官方文档:
Serializers - Django REST framework中文站点
上一章:
二、Django REST Framework (DRF)序列化&反序列化_做测试的喵酱的博客-CSDN博客
一、前提
models.py
class MiaoClass(models.Model):
id = models.AutoField(primary_key=True, verbose_name='id', help_text='id')
classname = models.CharField(max_length=20, verbose_name='班级名称', help_text='班级名称')
clasleader = models.CharField(max_length=10, verbose_name='班主任姓名', help_text='班主任姓名')
classcode = models.IntegerField(unique=True, verbose_name='班级code', help_text='班级code')
ifopens = models.BooleanField(default=True, verbose_name='是否开学', help_text='是否开学')
classrate = models.IntegerField( verbose_name='班费', help_text='班费')
class Meta:
# i.db_table指定创建的数据表名称
db_table = 'tb_class'
# 为当前数据表,设置中午呢描述
verbose_name = "班级表"
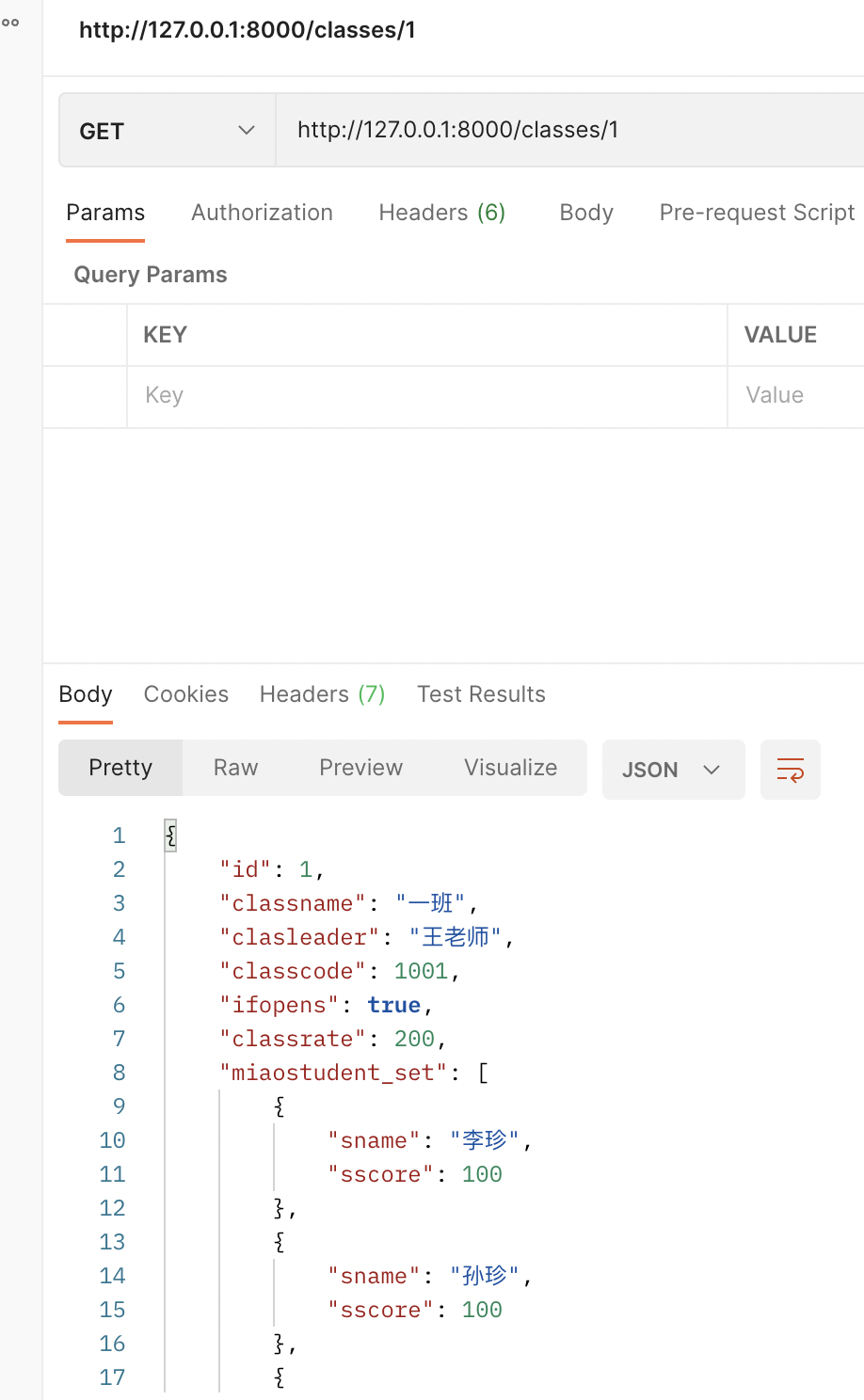
verbose_name_plural = "班级表"二、查询主表数据时,显示从表的主键数据(PrimaryKeyRelatedField)
- 可以通过定义PrimaryKeyRelatedField来获取关联表的外键值
- 如果通过父表获取从表数据,默认需要使用从表模型类名小写_set作为序列化器中的关联字段名称
- 如果在定义模型类的外键字段时,指定了realated_name参数,那么会把realated_name参数作为序列化器类中的关联字段。
2.1 主表的序列化器类
serializers.py
class ClassSerializer(serializers.Serializer):
id = serializers.IntegerField(label='班级id', help_text='班级id')
classname = serializers.CharField(max_length=20, label='班级名称', help_text='班级名称')
clasleader = serializers.CharField(max_length=10, label='班主任姓名', help_text='班主任姓名')
classcode = serializers.IntegerField(label='班级code', help_text='班级code')
ifopens = serializers.BooleanField(label='是否开学', help_text='是否开学')
classrate = serializers.IntegerField(label='班费', help_text='班费')
miaostudent_set = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',read_only=True,many=True)
2.2 查询主表时,显示从表的主键数据(PrimaryKeyRelatedField)
实现功能:
在查询主表时,需要显示主表对应的从表数据。
实现方法:
在定义主表的序列化器类时,需要新增一个关联从表的字段,命名为 【从表名模型类称小写_set】 ,值为 关键字 serializers.PrimaryKeyRelatedField 。
最后取值为从表的主键字段。
miaostudent_set = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',read_only=True,many=True)
1、该字段,在输入时不不需要输入该字段。在序列化输出时,需要显示该字段,所以使用
read_only=True,
2、一条主表数据,可能对应多条从表数据,所以需要使用 many=True
2.2.1 构建请求
views.py
class ClassesView(View):
# 查询所有数据
def get(self,request):
# 获取列表数据
queryset = MiaoClass.objects.all()
print(queryset)
serializer = ClassSerializer(instance=queryset, many=True)
return JsonResponse(serializer.data, safe=False)
class ClassesDetailView(View):
def get(self, request, pk):
# 1、需要校验pk在数据库中是否存在
# 2、从数据库中读取项目数据
try:
class_obj = MiaoClass.objects.get(id=pk)
except Exception as e:
return JsonResponse({'msg': '参数有误'}, status=400)
serializer = ClassSerializer(instance=class_obj)
return JsonResponse(serializer.data)
urls.py
# 样式:类视图.as_view()
path("classes/",views.ClassesView.as_view()),
path('classes/<int:pk>/',views.ClassesDetailView.as_view()), 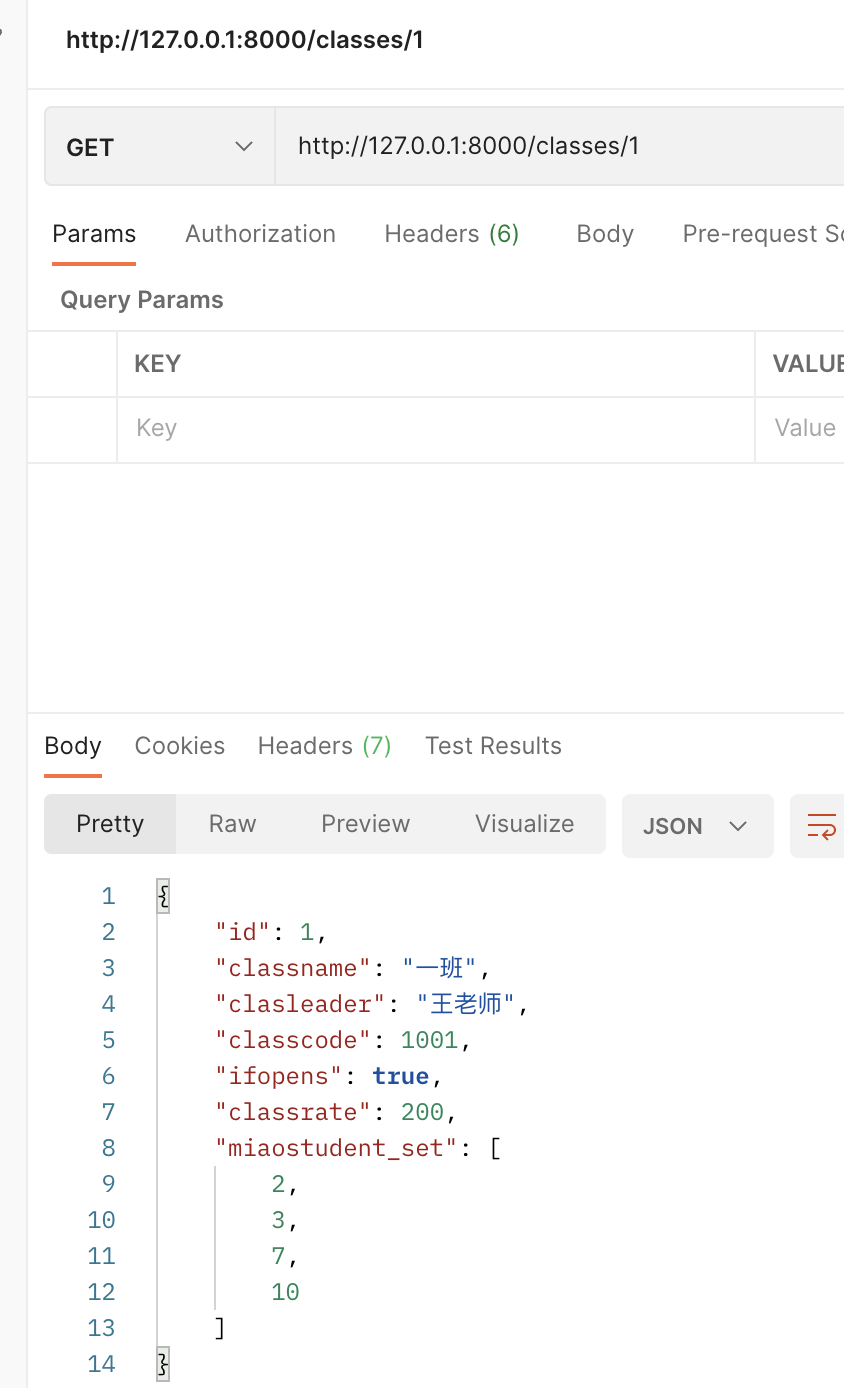
miaostudent_set 的值,显示的是从表的主键值
2.3 自定义主表中的从表属性名称
在上面的结果中,显示的值是 miaostudent_set (从表名模型类称小写_set),
对于调用者来说,不懂这个字段的含义,我们想自定义一下这个字段的名称。
如定义为sid。
1、先修改models.py 中学生表模型类的外键 ,关联名称related_name='sid'
class MiaoStudent(models.Model):
sname = models.CharField(max_length=20, verbose_name='学生姓名', help_text='学生姓名')
sgender = models.BooleanField(verbose_name='性别', help_text='性别')
sage = models.IntegerField(verbose_name='年龄', help_text='年龄')
sid = models.IntegerField(unique=True, verbose_name='学号', help_text='学号')
sscore = models.IntegerField( verbose_name='成绩', help_text='成绩')
classid = models.ForeignKey('miaoschool.MiaoClass',on_delete=models.CASCADE,verbose_name='班级id',
help_text='班级id',
related_name='sid')classid = models.ForeignKey('miaoschool.MiaoClass',on_delete=models.CASCADE,verbose_name='班级id',
help_text='班级id',
related_name='sid')
2、序列化器中,使用sid 字段
sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id', read_only=True, many=True)
class ClassSerializer(serializers.Serializer):
id = serializers.IntegerField(label='班级id', help_text='班级id')
classname = serializers.CharField(max_length=20, label='班级名称', help_text='班级名称')
clasleader = serializers.CharField(max_length=10, label='班主任姓名', help_text='班主任姓名')
classcode = serializers.IntegerField(label='班级code', help_text='班级code')
ifopens = serializers.BooleanField(label='是否开学', help_text='是否开学')
classrate = serializers.IntegerField(label='班费', help_text='班费')
# miaostudent_set = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',read_only=True,many=True)
sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id', read_only=True, many=True)
再次发起请求
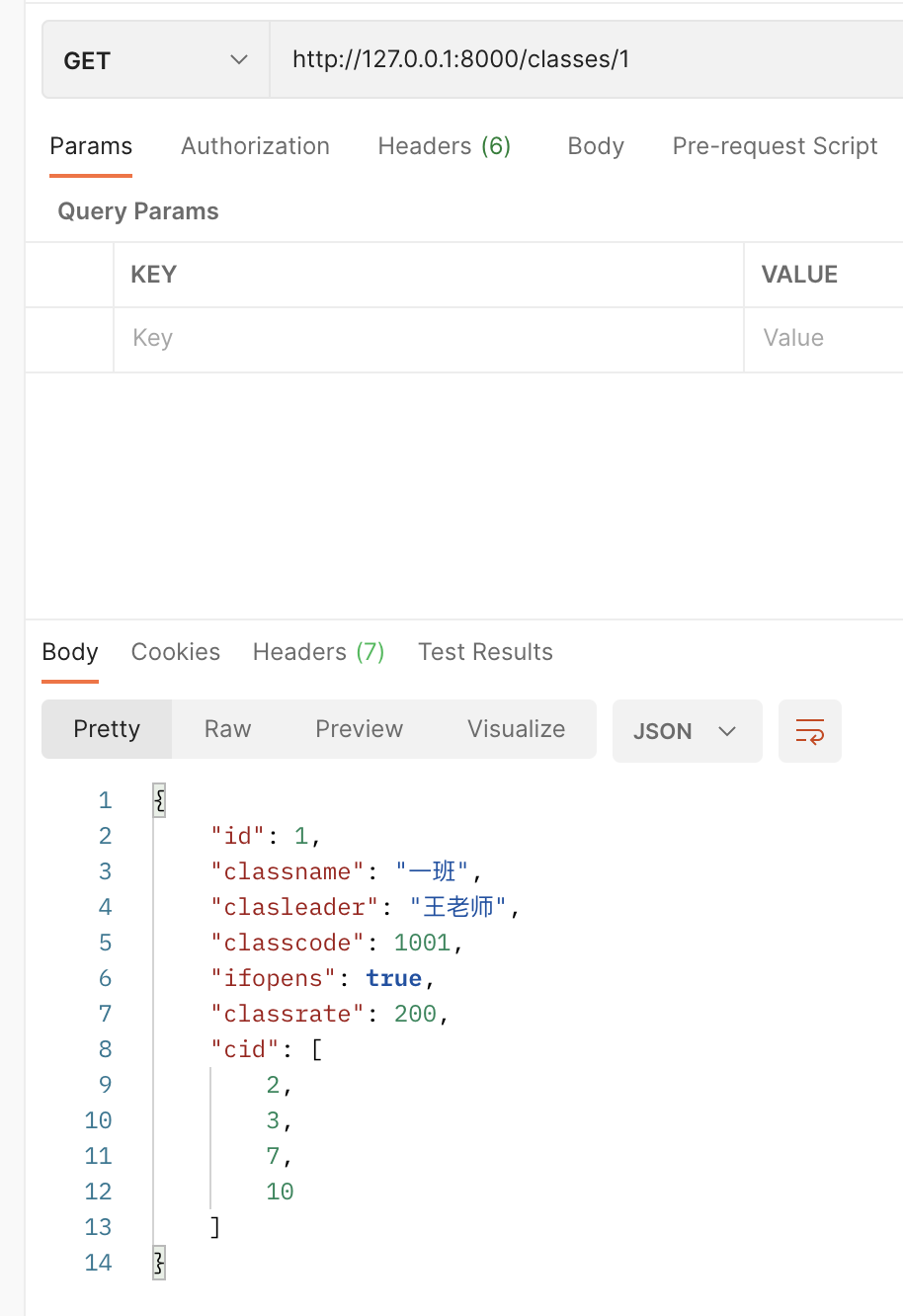
返回值变成了cid
2.4 PrimaryKeyRelatedField
PrimaryKeyRelatedField 中,需要指定 read_only=True, 或者 queryset
方式一:指定read_only=True
只做序列化输出,(在创建数据时,用户不需要输入该字段,在用户查询数据时,展示该字段的数据)
sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id', read_only=True, many=True)方式二:指定queryset=从表模型类.objects.all()
sid = serializers.PrimaryKeyRelatedField(label='学生id', help_text='学生id',
queryset = MiaoStudent.objects.all(),
write_only=True,
many=True)指定queryset=关联表的查询集对象,用于对参数进行校验。
三、 查询主表时,显示从表模型类的__str__
实现功能:
在从表模型类中,定义__str__方法。在主表中,查询数据时,将从表的__str__数据输出。
1、从表模型类,需要定义 __str__方法
def __str__(self):
return f"姓名:{self.sname},性别:{self.sgender},年龄:{self.sage},分数:{self.sscore}"class MiaoStudent(models.Model):
sname = models.CharField(max_length=20, verbose_name='学生姓名', help_text='学生姓名')
sgender = models.BooleanField(verbose_name='性别', help_text='性别')
sage = models.IntegerField(verbose_name='年龄', help_text='年龄')
sid = models.IntegerField(unique=True, verbose_name='学号', help_text='学号')
sscore = models.IntegerField( verbose_name='成绩', help_text='成绩')
classid = models.ForeignKey('miaoschool.MiaoClass',on_delete=models.CASCADE,verbose_name='班级id',
help_text='班级id',
related_name='sid')
class Meta:
# i.db_table指定创建的数据表名称
db_table = 'tb_student'
# 为当前数据表,设置中午呢描述
verbose_name = "学生信息表"
verbose_name_plural = "学生信息表"
def __str__(self):
return f"姓名:{self.sname},性别:{self.sgender},年龄:{self.sage},分数:{self.sscore}"2、在父表的序列化器类中,需要指定StringRelatedField(many=True)
sid = serializers.StringRelatedField(many=True)注意:
StringRelatedField 中,默认添加了read_only=True,该字段只序列化输出
3、接口请求,查看返回数据
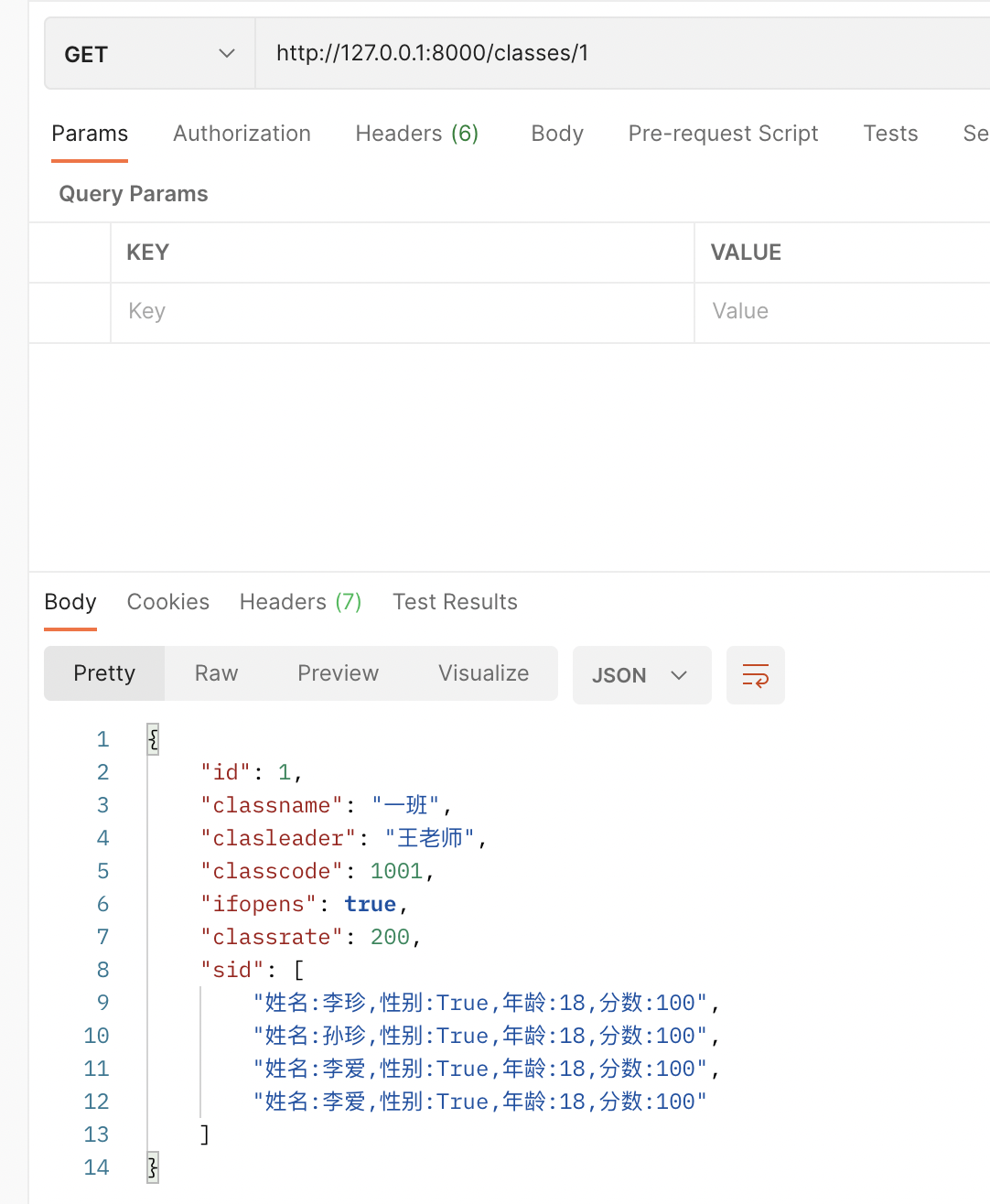
四、 查询主表时,显示从表的指定字段值
1、实现功能:
查询主表数据,同时显示从表中指定的字段。
如我想要展示从表中的学生姓名字段sname
2、SlugRelatedField(slug_field='')指定从表字段,只做序列化输出。(只读数据)
sid = serializers.SlugRelatedField(slug_field='sname', many=True, read_only=True)
3、 SlugRelatedField(slug_field='')指定从表字段,反序列化输出。写数据时进行校验
需要指定queryset,同时关联字段必须有唯一约束。
sid = serializers.SlugRelatedField(slug_field='sname',many=True,queryset=MiaoStudent.objects.all())五、查询主表时,显示从表的指定的多个字段值
1、需要展示从表的哪几个字段,我们可以单独再定义一个序列化器类。
如我想显示从表的 sname 与score字段。
定义一个序列化器类,只包含这两个字段。
class StudentINfoSerializer(serializers.Serializer):
sname = serializers.CharField(label='学生姓名', help_text='学生姓名', max_length=10, min_length=1)
sscore = serializers.IntegerField(label='学生成绩', help_text='学生成绩', max_value=100, min_value=0)2、在主表的序列化器中, miaostudent_set = StudentSerializer()
miaostudent_set = StudentSerializer(read_only=True,many=True)注意:
- 自定义序列化器是Field的子类。
- 在自定义序列化器中,定义字段时,字段必须是Field或者Field的子类,所以在自定义序列化器中,定义字段时,字段也可以是一个序列化器类。



![[快速入门前端17] CSS 选择器(6) 选择器总结](https://img-blog.csdnimg.cn/854f0ddf406b4889a8cf6f1f27727167.png)