论文来源:ACL2022
论文地址:https://aclanthology.org/2022.acl-demo.10.pdf
论文代码:https://github.com/thunlp/OpenPrompt
笔记仅供参考,撰写不易,请勿恶意转载抄袭!
Abstract
目前,还没有标准的提示学习实现框架,而且大多数现有的的提示学习代码库,仅在特定场景提供有限的实现。在提示学习中,由于需要考虑模板策略、初始化策略和表达器策略等诸多细节。实践者在快速调整所需的提示学习方法以适应其应用方面面临着障碍。在本文中,介绍了OpenPrompt,统一的易于使用的工具包,用于在PLMs上进行快速学习。OpenPrompt具有效率、模块化和可扩展性,其可组性允许在统一的范式中自由组合不同的PLMs、任务格式和提示模块。用户可以方便地部署提示学习框架,并对其在不同NLP任务上的泛化性进行评估,不受约束。
Introduction
提示学习问题可以视为PLMs、人类先验知识和需要处理的特定的NLP任务的综合。
存在的问题:
1. 当前的深度学习或NLP库很难很好的支持提示学习的特定实现,同时也缺乏一个标准的范式。以往的研究为了追求最有效的方法来实现提示学习,对现有的传统微调框架进行了最少的修改,导致可读性差,甚至可复现性不稳定。
2. 提示学习的性能随着模板和表达器的选择而变化很大,为实现带来了更多障碍。
3. 目前还没有专门为提示学习而设计的综合开源框架,这使得很难尝试新方法并与之前的方法进行严格比较。
贡献:介绍了一个开源、易用、可扩展的提示学习工具包,OpenPrompt。
OpenPrompt将提示学习的整个框架模块化,并考虑每个模块之间的交互。强调了OpenPrompt的可组性,它支持多种任务格式、PLMs和提示模板的灵活组合。该特点使用户能够在各种任务上评估其提示学习模型的通用性,且不仅仅是在特定任务上的表现。

Design and Implementation
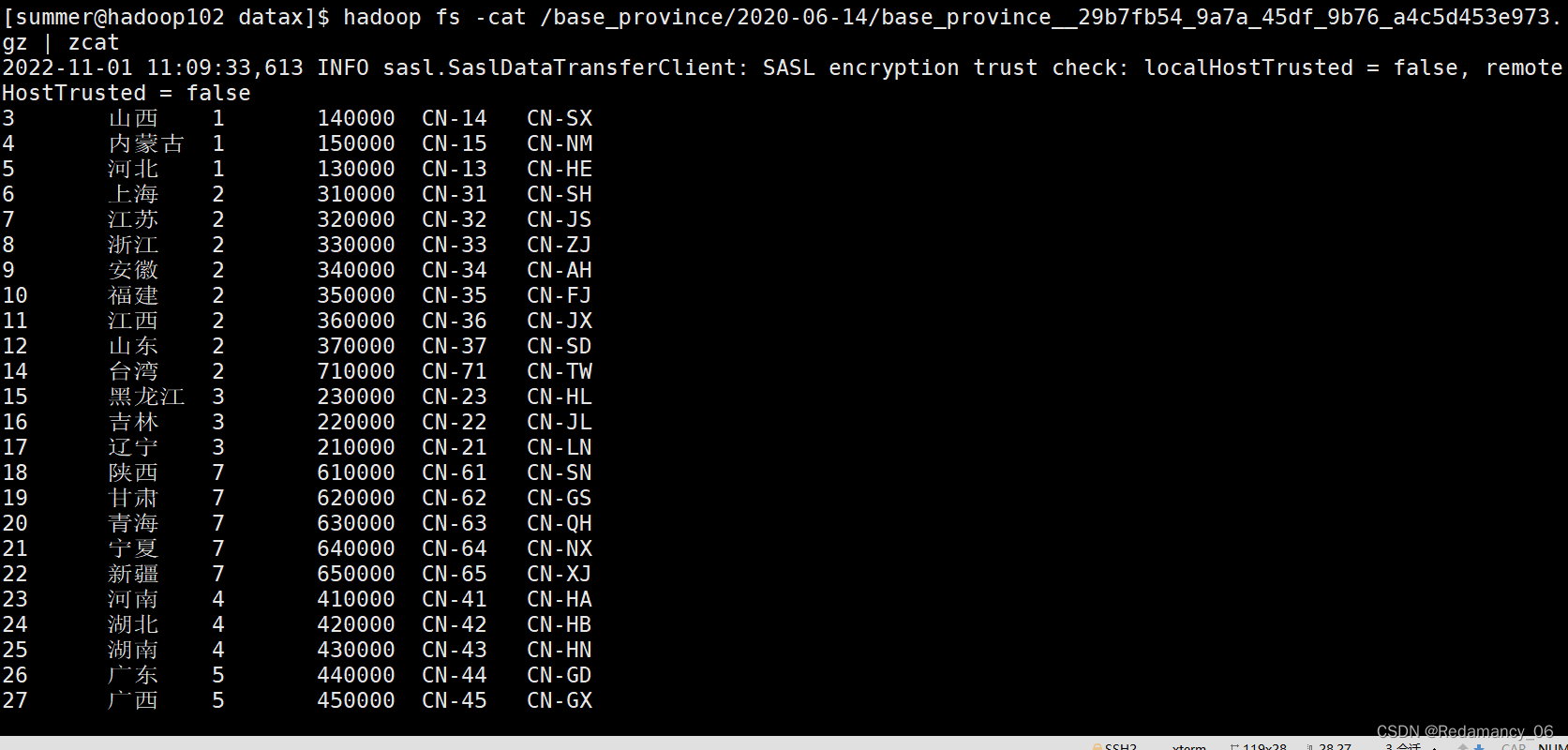
如 Figure 1所示,OpenPrompt提供了基于Pytorch的提示学习的完整生命周期。本节首先介绍OpenPrompt的可组性,然后详细介绍了OpenPrompt中每个组件的设计与实现。
Combinability(可组性)
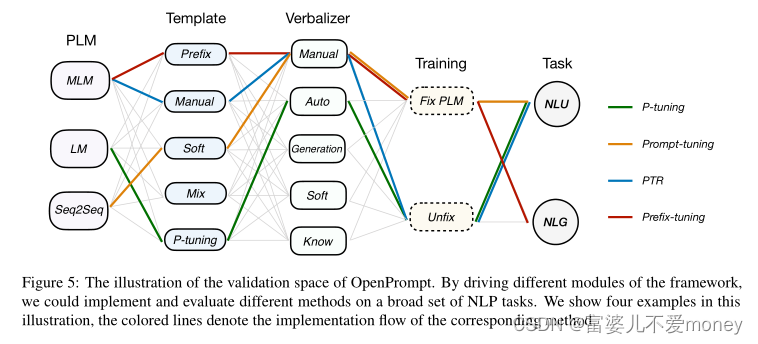
OpenPrompt支持task、PLMs和提示模块的灵活组合。例如,从模型的角度来看,T5不只用于跨度预测,GPT不只用于生成任务。从提示的角度来看,还可以使用prefix-tuning进行分类,使用软提示进行生成。在OpenPrompt框架中,这些组合都可以很容易的在NLP任务上实现和验证,这样可以更好地理解所涉及的机制。
Pre-trained Language Models
提示学习的一个核心思想是使用附加的带有[MASK]的上下文来模仿PLMs的预训练目标,并更好刺激这些模型。因此,PLMs的选择对提示学习的整个流程至关重要。PLMs可以根据预训练目标大致分为3组。
第1组PLMs使用MLM来重构被随机mask的序列,只计算mask部分的损失,包括BERT、RoBERTa等。第2组利用自回归式语言模型(LM)根据其前导tokens来预测当前token,包括GPT3。第3组是seq2seq模型,包括T5、MASS和BART等。
Tokenization
在设计模板之后,对原始输入和设计的模板的字符化的特定实现可能很耗时并且容易出错。首先,在提示学习中,tokenization应该小心处理一些特定的信息,如实体索引、被mask的token,一些小的错误可能会导致严重的后果。此外,还应该处理tokenization之后的连接和截断问题。由于不同的PLMs可能有不同的tokenization策略,还应该考虑额外上下文处理细节中的不一致性。
本文专门为提示学习设计了tokenization模块,极大地简化了过程。通过使用封装的数据处理APIs,用户可以使用可读的风格来设计模板,并方便地同时对输入和模板进行操作。基于PLMs的选择,OpenPrompt自动选择合适的tokenization,可以为用户节省大量处理提示相关数据的时间。
Templates
先前的工作设计了各种各样的模板,但是由于使用中需要很高的学习成本,因此为每个提示设计一个模板是不合理的。在OpenPrompt中,设计了一种模板语言来解决这一问题,用此模板语言可以在统一的范式下构造各种类型的模板。模板语言借鉴了python的字典语法。这样的设计同时保证了灵活性和清晰度。Figure 2中展示了一些模板示例。

Verbalizers
当PLMs预测到一个mask位置在词汇表上的概率分布的时候,表达器将提取标签词的logit,并将标签词的logit集成到相应的类中,从而负责损失计算。如Figure 3为定义情感分类语言表达器的一个简单方法。(也就是说,表达器用来将预测的标签词映射到相应的类)

与模板类似,所有的语言表达器类也从具有必要属性和抽象方法的公共基类继承而来。除了手工构建的语言表达器,OpenPrompt中还实现了自动生成语言表达器、知识表达器。
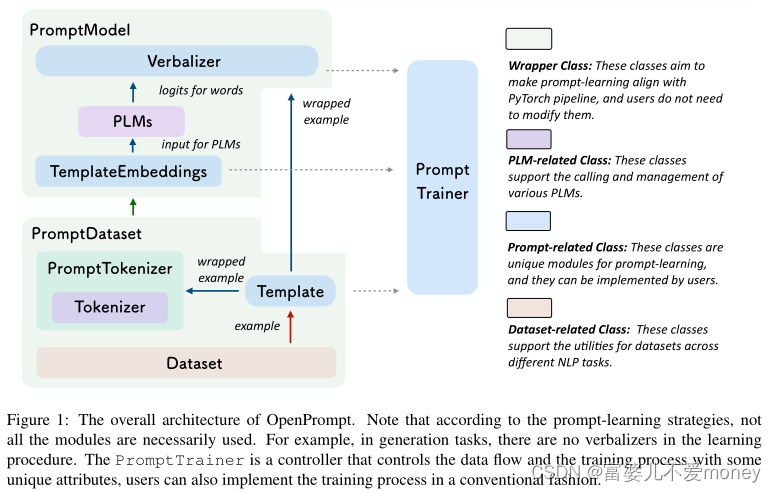
PromptModel
在OpenPrompt中,使用了一个PromptModel对象来负责训练和推理,它包含一个PLM、一个Template对象和一个Verbalizer对象(可选)。用户可以灵活地组合这些模块并定义它们之间的高级交互。 PromptModel如Figure 6所示。

Training
提示学习的训练可分为两种策略:① 同时调整提示和PLM,这在低数据环境下是有效的;②只训练提示的参数,PLM保持不变。这两种策略都可以在OpenPrompt的Trainer模板中一键调用。
Evaluation
本文使用OpenPrompt来实现各种基线,并在相应的NLP任务上评估它们。
下面介绍使用OpenPrompt 的一个简单demo:
# step1:确定NLP任务,情感分析
import torch
from openprompt.data_utils import InputExample
#确定类别,即数据标签:positive,negative
classes = [ # There are two classes in Sentiment Analysis, one for negative and one for positive
"negative",
"positive"
]
#确定数据集
dataset = [ # For simplicity, there's only two examples
# text_a is the input text of the data, some other datasets may have multiple input sentences in one example.
InputExample(
guid = 0,
text_a = "Albert Einstein was one of the greatest intellects of his time.",
),
InputExample(
guid = 1,
text_a = "The film was badly.",
),
]
# step 2确定PLMs
from openprompt.plms import load_plm
plm, tokenizer, model_config, WrapperClass = load_plm("bert", "PLMmodel/bert-base-cased") #PLMs
#step3 定义模板
from openprompt.prompts import ManualTemplate #人工构建模板
promptTemplate = ManualTemplate(
text = '{"placeholder":"text_a"} It was {"mask"}',
tokenizer = tokenizer,
)
#step4 答案映射
from openprompt.prompts import ManualVerbalizer #人工构建的语言表达器
promptVerbalizer = ManualVerbalizer(
classes = classes,
label_words = {
"negative": ["bad"],
"positive": ["good", "wonderful", "great"],
},
tokenizer = tokenizer,
)
#step 5 构造PromptModel,PLM、模板、verbalizer
from openprompt import PromptForClassification
promptModel = PromptForClassification(
template = promptTemplate,
plm = plm,
verbalizer = promptVerbalizer,
)
#step 6 构造PromptDataLoader
from openprompt import PromptDataLoader
data_loader = PromptDataLoader(
dataset=dataset,
tokenizer=tokenizer,
template=promptTemplate,
tokenizer_wrapper_class=WrapperClass,
)
# step 7 预测
# making zero-shot inference using pretrained MLM with prompt
promptModel.eval()
with torch.no_grad():
for batch in data_loader:
logits = promptModel(batch)
preds = torch.argmax(logits, dim=-1)
print(classes[preds])
# predictions would be 1, 0 for classes 'positive', 'negative'
输出结果:
![]()




![[附源码]计算机毕业设计JAVA校园求职与招聘系统](https://img-blog.csdnimg.cn/dead6759e4024606b7e2251afc49f73c.png)