canal实现mysql数据同步
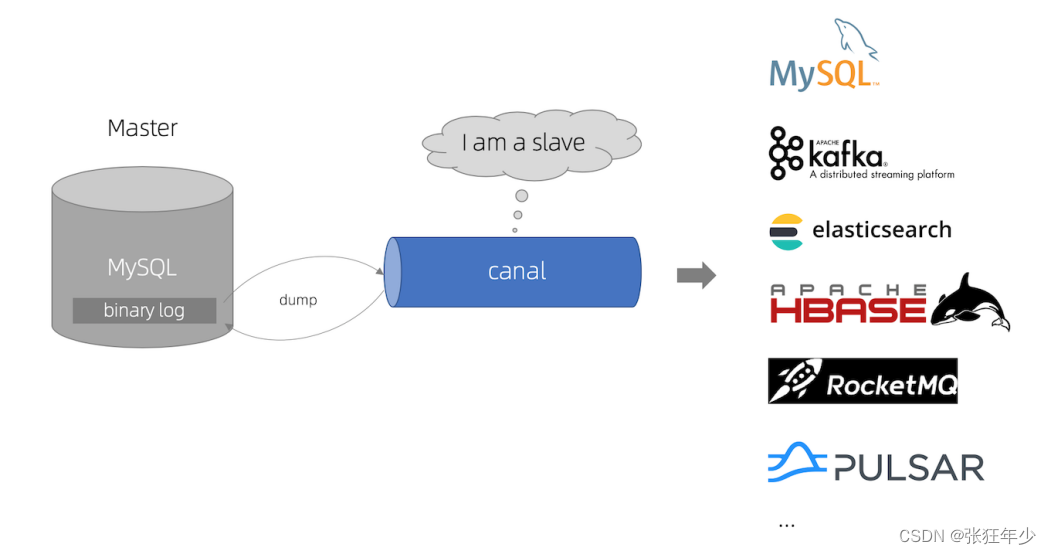
简介:最近线上系统进行压测,评估线上系统容量,根据压测情况对代理层,代码,sql等都做了相应的优化,而系统最大的瓶颈在于数据库,根据实际业务情况,决定对数据库架构进行优化升级。其中最大的一个优化方案就是把只读业务进行数据库迁移,因此有了同步线上数据库到本地数据库的需求,所以想到了阿里研发的canal中间件,下面将对canal的调研情况做详细分析。
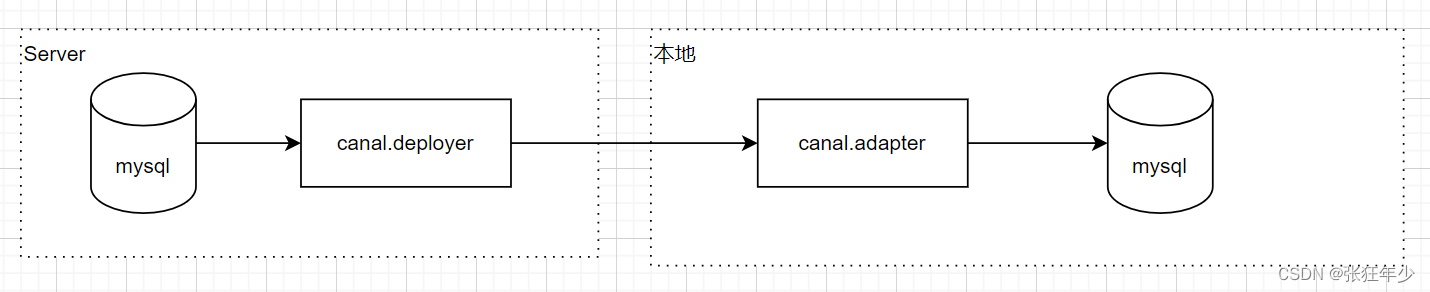
通过官网我们可以了解到canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
可以把日志同步到MySQL,MQ,ES等渠道中,这里我们要讲的模式是mysql to mysql
工作原理
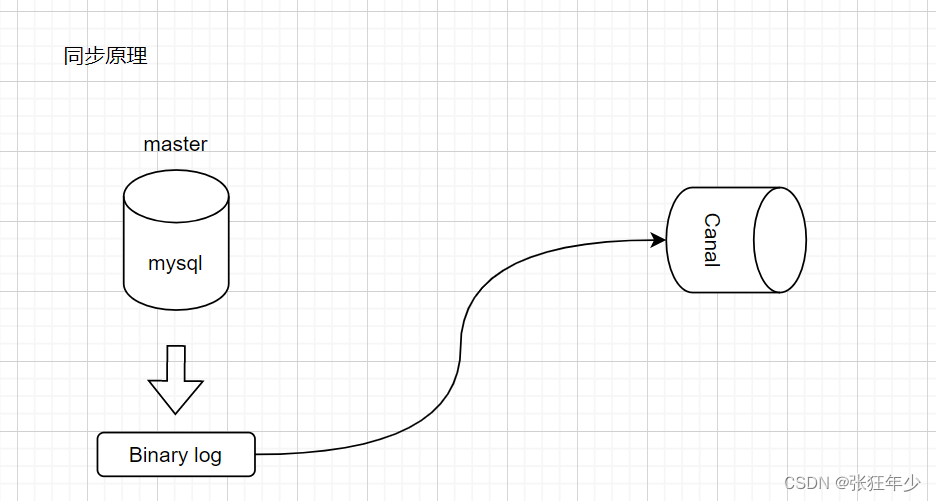
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
- 环境准备
| 服务器 | 数据库 | 安装包 |
| 192.168.1.46 | mysql 5.7 | canal.admin-1.1.7-SNAPSHOT.tar.gz canal.deployer-1.1.7-SNAPSHOT.tar.gz |
| 192.168.1.51 | mysql 5.7 | canal.adapter-1.1.7-SNAPSHOT.tar.gz |
- 配置
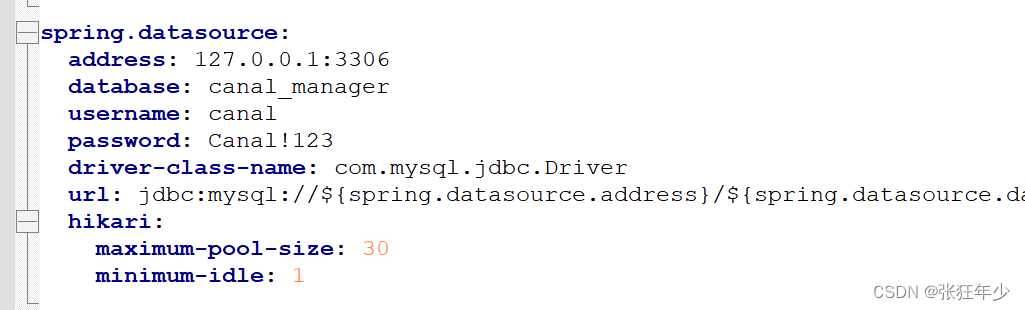
canal.admin 配置
tar -zxvf canal.admin-1.1.7-SNAPSHOT.tar.gz -C canal.admin
vi conf/application.yml
初始化元数据库
mysql -h127.0.0.1 -uroot -p
# 导入初始化SQL
> source /data2/soft/canal.admin/conf/canal_manager.sql
./bin/startup.sh 启动admin
浏览器访问 ip:8089
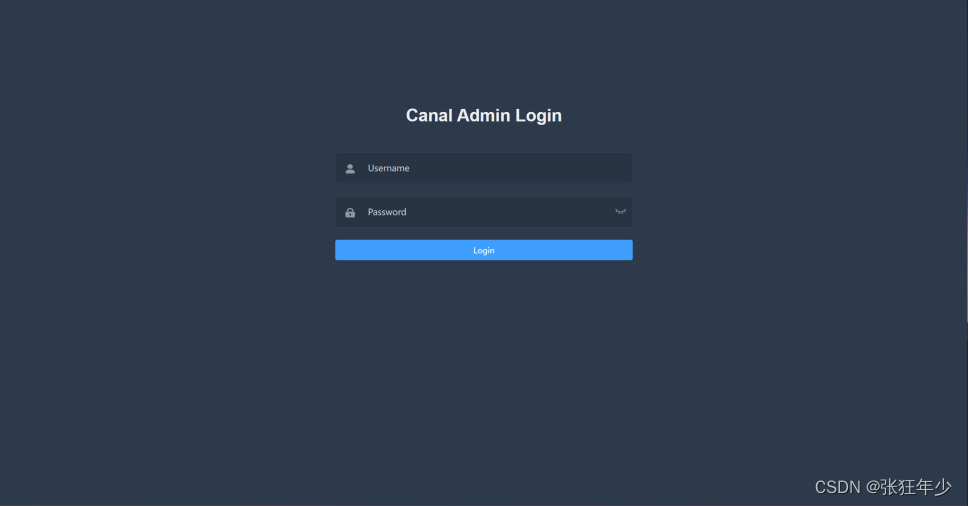
canal-admin为canal提供了整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面
canal.depoyer端配置
1、mysql开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
2、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'Canal!123';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
重新启动mysql
service mysqld restart / service mysql restart
3、配置canal.deployer
tar -zxvf canal.deployer-1.1.7-SNAPSHOT.tar.gz -C canal.deployer
主配置文件
canal.properties
子配置文件
instance.properties
./bin/startup.sh 启动deployer
canal.adapter端配置
tar -zxvf canal.adapter-1.1.7-SNAPSHOT.tar.gz -C canal.adapter
主配置文件
bootstrap.yml
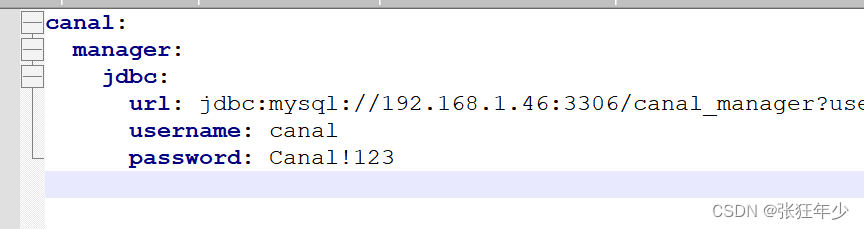
需要注意这里数据库连接的配置
application.yml
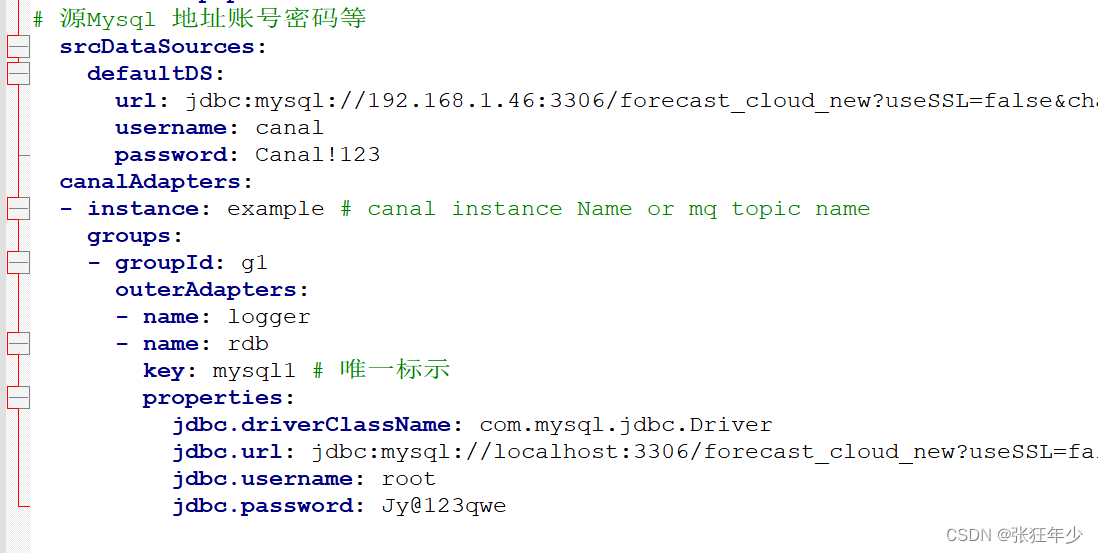
这里要注意的是,上面是源mysql连接的配置,下面是目标mysql的配置。注意这里数据库驱动需要和数据库版本对应上
子配置文件
forecast_cloud_new_stations.yml
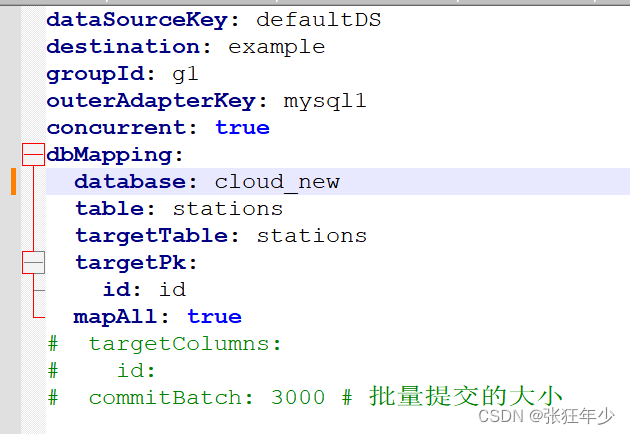
这里我配置的mapAll: true 整表映射,这样就需要源表和目标表字段一样。如果targetCloumns配置了映射,那就可以通过字段方式映射
./bin/stop.sh 停止
./bin/startup.sh 启动
看到如下日志说明已经成功实现了同步