大家好,我是微学AI,今天给大家介绍一下人工智能(Pytorch)搭建模型6-使用Pytorch搭建卷积神经网络ResNet模型,在本文中,我们将学习如何使用PyTorch搭建卷积神经网络ResNet模型,并在生成的假数据上进行训练和测试。本文将涵盖这些内容:ResNet模型简介、ResNet模型结构、生成假数据、实现ResNet模型、训练与测试模型。
一、ResNet模型简介
ResNet(残差网络)模型是由何恺明等人在2015年提出的一种深度卷积神经网络。它的主要创新是引入了残差结构,通过这种结构,ResNet可以有效地解决深度神经网络难以训练的问题。ResNet在多个图像分类任务上取得了非常好的效果,包括ImageNet大规模视觉识别挑战赛。ResNet模型使得卷积神经网络不受到层数的限制,解决了层数越深,模型预测结果越差的情况。
二、ResNet模型结构
ResNet的核心思想是引入残差块,残差块的输入不仅直接传给下一层,而且还通过一个跳跃连接(Skip Connection)直接连接到后面的层。这种结构可以有效地缓解梯度消失问题,使得网络可以被有效地训练。
一个典型的残差块包含两个卷积层、两个激活函数和一个跳跃连接。ResNet网络的层数可以通过堆叠不同数量的残差块来实现,例如常见的ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152等。
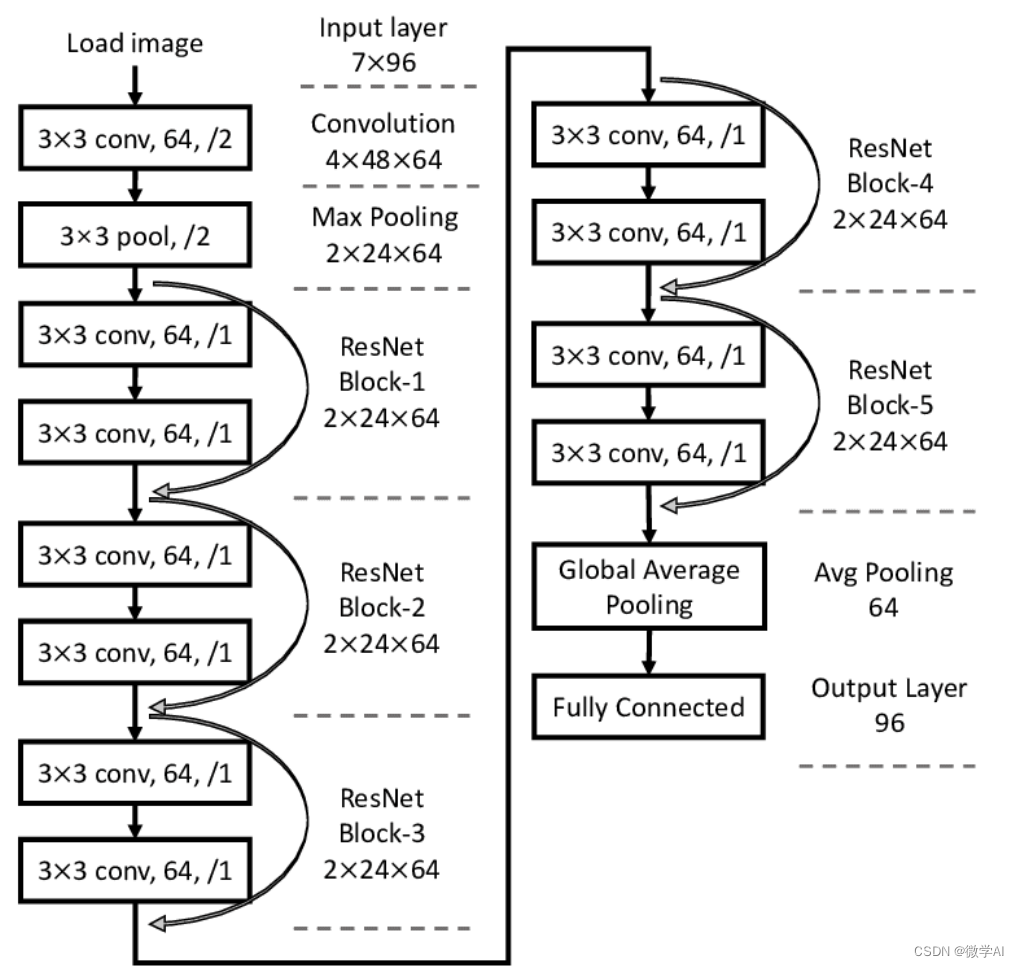
三、生成假数据
为了演示模型的训练和测试,我们将在本文中使用生成的假数据。我们将生成一个包含1000个3通道32x32图像的数据集,使用随机数来表示图像像素值,并为每个图像分配一个介于0到9之间的类别标签。
四、实现ResNet模型
接下来,我们将使用PyTorch框架实现一个简化版的ResNet-18模型。首先,我们需要导入所需的库:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.skip_connection = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.skip_connection = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.skip_connection(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, stride=1)
self.layer2 = self._make_layer(block, 128, stride=2)
self.layer3 = self._make_layer(block, 256, stride=2)
self.layer4 = self._make_layer(block, 512, stride=2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, stride):
layers = [block(self.in_channels, out_channels, stride)]
self.in_channels = out_channels
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x残差连接图:

五、训练与测试模型
现在我们创建数据集、模型、损失函数和优化器,然后进行训练:
# 生成假数据
num_samples = 1000
image_data = np.random.rand(num_samples, 3, 32, 32).astype(np.float32)
labels = np.random.randint(0, 10, size=num_samples, dtype=np.int64)
# 创建数据集和数据加载器
train_data = TensorDataset(torch.from_numpy(image_data), torch.from_numpy(labels))
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
# 创建模型、损失函数和优化器
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ResNet(ResidualBlock).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / (i + 1)}")
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy of the model on the {total} test images: {100 * correct / total}%")六、总结
文章详细介绍了如何使用PyTorch搭建卷积神经网络ResNet模型,并在生成的假数据上进行训练和测试。通过实现简化版的ResNet-18模型,我们了解了残差块的结构和原理,以及如何利用残差结构有效地训练深度神经网络。在实际应用中,可以通过调整模型结构和参数,以及使用真实的数据集来进一步提升模型的性能。