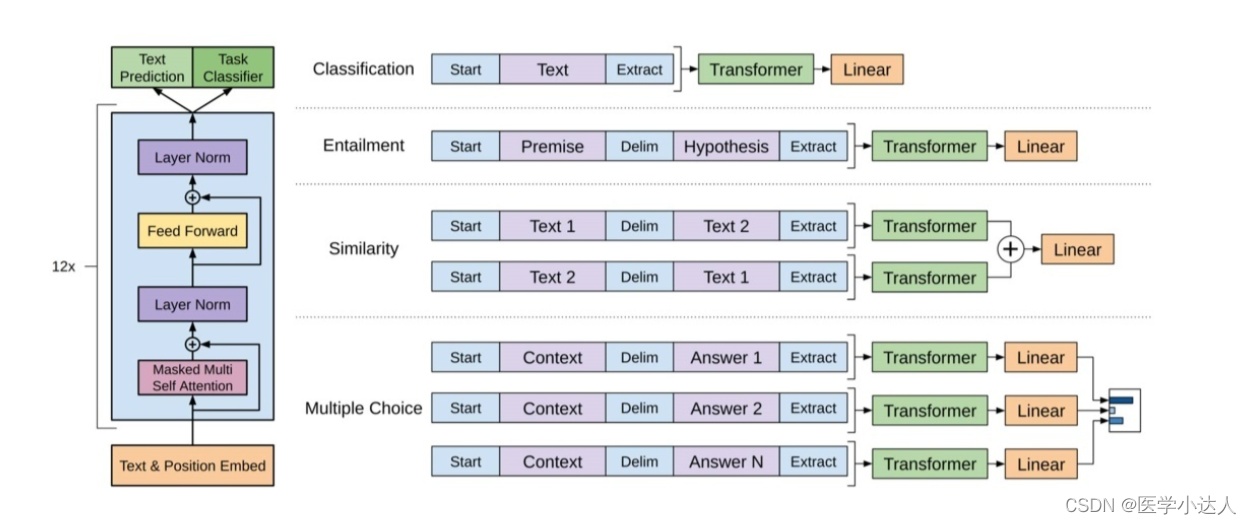
决策树是一种流程图,可以帮助我们根据以前的经验进行决策
比如,一个人将尝试决定他/她是否应该参加喜剧节目
下面是要用到的数据集
| Age | Experience | Rank | Nationality | Go |
|---|---|---|---|---|
| 36 | 10 | 9 | UK | NO |
| 42 | 12 | 4 | USA | NO |
| 23 | 4 | 6 | N | NO |
| 52 | 4 | 4 | USA | NO |
| 43 | 21 | 8 | USA | YES |
读取并打印数据集
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
print(df)打印的是上面的数据集
如需制作决策树,所有数据都必须是数字
所以必须在该例子中将非数字列 “Nationality” 和 “Go” 转换为数值
Pandas 有一个 map() 方法,该方法接受字典,其中包含有关如何转换值的信息
{'UK': 0, 'USA': 1, 'N': 2}表示将值 'UK' 转换为 0,将 'USA' 转换为 1,将 'N' 转换为 2
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
print(df)Age Experience Rank Nationality Go 0 36 10 9 0 0 1 42 12 4 1 0 2 23 4 6 2 0 3 52 4 4 1 0 4 43 21 8 1 1 5 44 14 5 0 0 6 66 3 7 2 1 7 35 14 9 0 1 8 52 13 7 2 1 9 35 5 9 2 1 10 24 3 5 1 0 11 18 3 7 0 1 12 45 9 9 0 1
然后,我们必须将特征列与目标列分开
特征列是我们尝试从中预测的列,目标列是具有我们尝试预测的值的列
X 是特征列,y 是目标列
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
print(X)
print(y)
Age Experience Rank Nationality 0 36 10 9 0 1 42 12 4 1 2 23 4 6 2 3 52 4 4 1 4 43 21 8 1 5 44 14 5 0 6 66 3 7 2 7 35 14 9 0 8 52 13 7 2 9 35 5 9 2 10 24 3 5 1 11 18 3 7 0 12 45 9 9 0 0 0 1 0 2 0 3 0 4 1 5 0 6 1 7 1 8 1 9 1 10 0 11 1 12 1 Name: Go, dtype: int64
现在,我们可以创建实际的决策树,使其适合我们的细节,然后在计算机上保存一个 .png 文件:
创建一个决策树,将其另存为图像,然后显示该图像
import pandas
from sklearn import tree
import pydotplus
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
import matplotlib.image as pltimg
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
# 实例化决策树对象
dtree = DecisionTreeClassifier()
# 使用 `fit()` 方法对该模型进行训练,使其能够根据输入特征 `X` 来预测输出标签 `y`
dtree = dtree.fit(X, y)
# 使用 `tree.export_graphviz` 函数将训练好的决策树模型 `dtree` 转换为 Graphviz 格式的数据,并将其保存在 `data` 变量中
# `dtree`:训练好的决策树模型
# `out_file`:输出文件名,这里设置为 `None`,表示将结果输出到 `data` 变量中
# `feature_names`:特征列的列名,这里设置为 `features`,即 ['Age', 'Experience', 'Rank', 'Nationality']。
data = tree.export_graphviz(dtree, out_file=None, feature_names=features)
# 使用 `pydotplus.graph_from_dot_data` 函数将 Graphviz 格式的数据转换为图形对象 `graph`
graph = pydotplus.graph_from_dot_data(data)
# 调用 `write_png` 方法将图形对象保存为 PNG 格式的图片文件,即 'mydecisiontree.png'
graph.write_png('mydecisiontree.png')
# 读取并加载生成的 PNG 格式的决策树图像文件 `'mydecisiontree.png'`,并将其存储在量量 `img` 中,以便后续进行显示
img=pltimg.imread('mydecisiontree.png')
imgplot = plt.imshow(img)
plt.show()
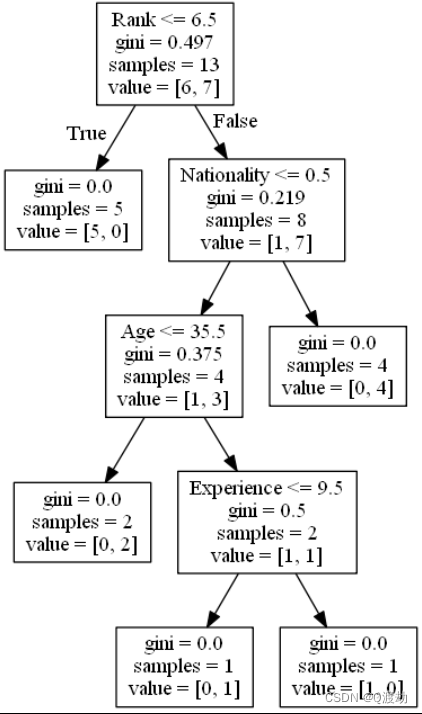
使用 predict() 方法来预测新值
import pandas
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
df = pandas.read_csv("shows.csv")
d = {'UK': 0, 'USA': 1, 'N': 2}
df['Nationality'] = df['Nationality'].map(d)
d = {'YES': 1, 'NO': 0}
df['Go'] = df['Go'].map(d)
features = ['Age', 'Experience', 'Rank', 'Nationality']
X = df[features]
y = df['Go']
dtree = DecisionTreeClassifier()
dtree = dtree.fit(X, y)
print(dtree.predict([[40, 10, 6, 1]]))
print("[1] means 'GO'")
print("[0] means 'NO'")

链接:上面的具体详细决策过程点击该链接