title: Flink系列
二、Flink Source 整理和实战
Flink Source 是程序的数据源输入,可以通过 StreamExecutionEnvironment.addSource(sourceFunction) 来为你的程序添加一个 Source。
Flink 提供了大量的已经实现好的 source 方法,也可以自定义 source:
1、通过实现 sourceFunction 接口来自定义无并行度的 source
2、通过实现 ParallelSourceFunction 接口 or 继承 RichParallelSourceFunction 来自定义有并行度的 source
大多数情况下,我们使用自带的 source 即可。
2.1 Flink 内置 Source
关于 Flink 的内置 Source 大致可以分为这四类:
-
基于 File:readTextFile(path),读取文本文件,文件遵循 TextInputFormat 读取规则,逐行读取并返回。
-
基于数据集合:fromCollection(Collection),通过 java 的 collection 集合创建一个数据流,集合中的所有元素必须是相同类型的。
-
基于 Socket:socketTextStream(hostname,port),从 socker 中读取数据,元素可以通过一个分隔符切开。
-
扩展 Source:addSource() 方法可以实现读取第三方数据源的数据,系统内置提供了一批connectors,连接器会提供对应的 source,比如 Kafka,Pulsar 等
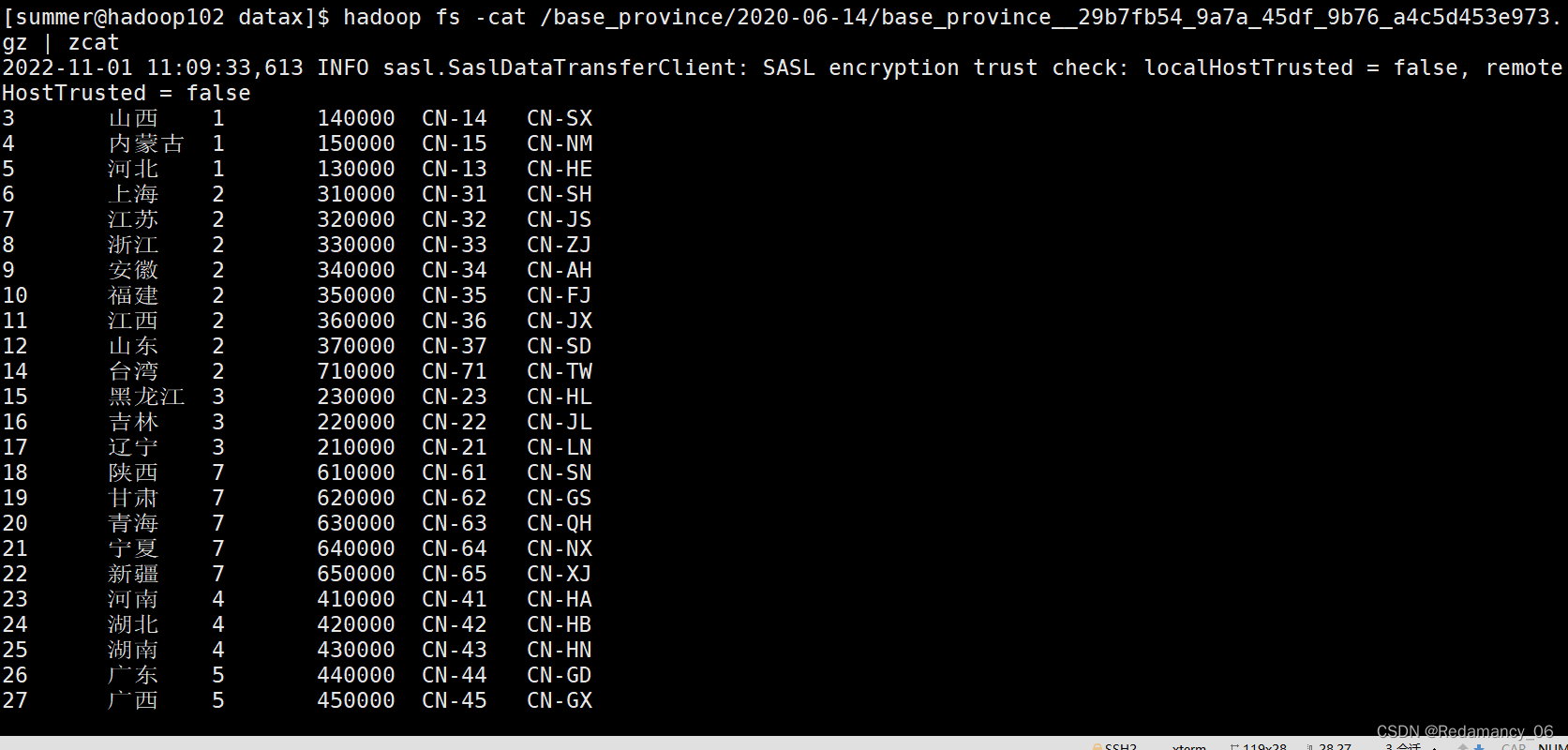
关于这四种类型的 Source 的使用,具体见程序
官网:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/overview/#bundled-connectors
官网截图:
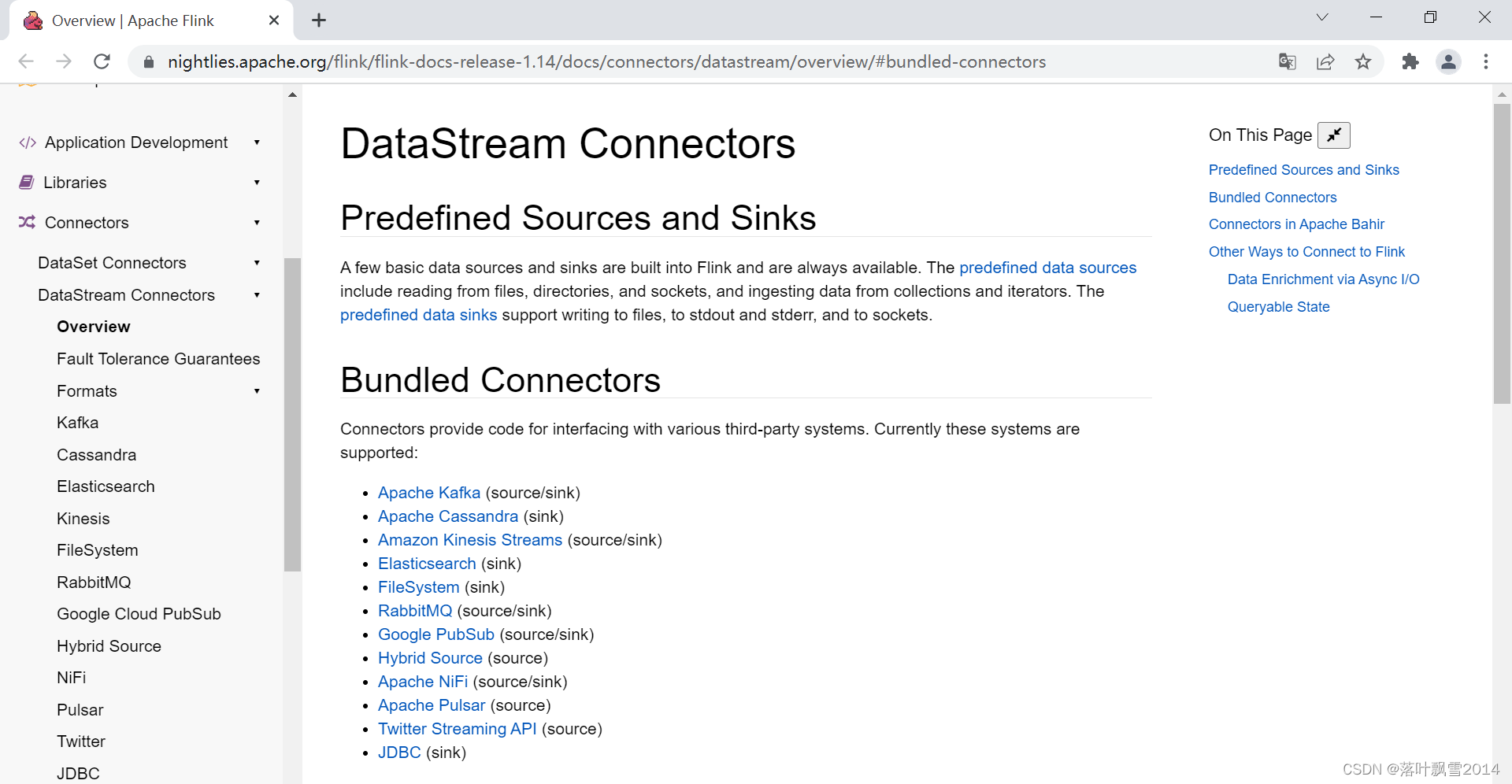
Connectors provide code for interfacing with various third-party systems. Currently these systems are supported:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- FileSystem (sink)
- RabbitMQ (source/sink)
- Google PubSub (source/sink)
- Hybrid Source (source)
- Apache NiFi (source/sink)
- Apache Pulsar (source)
- Twitter Streaming API (source)
- JDBC (sink)
2.1.0 flink程序pom文件添加
依赖如下:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.14.3</version>
</dependency>
</dependencies>
2.1.1 基于 File案例
FlinkSourceReadTextFile.java完整代码如下:
package com.aa.flinkjava.source.builtin;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
/**
* @Author AA
* @Date 2022/2/24 16:35
* @Project bigdatapre
* @Package com.aa.flinkjava.source.builtin
*/
public class FlinkSourceReadTextFile {
public static void main(String[] args) throws Exception {
//1、初始化环境变量
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//2、读取数据
DataSource<String> dataSource = executionEnvironment.readTextFile("D://input//test1.txt");
//3、打印输出
dataSource.print();
//4、执行
//异常:No new data sinks have been defined since the last execution.
// The last execution refers to the latest call to 'execute()', 'count()', 'collect()', or 'print()'.
//上面异常解决方案:Flink批处理的时候注释掉下面的代码即可。
//executionEnvironment.execute("FlinkSourceReadTextFile");
}
}
2.1.2 基于数据集合案例
FlinkSourceFromCollection.java完整代码如下:
package com.aa.flinkjava.source.builtin;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import java.util.ArrayList;
/**
* @Author AA
* @Date 2022/2/24 16:46
* @Project bigdatapre
* @Package com.aa.flinkjava.source.builtin
*/
public class FlinkSourceFromCollection {
public static void main(String[] args) throws Exception {
//1、初始化环境变量
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
//2、造点数据
ArrayList<String> list = new ArrayList<>();
list.add("zhangsan");
list.add("lisi");
list.add("wangwu");
list.add("zhaoliu");
//3、从数据集合读取数据
DataSource<String> dataSource = executionEnvironment.fromCollection(list);
//4、做一个小的业务逻辑
MapOperator<String, String> result = dataSource.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return s + " , 欢迎你!";
}
});
//5、打印输出
result.print();
//6、执行 注意,批处理场景下,给下面的依据注释掉。
//executionEnvironment.execute("FlinkSourceFromCollection");
}
}
2.1.3 基于 Socket 案例
FlinkSourceSocketTextStream.java 完整代码如下:
package com.aa.flinkjava.source.builtin;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Date 2022/2/24 16:53
* @Project bigdatapre
* @Package com.aa.flinkjava.source.builtin
*/
public class FlinkSourceSocketTextStream {
public static void main(String[] args) throws Exception {
//1、初始化环境变量
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//2、从socket读取数据
DataStreamSource<String> dataStreamSource = executionEnvironment.socketTextStream("hadoop12", 9999);
//3、业务逻辑处理
//3-1 转换给键值对
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
if (s.isEmpty()){
return; //给输入的是空的过滤掉。
}else {
String[] splits = s.split(" ");
for (String split : splits) {
collector.collect(new Tuple2<>(split, 1));
}
}
}
});
//3-2 累加
SingleOutputStreamOperator<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1);
//4、数据
result.print();
//5、提交执行
executionEnvironment.execute();
}
}
2.2 Flink 自定义 Source
样例UserDefineSourceDemo.java如下:
package com.aa.flinkjava.source.userdefine;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* @Author AA
* @Date 2022/2/24 17:15
* @Project bigdatapre
* @Package com.aa.flinkjava.source.userdefine
*/
public class UserDefineSourceDemo {
public static void main(String[] args) throws Exception {
//1、初始化环境变量
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//2、添加自定义的数据源
DataStreamSource<Long> dataStreamSource = executionEnvironment.addSource(new UserDefineSource());
//3、业务逻辑
SingleOutputStreamOperator<Long> result = dataStreamSource.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long aLong) throws Exception {
return aLong + 1000;
}
});
//4、打印结果
result.print();
//5、执行
executionEnvironment.execute();
}
}
class UserDefineSource implements SourceFunction<Long>{
private boolean flag = true;
private long num = 100;
@Override
public void run(SourceContext<Long> sourceContext) throws Exception {
while (flag){
//每间隔两秒给num数据递增输出。
sourceContext.collect(num++);
Thread.sleep(2000);
}
}
@Override
public void cancel() {
flag = false;
}
}
三、Flink Transform 整理和实战
DataStream Transformations 官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/overview/
DataSet Transformations 官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/dataset/transformations/
- map 和 filter
- flatMap,keyBy、sum
- union
- connect,coMap
四、Flink Sink 整理和实战
4.1 Flink 内置 Sink
关于 Flink 的内置 Sink 大致可以分为这三类:
-
1、标准输出/异常输出:print() / printToErr(),打印每个元素的 toString() 方法的值到标准输出或者标准错误输出流中
-
2、基于文件系统:writeAsText() / writeAsCsv(…) / write() / output()
-
3、扩展 Sink:常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem等
官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/overview/#bundled-connectors
官网截图:

4.2 Flink自定义Sink
Flink 自定义 Sink 有两种方式:
-
implements SinkFunction 接口
-
extends RichSinkFunction 抽象类
自定义的 Sink 逻辑可以在生命周期 open, invoke, close 中进行编写。
五、Flink DataSet 常用 Transformation
有一个大文件 ,有一个很大的集合,有一张很大的表,都是不动的。 针对这个数据整体,做一次计算:
-
1、Map:输入一个元素,然后返回一个元素,中间可以做一些清洗转换等操作
-
2、FlatMap:输入一个元素,可以返回零个,一个或者多个元素
-
3、MapPartition:类似map,一次处理一个分区的数据【如果在进行map处理的时候需要获取第三方资源链接,建议使用MapPartition】
-
4、Filter:过滤函数,对传入的数据进行判断,符合条件的数据会被留下
-
5、Reduce:对数据进行聚合操作,结合当前元素和上一次reduce返回的值进行聚合操作,然后返回一个新的值
-
6、Aggregate:sum、max、min 等,多个值,映射一个值
-
7、Distinct:返回一个数据集中去重之后的元素,data.distinct()
-
8、Join:内连接
-
9、OuterJoin:外链接
-
10、Cross:获取两个数据集的笛卡尔积
-
11、Union:返回两个数据集的总和,数据类型需要一致
-
12、First-n:获取集合中的前N个元素
-
13、Sort Partition:在本地对数据集的所有分区进行排序,通过 sortPartition() 的链接调用来完成对多个字段的排序
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接



![[附源码]计算机毕业设计JAVA校园求职与招聘系统](https://img-blog.csdnimg.cn/dead6759e4024606b7e2251afc49f73c.png)