出品人:Towhee 技术团队 作者:张晨
DragGAN介绍
合成满足用户需求的视觉内容往往需要对生成对象的姿势、形状、表情和布局进行灵活和精确的控制。 现有方法通过手动注释的训练数据或先前的 3D 模型获得生成对抗网络 (GAN) 的可控性,这通常缺乏灵活性、精确性和通用性。 这项工作研究了一种强大但探索较少的控制 GAN 的方法,即以用户交互的方式“拖动”图像的任何点以精确到达目标点,如下图所示。 为实现这一目标,本文提出了 DragGAN,通过 DragGAN,任何人都可以通过精确控制像素的位置对图像进行变形,从而操纵动物、汽车、人类、风景等不同类别的姿势、形状、表情和布局。定性和定量比较都证明了 DragGAN 在图像处理和点跟踪任务中优于先前方法的优势。

DragGAN 允许用户“拖动”任何 GAN 生成图像的内容。 用户只需点击图像上的几个handle点(红色)和目标点(蓝色),就可以移动 handle 点以精确到达其对应的目标点。 用户可以选择绘制灵活区域(较亮区域)的 mask,保持图像的其余部分固定。 这种灵活的基于点的操作可以控制许多空间属性,如姿势、形状、表情和跨不同对象类别的布局。
运动监督和handle跟踪
DragGAN包含了两个子操作:
-
基于特征的运动监督,驱动handle点向目标位置移动, -
一种新的点跟踪方法,利用判别生成器特征来保持定位handle点的位置。
理论上,GAN 的特征空间具有足够的判别性,可以实现运动监督和精确点跟踪。 具体来说,运动监督是通过优化隐空间编码(latent code)的偏移 patch loss 来实现的。 每个优化步骤都会使得 handle 点更接近目标; 然后通过特征空间中的最近邻搜索来执行 handle 点跟踪。 重复此优化过程,直到 handle 点达到目标。 DragGAN 还允许用户有选择地绘制感兴趣的区域以执行特定于区域的编辑。 由于 DragGAN 不依赖任何额外的网络,它实现了高效的操作,在大多数情况下在比如单个 RTX 3090 GPU 上只需要几秒钟。 这允许进行实时的交互式编辑会话,用户可以在其中快速迭代不同的布局,直到获得所需的输出。
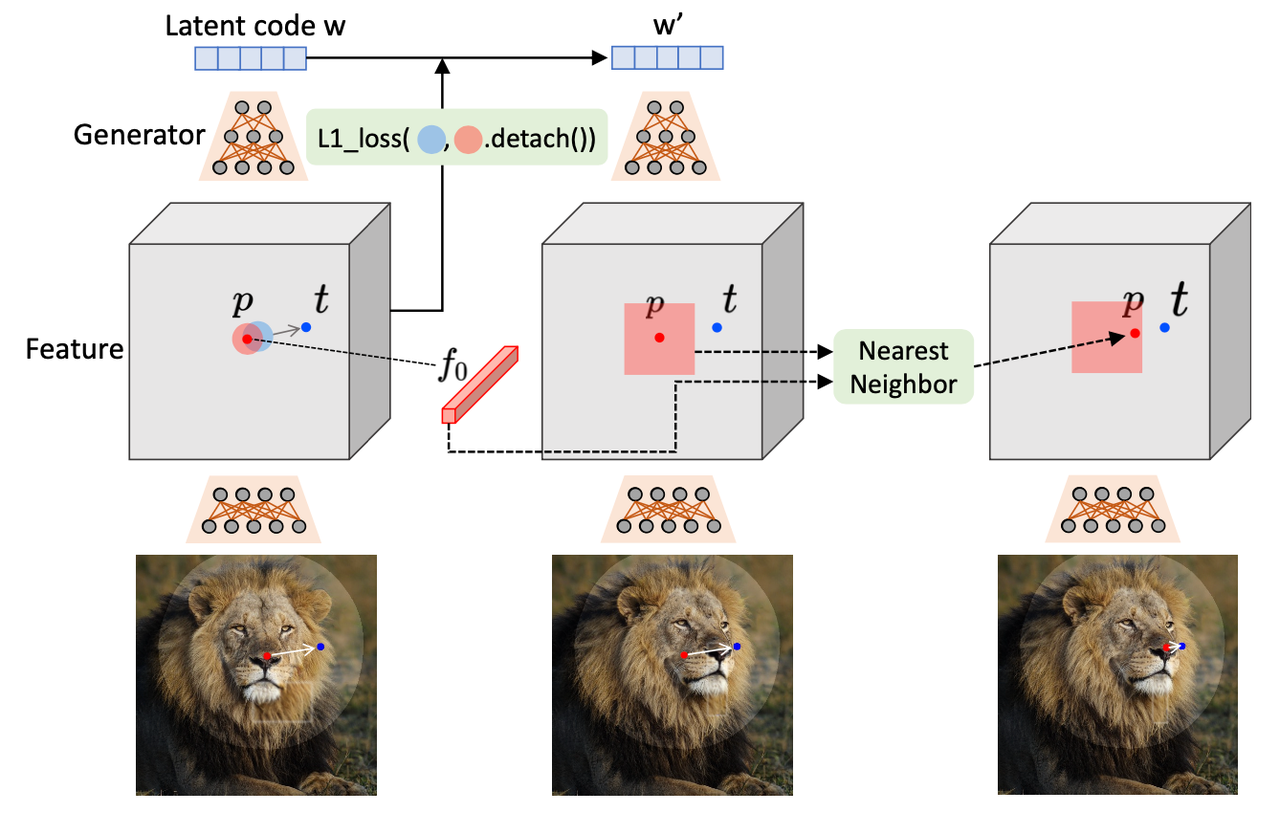
-
运动监督是通过生成器特征图上的偏移patch loss来实现的。图中红圈patch和蓝圈patch之间的差异,对于latent code求导,可以得到新的latent code w'。图中红patch后加了".detach()",意思就是它是原图,是不变的,而蓝patch是通过新latent code出来的可变量,所以是通过它反传梯度。
-
通过最近邻搜索对同一特征空间进行handle点跟踪。图中是中间那个图,在正方形区域内最近邻搜索原来p点的特征f0,于是可以搜索到新的位置p,即完成跟踪。这么做的原理是,GAN 的特征具有判别性,能很好地捕获了密集的对应关系,因此可以通过特征块中的最近邻搜索有效地执行跟踪。
遮罩(mask)的用处

将狗的头部区域遮盖后,其余部分几乎没有变化。 Mask 可以在交互时,确定图像中确定图像中的可变区域,这样可以消除歧义,让用户做到更加精准的控制。
总结
DragGAN是一种用于直观的基于点的图像编辑的交互式方法。 方法利用预训练的 GAN 来合成图像,这些图像不仅能精确地遵循用户输入,而且还能保持真实图像的多样性。 与许多以前的方法相比,本文通过不依赖特定领域的建模或辅助网络来呈现一个通用框架。 这是通过使用两个主要步骤来实现的:一是 latent code 的优化,它可以进行运动监督,将 handle 点移向其目标位置,二是一个点跟踪方法,它有效地跟踪 handle 点的轨迹。 作者未来计划将基于点的编辑扩展到3D生成模型。
相关资料:
-
官网展示:https://vcai.mpi-inf.mpg.de/projects/DragGAN/ -
论文链接:https://arxiv.org/abs/2305.10973 -
代码地址:https://github.com/XingangPan/DragGAN(官方版本,计划6月开源),https://github.com/Zeqiang-Lai/DragGAN(非官方版本)
本文由 mdnice 多平台发布