目录
1.Linux线程同步
1.1.条件变量
1.1.1.同步概念与竞态条件
1.1.2.条件变量函数 初始化和销毁
1.1.3.等待条件满足
1.1.5.为什么 pthread_cond_wait 需要互斥量?
1.1.6.条件变量使用规范
2.生产者消费者模型
2.1.模型概念
2.2.模型优点
2.3.基于Blocking Queue的生产者消费者模型
2.4.POSIX信号量
2.4.1.初始化
2.4.2.销毁信号量
2.4.3.等待信号量 (申请资源)(P操作)(原子的)
2.4.4.发布信号量(归还资源)(V操作)(原子的)
2.5.基于环形队列的生产消费模型
3.线程池
4.线程安全的单例模式
4.1.单例模式的特点
4.2.饿汉实现方式和懒汉实现方式
4.2.1.饿汉方式实现单例模式
4.2.2.懒汉方式实现单例模式
5.单例模式的线程池(懒汉)
6.STL,智能指针和线程安全
6.1.STL中的容器是否是线程安全的?
6.2.智能指针是否是线程安全的?
7. 其他常见的各种锁
7.1.自旋锁
8.读者写者问题
1.Linux线程同步
1.1.条件变量
- 当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
- 例如一个线程访问队列时,发现队列为空,它只能等待,只到其它线程将一个节点添加到队列中。这种情 况就需要用到条件变量。
1.1.1.同步概念与竞态条件
- 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问 题,叫做同步
- 竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解
1.1.2.条件变量函数 初始化和销毁
函数原型
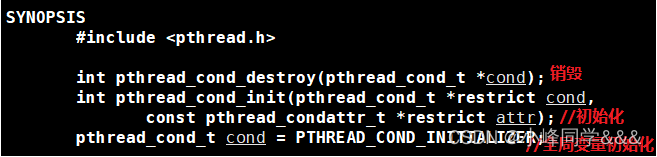
和互斥锁相同,全局变量可以使用静态初始化和动态初始化,局部变量只能动态初始化。
1.1.3.等待条件满足

int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
参数:
cond:要在这个条件变量上等待
mutex:互斥量,后面详细解释1.1.4.唤醒等待

1.1.5.为什么 pthread_cond_wait 需要互斥量?
- 条件等待是线程间同步的一种手段,如果只有一个线程,条件不满足,一直等下去都不会满足,所以必须 要有一个线程通过某些操作,改变共享变量,使原先不满足的条件变得满足,并且友好的通知等待在条件 变量上的线程。
- 条件不会无缘无故的突然变得满足了,必然会牵扯到共享数据的变化。所以一定要用互斥锁来护。没有 互斥锁就无法安全的获取和修改共享数据。

// 错误的设计
pthread_mutex_lock(&mutex);
while (condition_is_false) {
pthread_mutex_unlock(&mutex);
//解锁之后,等待之前,条件可能已经满足,信号已经发出,但是该信号可能被错过
pthread_cond_wait(&cond);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);
- 由于解锁和等待不是原子操作。调用解锁之后, pthread_cond_wait 之前,如果已经有其他线程获取到 互斥量,摒弃条件满足,发送了信号,那么 pthread_cond_wait 将错过这个信号,可能会导致线程永远 阻塞在这个 pthread_cond_wait 。所以解锁和等待必须是一个原子操作。
- int pthread_cond_wait(pthread_cond_ t *cond,pthread_mutex_ t * mutex); 进入该函数后, 会去看条件量等于0不?等于,就把互斥量变成1,直到cond_ wait返回,把条件量改成1,把互斥量恢复 成原样。
1.1.6.条件变量使用规范
等待条件代码
pthread_mutex_lock(&mutex);
while (条件为假)
{
pthread_cond_wait(cond, mutex);
}
修改条件
pthread_mutex_unlock(&mutex);给条件发送信号代码
pthread_mutex_lock(&mutex);
设置条件为真
pthread_cond_signal(cond);
pthread_mutex_unlock(&mutex);2.生产者消费者模型
2.1.模型概念
321原则(便于记忆)
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
2.2.模型优点
- 生产线程和消费线程强解耦。
- 支持并发。
- 提高效率(平均),生产者专心搞生成,消费者专心搞消费,缓冲区负责分发。
- 支持忙闲不均。
2.3.基于Blocking Queue的生产者消费者模型
- 在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,
- 当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;
- 当队列满时,往队列里存放元 素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞)

#include <iostream>
#include <queue>
#include <stdlib.h>
#include <pthread.h>
#define NUM 8
class BlockQueue
{
private:
std::queue<int> q;
int cap;
pthread_mutex_t lock;
pthread_cond_t full;
pthread_cond_t empty;
private:
void LockQueue()
{
pthread_mutex_lock(&lock);
}
void UnLockQueue()
{
pthread_mutex_unlock(&lock);
}
void ProductWait()
{
pthread_cond_wait(&full, &lock);
}
void ConsumeWait()
{
pthread_cond_wait(&empty, &lock);
}
void NotifyProduct()
{
pthread_cond_signal(&full);
}
void NotifyConsume()
{
pthread_cond_signal(&empty);
}
bool IsEmpty()
{
return (q.size() == 0 ? true : false);
}
bool IsFull()
{
return (q.size() == cap ? true : false);
}
public:
BlockQueue(int _cap = NUM) : cap(_cap)
{
pthread_mutex_init(&lock, NULL);
pthread_cond_init(&full, NULL);
pthread_cond_init(&empty, NULL);
}
void PushData(const int &data)
{
LockQueue();
while (IsFull())
{
NotifyConsume();
std::cout << "queue full, notify consume data, product stop." << std::endl;
ProductWait();
}
q.push(data);
// NotifyConsume();
UnLockQueue();
}
void PopData(int &data)
{
LockQueue();
while (IsEmpty())
{
NotifyProduct();
std::cout << "queue empty, notify product data, consume stop." << std::endl;
ConsumeWait();
}
data = q.front();
q.pop();
// NotifyProduct();
UnLockQueue();
}
~BlockQueue()
{
pthread_mutex_destroy(&lock);
pthread_cond_destroy(&full);
pthread_cond_destroy(&empty);
}
};
void *consumer(void *arg)
{
BlockQueue *bqp = (BlockQueue *)arg;
int data;
for (;;)
{
bqp->PopData(data);
std::cout << "Consume data done : " << data << std::endl;
}
}
// more faster
void *producter(void *arg)
{
BlockQueue *bqp = (BlockQueue *)arg;
srand((unsigned long)time(NULL));
for (;;)
{
int data = rand() % 1024;
bqp->PushData(data);
std::cout << "Prodoct data done: " << data << std::endl;
// sleep(1);
}
}
int main()
{
BlockQueue bq;
pthread_t c, p;
pthread_create(&c, NULL, consumer, (void *)&bq);
pthread_create(&p, NULL, producter, (void *)&bq);
pthread_join(c, NULL);
pthread_join(p, NULL);
return 0;
}上面的基于blockqueue的生产者消费者模型是可以直接扩展未多生产多消费的模型, 因为使用一个互斥锁即可实现对,所有生产者和所有消费者的互斥访问。
2.4.POSIX信号量
- 本质就是一个计数器。衡量临界资源资源数目的多少的计数器。
- 只要拥有信号量,在未来就一定能够拥有临界资源的一部分,申请信号量的本质:对临界资源的预定机制。
- 用信号量的申请成功与否,来判断临界资源是否条件满足。在没有进入临界区就可以判断是否条件满足。
- 一般先申请信号量,申请成功,再加锁进入临界区;申请失败,阻塞等待。不进入临界区,避免频繁的加锁检测解锁程序。
2.4.1.初始化
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数:
pshared:0表示线程间共享,非零表示进程间共享
value:信号量初始值2.4.2.销毁信号量
int sem_destroy(sem_t *sem);2.4.3.等待信号量 (申请资源)(P操作)(原子的)
功能:等待信号量,会将信号量的值减1
int sem_wait(sem_t *sem); //P()2.4.4.发布信号量(归还资源)(V操作)(原子的)
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。
int sem_post(sem_t *sem);//V()信号量适合,在一个临界资源中,整体支持并发访问,但是里面的小单元不支持并发访问,可以通过合理的控制实现,让每一个线程程通过访问整个临界资源中不同的位置,来实现并发访问。
2.5.基于环形队列的生产消费模型
上面我们写的基于阻塞队列的生产者消费者模型,也有不足的地方:
- 1.一个线程,在操作临界资源的时候,必须先是满足条件的!
- 2.可是我们在访问之前,是无法得知他是否满足条件的,只有在访问的时候判断是否满足条件。
- 3.所有只能先加锁,再检测,再操作,再解锁。(在临界区以外是不知道是否满足条件的)。
- 4.频繁的加锁解锁是有很大的消耗的。
- 5.这里就顺利引入信号量了。在进入临界区之前就可以判断时候满足条件。
- 6.信号量,可以满足不进入临界区就可以,知道临界资源的使用情况。申请到了信号量的线程,一定可以满足条件。临界资源一定满足。

我们这里的环形队列是使用数组实现的。下面是具体代码,多生产和多消费的。
#include <iostream>
#include <vector>
#include <unistd.h>
#include <stdlib.h>
#include <semaphore.h>
#include <pthread.h>
#define NUM 16
class RingQueue
{
private:
std::vector<int> q;//环形队列
int cap;//队列容量
sem_t data_sem;//代表数据个数信号量(初始为0)
sem_t space_sem;//代表空盘子的个数的信号量(初始为cap个)
int consume_step;//当前消费者访问的下标
int product_step;//当前生产者访问的下标
pthread_mutex_t consume_mutex;//让消费者互斥
pthread_mutex_t product_mutex;//让生产者互斥
//这里互斥争夺的是对应下标的访问
public:
RingQueue(int _cap = NUM) : q(_cap), cap(_cap)
{
//初始化信号量
sem_init(&data_sem, 0, 0);
sem_init(&space_sem, 0, cap);
consume_step = 0;
product_step = 0;
//初始化互斥量
pthread_mutex_init(&consume_mutex, nullptr);
pthread_mutex_init(&product_mutex, nullptr);
}
void PutData(const int &data)
{
sem_wait(&space_sem); // P
pthread_mutex_lock(&product_mutex);
q[consume_step] = data;
consume_step++;
consume_step %= cap;
pthread_mutex_unlock(&product_mutex);
sem_post(&data_sem); // V
}
void GetData(int &data)
{
sem_wait(&data_sem);
pthread_mutex_lock(&consume_mutex);
data = q[product_step];
product_step++;
product_step %= cap;
pthread_mutex_unlock(&consume_mutex);
sem_post(&space_sem);
}
~RingQueue()
{
sem_destroy(&data_sem);
sem_destroy(&space_sem);
pthread_mutex_destroy(&product_mutex);
pthread_mutex_destroy(&consume_mutex);
}
};
void *consumer(void *arg)
{
RingQueue *rqp = (RingQueue *)arg;
int data;
for (;;)
{
rqp->GetData(data);
std::cout << "Consume data done : " << data << std::endl;
sleep(1);
}
}
// more faster
void *producter(void *arg)
{
RingQueue *rqp = (RingQueue *)arg;
srand((unsigned long)time(NULL));
for (;;)
{
int data = rand() % 1024;
rqp->PutData(data);
std::cout << "Prodoct data done: " << data << std::endl;
// sleep(1);
}
}
int main()
{
RingQueue rq;
pthread_t c1, c2, c3, c4, p1, p2, p3, p4;
pthread_create(&c1, NULL, consumer, (void *)&rq);
pthread_create(&c2, NULL, consumer, (void *)&rq);
pthread_create(&c3, NULL, consumer, (void *)&rq);
pthread_create(&c4, NULL, consumer, (void *)&rq);
pthread_create(&p1, NULL, producter, (void *)&rq);
pthread_create(&p2, NULL, producter, (void *)&rq);
pthread_create(&p3, NULL, producter, (void *)&rq);
pthread_create(&p4, NULL, producter, (void *)&rq);
pthread_join(c1, NULL);
pthread_join(c2, NULL);
pthread_join(c3, NULL);
pthread_join(c4, NULL);
pthread_join(p1, NULL);
pthread_join(p2, NULL);
pthread_join(p3, NULL);
pthread_join(p4, NULL);
return 0;
}3.线程池
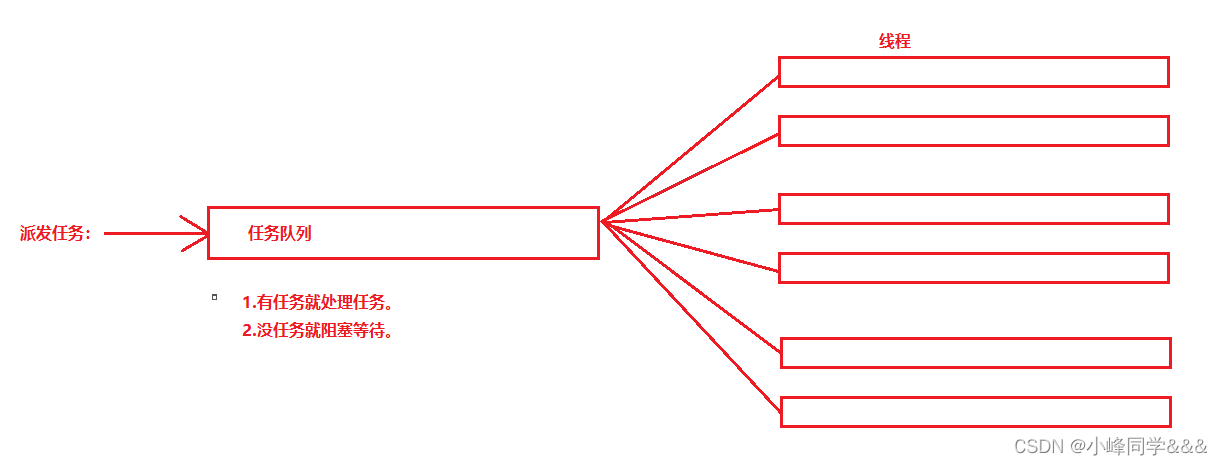
一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着 监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。可用线程数量应该取决于可用的并发处理器、处理器内核、内存、网络sockets等的数量。
- 1. 需要大量的线程来完成任务,且完成任务的时间比较短。 WEB服务器完成网页请求这样的任务,使用线程池技术是非常合适的。因为单个任务小,而任务数量巨大,你可以想象一个热门网站的点击次数。 但对于长时间的任务,比如一个 Telnet连接请求,线程池的优点就不明显了。因为Telnet会话时间比线程的创建时间大多了。
- 2. 对性能要求苛刻的应用,比如要求服务器迅速响应客户请求。
- 3. 接受突发性的大量请求,但不至于使服务器因此产生大量线程的应用。突发性大量客户请求,在没有线程池情况下,将产生大量线程,虽然理论上大部分操作系统线程数目最大值不是问题,短时间内产生大量线程可能使内存到达极限, 出现错误.
gitee代码链接:gitee
//threadpool.hpp
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <pthread.h>
#include "thread.hpp"
#include "lockguard.hpp"
using namespace ThreadNS;
#define NUM 15
template <class T>
class ThreadPool;
template <class T>
class ThreadData
{
public:
ThreadData(ThreadPool<T> *tpthis, std::string threadname)
: _tpthis(tpthis), _threadname(threadname)
{
}
ThreadPool<T> *_tpthis;
std::string _threadname;
};
template <class T>
class ThreadPool
{
private:
int _num;
std::vector<Thread *> _threads; // 保存创建的线程
std::queue<T> _task_queue; // 保存任务列表
pthread_mutex_t _mutex; // 保护任务队列
pthread_cond_t _cond; // 线程阻塞的条件变量
private:
static void *handlertask(void *args)
{
// sleep(3);
// std::cout<<(args)<<std::endl;
ThreadData<T> *data = static_cast<ThreadData<T> *>(args);
while (true)
{
// data->_tpthis->lockqueue();
T t;
{
LockGuard lock(data->_tpthis->getmutex());
while (data->_tpthis->queueempty())
{
data->_tpthis->waitthread();
}
t = data->_tpthis->queuepop();
}
// data->_tpthis->unlockqueue();
std::cout << data->_threadname << "处理任务:" << t() << std::endl;
}
}
void lockqueue()
{
pthread_mutex_lock(&_mutex);
}
void unlockqueue()
{
pthread_mutex_unlock(&_mutex);
}
bool queueempty()
{
return _task_queue.empty();
}
void waitthread()
{
pthread_cond_wait(&_cond, &_mutex);
}
T queuepop()
{
// 这个是内部接口
// 不用加锁,因为在锁内部调用。
T ret = _task_queue.front();
_task_queue.pop();
return ret;
}
void signalthread()
{
pthread_cond_signal(&_cond);
}
pthread_mutex_t *getmutex()
{
return &_mutex;
}
public:
ThreadPool(int num = NUM)
: _num(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
for (int i = 0; i < _num; ++i)
{
Thread *tp = new Thread();
_threads.push_back(tp);
}
}
void start()
{
for (auto &e : _threads)
{
ThreadData<T> *data = new ThreadData<T>(this, e->getname());
e->start(handlertask, (void *)data);
// std::cout<<e<<" thread start.."<<std::endl;
}
}
void push(T in)
{
// lockqueue();
LockGuard lock = getmutex();
_task_queue.push(in);
std::cout << "收到任务:" << in.totaskstring() << std::endl;
signalthread();
// unlockqueue();
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
for (auto &e : _threads)
{
e->join();
delete e;
}
}
};4.线程安全的单例模式
IT行业这么火, 涌入的人很多. 俗话说林子大了啥鸟都有. 大佬和菜鸡们两极分化的越来越严重. 为了让菜鸡们不太拖大 佬的后腿, 于是大佬们针对一些经典的常见的场景, 给定了一些对应的解决方案, 这个就是 设计模式。单例模式是一种 "经典的, 常用的, 常考的" 设计模式
4.1.单例模式的特点
4.2.饿汉实现方式和懒汉实现方式
- 吃完饭, 立刻洗碗, 这种就是饿汉方式. 因为下一顿吃的时候可以立刻拿着碗就能吃饭.
- 吃完饭, 先把碗放下, 然后下一顿饭用到这个碗了再洗碗, 就是懒汉方式.
- 懒汉方式最核心的思想是 "延时加载". 从而能够优化服务器的启动速度
4.2.1.饿汉方式实现单例模式
template <typename T>
class Singleton
{
static T data;//直接创建称为静态的,再mian函数还没调用之前就创建好了。
public:
static T *GetInstance()//创建也是直接返回
{
return &data;
}
};
//只要通过 Singleton 这个包装类来使用 T 对象, 则一个进程中只有一个 T 对象的实例.4.2.2.懒汉方式实现单例模式
template <typename T>
class Singleton
{
static T *inst;//先创建一个指针,用的时候再创建,先不创建。
//一般多线程再同时访问 inst的时候还需要对inst进行加锁。
//不加锁可能会出现问题。
public:
static T *GetInstance()
{
if (inst == NULL)
{
inst = new T();
}
return inst;
}
};template <typename T>
class Singleton
{
volatile static T *inst; // 需要设置 volatile 关键字, 否则可能被编译器优化.
static std::mutex lock;
public:
static T *GetInstance()
{
if (inst == NULL)
{ // 双重判定空指针, 降低锁冲突的概率, 提高性能.
lock.lock(); // 使用互斥锁, 保证多线程情况下也只调用一次 new.
if (inst == NULL)
{
inst = new T();
}
lock.unlock();
}
return inst;
}
}注意事项:1. 加锁解锁的位置2. 双重 if 判定, 避免不必要的锁竞争。3. volatile关键字防止过度优化。
5.单例模式的线程池(懒汉)
直接上代码:gtiee链接
#pragma once
#include <iostream>
#include <vector>
#include <queue>
#include <pthread.h>
#include "thread.hpp"
#include "lockguard.hpp"
#include <mutex> //c++ 中也有锁的概念
using namespace ThreadNS;
#define NUM 15
template <class T>
class ThreadPool;
template <class T>
class ThreadData
{
public:
ThreadData(ThreadPool<T> *tpthis, std::string threadname)
: _tpthis(tpthis), _threadname(threadname)
{
}
ThreadPool<T> *_tpthis;
std::string _threadname;
};
template <class T>
class ThreadPool
{
private:
int _num;
std::vector<Thread *> _threads; // 保存创建的线程
std::queue<T> _task_queue; // 保存任务列表
pthread_mutex_t _mutex; // 保护任务队列
pthread_cond_t _cond; // 线程阻塞的条件变量
// 单例
static ThreadPool<T> *_ptp;
// 这里的静态指针是,公共资源,在多线程访问的时候可能会出问题,因为后面多线程会对他进行判断。
// 所以需要对他进行加锁
static std::mutex _cpplock; // c++的锁
private:
static void *handlertask(void *args)
{
// sleep(3);
// std::cout<<(args)<<std::endl;
ThreadData<T> *data = static_cast<ThreadData<T> *>(args);
while (true)
{
// data->_tpthis->lockqueue();
T t;
{
LockGuard lock(data->_tpthis->getmutex());
while (data->_tpthis->queueempty())
{
data->_tpthis->waitthread();
}
t = data->_tpthis->queuepop();
}
// data->_tpthis->unlockqueue();
std::cout << data->_threadname << "处理任务:" << t() << std::endl;
}
delete data;
return nullptr;
}
void lockqueue()
{
pthread_mutex_lock(&_mutex);
}
void unlockqueue()
{
pthread_mutex_unlock(&_mutex);
}
bool queueempty()
{
return _task_queue.empty();
}
void waitthread()
{
pthread_cond_wait(&_cond, &_mutex);
}
T queuepop()
{
// 这个是内部接口
// 不用加锁,因为在锁内部调用。
T ret = _task_queue.front();
_task_queue.pop();
return ret;
}
void signalthread()
{
pthread_cond_signal(&_cond);
}
pthread_mutex_t *getmutex()
{
return &_mutex;
}
ThreadPool(int num = NUM)
: _num(num)
{
pthread_mutex_init(&_mutex, nullptr);
pthread_cond_init(&_cond, nullptr);
for (int i = 0; i < _num; ++i)
{
Thread *tp = new Thread();
_threads.push_back(tp);
}
}
void operator=(const ThreadPool<T> &) = delete;
ThreadPool(const ThreadPool<T> &) = delete;
public:
void start()
{
for (auto &e : _threads)
{
ThreadData<T> *data = new ThreadData<T>(this, e->getname());
e->start(handlertask, (void *)data);
// std::cout<<e<<" thread start.."<<std::endl;
}
}
void push(T in)
{
// lockqueue();
LockGuard lock = getmutex();
_task_queue.push(in);
std::cout << "收到任务:" << in.totaskstring() << std::endl;
signalthread();
// unlockqueue();
}
~ThreadPool()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_cond);
for (auto &e : _threads)
{
e->join();
delete e;
}
}
// 单例
static ThreadPool<T> *getinstance(int num = NUM)
{
if (_ptp == nullptr)//加上这个可以在对象创建完毕之后,不用再加锁判断即可返回。
{
_cpplock.lock(); // c++的加锁
if (_ptp == nullptr)
{
_ptp = new ThreadPool<T>(num);
}
_cpplock.unlock(); // c++的解锁
}
return _ptp;
}
};
// 模板中静态成员的初始化
template <class T>
ThreadPool<T> *ThreadPool<T>::_ptp = nullptr;
template <class T>
std::mutex ThreadPool<T>::_cpplock;
///
6.STL,智能指针和线程安全
6.1.STL中的容器是否是线程安全的?
不是.原因是, STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响.而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶). 因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全.
6.2.智能指针是否是线程安全的?
对于 unique_ptr, 由于只是在当前代码块范围内生效, 因此不涉及线程安全问题.对于 shared_ptr, 多个对象需要共用一个引用计数变量, 所以会存在线程安全问题. 但是标准库实现的时候考虑到了这 个问题, 基于原子操作(CAS)的方式保证 shared_ptr 能够高效, 原子的操作引用计数.
7. 其他常见的各种锁
- 悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
- 乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前, 会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
- CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不 等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
- 自旋锁,公平锁,非公平锁?
7.1.自旋锁
以前我们学习到互斥锁(mutex),信号量,都是挂起等待锁,当条件不满足的时候在系统级别线程直接挂起等待了。自旋锁是,线程不会挂起等待,而是不停的去申请锁,一直轮询的去等待锁。
一般锁会分为两种: 一是挂起等待,二是自旋(轮询)。到底是挂起还是自旋,是由等待时间决定的,要等待时间很长的时候,建议挂起等待,等待时间很短的时候,建议轮询。
目前使用的大部分都是挂起等待锁。自旋锁很少用。消耗太大。
1. 销毁自旋锁
int pthread_spin_destroy(pthread_spinlock_t * lock);
2. 初始化自旋锁
int pthread_spin_init(pthread_spinlock_t * lock, int pshared);
3. 自旋锁上锁(阻塞)
int pthread_spin_lock(pthread_spinlock_t * lock);
4. 自旋锁上锁(非阻塞)
int pthread_spin_trylock(pthread_spinlock_t * lock);
5. 自旋锁解锁
int pthread_spin_unlock(pthread_spinlock_t * lock);
以上函数成功都返回0.
pthread_spin_init函数的pshared参数表示进程共享属性,表明自旋锁是如何获取的,如果它设为PTHREAD_PROCESS_SHARED,则自旋锁能被可以访问锁底层内存的线程所获取,即使那些线程属于不同的进程(进程之间互斥)。否则pshared参数设为PTHREAD_PROCESS_PRIVATE,自旋锁就只能被初始化该锁的进程内部的线程访问到(线程之间互斥)。
如果自旋锁当前在解锁状态,pthread_spin_lock函数不要自旋就可以对它加锁,试图对没有加锁的自旋锁进行解锁,结果是未定义的。需要注意,不要在持有自旋锁情况下可能会进入休眠状态的函数,如果调用了这些函数,会浪费CPU资源,其他线程需要获取自旋锁需要等待的时间更长了。
- pthread_spin_lock()函数锁定lock所指的旋转锁。如果当前未锁定旋转锁,则调用线程将立即获取该锁。如果旋转锁当前被另一个线程锁定,则调用线程旋转,测试该锁直到可用为止,此时调用线程获取该锁。
- 在调用者已经持有的锁上或未通过pthread_spin_init(3)初始化的锁上调用pthread_spin_lock()会导致未定义的行为。
- pthread_spin_trylock()函数与pthread_spin_lock()相似,不同之处在于,如果当前锁定由锁引用的自旋锁,则该调用将立即返回错误EBUSY,而不是旋转。
- pthread_spin_unlock()函数可将称为锁的自旋锁解锁。如果有任何线程在该锁上旋转,则这些线程之一将获取该锁。
- 在调用者未持有的锁上调用pthread_spin_unlock()会导致未定义的行为。
实例:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <dirent.h>
#include <stdlib.h>
#include <pthread.h>
pthread_spinlock_t spinlock;
int data;
/*
线程工作函数
*/
void *thread_work_func(void *dev)
{
while(1)
{
pthread_spin_lock(&spinlock); //上锁
printf("data=%d\n",data);
pthread_spin_unlock(&spinlock); //解锁
sleep(1);
}
}
/*
线程工作函数
*/
void *thread_work_func2(void *dev)
{
while(1)
{
pthread_spin_lock(&spinlock); //上锁
data++;
pthread_spin_unlock(&spinlock); //解锁
sleep(1);
}
}
int main(int argc,char **argv)
{
//初始化自旋锁
pthread_spin_init(&spinlock,PTHREAD_PROCESS_PRIVATE);
/*1. 创建子线程1*/
pthread_t thread_id;
if(pthread_create(&thread_id,NULL,thread_work_func,NULL)!=0)
{
printf("子线程1创建失败.\n");
return -1;
}
/*2. 创建子线程2*/
pthread_t thread_id2;
if(pthread_create(&thread_id2,NULL,thread_work_func2,NULL)!=0)
{
printf("子线程2创建失败.\n");
return -1;
}
/*3. 等待线程的介绍*/
pthread_join(thread_id,NULL);
pthread_join(thread_id2,NULL);
//销毁自旋锁
pthread_spin_destroy(&spinlock);
return 0;
}8.读者写者问题

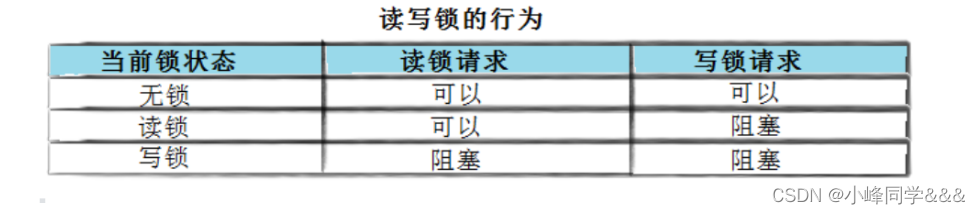
注意:写独占,读共享,读锁优先级高
接口:
设置读写优先
// 写优先
pthread_rwlockattr_t attr;
pthread_rwlockattr_init(&attr);
pthread_rwlockattr_setkind_np(&attr, PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP);
int pthread_rwlockattr_setkind_np(pthread_rwlockattr_t *attr, int pref);
/*
pref 共有 3 种选择
PTHREAD_RWLOCK_PREFER_READER_NP (默认设置) 读者优先,可能会导致写者饥饿情况
PTHREAD_RWLOCK_PREFER_WRITER_NP 写者优先,目前有 BUG,导致表现行为和
PTHREAD_RWLOCK_PREFER_READER_NP 一致
PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP 写者优先,但写者不能递归加锁
*/
//读优先
pthread_rwlock_init(&rwlock, nullptr);
读写锁初始化
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,const pthread_rwlockattr_t*restrict attr);
读写锁销毁
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
读写锁的加锁和解锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);//读者加锁
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);//写者加锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);//解锁的接口相同。案例:
#include <vector>
#include <sstream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <unistd.h>
#include <pthread.h>
volatile int ticket = 1000; // 抢票的票数
pthread_rwlock_t rwlock; // 定义读写锁
void *reader(void *arg)
{
char *id = (char *)arg;
while (1)
{
pthread_rwlock_rdlock(&rwlock);
if (ticket <= 0)
{
pthread_rwlock_unlock(&rwlock);
break;
}
printf("%s: %d\n", id, ticket);
pthread_rwlock_unlock(&rwlock);
usleep(1);
}
return nullptr;
}
void *writer(void *arg)
{
char *id = (char *)arg;
while (1)
{
pthread_rwlock_wrlock(&rwlock);
if (ticket <= 0)
{
pthread_rwlock_unlock(&rwlock);
break;
}
printf("%s: %d\n", id, --ticket);
pthread_rwlock_unlock(&rwlock);
usleep(1);
}
return nullptr;
}
struct ThreadAttr
{
pthread_t tid;
std::string id;
};
std::string create_reader_id(std::size_t i) // 给线程创建一个名字
{
// 利用 ostringstream 进行 string 拼接
std::ostringstream oss("thread reader ", std::ios_base::ate);
oss << i;
return oss.str();
}
std::string create_writer_id(std::size_t i) // 给线程创建一个名字
{
// 利用 ostringstream 进行 string 拼接
std::ostringstream oss("thread writer ", std::ios_base::ate);
oss << i;
return oss.str();
}
void init_readers(std::vector<ThreadAttr> &vec)
{
for (std::size_t i = 0; i < vec.size(); ++i)
{
vec[i].id = create_reader_id(i);
pthread_create(&vec[i].tid, nullptr, reader, (void *)vec[i].id.c_str());
}
}
void init_writers(std::vector<ThreadAttr> &vec)
{
for (std::size_t i = 0; i < vec.size(); ++i)
{
vec[i].id = create_writer_id(i);
pthread_create(&vec[i].tid, nullptr, writer, (void *)vec[i].id.c_str());
}
}
void join_threads(std::vector<ThreadAttr> const &vec)
{
// 我们按创建的 逆序 来进行线程的回收
for (std::vector<ThreadAttr>::const_reverse_iterator it = vec.rbegin(); it !=
vec.rend();
++it)
{
pthread_t const &tid = it->tid;
pthread_join(tid, nullptr);
}
}
void init_rwlock()
{
#if 1
// 写优先
pthread_rwlockattr_t attr;
pthread_rwlockattr_init(&attr);
pthread_rwlockattr_setkind_np(&attr, PTHREAD_RWLOCK_PREFER_WRITER_NONRECURSIVE_NP);
pthread_rwlock_init(&rwlock, &attr);
pthread_rwlockattr_destroy(&attr);
#else
// 读优先,会造成写饥饿
pthread_rwlock_init(&rwlock, nullptr);
#endif
}
int main()
{
// 测试效果不明显的情况下,可以加大 reader_nr
// 但也不能太大,超过一定阈值后系统就调度不了主线程了
const size_t reader_nr = 1000; // 定义读者数目
const size_t writer_nr = 2; // 定义写者数目
std::vector<ThreadAttr> readers(reader_nr); // 管理读者//初始化reader_nr个元素
std::vector<ThreadAttr> writers(writer_nr); // 管理写者//初始化writer_nr个元素
init_rwlock(); // 初始化读写锁
init_readers(readers); // 初始化读者数组(创建读者线程)
init_writers(writers); // 初始化写者数组(创建写者线程)
join_threads(writers); // 等待全部写者线程
join_threads(readers); // 等待全部读者线程
pthread_rwlock_destroy(&rwlock); // 销毁读写锁
}![[入门必看]数据结构6.1:图的基本概念](https://img-blog.csdnimg.cn/a8f4f62c6ba843308cb68f86c7f9e340.png#pic_center)