1、自学习(self-taught learning)与半监督学习
自学习(self-taughtlearning)是不要求未标注数据
X
u
X_u
Xu和已标注数据
X
l
X_l
Xl来自同样的分布。另外一种带限制性的方式也被称为半监督学习,它要求
X
u
X_u
Xu和
X
l
X_l
Xl服从同样的分布。下面通过例子解释二者的区别。
假定有一个计算机视觉方面的任务,目标是区分汽车和摩托车图像;也即训练样本里面要么是汽车的图像,要么是摩托车的图像。哪里可以获取大量的未标注数据呢?
最简单的方式可能是从互联网上下载一些随机的图像数据集,在这些数据上训练出一个稀疏自编码器,从中得到有用的特征。这个例子里,未标注数据完全来自于一个和已标注数据不同的分布(未标注数据集中,或许其中一些图像包含汽车或者摩托车,但是不是所有的图像都如此)。这种情形被称为自学习。
相反,如果有大量的未标注图像数据,要么是汽车图像,要么是摩托车图像,仅仅是缺失了类标号(没有标注每张图片到底是汽车还是摩托车)。也可以用这些未标注数据来学习特征。这种方式,即要求未标注样本和带标注样本服从相同的分布,有时候被称为半监督学习。
2、单任务学习与多任务学习
这篇博客讲的很好:https://blog.csdn.net/qq_41033011/article/details/127326744
其中多任务学习有两种主要方式:
- 基于参数的共享:例如,神经网络隐藏节点的共享,这种方法主要通过挖掘不同任务之间在浅层所共享的隐藏节点特征来达到任务之间相关性建模的目的。
例如:
Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xiaoou Tang. Facial landmark detection by deep multi-task learning, ECCV, 2014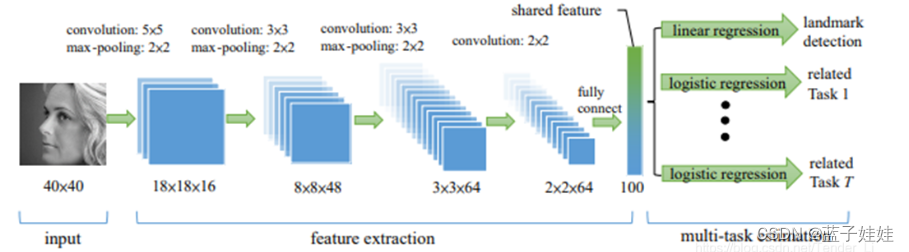 在右侧有7个相关任务,它们在左侧共享同一个模型参数提取能够应用于不同任务的共享特征,这样就实现了通过神经网络的方式在浅层共享同一个参数为不同的任务服务,建立任务之间的相关性,挖掘它们之间的潜在共享信息的目的。在这个网络中,通过最后不同的输出层建立不同任务之间的差异性
在右侧有7个相关任务,它们在左侧共享同一个模型参数提取能够应用于不同任务的共享特征,这样就实现了通过神经网络的方式在浅层共享同一个参数为不同的任务服务,建立任务之间的相关性,挖掘它们之间的潜在共享信息的目的。在这个网络中,通过最后不同的输出层建立不同任务之间的差异性
- 基于正则化约束的共享:例如:均值约束、联合特征学习等,实际上就是在模型中引入一些正则化的先验,通过先验对模型的约束来建模不同任务之间的相关性。
![[快速入门前端17] CSS 选择器(6) 选择器总结](https://img-blog.csdnimg.cn/854f0ddf406b4889a8cf6f1f27727167.png)