文章目录
- 小文件危害
- 表的缓存
- shuffle 分区数调整
- Spark SQL 客户端设置合并
- Hive 客户端处理小文件合并
小文件危害
小文件会造成 nn 处理压力变大,大大降低了读取性能,整个 HDFS 文件系统访问缓慢,大量的小文件还会导致 nn 内存溢出,无法正常使用。
表的缓存
# 缓存某个表
spark.catalog.cacheTable("tableName")
# 释放缓存的表
spark.catalog.uncacheTable("tableName")
shuffle 分区数调整
# 指定在进行 shuffle 操作时的分区数量,默认:200
spark.sql.shuffle.partitions
Spark SQL 客户端设置合并
我的建议是,不如直接调用方法coalesce 来得实在。
那么如何设置 coalesce 参数的个数呢?
可以先查看我们操作的数据量大小,然后用它去除以我们的集群块Block Size 即可。
Hive 客户端处理小文件合并
方法一:
-- 是否开启分区调整功能,默认:false
set spark.sql.adaptive.enabled=true;
-- 开启分区调整后,在 reduce 阶段每个 task 最少处理的数据量,默认:64M,单位:B
-- 一般改成和集群块一样的大小,Hadoop2.7.2版本及之前默认64MB,Hadoop2.7.3版本及之后默认128M
set spark.sql.adaptive.shuffle.targetPostShuffleInputSize=128000000;
-- 开启分区调整后,最小的 reducer 个数,默认:1
set spark.sql.adaptive.minNumPostShufflePartitions=1;
-- 开启分区调整后,最大的 reducer 个数,默认:500
set spark.sql.adaptive.maxNumPostShufflePartitions=500;
-- 开启分区调整后,在 reduce 阶段每个 task 最少处理的条数,默认:20000000
set spark.sql.adaptive.shuffle.targetPostShuffleRowCount=20000000;
一般情况数据量小的话,只需要设置前面两个参数就可以了。
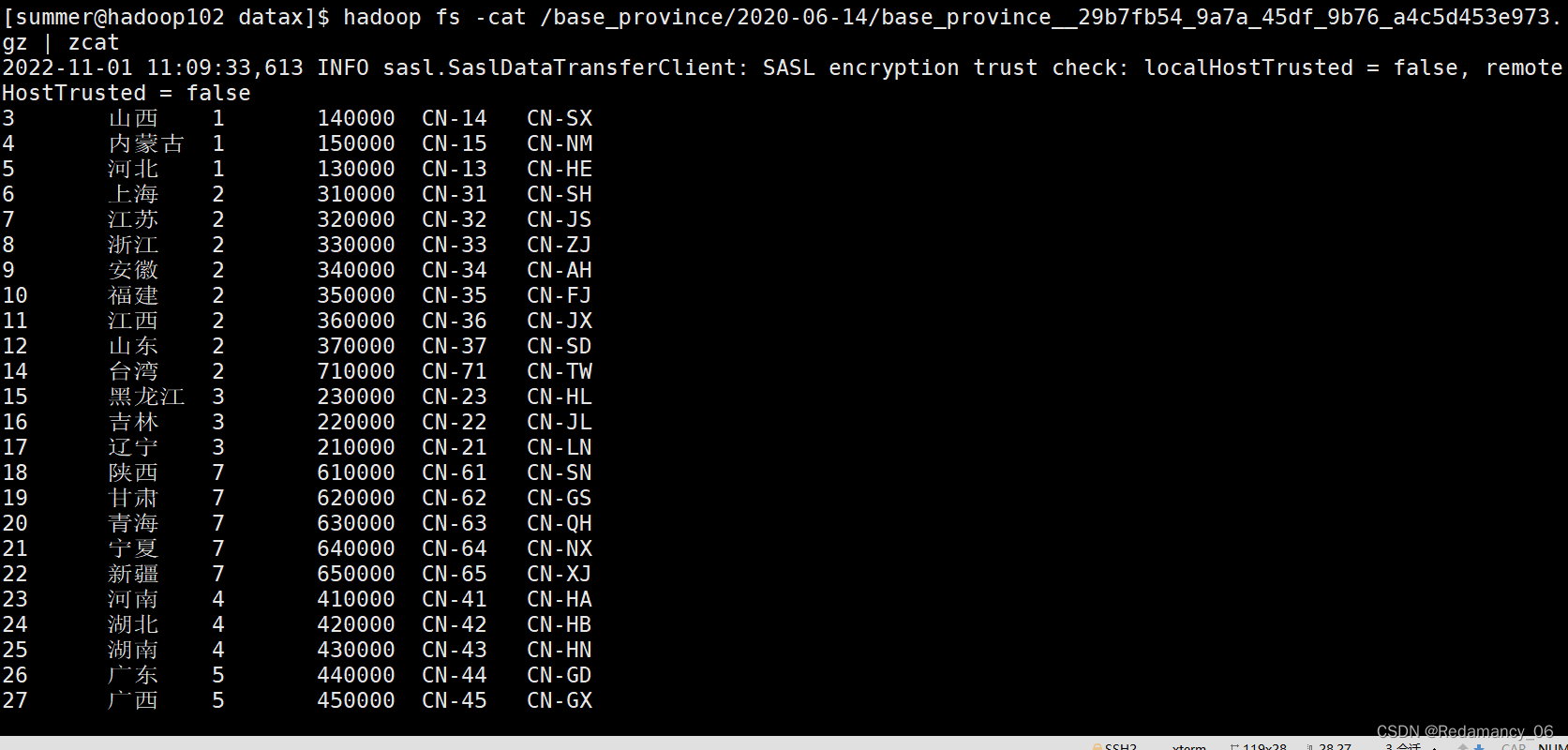
参数调整前:
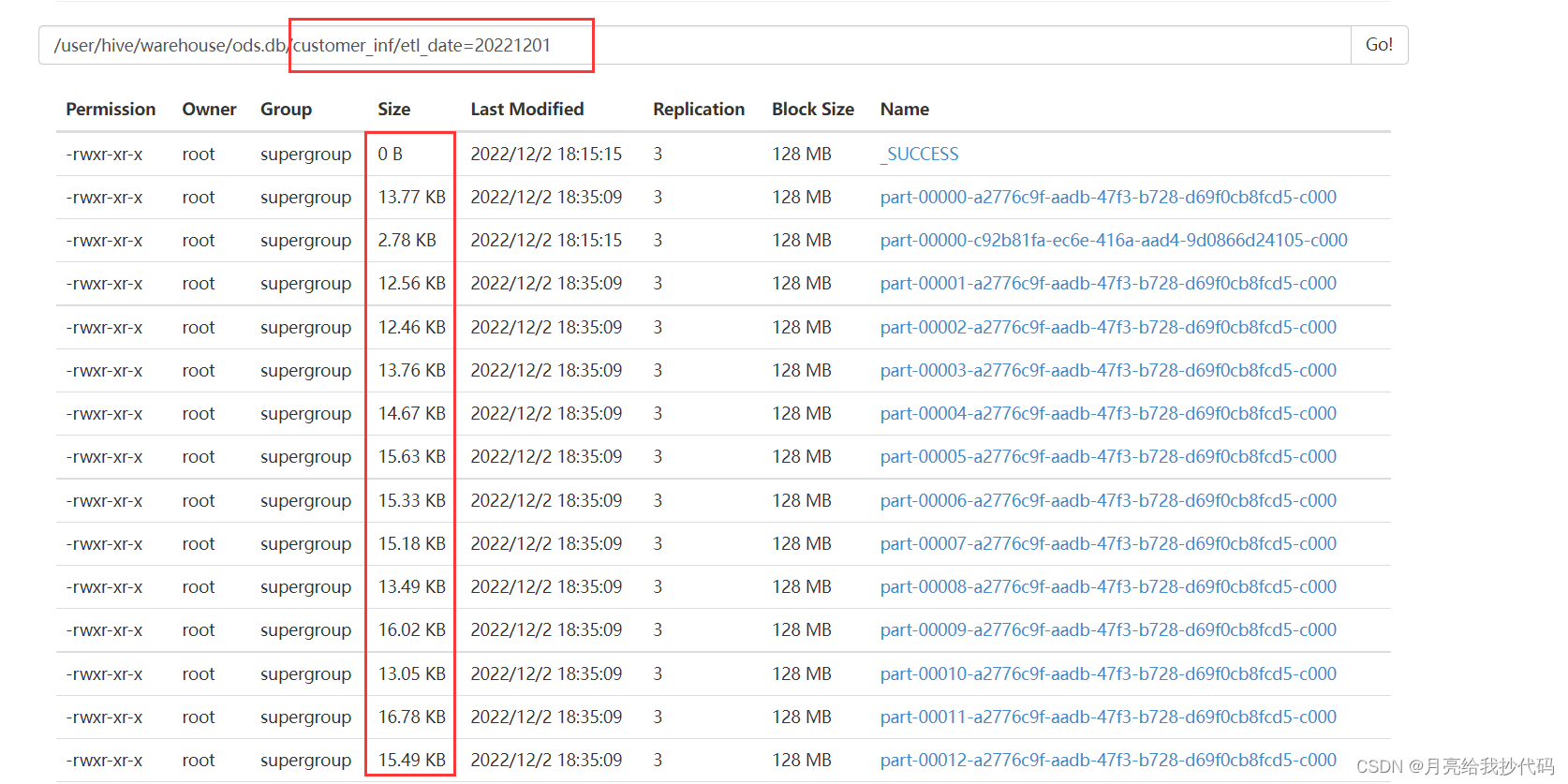
参数调整后:
新建了一个和其结构一样 test 表,然后导入数据,成功的合并了小文件:

方法二:
-- 执行 Map 前进行小文件合并,默认开启
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
-- 合并为一个 split 的最大值(单位byte),当超过该值时新建一个split,256MB
set mapreduce.input.fileinputformat.split.maxsize=268435456;
-- 在第一步合并后每个节点剩余的文件,如果大于该值(单位byte),单独创建一个split,256MB
set mapreduce.input.fileinputformat.split.minsize.per.node=268435456;
-- 在第二步处理完,每个机架上剩余的文件,如果大于该值(单位byte),单独创建一个split,256MB
set mapreduce.input.fileinputformat.split.minsize.per.rack=268435456;
参数调整前:
参数调整后:
新建了一个和其结构一样 test 表,然后导入数据,成功的合并了小文件:

以上参数调优都是临时调优,仅限于本次会话,如果想要永久设置的话只需要将参数配置到 hive-site.xml 文件中即可。



![[附源码]计算机毕业设计疫情防控平台Springboot程序](https://img-blog.csdnimg.cn/ab71277cb91a4e6ab64898cd20915bd0.png)

![[附源码]计算机毕业设计志愿者服务平台Springboot程序](https://img-blog.csdnimg.cn/addcd33629c5486998a5a620dd99f3ca.png)


![[附源码]Python计算机毕业设计Django健康医疗体检](https://img-blog.csdnimg.cn/730df7095d5c45cda0352f397b4f01ca.png)
![[附源码]计算机毕业设计JAVA校园闲置物品交易](https://img-blog.csdnimg.cn/bf23b357e8994acdb640b50e36f34587.png)