文章目录
- 一. 存储一直看不到数据
- 二. 数据有重复
- 三. NoSuchMethodError
- 3.1 问题描述
- 3.2 解决方案
- 3.2.1 查看源码
- 3.2.2 avro版本问题
- 3.2.3 hudi-flink1.14-bundle jar包的问题
- 四. Merge On Read 写只有 log 文件
- 4.1 问题描述
- 4.2 解决方案1(测试未通过)
- 4.2 解决方案2(测试通过:)
- 4.3 原来是配置的问题
- 参考:
一. 存储一直看不到数据
这个问题卡了我好久好久,差点都要放弃了,还是看视频和文档不仔细。
如果是 streaming 写, 请确保开启 checkpoint, Flink 的 writer 有 3中刷数据到磁盘的策略:
- 当某个 bucket在内存中积攒到一定大小 (可配, 默认 64MB)
- 当总的 buffer 大小积攒到 一定大小 (可配, 默认 1GB)
- 当checkpoint 触发, 将内存里的数据全部 flush出去
set execution.checkpointing.interval=600sec;
二. 数据有重复
如果是 COW 写, 需要开启参数 write.insert.drop.duplicates, COW 写每个 bucket的第一个文件默认是不去重的, 只有增量的数据会去重,全局去重需要开启该参数; MOR 写不需要开启任何参数, 定义好 primary key 后默认全局去重。 (注意: 从 0.10 版本开始, 该属性改名 write.precombine 并且默认为 true)
如果需要多 partition 去重,需要开启参数: index.global.enabled为true。(注意: 从 0.10 版本开始, 该属性改名 write.precombine 并且默认为 true)
索引 index 是判断数据重复的核心数据结构, index.state.ttl 设置了索引保存的时间, 默认 1.5 天,对于昌时间周期的更新, 比如更新一个月前的数据,需要将 index.state.ttl 调大(单位 天), 设置小于0代表永久保存。(注意: 从0.10 版本开始, 该属性默认为0)
三. NoSuchMethodError
3.1 问题描述
Flink SQL将MySQL数据写Hudi的MOR总是报如下错误:
Caused by: java.lang.NoSuchMethodError: org.apache.hudi.org.apache.avro.specific.SpecificRecordBuilderBase.<init>
(Lorg/apache/hudi/org/apache/avro/Schema;Lorg/apache/hudi/org/apache/avro/specific/SpecificData;)
报错:

3.2 解决方案
3.2.1 查看源码
编译后的源码查找:
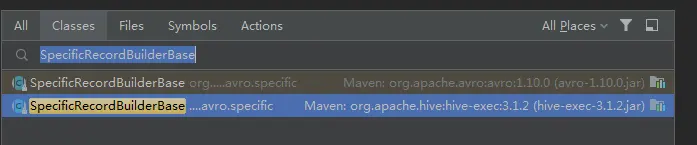
Flink源码中查找:
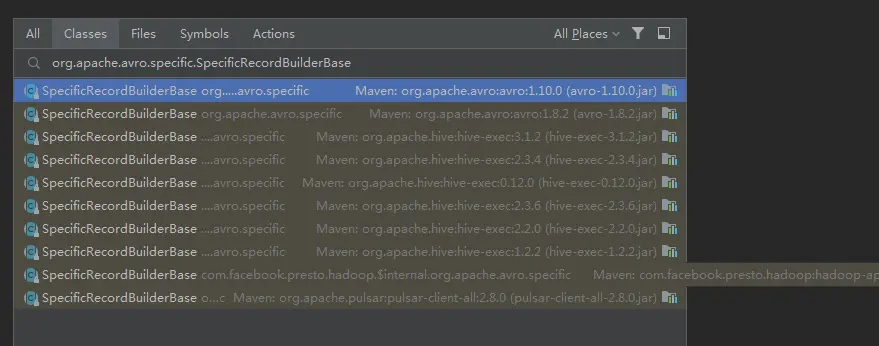
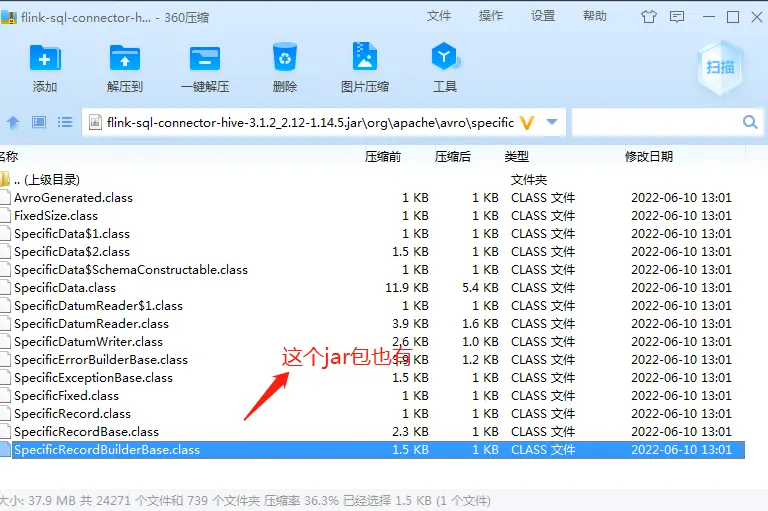
原来是有同名的class:
而且这两个jar包下的class,内容还不一样
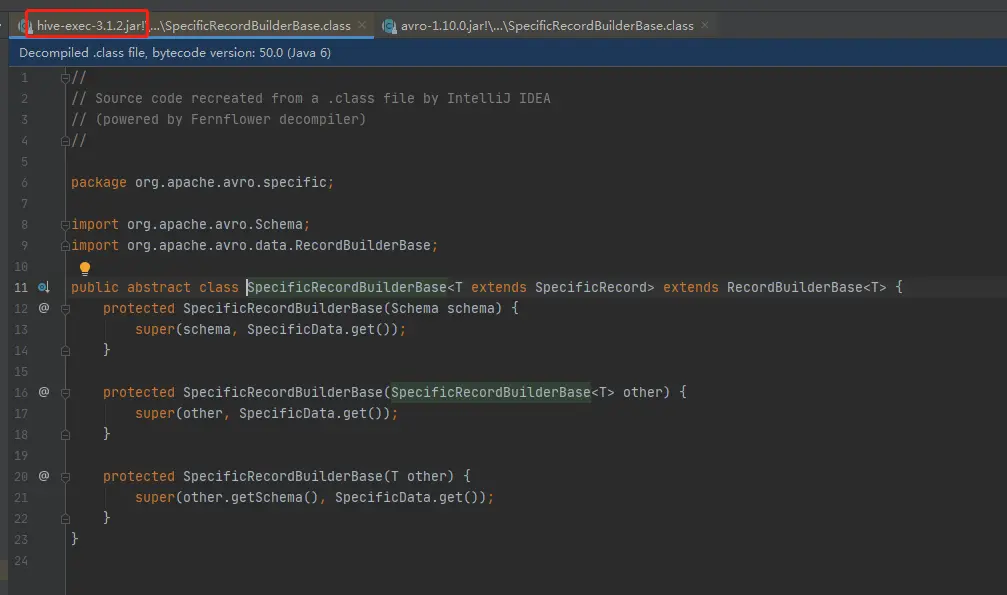
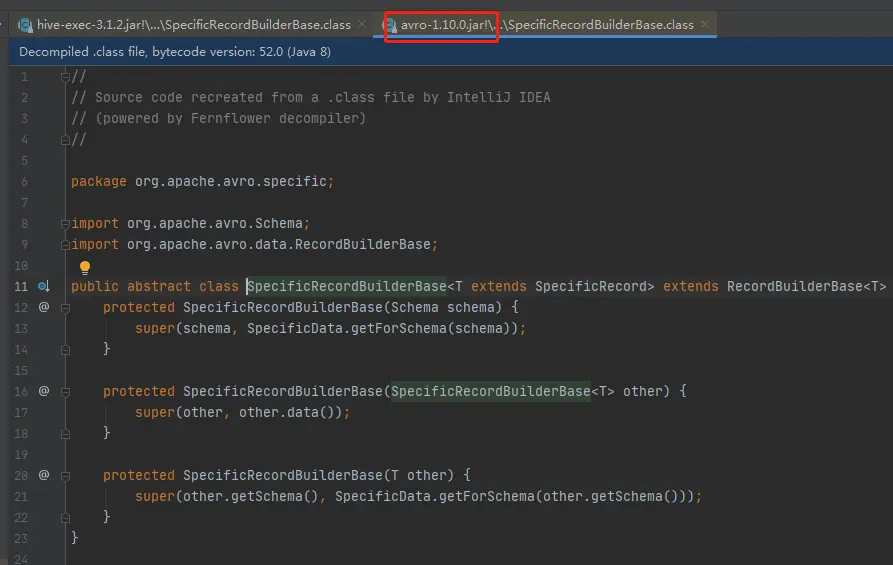
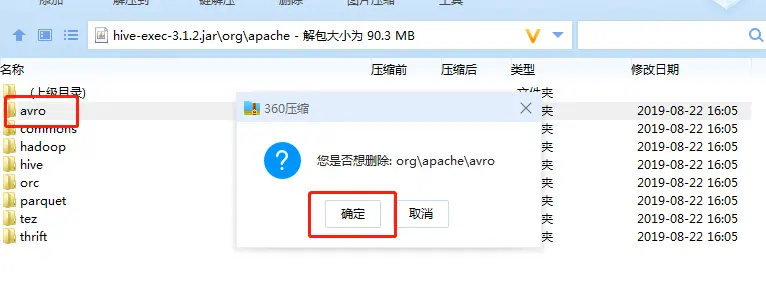
结果:
最终还是不行,一样的报错。
3.2.2 avro版本问题
在网上看了一些博客,说可能是avro的版本的问题
于是把 hadoop、hive、spark、flink的avro版本都修改为了最新的版本 avro-1.11.0.jar
https://www.coder.work/article/728416
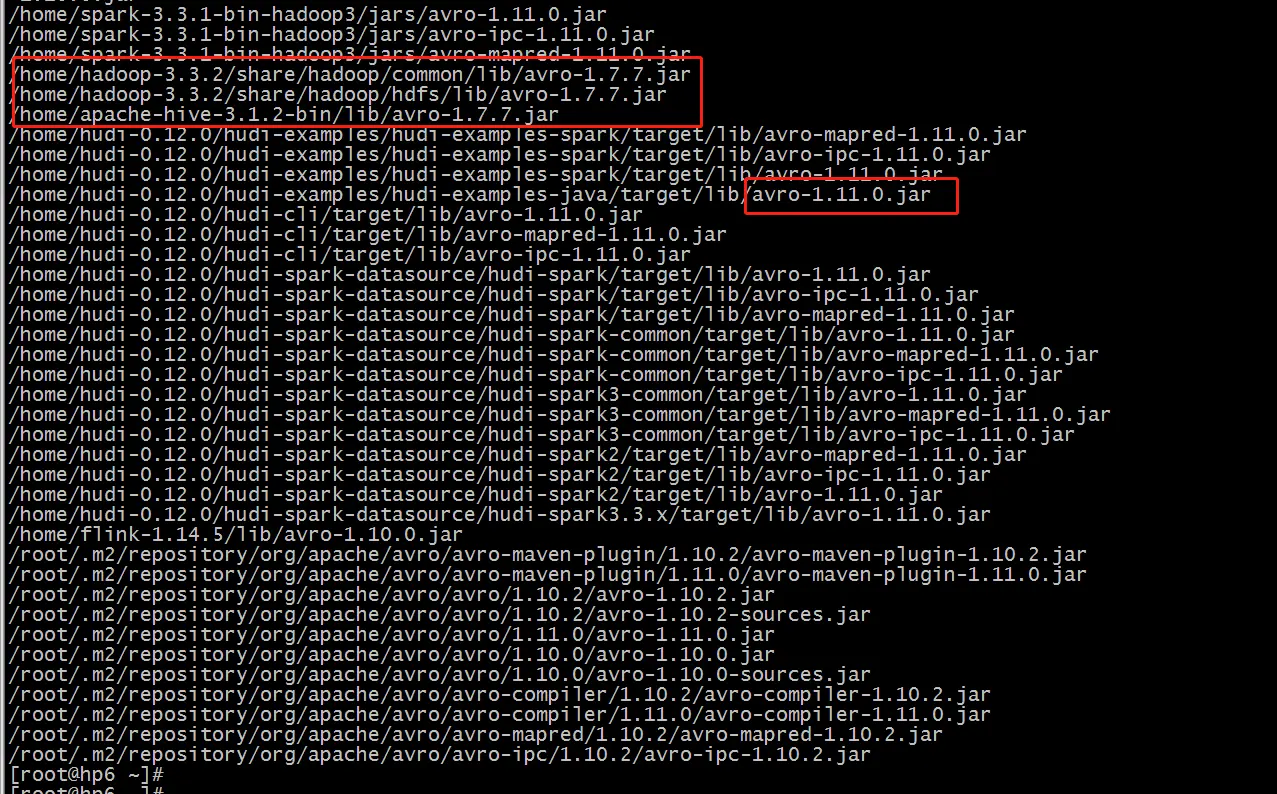
结果:
最终还是不行,一样的报错。
3.2.3 hudi-flink1.14-bundle jar包的问题
最开始我看到报错前面都是 org.apache.hudi.org.apache.avro,我还以为是提示错误,后来想想也不至于,然后想到 hudi-flink1.14-bundle 这个jar包的问题,下载下来通过idea代开后看了下,果然和我想的一样。
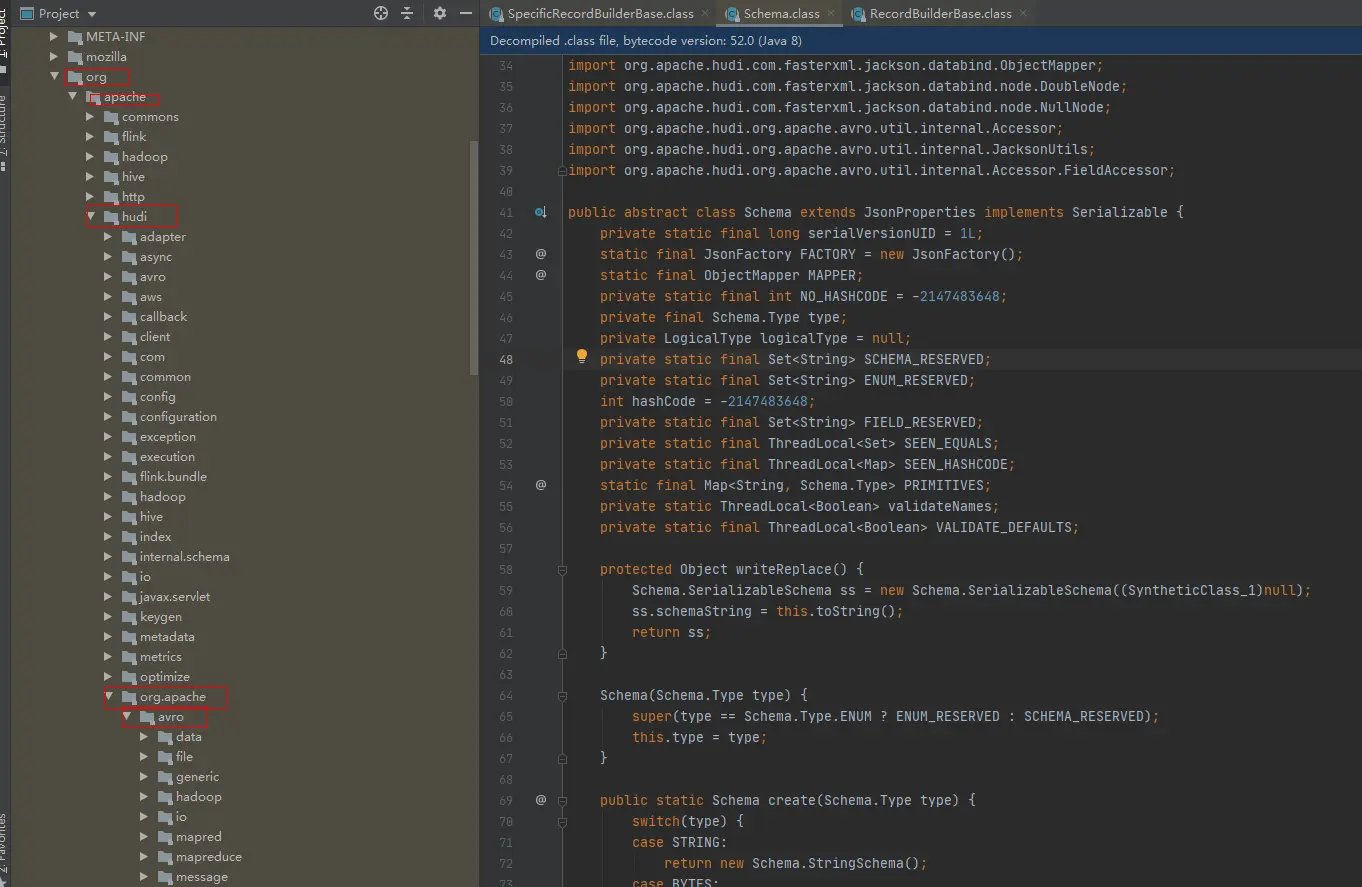
找到了具体有问题的class,但是暂时也解决不了。
所以只能想着替换这个jar包。
替换jar包:
https://blog.csdn.net/dkl12/article/details/127621878
如果想同步 Hive 的话,就不能使用上面下载的包了,必须使用profileflink-bundle-shade-hive。 (先就这样吧,谁让我编译的有问题呢?)
https://repo1.maven.org/maven2/org/apache/hudi/hudi-flink1.14-bundle/0.12.0/hudi-flink1.14-bundle-0.12.0.jar
结果:
问题解决,困扰了长达两周的问题终于解决了。
四. Merge On Read 写只有 log 文件
4.1 问题描述
Merge On Read 默认开启了异步的compaction,策略是 5 个 commits 压缩一次, 当条件满足会触发压缩任务,另外,压缩本身因为耗费资源,所以不一定能跟上写入效率,可能有滞后。
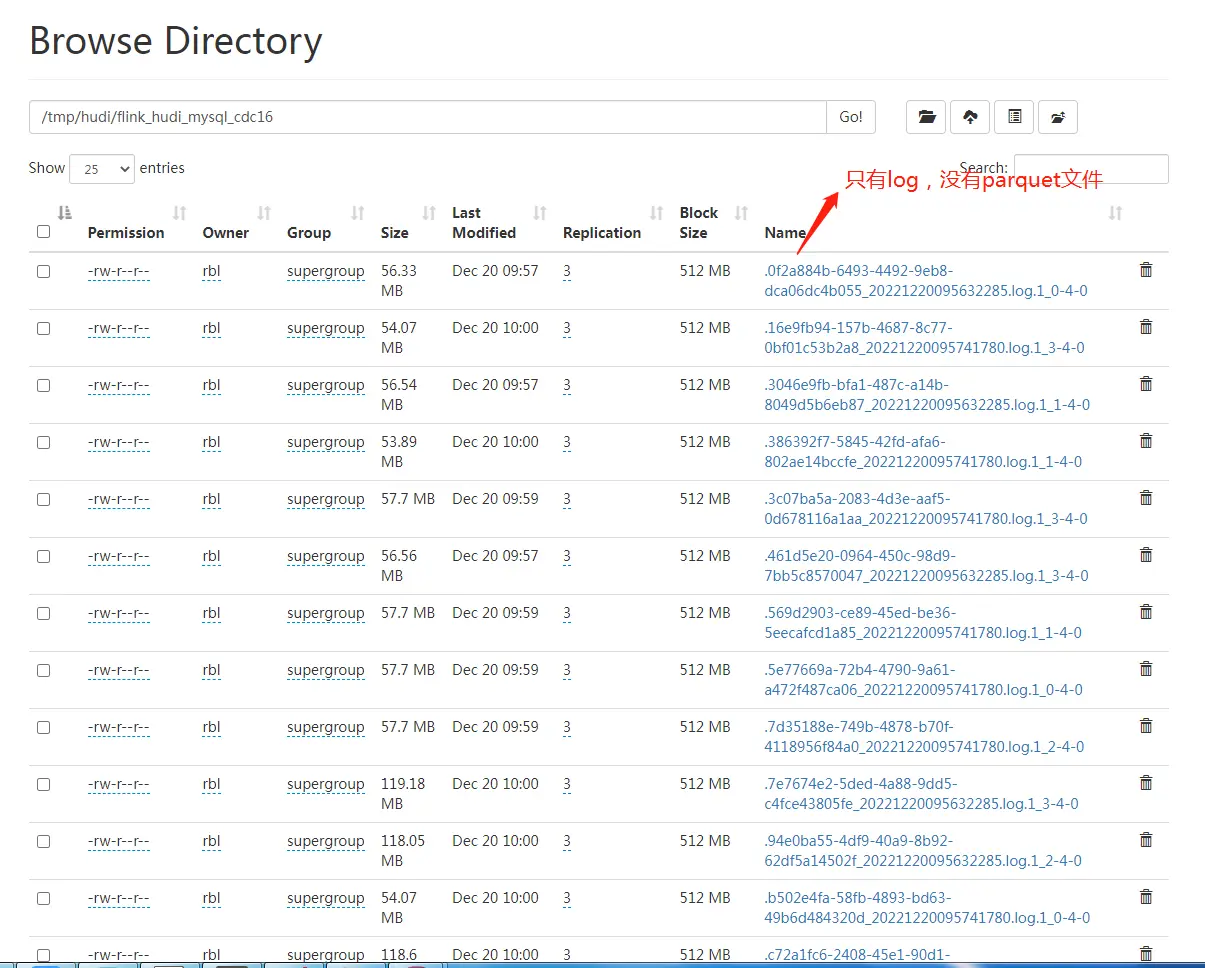
可以先观察 log,搜索 compaction 关键词, 看是否有 compact 任务调度:
After filtering, Nothing to compact for 关键词说明本次 compaction stratefy是不做压缩。
MOR表只有log 没有parquet
4.2 解决方案1(测试未通过)
网上的案例,要求加上这个:
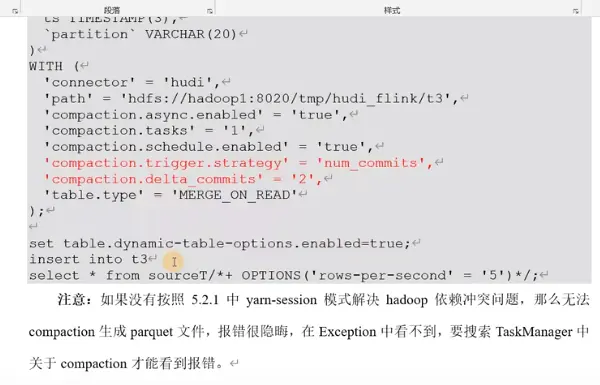
将jar包拷贝过去:
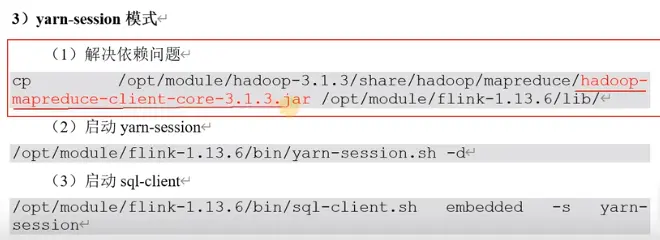
结果:
问题依旧,依然只有log文件,没有parquet文件。
4.2 解决方案2(测试通过:)
Hudi还支持离线手动Compaction,然后我就手工执行Compaction命令。
flink run -c org.apache.hudi.sink.compact.HoodieFlinkCompactor /home/flink-1.14.5/lib/hudi-flink1.14-bundle-0.12.1.jar --path hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc8
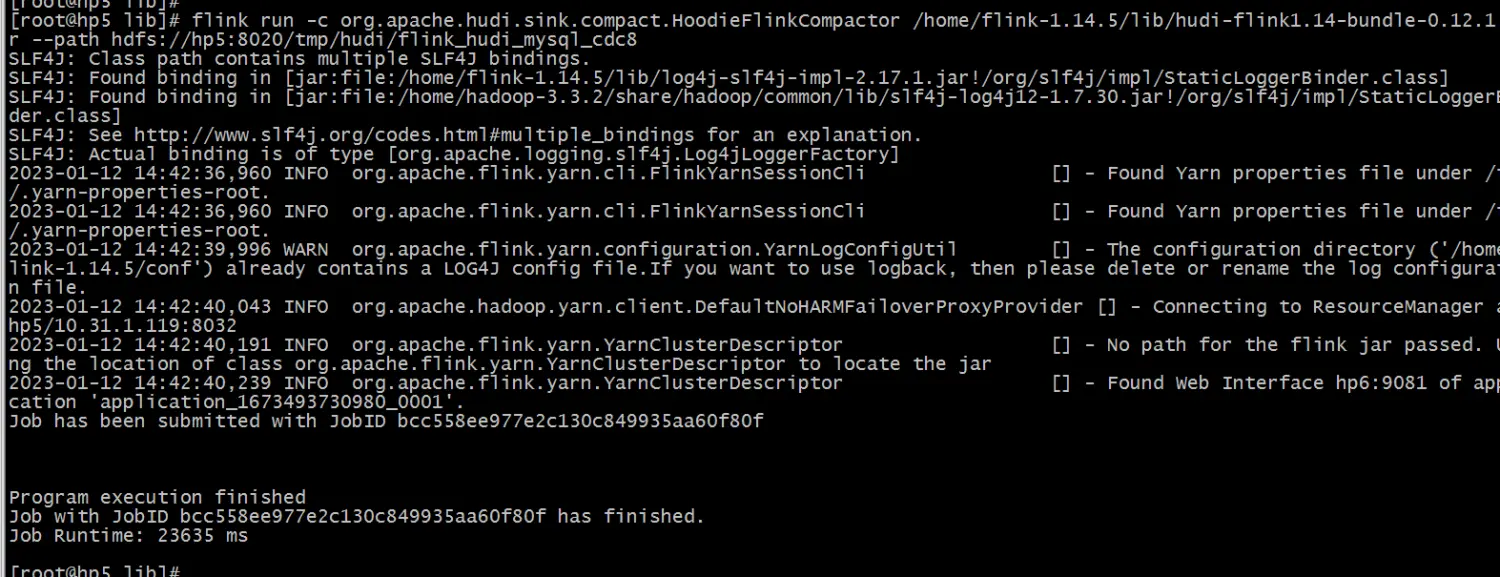
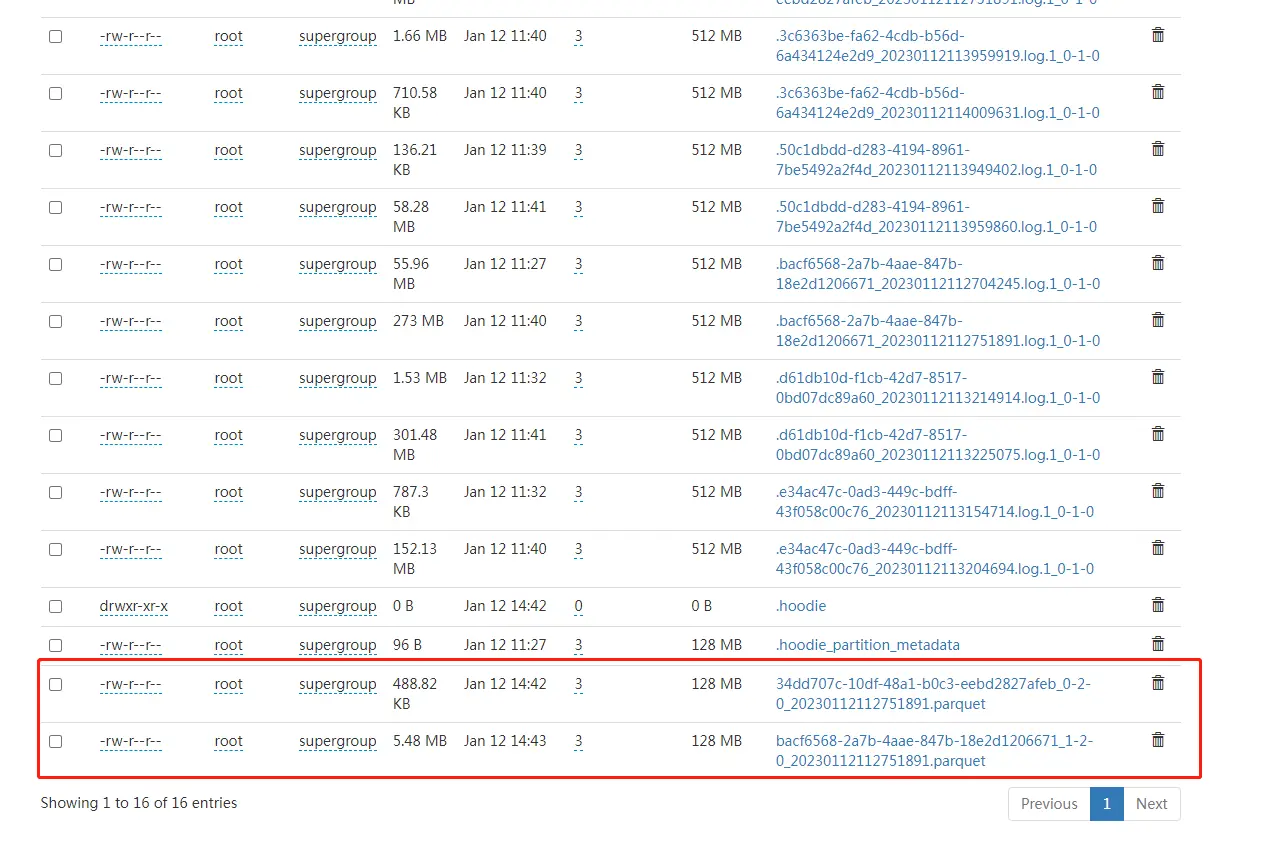
终于有parquet文件了:
4.3 原来是配置的问题
我最开始创建Hudi表,将Compaction设置为了flase,改为true即可,无需手工进行compaction
原始脚本:
CREATE TABLE flink_hudi_mysql_cdc8(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc8',
'table.type' = 'MERGE_ON_READ',
'changelog.enabled' = 'true',
'hoodie.datasource.write.recordkey.field' = 'id',
'write.precombine.field' = 'name',
'compaction.async.enabled' = 'false'
);
修改后:
CREATE TABLE flink_hudi_mysql_cdc8(
id BIGINT NOT NULL PRIMARY KEY NOT ENFORCED,
name varchar(100)
) WITH (
'connector' = 'hudi',
'path' = 'hdfs://hp5:8020/tmp/hudi/flink_hudi_mysql_cdc8',
'table.type' = 'MERGE_ON_READ',
'changelog.enabled' = 'true',
'hoodie.datasource.write.recordkey.field' = 'id',
'write.precombine.field' = 'name',
'compaction.async.enabled' = 'true'
);
参考:
- https://www.bilibili.com/video/BV1ue4y1i7na/
![[LitCTF 2023]Flag点击就送!(cookie伪造)](https://img-blog.csdnimg.cn/d5efae44feeb4ee68a05b93ca4e744b9.png)