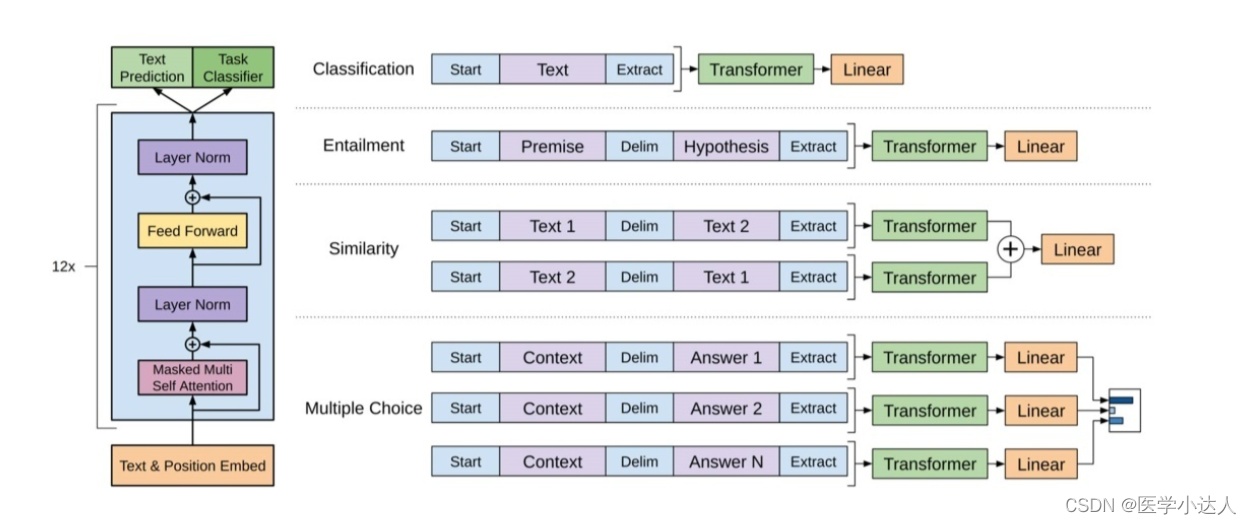
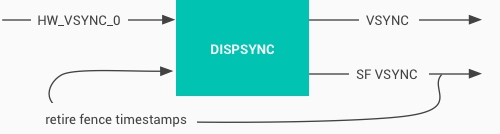
在图像中的特征处理:
- 平均亮度的去除

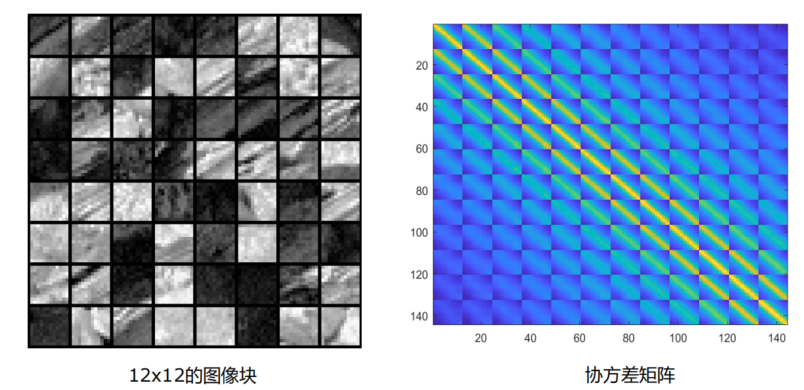
SVD
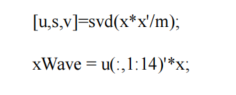
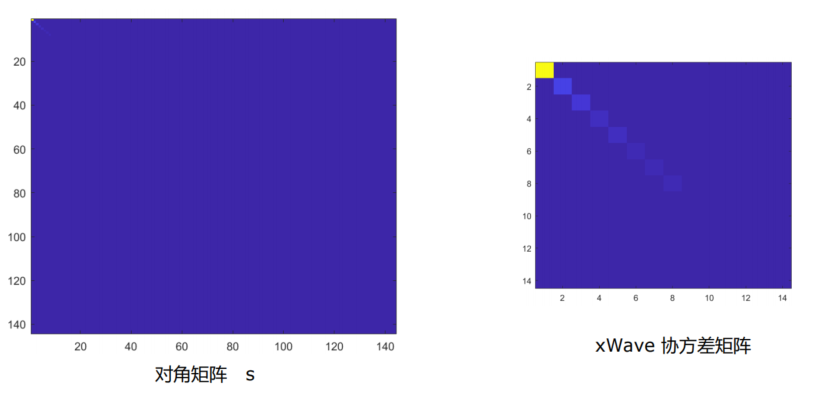
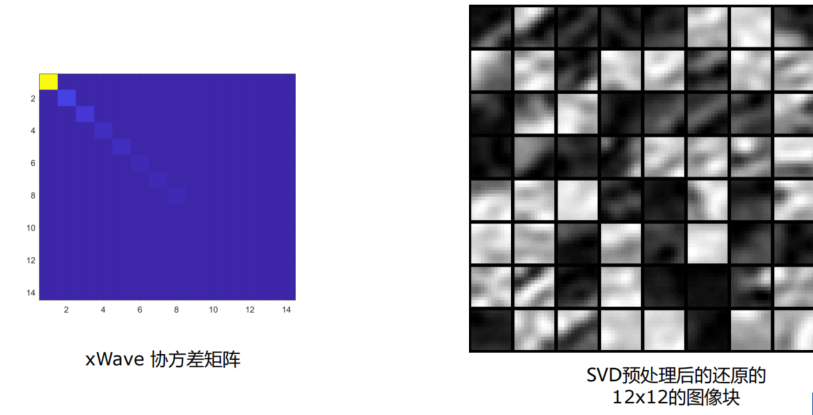
Whiten PCA

参数初始化策略
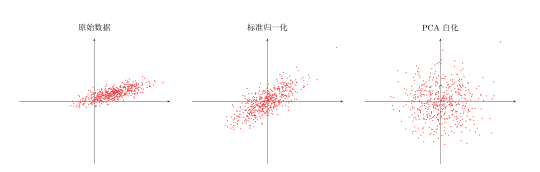
数据归一化:
- 标准归一化
- 缩放归一化
- PCA/SVD
数据归一化对梯度的影响
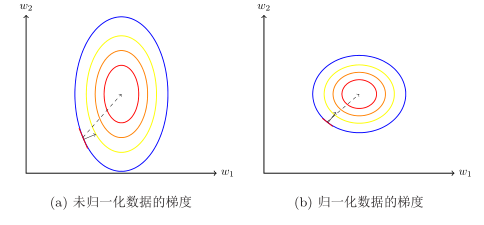
- 归一化后,可以更快的搜索到最优值点
正则化
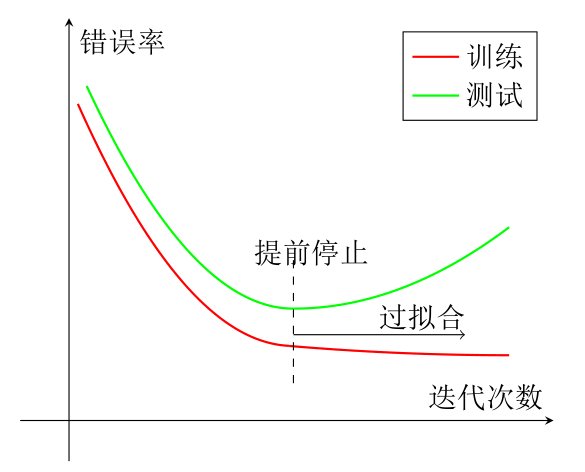
数据增强与早停
图像数据的增强主要是通过算法对图像进行转变,引入噪声等方法来增加数据的多样性

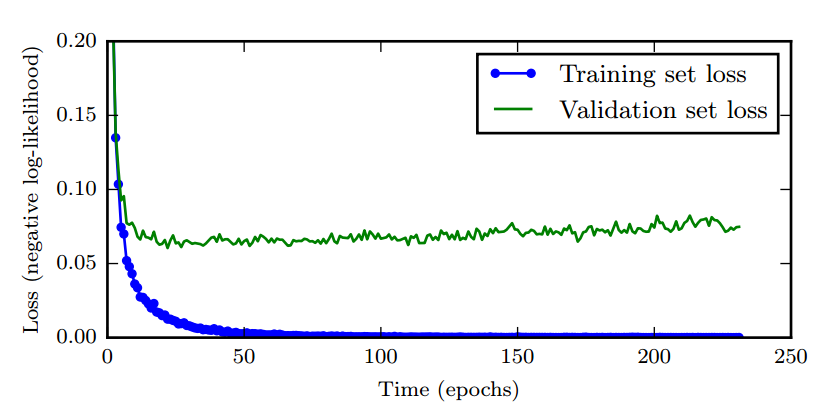
- 早停:我们使用一个验证集(Validation Dataset)来测试每一次迭代的参数在验证集上是否最优。如果在验证集上的错误率不再下降,就停止迭代。

Dropout
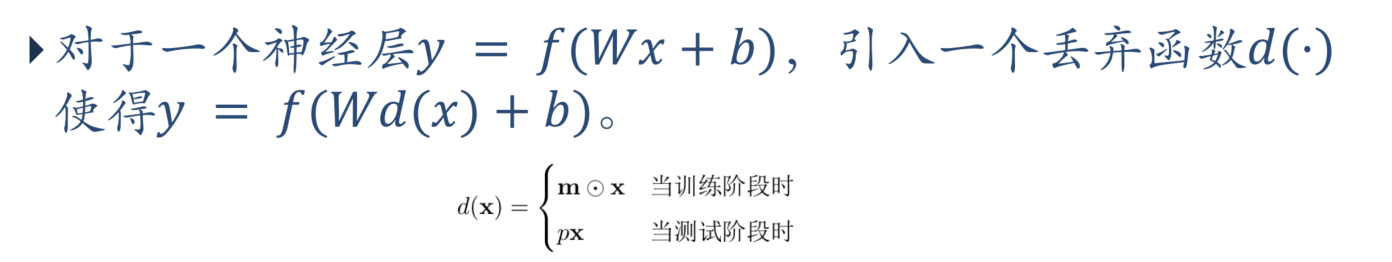
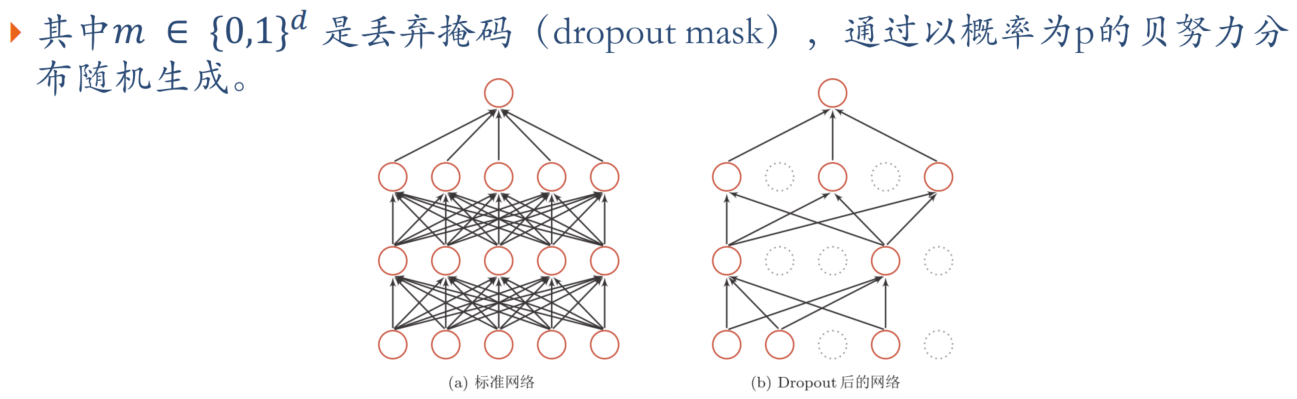
步骤:
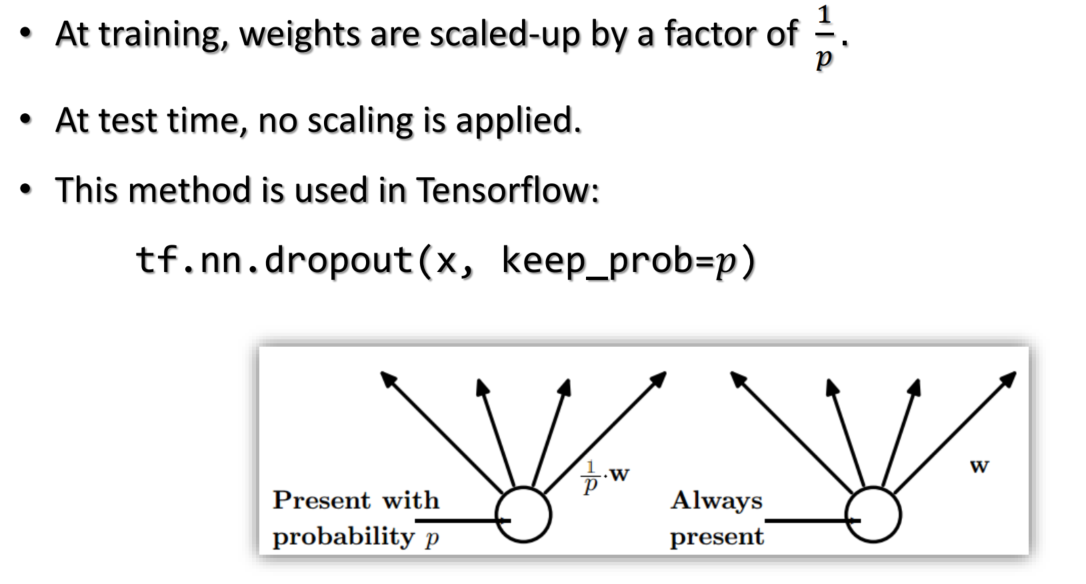
- 首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图中虚线为部分临时被删除的神经元)
- 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
- 然后继续重复这一过程:恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
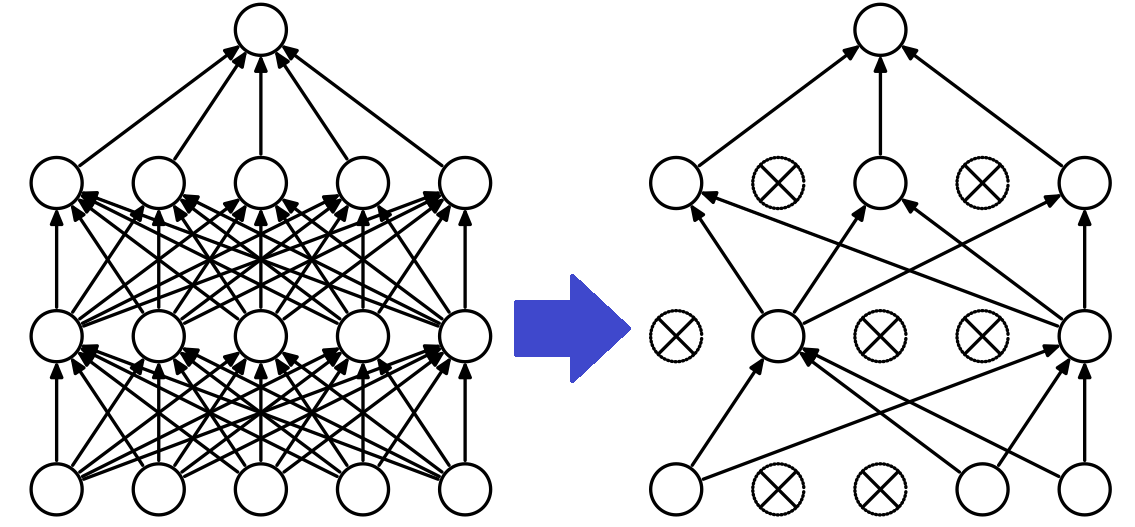
Dropout & bagging

相同点:
- 都是基于模型集成的方法。Bagging和Dropout都通过构建多个模型的集合来提高性能。
- 都使用随机性。Bagging使用自助采样法(bootstrap)从原始数据集中有放回地进行采样,以构建多个子集用于训练不同的模型。Dropout通过在训练过程中随机地关闭一部分神经元,以使每次训练过程都能得到不同的子网络。
- 都可以减小模型的方差。通过组合多个模型的预测结果,Bagging和Dropout都可以减小单个模型的方差,从而提高整体模型的稳定性和泛化能力。
不同点:
- 应用对象不同。Bagging主要应用于传统的机器学习算法(如决策树、随机森林等),而Dropout主要应用于深度学习模型(如神经网络)。
- 采样方式不同。Bagging使用自助采样法,从原始数据集中有放回地采样,每个子集的大小与原始数据集相同。而Dropout是在每次训练迭代中随机关闭一部分神经元,以得到不同的子网络。
- 模型组合方式不同。Bagging通过对多个模型的预测结果进行平均或投票来得到最终的预测结果。而Dropout是在训练过程中对多个子网络进行平均,得到一个集成的模型。
- 训练过程不同。Bagging是并行地训练多个模型,每个模型独立地对子集进行训练。而Dropout是在单个模型的训练过程中随机关闭一部分神经元,以模拟多个子网络的效果。
![[快速入门前端17] CSS 选择器(6) 选择器总结](https://img-blog.csdnimg.cn/854f0ddf406b4889a8cf6f1f27727167.png)