#include <iostream> #include <string> #include "Sales_data.h" int main() { Sales_data data1,data2; //方法 } -
和原来的程序一样,先把所需的头文件包含进来并且定义变量用于接受输入。和sales_item类不同的是,新程序还包含了string头文件,因为我们的代码中将用到string类型的成员变量bookNo。
-
-
Sales_data对象读入数据
-
在此之前,我们先了解一点儿关于string 的知识以便定义和使用我们的ISBN成员。string类型其实就是字符的序列,它的操作有>>、<<和==等,功能分别是读入字符串、写出字符串和比较字符串。这样我们就能书写代码读入第一笔交易了:
-
struct Sales_data { std::string bookNo; unsigned units_sold = 0; double revenue = 0.0; }; Sales_data data1, data2; double price = 0; //读入第一笔交易:ISBN,销售数量,单价 std::cin >> data1.bookNo >> data1.units_sold >> price; //计算销售额 data1.revenue = data1.units_sold * price; //读入第二笔交易:ISBN,销售数量,单价 std::cin >> data2.bookNo >> data2.units_sold >> price; //计算销售额 data2.revenue = data2.units_sold * price; -
交易信息记录的是书售出的单价,而数据结构存储的是一次交易的销售收入,因此需要将单价读入到double变量price,然后再计算销售收入revenue。最后一条语句把data1.units_sold和price的乘积赋值给data1的revenue成员。
-
-
输出两个Sales_data对象的和
-
剩下的工作就是检查两笔交易涉及的工SBN编号是否相同了。如果相同输出它们的和,否则输出一条报错信息:
-
if (data1.bookNo == data2.bookNo) { unsigned totalCnt = data1.units_sold + data2.units_sold; double totalRev = data1.revenue + data2.revenue; std::cout << data1.bookNo << "\t" << totalCnt << "\t" << totalRev; if (totalCnt != 0) { std::cout << totalRev / totalCnt << std::endl; } else { std::cout << "这个书本没有卖出数据" << std::endl; } return 0; } else { std::cerr << "键入两次交易的书本ISBN号不一致" << std::endl; return -1; }- 在第一个if语句中比较了data1和 data2的 bookNo成员是否相同。如果相同则执行第一个if语句花括号内的操作,首先计算units_sold的和并赋给变量totalCnt,然后计算revenue的和并赋给变量totalRevenue,输出这些值。接下来检查是否确实售出了书籍,如果是,计算并输出每本书的平均价格;如果售量为零,输出一条相应的信息。
-

-
-
编写自己的头文件
-
类一般都不定义在函数体内。当在函数体外部定义类时,在各个指定的源文件中可能只有一处该类的定义。而且,如果要在不同文件中使用同一个类,类的定义就必须保持一致。
-
为了确保各个文件中类的定义一致,类通常被定义在头文件中,而且类所在头文件的名字应与类的名字一样。例如,库类型string在名为string 的头文件中定义。又如,我们应该把sales_data类定义在名为sales_data.h的头文件中。
-
头文件通常包含那些只能被定义一次的实体,如类、const和 constexpr变量等。头文件也经常用到其他头文件的功能。例如,我们的sales_data类包含有一个string成员,所以sales_data.h必须包含string.h头文件。同时,使用sales_data类的程序为了能操作bookNo成员需要再一次包含string.h头文件。这样,事实上使用sales_data类的程序就先后两次包含了string.h头文件:一次是直接包含的,另有一次是随着包含sales_data.h被隐式地包含进来的。有必要在书写头文件时做适当处理,使其遇到多次包含的情况也能安全和正常地工作。
-
-
头文件一旦改变,相关的源文件必须重新编译以获取更新过的声明。
-
确保头文件多次包含仍能安全工作的常用技术是预处理器(preprocessor),它由C++语言从C语言继承而来。预处理器是在编译之前执行的一段程序,可以部分地改变我们所写的程序。之前已经用到了一项预处理功能#include,当预处理器看到#include标记时就会用指定的头文件的内容代替#include。
-
C++程序还会用到的一项预处理功能是头文件保护符(header guard),头文件保护符依赖于预处理变量。预处理变量有两种状态:已定义和未定义。#define 指令把一个名字设定为预处理变量,另外两个指令则分别检查某个指定的预处理变量是否已经定义:#ifdef 当且仅当变量已定义时为真,#ifndef当且仅当变量未定义时为真。一旦检查结果为真,则执行后续操作直至遇到#endif指令为止。使用这些功能就能有效地防止重复包含的发生:
-
第一次包含sales_data.h时,#ifndef的检查结果为真,预处理器将顺序执行后面的操作直至遇到#endif为止。此时,预处理变量 SALES_DATA_H的值将变为已定义,而且sales_data.h也会被拷贝到我们的程序中来。后面如果再一次包含sales_data.h,则#ifndef的检查结果将为假,编译器将忽略#ifndef到#endif之间的部分。
-
预处理变量无视C++语言中关于作用域的规则。
-
整个程序中的预处理变量包括头文件保护符必须唯一,通常的做法是基于头文件中类的名字来构建保护符的名字,以确保其唯一性。为了避免与程序中的其他实体发生名字冲突,一般把预处理变量的名字全部大写。
-
头文件即使没有被包含在任何其他头文件中,也应该设置保护符。头文件保护符很简单,程序员只要习惯性地加上就可以了,没必要太在乎你的程序到底需不需要。
-
类型是C++编程的基础。
- 类型规定了其对象的存储要求和所能执行的操作。C++语言提供了一套基础内置类型,如int和char等,这些类型与实现它们的机器硬件密切相关。类型分为非常量和常量,一个常量对象必须初始化,而且一旦初始化其值就不能再改变。此外,还可以定义复合类型,如指针和引用等。复合类型的定义以其他类型为基础。
-
C++语言允许用户以类的形式自定义类型。C++库通过类提供了一套高级抽象类型,如输入输出和string等。
-

c++基础概念,const与指针、引用的关系,auto,decltype关键字能干啥总得了解吧。总得按照需求自定义创建实体类,自己编写头文件吧
news2026/2/12 11:26:38


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/575633.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
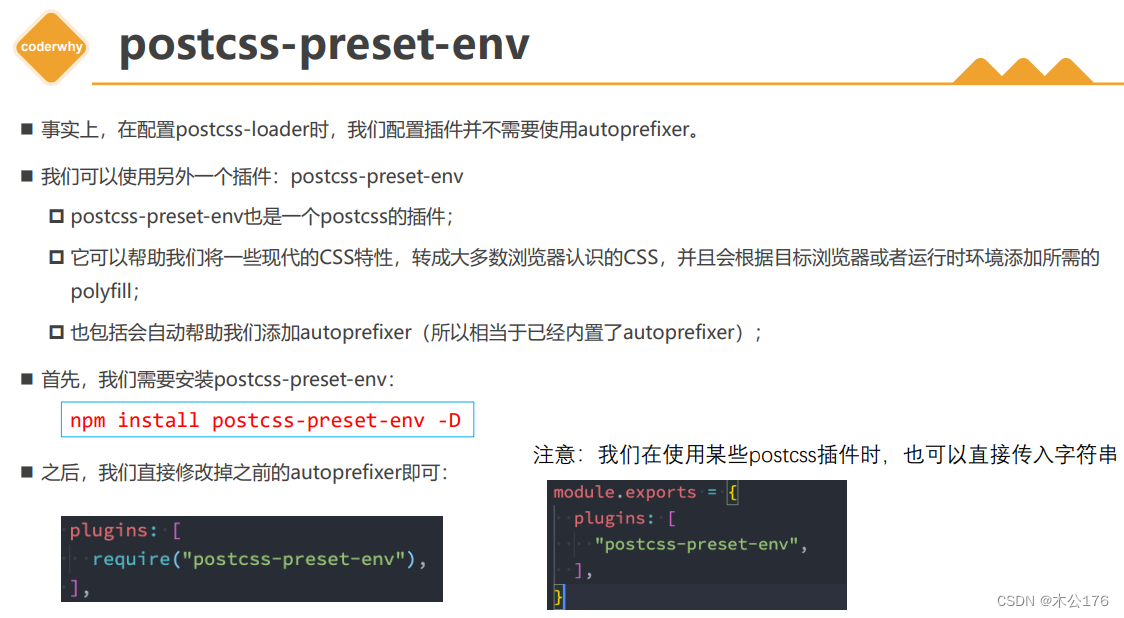
邂逅Webpack和打包过程
1 认识webpack工具
2 webpack基本打包
3 webpack配置文件
4 编写和打包CSS文件
5 编写和打包LESS文件
6 postcss工具处理CSS 从脚手架打包成普通的htmlcssjs文件 内置模块path: 拼接路径 const path require("path")const filepath "C://abc/…
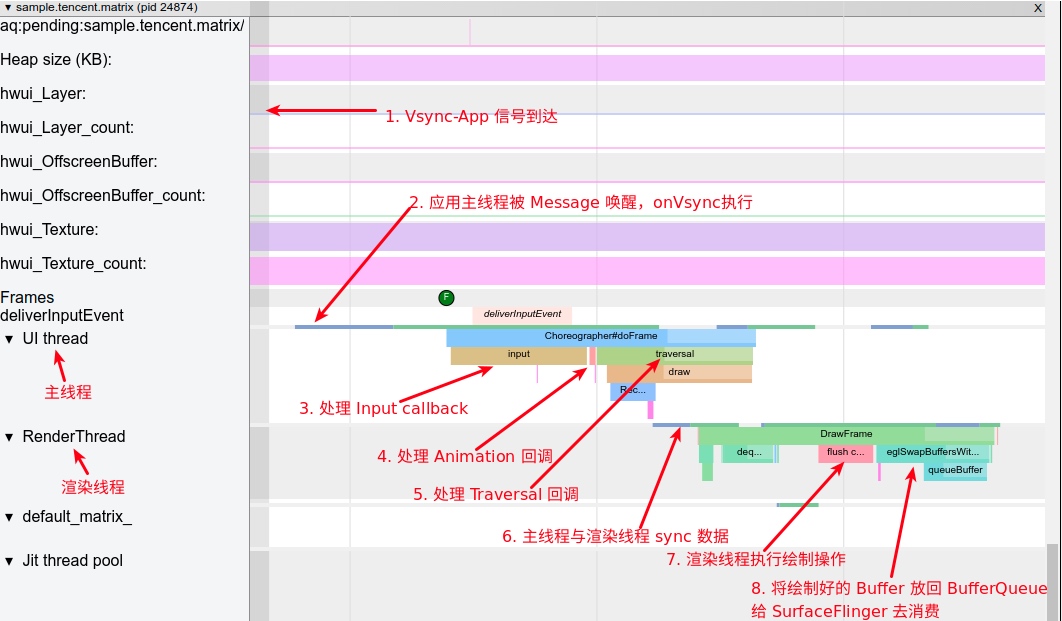
Systrace系列9 —— MainThread 和 RenderThread 解读
本文是介绍 Android App 中的 MainThread 和 RenderThread,也就是大家熟悉的主线程和渲染线程。文章会从 Systrace 的角度来看 MainThread 和 RenderThread 的工作流程,以及涉及到的相关知识:卡顿、软件渲染、掉帧计算等。 这里以滑动列表为例 ,我们截取主线程和渲染线程一…
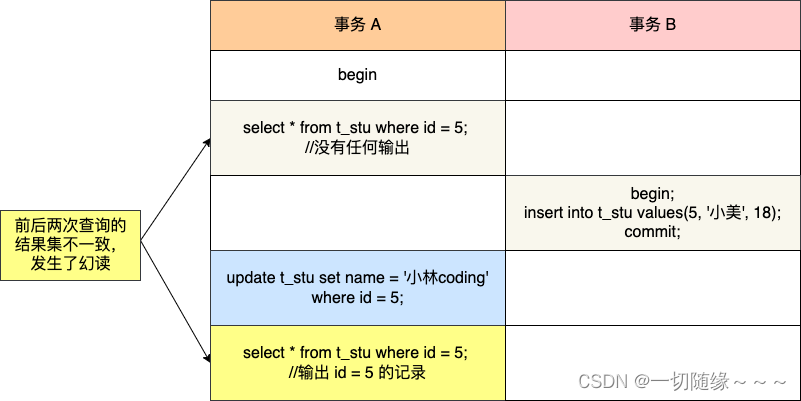
InnoDB 在可重复读 RR 隔离级别下,能解决幻读问题吗?
InnoDB 在可重复读 RR 隔离级别下,能解决幻读问题吗? MySQL 在「可重复读」隔离级别下,可以很大程度上避免幻读现象的发生(注意是很大程度避免,并不是彻底避免),所以 MySQL 并不会使用「串行化」…
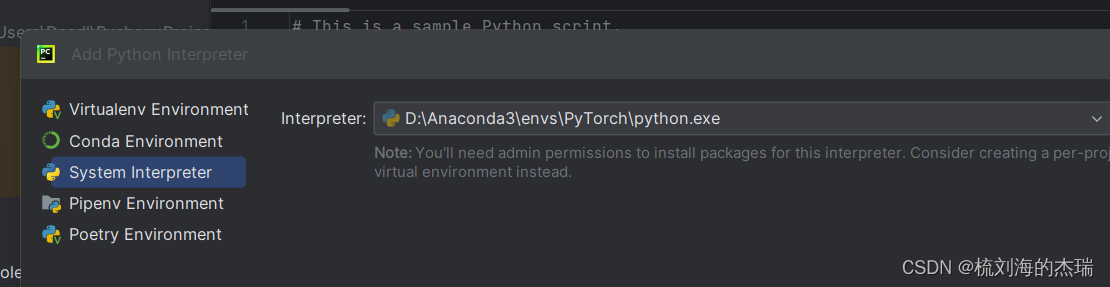
Pycharm中配置不了conda解释器
我安装的是pytorch的CPU版本,在Pycharm中配置conda环境时,每次添加完都不显示,搜遍了很多方法都没用。最后成功解决,这里将一些方法进行总结,方便大家解决问题。
我的情况和解决
问题情况以及显示
1.在Pycharm的日志…
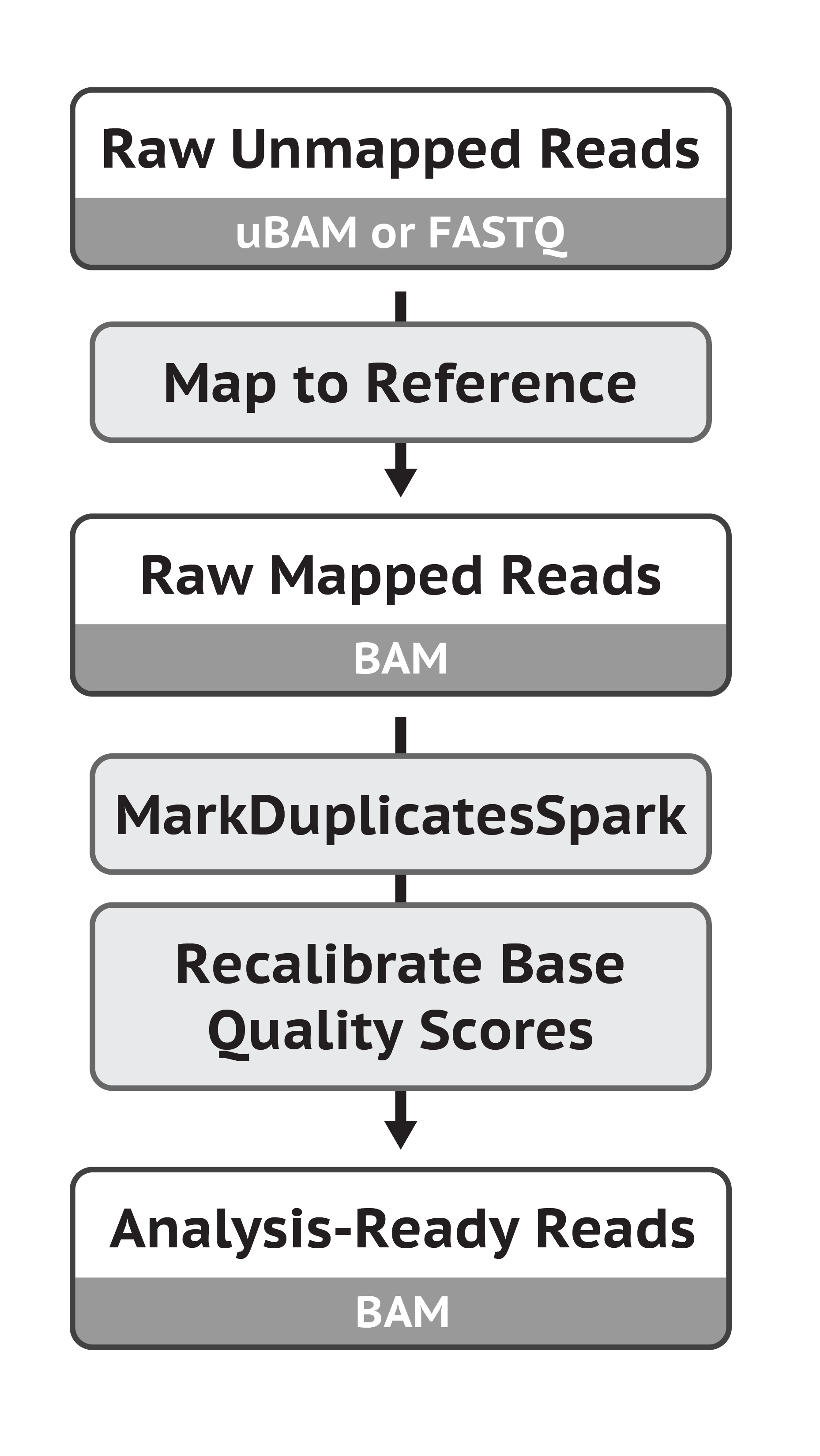
GATK最佳实践之数据预处理SnakeMake流程
<~生~信~交~流~与~合~作~请~关~注~公~众~号生信探索> 写的数据预处理snakemake流程其实包括在每个单独的分析中比如种系遗传变异和肿瘤变异流程中,这里单独拿出来做演示用,因为数据预处理是通用的,在call变异之前需要处理好数据。 数据…
Java中如何使用策略模式减少 if / else 分支的使用
目录
1、策略模式
1.1 、策略模式包含三个角色:
2、需求
2.1 、传统方式
2.2 、策略模式实现
2.2.1 、新建PolicyPatternController.java
2.2.2 、Express.java(实体类)
2.2.3 、定义一个接口:PolicyPatternService.java
2.2.4 、定义3个实现类…
Python根据经纬度在地图上显示(folium)
Python根据经纬度在地图上显示(folium) 一、folium介绍1.folium.Map参数简要介绍2.folium.Marker参数介绍 二、Python根据经纬度在地图上显示(示例)1.经纬度坐标标记2.经纬度坐标分组标记 一、folium介绍
1.folium.Map参数简要介…

URLConnection(五)
文章目录 1. 断开与服务器的连接2. 处理服务器响应3. 错误条件4. 重定向5. 代理6. 流模式 1. 断开与服务器的连接
HTTP1.1 支持持久连接,允许通过一个TCP socket发送多个请求和响应。不过使用Keep-Alive时,服务器不会因为已经向客户端发送了最后一个字节…

chatgpt赋能python:使用Python操作股票软件:探索股票市场的新方式
使用Python操作股票软件:探索股票市场的新方式
在当今股票市场中,许多投资者正在寻找新的方式来更好地管理其投资组合。一种新的方式是使用Python编程语言操作股票软件。Python拥有简洁的语法和丰富的库来帮助投资者更好地理解和管理股票。在本文中&…

挂耳式耳机哪个牌子好?这次推荐准没错!
在校园里,上网课、复习考证、刷视频……耳机总是我的第一选择,既不会打扰别人又能有效学习,普通的入耳式耳机戴久了总是会耳道痛,甚至出现耳道发炎问题,耳机也总是很难清洁。但是生活中我又离不开耳机,所以…

【源码解析】分库分表框架 Shardingsphere 源码解析
前言
以前研究过如何使用ShardingJdbc,使用ShardingJdbc进行分库分表,但是原理方面没有细致的深入了解。如果仅仅了解如何使用的话,对于改造和排查问题,其实都是不够的,所以跟踪源码了解其运行原理是很重要的。
Demo…
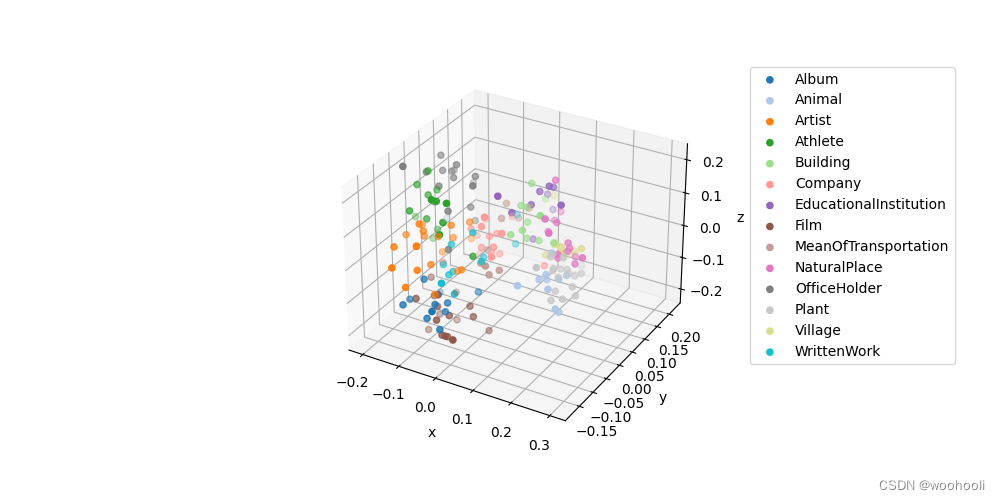
GPT学习笔记-Embedding的降维与2D,3D可视化
嵌入(Embedding)在机器学习和自然语言处理中是一种表示离散变量(如单词、句子或整个文档)的方式,通常是作为高维向量或者矩阵。嵌入的目标是捕捉到输入数据中的语义信息,使得语义相近的元素在嵌入空间中的距…
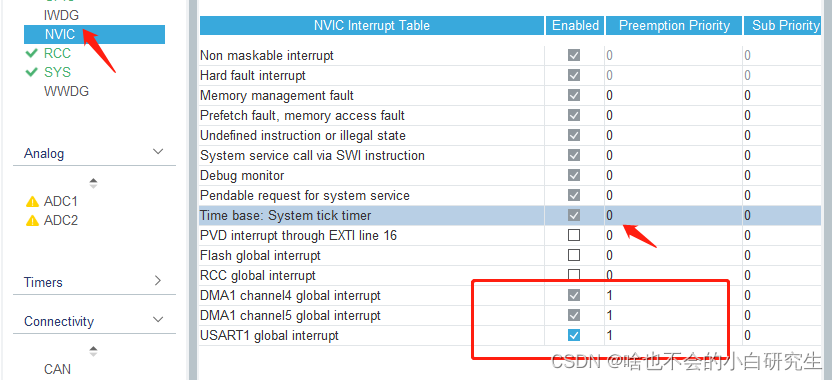
STM32+UART串口+DMA收发
目录 1、cubemax端配置
1.1 初始化配置
1.2 GPIO配置 1.3 UART配置
1.3.1 串口基础配置
1.3.2 DMA配置
2、keil端代码设计
2.1 初始化配置
2.2 DMA接收初始化配置
2.3 DMA发送配置 2.4 接收回调函数设置
2.5 回调函数内容代码编写
2.5.1 接收回调函数
2.5.2 发送回调…
最优化理论-最速下降法的推导与应用
目录
1. 引言
2. 最速下降法的基本原理
3. 最速下降法的推导过程
3.1 梯度和梯度下降
3.2 最速下降法的数学表述
4. 最速下降法的应用
4.1 无约束优化问题
4.2 约束优化问题
5. 最速下降法的优缺点
6. 结论
7.代码实现 1. 引言 在最优化理论中,最速下降法…
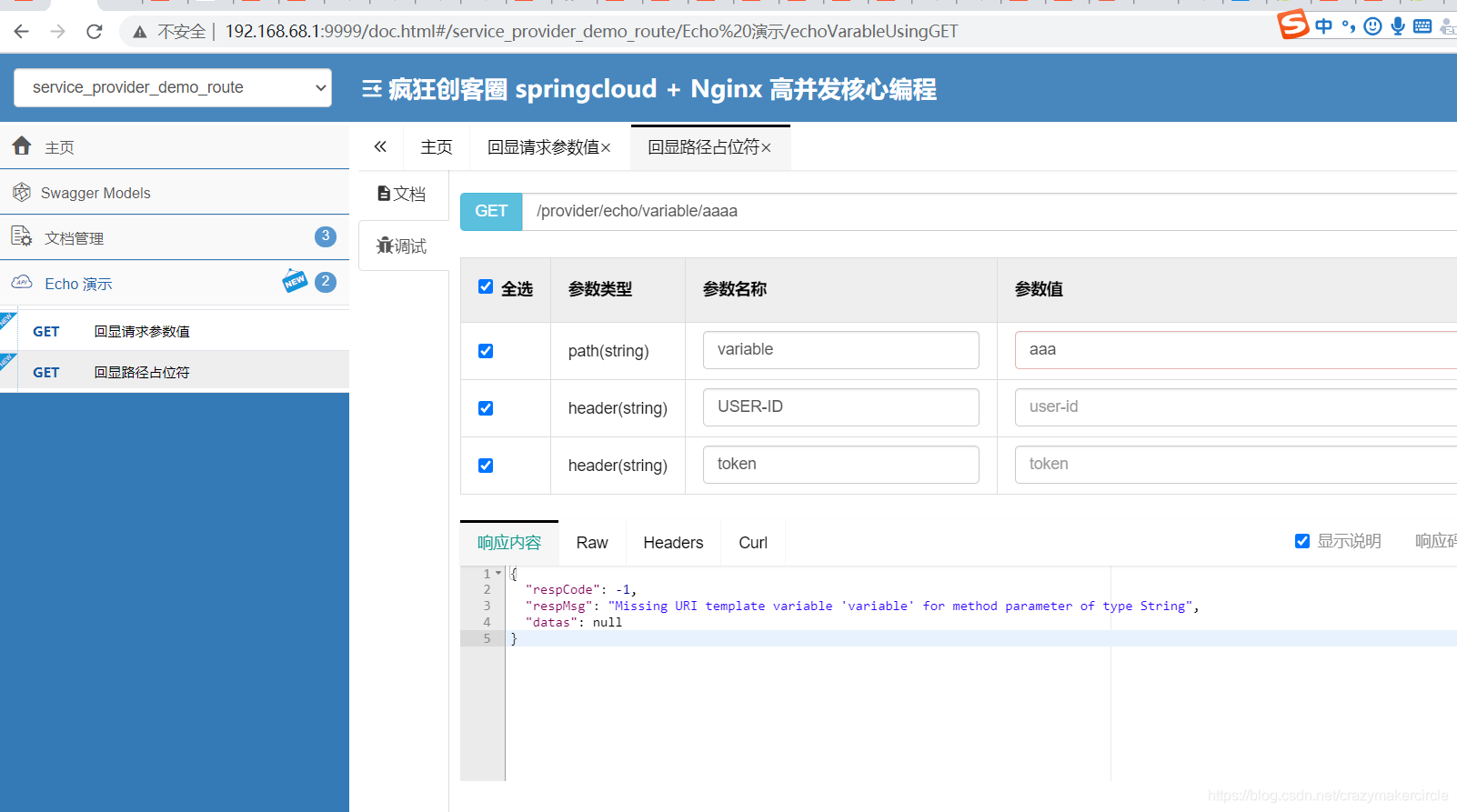
3W字吃透:微服务网关SpringCloud gateway底层原理和实操
40岁老架构师尼恩的掏心窝:
现在拿到offer超级难,甚至连面试电话,一个都搞不到。
尼恩的技术社群中(50),很多小伙伴凭借 “左手云原生 右手大数据 SpringCloud Alibaba 微服务“三大绝活,拿…

Dock的安装和使用
1、docker基础 三大组件: 仓库、镜像、容器什么是docker: 通俗来讲就是提供服务的容器Docker 两个概念:容器:可以看做空间 例如:磁盘、文件夹 镜像:灵魂 例如:系统、应用 一个镜像可以放在多个容器中(就如同把同一个文件复制到多个磁盘或文件夹一样) 一个容器可以放多个镜…
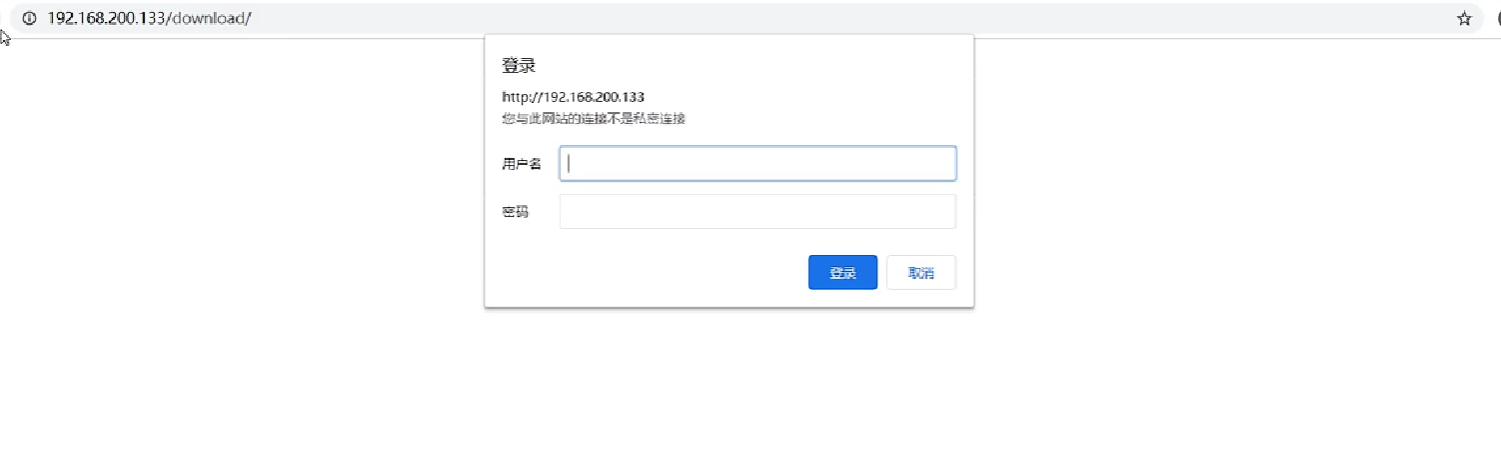
【Nginx】实战应用(服务器端集群搭建、下载站点、用户认证模块)
文章目录 Nginx实现服务器端集群搭建Nginx与Tomcat部署环境准备(Tomcat)环境准备(Nginx) Nginx实现动静分离需求分析动静分离实现步骤 Nginx实现Tomcat集群搭建 Nginx高可用解决方案KeepalivedVRRP环境搭建Keepalived配置文件介绍访问测试keepalived之vrrp_script Nginx制作下载…
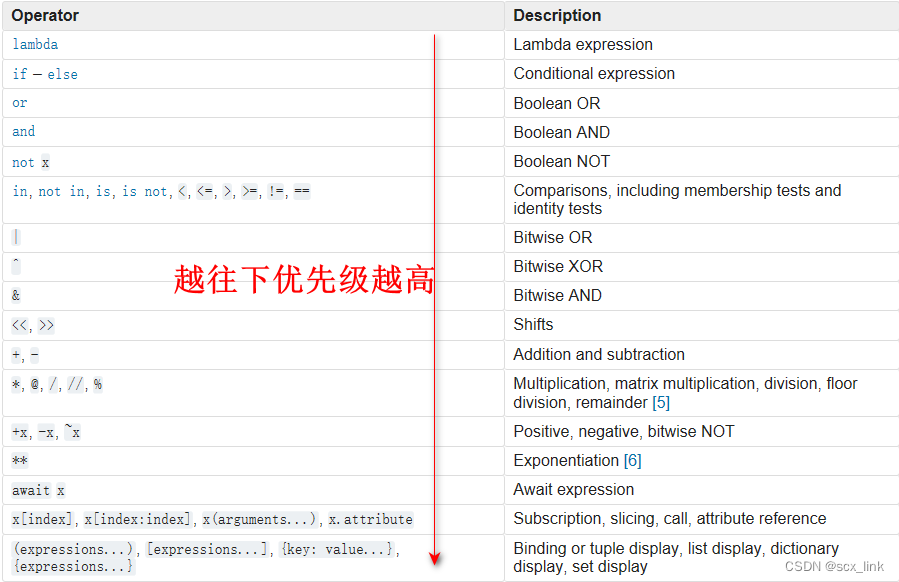
python中的常见运算符
文章目录 算数运算符赋值运算关系运算符逻辑运算符非布尔值的与或非运算条件运算符(也叫三元运算符)运算符的优先级 算数运算符 加法运算符(如果两个字符串之间进行加法运算,则会进行拼串操作)
- 减法运算符
* 乘法运算符(如果将字…

小鹏汽车Q1财报:押注G6、大力降本,明年智驾BOM降半
作者 | 德新编辑 |
王博 小鹏汽车本周发了Q1财报,数据不好看,以致于在微博端也发了公开信。
那后续呢?
小鹏第二季度指引是,总交付数量约为2.1 - 2.2万辆,收入预计约为45 - 47亿元;四季度,…
Selective Kernel Networks论文总结和代码实现
论文:https://arxiv.org/abs/1903.06586?contextcs 中文版:(CVPR-2019)选择性的内核网络_sk卷积 源码:GitHub - implus/SKNet: Code for our CVPR 2019 paper: Selective Kernel Networks 目录
一、论文出发点
二、论文主要工作
三、SK模…