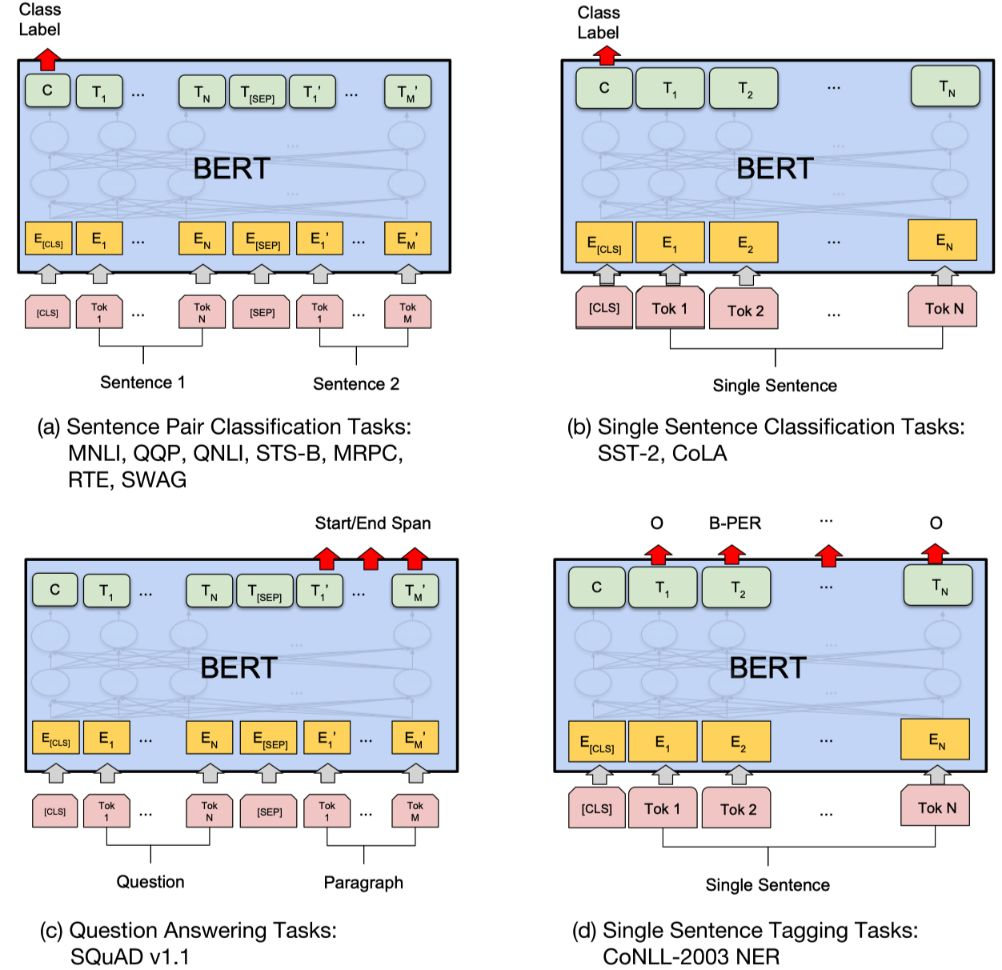
文章目录
- 前言
- 一、unordered_map的使用及性能测试
- 二、unordered_set的使用
- 1.习题练习
- 总结
前言
下面我们对比一下unordered_map和map的区别:
 看到这里大家发现了吧,其实他们的功能一模一样,只不过底层不一样。注意:map和set使用的是双向迭代器 unordered系列用的是单向迭代器
看到这里大家发现了吧,其实他们的功能一模一样,只不过底层不一样。注意:map和set使用的是双向迭代器 unordered系列用的是单向迭代器
map / set :的底层是红黑树
unordered_map / unordered_set :的底层是哈希表
为什么要设计他们俩呢?因为哈希的查找效率非常高!
下面我们进入使用环节:
一、unordered_map的使用
#include <unordered_map>
#include <unordered_set>
#include <iostream>
using namespace std;
void unordered_map_test()
{
unordered_map<string, int> ump;
ump.insert(make_pair("left", 1));
ump.insert(make_pair("right", 2));
ump.insert(make_pair("string", 3));
ump.insert(make_pair("list", 4));
ump.insert(make_pair("list", 5));
for (auto& e : ump)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
unordered_map<string, int>::iterator it = ump.begin();
while (it != ump.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
}
int main()
{
unordered_map_test();
}我们可以看到unordered的使用方法简直和map一模一样,都是重复的数据不会被插入,当然也有支持重复数据插入的unordered_multimap系列,那么主要区别在哪里呢?我们来看看:

可以看到最主要的区别是unordered系列是无序的,下面我们给出map和unordered系列的性能测试:
void unordered_map_test2()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
v.push_back(rand());
//v.push_back(rand()+i);
//v.push_back(i);
}
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : v)
{
s.find(e);
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << endl;
size_t begin4 = clock();
for (auto e : v)
{
us.find(e);
}
size_t end4 = clock();
cout << "unordered_set find:" << end4 - begin4 << endl << endl;
cout << s.size() << endl;
cout << us.size() << endl << endl;;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
} 
先从10000个随机数为例:
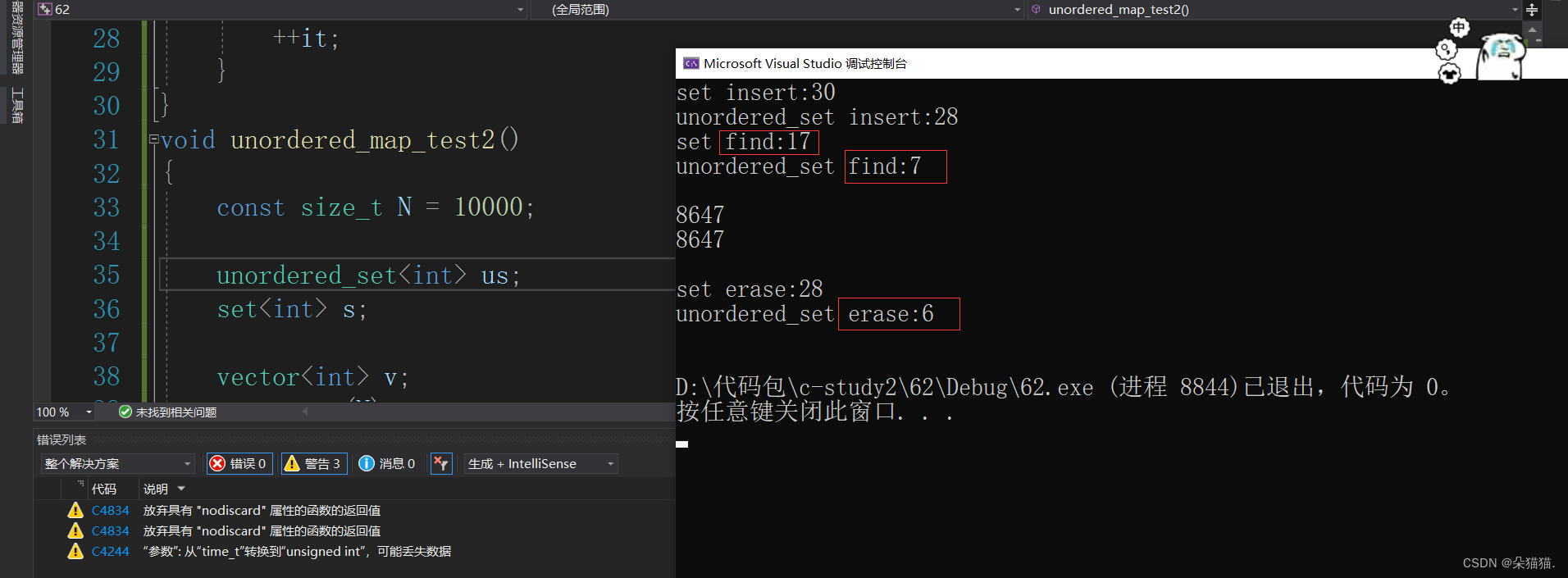 我们可以看到哈希系列的各项功能都比普通的快,下面我们来100000个随机数对比一下:
我们可以看到哈希系列的各项功能都比普通的快,下面我们来100000个随机数对比一下:
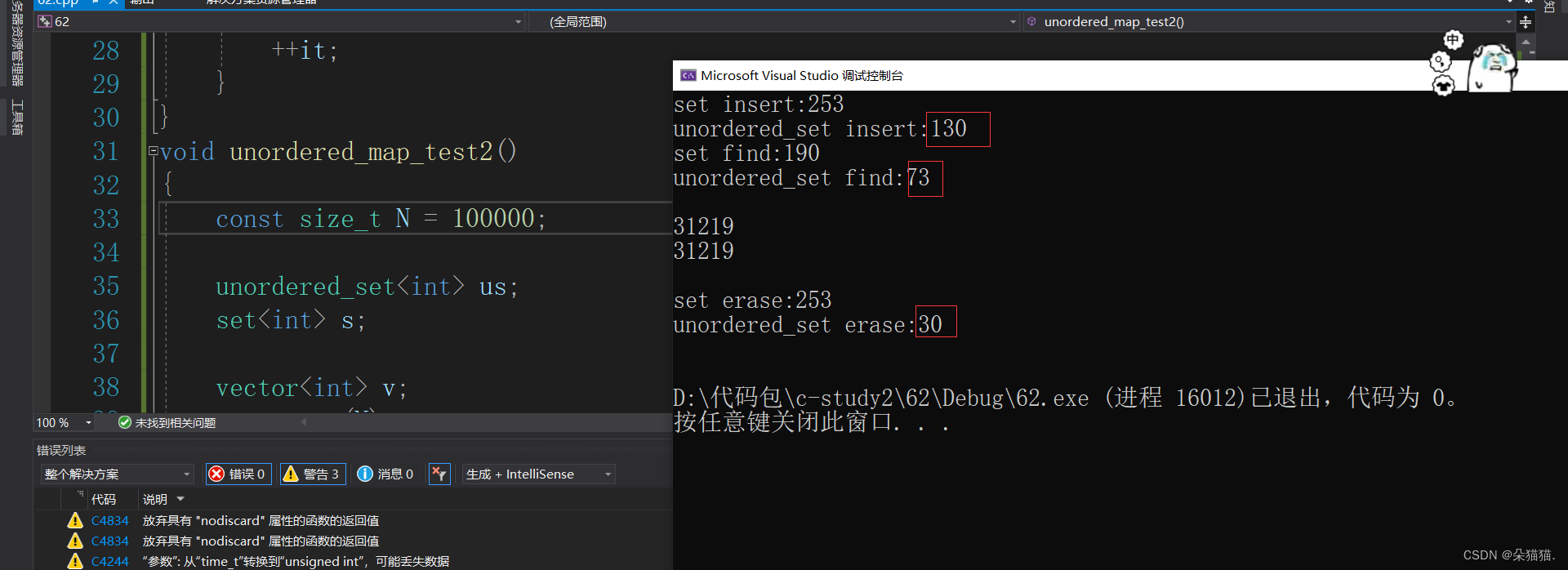
可以看到还是unordered系列更快,再来1000000个:
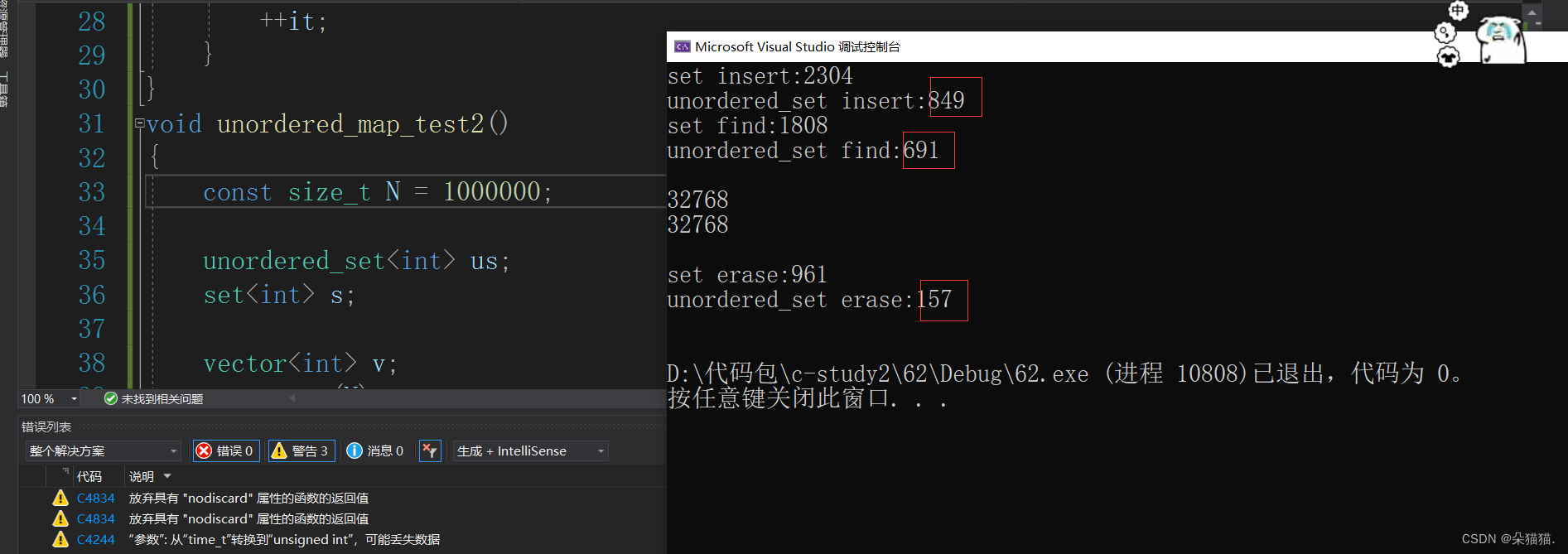
从以上的结果可以看出来为什么c++会新增哈希系列了,下面是另一台机器测出的数据:

总结:综合各种场景而言,unordered系列综合性能是更好的,尤其是find更是一骑绝尘。
二、unordered_set的使用
同样我们先看看set和哈希set有没有功能的不同:

还是我们之前说的,set是双向迭代器哈希系列是单向迭代器,除了迭代器有区别其他功能几乎都是一样的,下面我们演示一下基础功能如何使用:
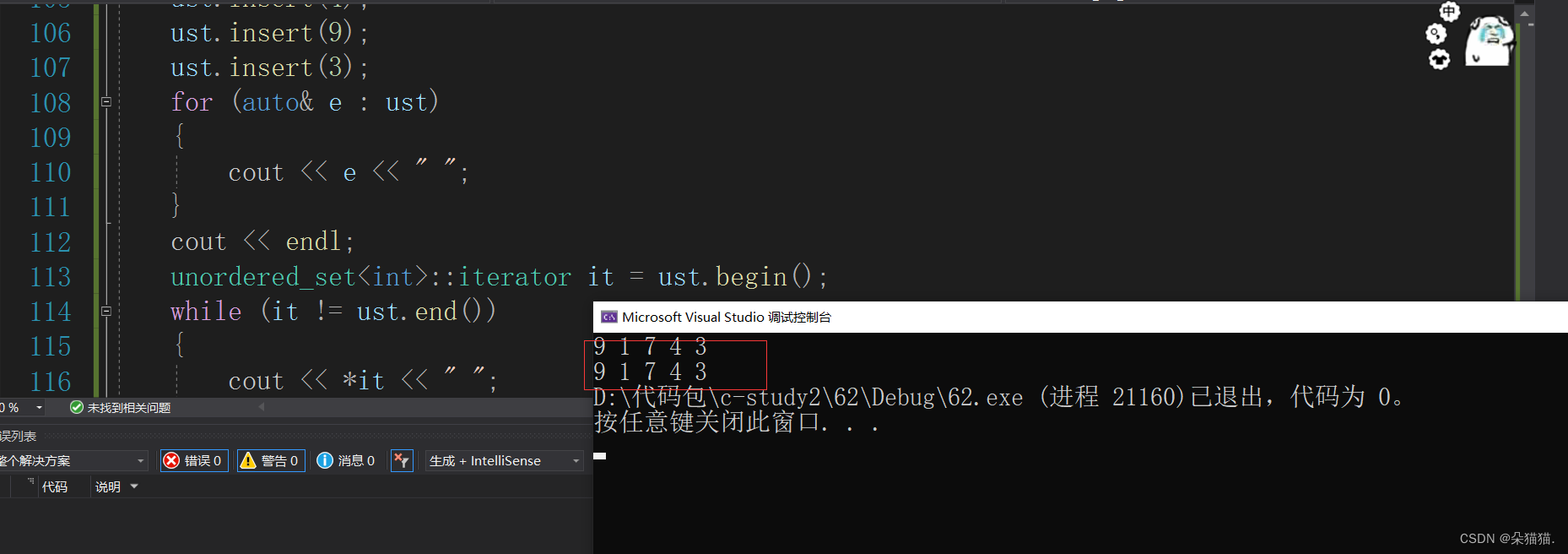
void unordered_set_test()
{
unordered_set<int> ust;
ust.insert(1);
ust.insert(7);
ust.insert(4);
ust.insert(9);
ust.insert(3);
for (auto& e : ust)
{
cout << e << " ";
}
cout << endl;
unordered_set<int>::iterator it = ust.begin();
while (it != ust.end())
{
cout << *it << " ";
++it;
}
}
int main()
{
unordered_set_test();
}
习题练习:
同样与set的区别是无序的,以上就是所有内容哈希系列的使用,下面我们用哈希系列练习一道题:
两个数的交集I:
力扣链接:力扣

交集只需要找出两个数组相同的元素就可以了,而且题目告诉了我们每个元素都是唯一的所以不存在重复元素.
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> us1(nums1.begin(),nums1.end());
unordered_set<int> us2(nums2.begin(),nums2.end());
vector<int> v;
for (auto& e:us1)
{
if (us2.find(e)!=us2.end())
{
v.push_back(e);
}
}
return v;
}
};首先我们将两个数组的数分别放入哈希set中,然后我们遍历第一个哈希set(也可以遍历第二个都是一样的),然后我们让第二个哈希set查找第一个哈希set中的值,如果找到了就说明这个数是交集就放到数组中,然后最后返回数组即可。
总结
哈希系列的容器与之前的容器用法几乎都是一样的,经常使用STL容器更容易上手,下一篇我们讲解哈希表的底层原理并且实现,所以要想实现底层还是需要知道人家这个容器是如何使用的你才能实现出功能。