Swin Transformer 论文精读
https://www.bilibili.com/video/BV13L4y1475U
Swin 几乎涵盖了 CV 的下游任务(下游任务指骨干网后面的 head 解决的任务,如:分类、检测、语义分割),并且曾经刷新多个数据集的榜单。
题目 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 含义:使用移动窗口的层级式的 Vision Transformer。Swin 希望 Transformer 像卷积网络一样可分成几个 block,能够做层级式的特征提取,使提取到的特征具有层级的概念。
Abstract
本文提出了一种新的 vision transformer,称为 Swin Transformer,它可以作为计算机视觉的通用骨干网。将Transformer 从语言应用到视觉的挑战来自于这两个领域之间的差异,例如视觉实体规模的巨大差异(在不同图片的同一个物体尺寸可能不同)以及与文本中的单词相比,图像中像素的高分辨率。为了解决这些差异,我们提出了一个 hierarchical Transformer,它的表示是用 shifted windows 计算的。shifted windows 提高了效率(因为self-attention 是在窗口内计算的,序列长度大大降低);将 self-attention 限制在不重叠的局部窗口,同时允许跨窗口连接(通过 shfiting,相邻的窗口之间有了交互。所以上下层之间可以 cross-windows connection,从而变相的达到一种全局建模的能力)。这种层次结构的好处:①、灵活提供各种尺度上的信息(建模的灵活性);②、相对于图像大小具有线性计算复杂度(self-attention 是在小窗口内计算的,计算复杂度随图像大小线性增长,而不是平方增长)。Swin Transformer 的这些特性使其与广泛的视觉任务兼容,包括图像分类(ImageNet-1K上的87.3 top-1精度)和密集预测任务,如对象检测(COCO testdev上的58.7 box AP和51.1 mask AP)和语义分割(ADE20K val上的53.5 mIoU)。其性能在COCO上大幅超过了+2.7盒AP和+2.6掩模AP,在ADE20K上超过了+3.2 mIoU,显示了基于 Transformer 的模型作为视觉骨干的潜力 。分层设计和移位窗口方法也被证明对所有 MLP 体系结构都是有益的。
Introduction
前两段的含义:在视觉领域,之前是卷积网络占主导地位,Transformer 在 NLP 领域效果很好,可以把 Transformer 应用于视觉领域。ViT 已经把这个落实了;而 Swin 的出发点便是证明 Transformer 可以用作一个视觉领域的通用骨干网络。
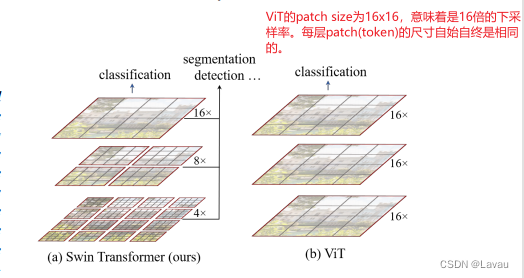
ViT 虽然可通过全局的自注意力操作达到全局的建模,但对多尺度特征的把握就弱一些。 对于具体的视觉任务,如检测和分割,多尺度的特征尤为重要。ViT 处理的特征是 single low resolution —— 一直处理的都是16倍的下采样率过后的的特征。因此 ViT 可能不适合于处理密集预测型的任务。另一方面,ViT 的 self-attention 始终是在整张图上进行的。它是一个全局建模,而且复杂度跟图像尺寸进行平方倍的增长。
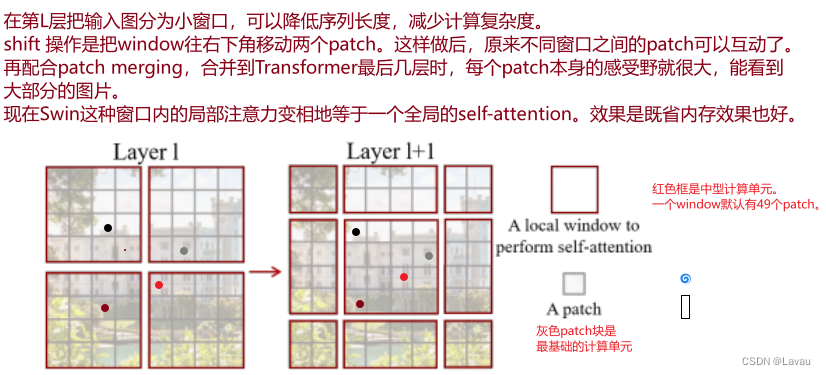
Swin 借鉴了很多卷积网络的经验与先验知识。比如为减少序列长度、降低计算复杂度。Swin 提出在小窗口内计算 self-attention,而不像 ViT 在全图上进行。只要窗口大小固定,计算复杂度固定;整张图的计算复杂度,与这张图片的大小成线性增长关系。这一点也算是利用了卷积网络中的 locality 的 inductive bias:同一物体的不同部位或者语义相近的不同物体大概率会出现在相连的地方。
Swin 怎样产生多尺寸的特征呢?卷积网络中主要通过 pooling 生成多尺寸特征。pooling 操作能增大每个卷积核看到的感受野,从而使得池化后的特征抓住物体不同的尺寸。相应地,Swin 提出类 pooling 操作 —— patch merging:把相邻的小 patch 合成大 patch。大 patch 能够看到之前小 patch 看到的内容,感受野也就增大了,正如上图(左)表示的。
(第三段)
(第四段。第四段介绍 shifting 操作。这里结合 Fig 2 讲解。)
第五段展示 Swin 取得的结果。
第六段作者展望:CV 与 NLP 大一统的框架能够促进两个领域的共同发展。
(Swin 很好地利用视觉里的先验知识,在视觉任务上大杀四方。但是在大一统上,ViT 更好。因为它什么都不改,先验信息也不加,Transformer 在两个领域都用的很好。这样模型可以共享参数,甚至到多个模态的输出拼接起来当成一个很长的输入,直接交过 Transformer,不考虑模态间的差异。)
Conclusion
Swin 是一种新的视觉 Transformer,它产生层次特征表示,并且对输入图像大小具有线性计算复杂度。Swin 在 COCO 对象检测和 ADE20K 语义分割方面实现了最先进的性能,大大超过了以前的最佳方法。我们希望 Swin 在各种视觉问题上的强大表现将鼓励视觉和语言信号的统一建模。(第一段)
作者提出 Swin 最关键的贡献是 shifted window based self-attention。对于视觉的下游任务尤其是密集预测型任务更重要。作者提出接下来的工作可以把 shifted window based self-attention 应用在 NLP 中。(第二段)
Related Work
作者先大概讲一下卷积神经网络,再谈到 self-attention 或者 Transformer 如何帮助卷积神经网络,最后谈纯 Transformer 做视觉的骨干网络。
(Swin 的相关工作与 ViT 相关工作的内容几乎一致,不再赘述)
Method
作者在本章节分两个大块:3.1 讲述 Swin 的整体流程,主要是过一遍 Swin 的前向过程以及描述 patch merging 操作如何实现。3.2 讨论 Swin 如何把基于 shifted window 的 self-attention 变为一个 Transformer block 开展计算。
Overall Architecture
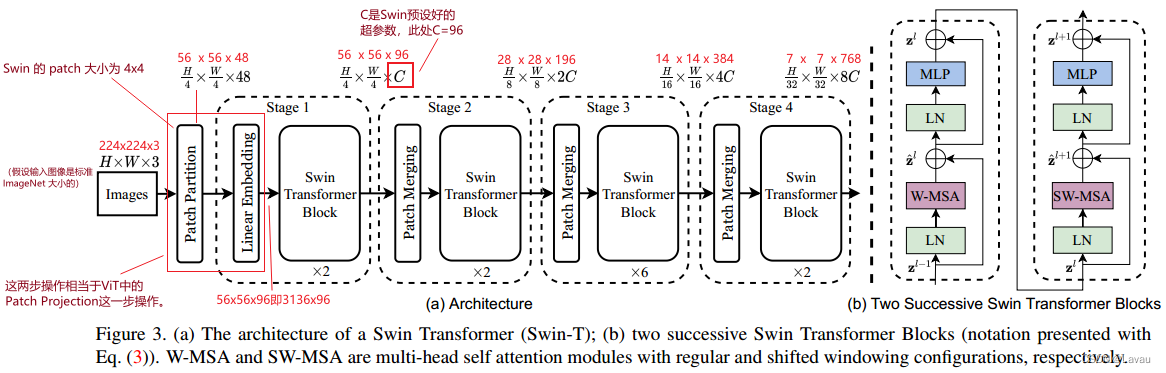
(21:06—29:00 根据模型总览图 Fig 3 讲述 Swin 的前向计算过程)
假设输入的图片大小是标准 ImageNet 大小 224 ∗ 224 ∗ 3 224*224*3 224∗224∗3。因为 Swin 的 patch 大小为 4 ∗ 4 4*4 4∗4,所以处理得到的图像块为 56 ∗ 56 ∗ 48 ( 56 = 224 4 )( 48 = 4 ∗ 4 ∗ 3 表示每个 p a t c h 向量的维度) 56*56*48(56=\frac{224}{4})(48=4*4*3\ 表示每个\ patch\ 向量的维度) 56∗56∗48(56=4224)(48=4∗4∗3 表示每个 patch 向量的维度)。
通过 Linear Embedding 把向量维度变成 已经预设好的大小(即 Transformer 能够接受的大小),Swin 论文中把这个超参数设为 C C C(对于 Fig 3 展示的 Swin-T 来说, C = 96 C=96 C=96)。那么通过 Linear Embedding 得到的结果大小为 3136 ∗ 96 ( 3136 = 56 ∗ 56 ) 3136*96(3136=56*56) 3136∗96(3136=56∗56);也就是说,序列的长度为 3136 3136 3136,每个 token 向量的维度为 96 96 96。
Swin 的 Patch Partition、Linear Embedding 这两步操作相当于 ViT 中的 Patch Projection 这一步操作。在 Swin 代码中,作者用一步卷积完成。
此时进入 Transformer 的序列长度为 3136 3136 3136,远超 ViT 进入 Transformer 的序列长度(它的序列长度为 196 196 196);而且 Transformer 也不能接受这么长的序列。Swin 便引入了 self-attention based shifted windows。默认的,每个窗口有 49 个 patch,即序列长度只有 49。Swin Transformer Block 是 self-attention based shifted windows 进行计算的。
接下来我们了解 Patch Merging 如何实现。

应该明确 Patch Merging 的输入为 H ∗ W ∗ C H*W*C H∗W∗C,经过中间 Ⅰ、Ⅱ、Ⅲ、Ⅳ 四步之后的输出为 H 2 ∗ W 2 ∗ 2 C \frac{H}{2}*\frac{W}{2}*2C 2H∗2W∗2C。也就是经过 Patch Merging 之后,实现了 “宽高减半,通道加倍” 的效果。
- 第 Ⅰ 步把给出的图像分为 4 个窗口,每个窗口有 4 个 patch。
- 第 Ⅱ 步把每个窗口相应位置的 patch 放在一起,达到了 “宽高减半” 的效果。
- 第 Ⅲ 步把它们叠放一起,得到 “宽高减半,通道四倍” 的结果。
- 第 Ⅳ 步使用 1 ∗ 1 1*1 1∗1 的卷积对通道降维,实现 “宽高减半,通道加倍” 。
再次回看 Fig 3。
每次经过每个 Stage 的 Patch Merging 后,都会 “宽高减半,通道加倍” (Fig 3 中已经标出这些变化)。
到此为止,Swin 骨干网的前向传播(计算)完成。
Swin 有四个 Stage,后三个 Stage 有类似池化的 Patch Merging 操作,并且它的 self-attention 在小窗口之内计算的。
Shifted Window based Self-Attention
为何引入 Shifted Window based Self-Attention?基于全局的 self-attention 导致平方倍的复杂度;在做视觉的下游任务,尤其是密集预测型的任务时,或者遇到图片尺寸很大时,全局的 self-attention 的计算非常非常昂贵!所以,作者提出 Shifted Window based Self-Attention。(第一段)
作者如何实现窗口划分的?(开始 20:45-结束 30:54)(下图以 Stage 1 的输入举例,讲解窗口的划分)

输入尺寸是 56 ∗ 56 ∗ 96 56*56*96 56∗56∗96。原来的图片被平均分为没有重叠的窗口。上图用橘黄色表示这些窗口。这些窗口并非是最小的计算单元,最小的计算单元还是 patch。也就是说每个窗口里还有 m ∗ m m*m m∗m 个 patch。在 Swin 本篇论文中, m = 7 m=7 m=7。即每个窗口中有 49 ( 49 = 7 ∗ 7 ) 49(49=7*7) 49(49=7∗7) 个 patch。又因为 self-attention 的计算是在窗口内进行的,所以序列长度永远是 49 49 49。那么上图一共可以划分出 64 ( 56 7 ∗ 56 7 ) 64(\frac{56}{7}*\frac{56}{7}) 64(756∗756) 个窗口,分别在这 64 64 64 个窗口里算 self-attention。
讲解 Shifted Window based Self-Attention 的复杂度的计算方式以及与全局的 self-attention 复杂度的对比。(开始 30:54-结束 34:41)
(此部分笔记略。等到以后需要时再添加)
作者如何实现移动窗口(shift window)的呢?(开始 35:07-结束 36:95)
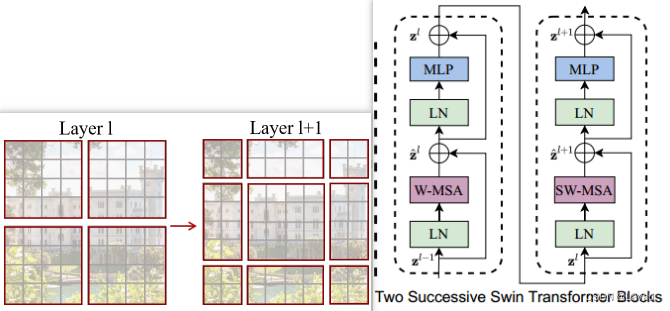
上图已经左部分介绍了移动过程,实现窗口间互通信的目的。Swin Transformer Block 结构的安排也是有讲究的(符合左部分图示的移动过程):每次先做一次基于窗口的 multi-head self-attention,再做一次基于移动窗口的 multi-head self-attention(如上图右部分所示)。
z
^
l
=
W
_
M
S
A
(
L
N
(
z
l
−
1
)
)
+
z
l
−
1
\hat{\pmb{z}}^l = W\_MSA(LN(\pmb{z}^{l-1})) + \pmb{z}^{l-1}
z^l=W_MSA(LN(zl−1))+zl−1
z
l
=
M
L
P
(
L
N
(
z
^
l
)
)
+
z
^
l
{\pmb{z}}^l = MLP(LN(\hat{\pmb{z}}^l)) + \hat{\pmb{z}}^l
zl=MLP(LN(z^l))+z^l
z
^
l
+
1
=
S
W
_
M
S
A
(
L
N
(
z
l
)
)
+
z
l
\hat{\pmb{z}}^{l+1} = SW\_MSA(LN(\pmb{z}^{l})) + \pmb{z}^{l}
z^l+1=SW_MSA(LN(zl))+zl
z
l
+
1
=
M
L
P
(
L
N
(
z
^
l
+
1
)
)
+
z
^
l
+
1
{\pmb{z}}^{l+1} = MLP(LN(\hat{\pmb{z}}^{l+1})) + \hat{\pmb{z}}^{l+1}
zl+1=MLP(LN(z^l+1))+z^l+1
讲解 Swin 如何利用掩码的方式提高移动窗口的计算效率。(开始 37:04-结束 51:00)
(此部分笔记略。等到以后需要时再添加)
Architecture Variants
(开始 51:00-结束 51:43)
在本节作者提出 Swin 的四种变体:Swin-T、Swin-S、Swin-B、Swin-L。目的是希望与 Resnet 做比较公平的对比。四种变体的不同体现在两个超参数:①、向量维度大小 C C C,②、每层 Stage 拥有的 transformer block 的数量。(这一点与 Resnet 的结构相似。Resnet 也是分为四个 Stage,每个 Stage 拥有残差块数量不同)