目录
- 1.auto关键字(C++11)
- 1.1auto简介
- 1.2auto的使用细则
- 1.3auto函数不能推导的场景
- 1.auto不能作为函数的参数
- 2.auto不能直接用来声明数组
- 2.基于范围的for循环(C++)
- 2.1范围for循环的语法
- 2.2使用auto的for循环
- 2.3基于for循环的使用条件
- 3.指针空值nullptr(C++11)
- 4.内联函数
- 4.1内联函数概念
- 4.2内联函数的特性
- 5.总结
1.auto关键字(C++11)
1.1auto简介
C++11中auto的全新的含义:
auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时推导而得。
#include<iostream>
using namespace std;
int main()
{
int a = 10;
double b = 1.1;
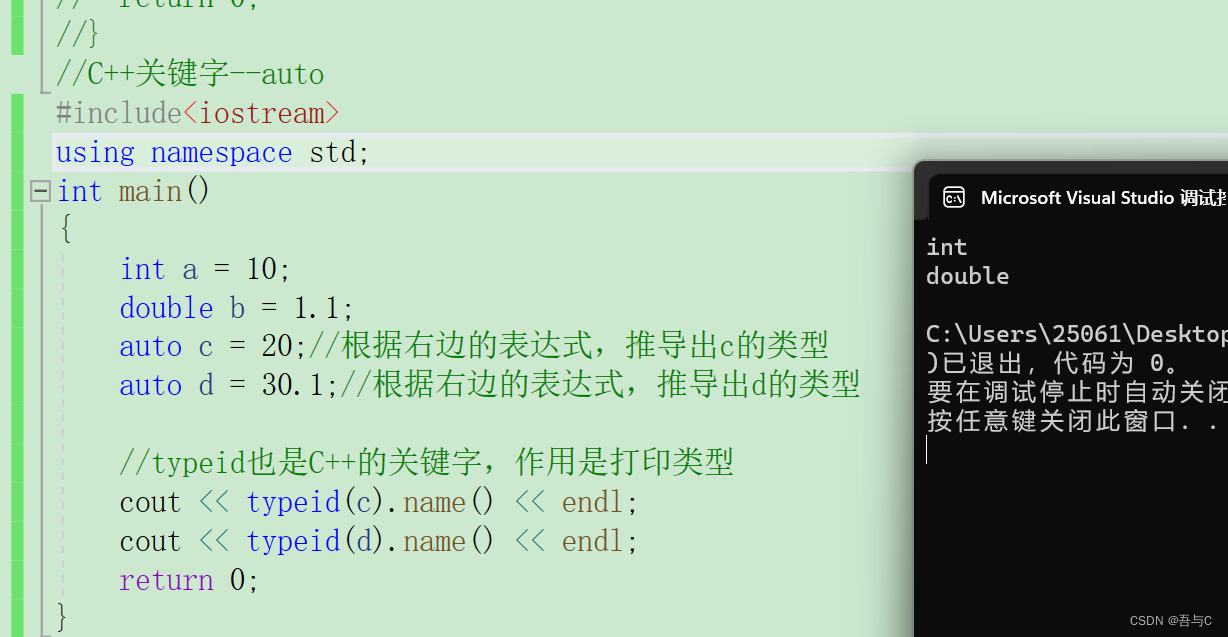
auto c = 20;//根据右边的表达式,推导出c的类型
auto d = 30.1;//根据右边的表达式,推导出d的类型
//typeid也是C++的关键字,作用是打印类型
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
代码运行的结果为:
注意: 使用
auto定义的变量时必须对其进行初始化,在编译阶段编译器需要根据初始化的表达式来推导auto的实际类型,因此auto并非是一种“类型”的声明,而是类型声明的“占位符”,编译器在编译时会将auto替换成变量实际的类型。
1.2auto的使用细则
1.
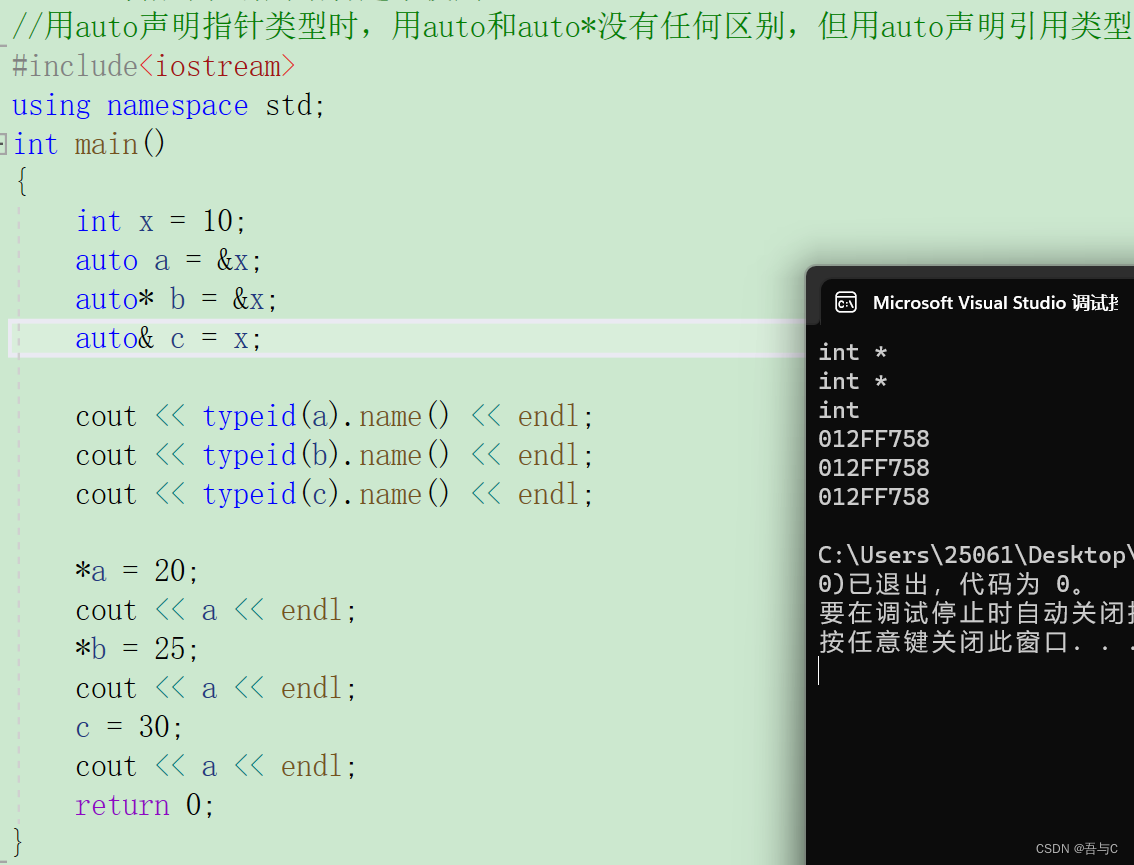
auto与指针和引用结合起来使用,用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时必须加&。
#include<iostream>
using namespace std;
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
cout << a << endl;
*b = 25;
cout << a << endl;
c = 30;
cout << a << endl;
return 0;
}
代码运行的结果为:
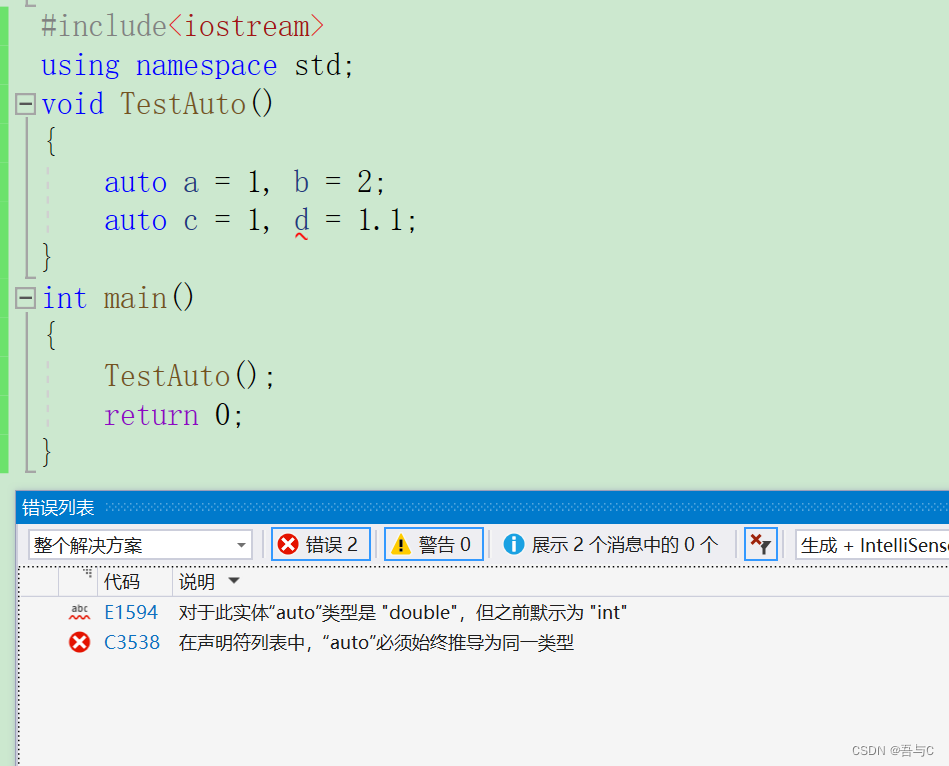
2.当在同一行定义多个变量时,这些变量的类型必须相同,编译器是根据第一个变量的表达式进行推导的,然后根据推导出来的变量类型定义其他变量,如果不相同编译器就会报错
#include<iostream>
using namespace std;
void TestAuto()
{
auto a = 1, b = 2;
auto c = 1, d = 1.1;
}
int main()
{
TestAuto();
return 0;
}
代码运行的结果为:
1.3auto函数不能推导的场景
1.auto不能作为函数的参数
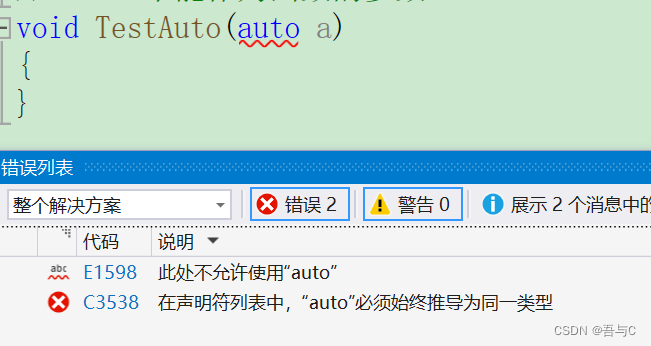
//1.auto不能作为函数的参数
//此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的类型进行推导
void TestAuto(auto a)
{
}
编译器报错的结果:
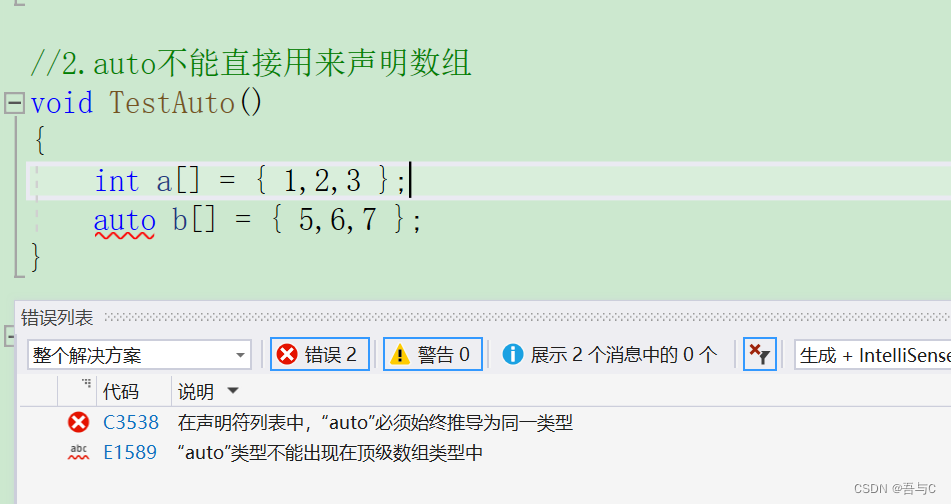
2.auto不能直接用来声明数组
void TestAuto()
{
int a[] = { 1,2,3 };
auto b[] = { 5,6,7 };
}
编译器报错的结果:
2.基于范围的for循环(C++)
2.1范围for循环的语法
#include<iostream>
using std::cout;
using std::endl;
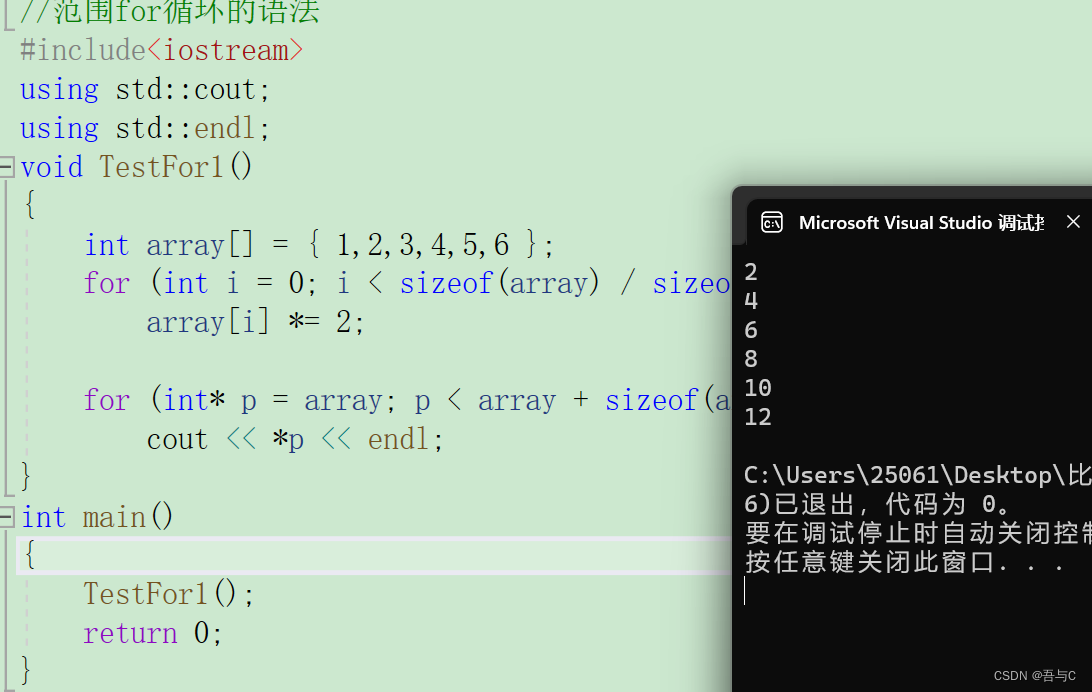
void TestFor1()
{
int array[] = { 1,2,3,4,5,6 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); p++)
cout << *p << endl;
}
int main()
{
TestFor1();
return 0;
}
代码运行的结果为:
2.2使用auto的for循环
#include<iostream>
using std::cout;
using std::endl;
void TestForAuto()
{
int Array[] = { 1,2,3,4,5,6 };
for (auto& e : Array)
e *= 2;
for (auto& e : Array)
cout << e << " ";
}
//使用auto后相当于把数组的每个元素取别名为e,然后对e进行操作,遍历数组工作编译器自动完成
int main()
{
TestForAuto();
return 0;
}
代码运行的结果为:
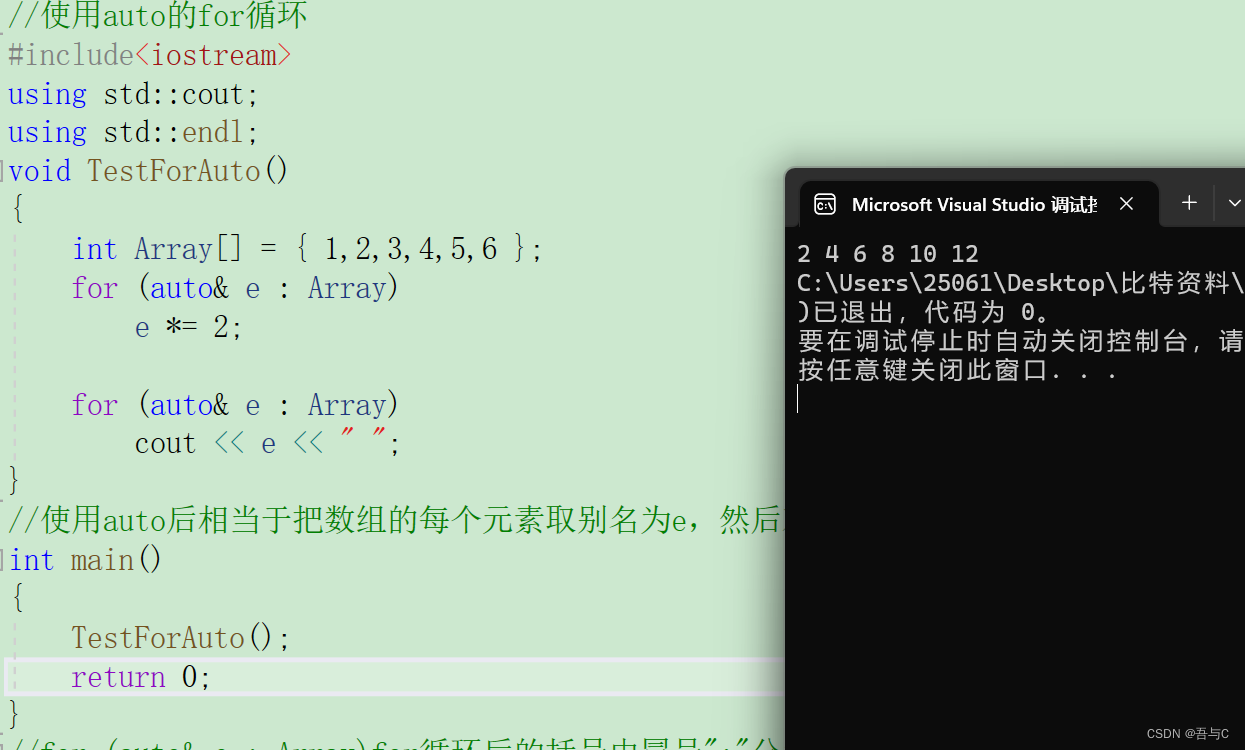
总结: for (auto& e : Array)for循环后的括号由冒号":"分为两部分:第一部分是范围内的迭代变量第二部分则表示被迭代的范围;注意:与普通循环一样,可以用continue来结束本次循环,也可以用break跳出整个循环。
2.3基于for循环的使用条件
#include<iostream>
using std::cout;
using std::endl;
void TestFor(int arry[])
{
for (auto& e : array)
cout << e << endl;
}
编译器报错的结果:
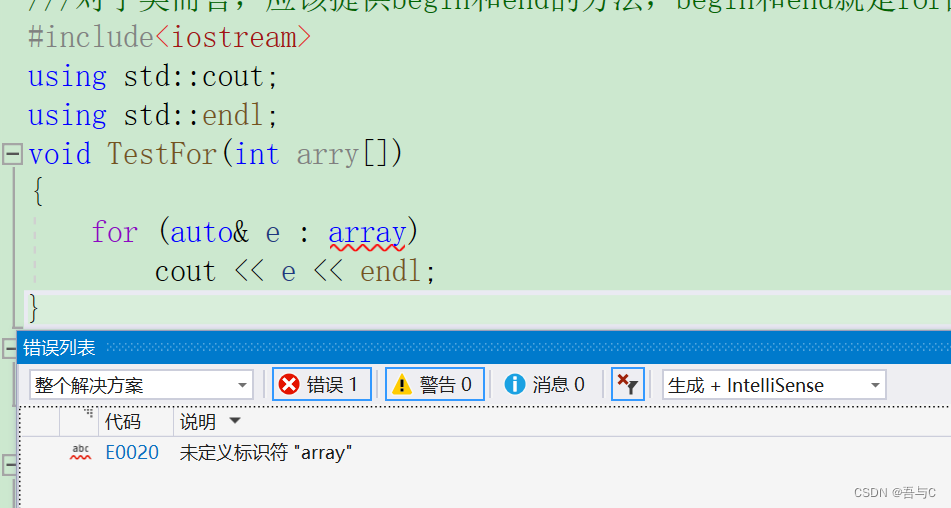
上面的代码有问题,
for (auto& e : array),array是指针,不是数组,所以不可以使用auto
1.for循环迭代的范围必须是确定的。对于数组而言就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for的迭代的范围;2.迭代的对象要实现++和==的操作。
3.指针空值nullptr(C++11)
C++98中的指针空值,在之前C语言的学习中,声明指针变量的时候,我们需要进行初始化。
//指针的初始化如下
void TestPtr()
{
int* p1 = NULL;
int* p2 = 0;
}
NULL实际上是一个宏,在传统的C头文件stddef.h中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量,不论哪种定义,在使用空指针的时候都会遇到一些麻烦
情况如下:
#include<iostream>
using std::cout;
using std::endl;
void Func(int)
{
cout << "void Func()" << endl;
}
void Func(int*)
{
cout << "void Func(int*)" << endl;
}
int main()
{
Func(0);
Func(NULL);
Func((int*)NULL);//通过NULL调用指针版本的Func(int*)函数
return 0;
}
代码运行的结果为:
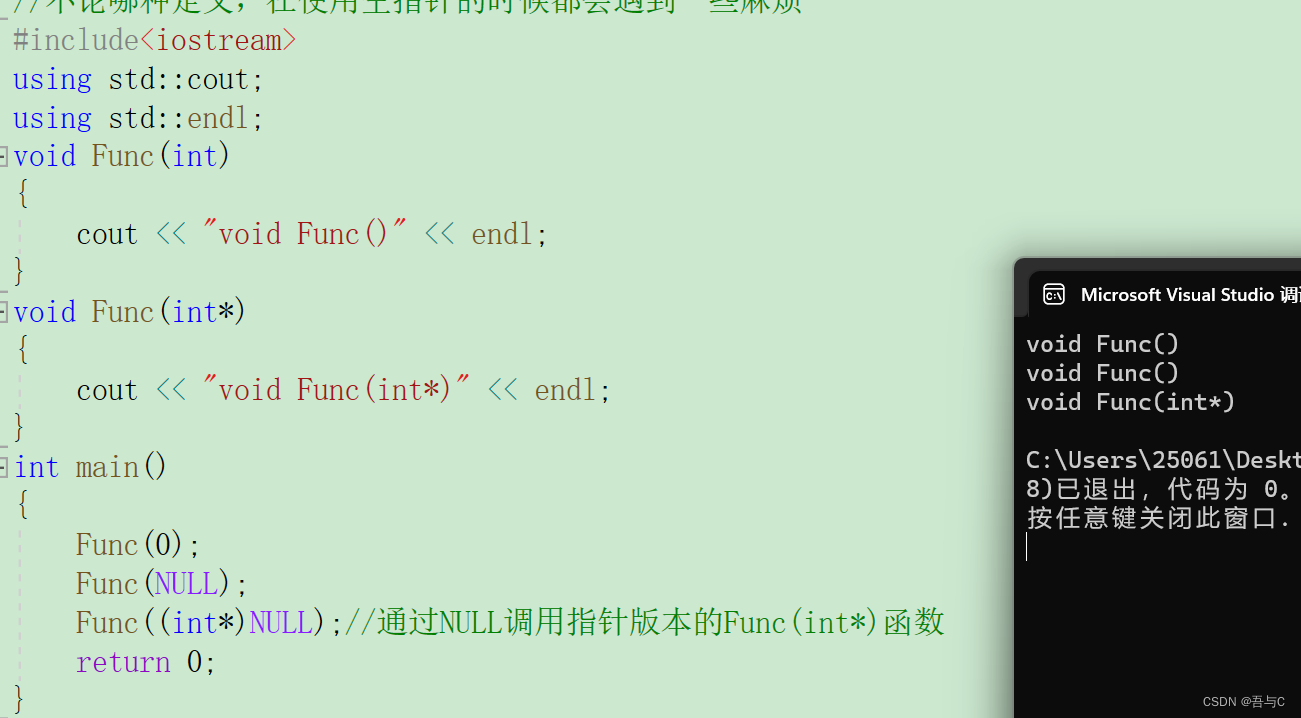
在C++98中,字面常量0既可以是一个整型数字,也可以是无类型的指针
void*常量,但是编译器默认情况下将其看成是一个整型变量,如果要将其按照指针的方式来使用,必须对其进行强转void*。
正确使用的栗子:
//正确调用Func(int*)函数应该使用nullptr
#include<iostream>
using std::cout;
using std::endl;
void Func(int)
{
cout << "void Func()" << endl;
}
void Func(int*)
{
cout << "void Func(int*)" << endl;
}
int main()
{
Func(0);
Func(nullptr);
return 0;
}
代码运行的结果为:
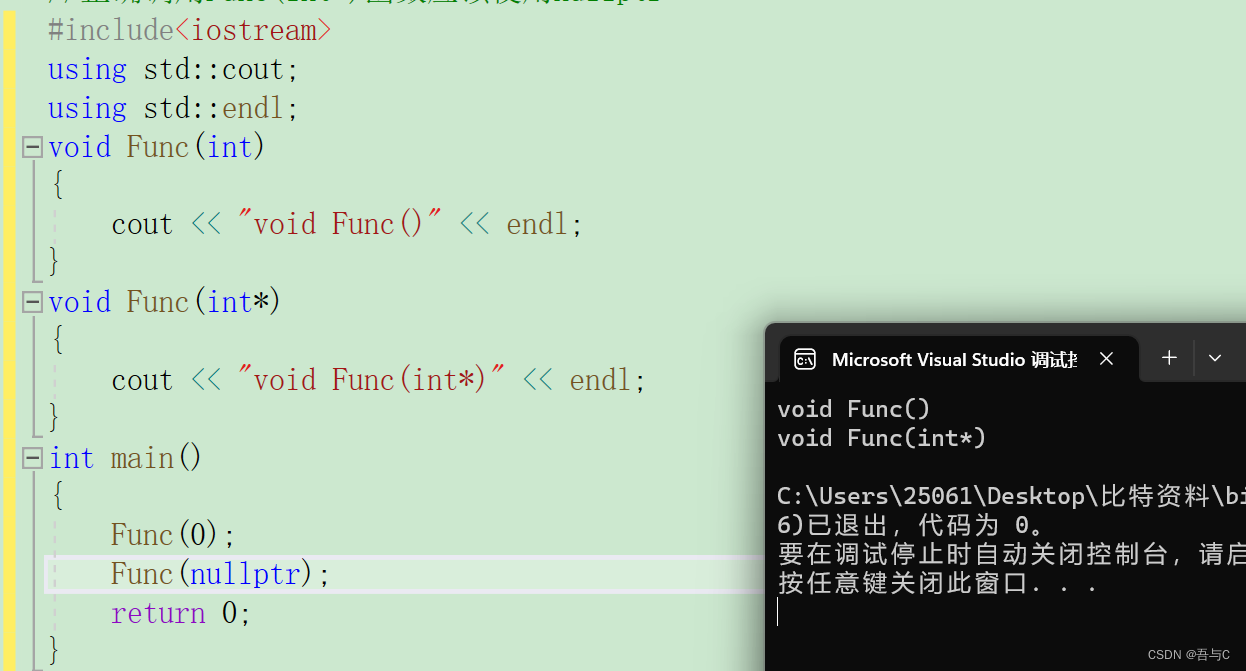
注意: 1.在使用
nullptr的时候不需要包含头文件,因为nullptr是C++作为新关键字引入的;2.C++中,sizeof(nullptr)与sizeof((void*)0)所占的字节数相同。;3.为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
4.内联函数
我们正常调用函数的时候,编译器会进行压栈、出栈的操作(创建函数栈帧),当执行程序的时间小于创建栈帧的时间的时候(即代码量较小的时候),就会**“得不偿失”**。在C语言中,我们会使用宏代替函数。而在C++中引入了内联函数进行代替。
宏的优点:1.增强代码的复用性;2.提高性能
宏的缺点:1.不方便调试宏。(因为编译阶段进行了替换);2.导致代码可读性差,可维护性差,容易误用。
4.1内联函数概念
内联函数的概念: 以inline修饰的函数叫内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数能提升程序的运行效率。
//没有使用inline修饰
#include<iostream>
using std::cout;
using std::endl;
int Add(int left, int right)
{
return left + right;
}
int main()
{
int ret = 0;
ret = Add(1, 2);
return 0;
}
转化为汇编代码为:
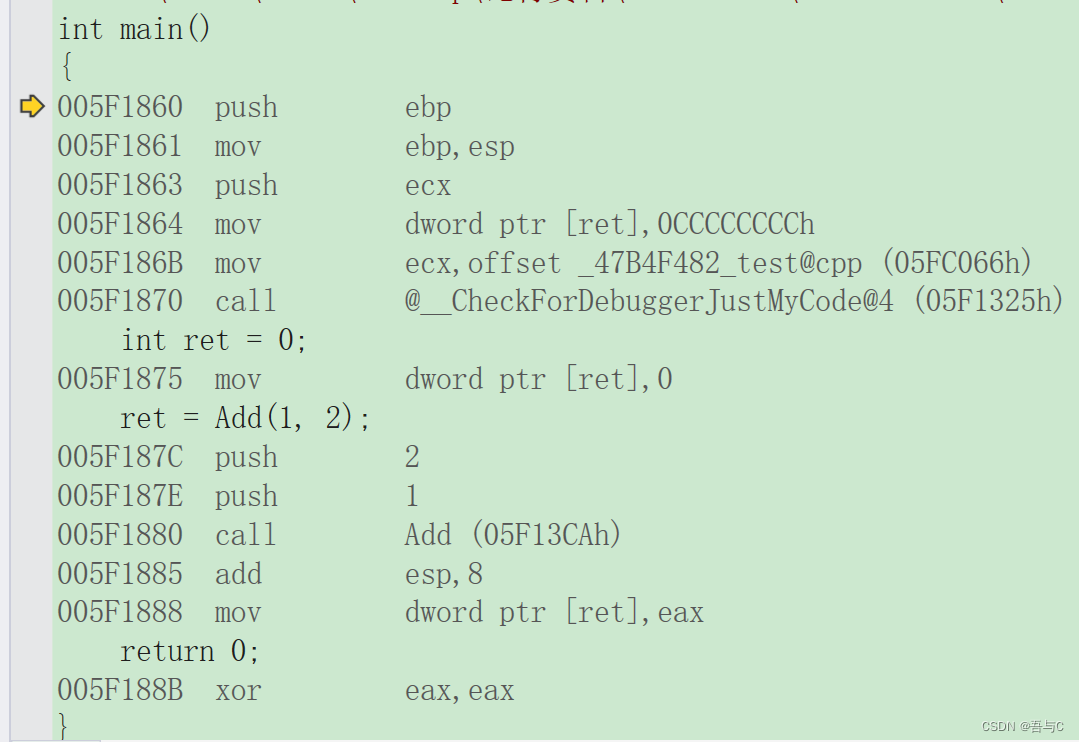
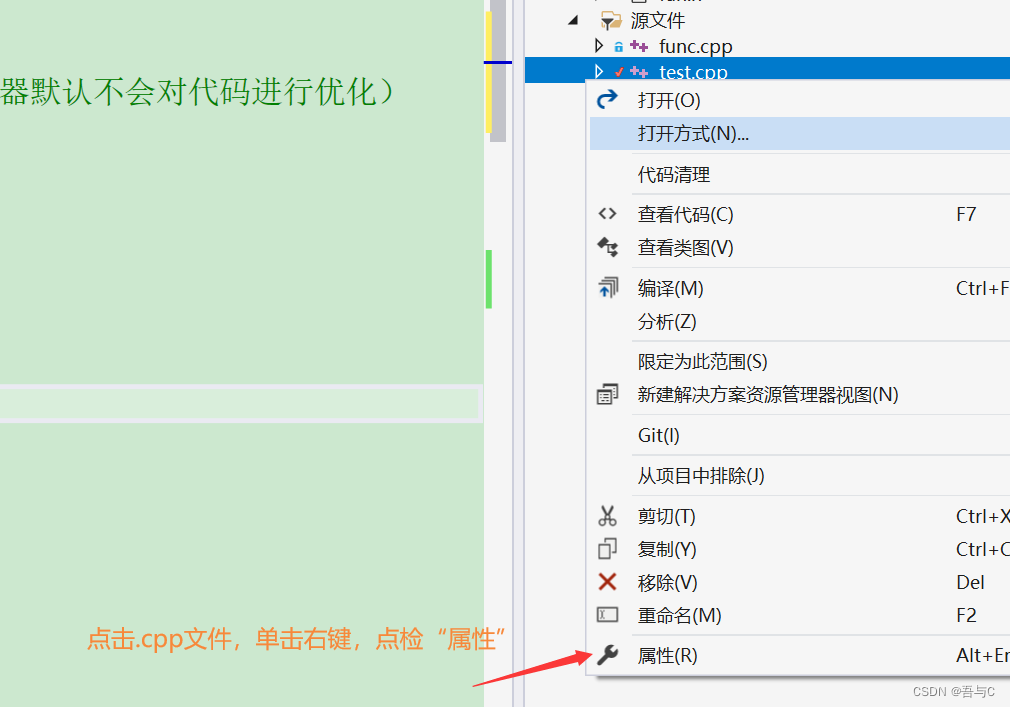
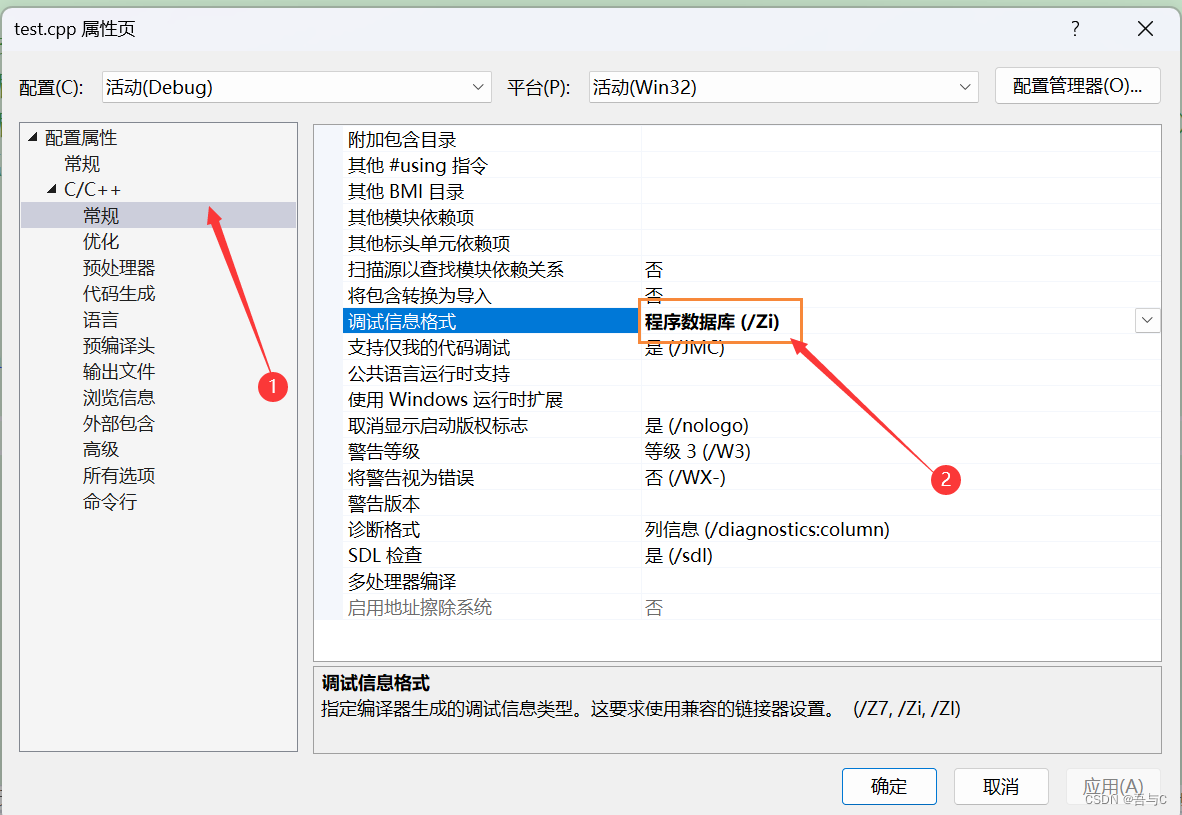
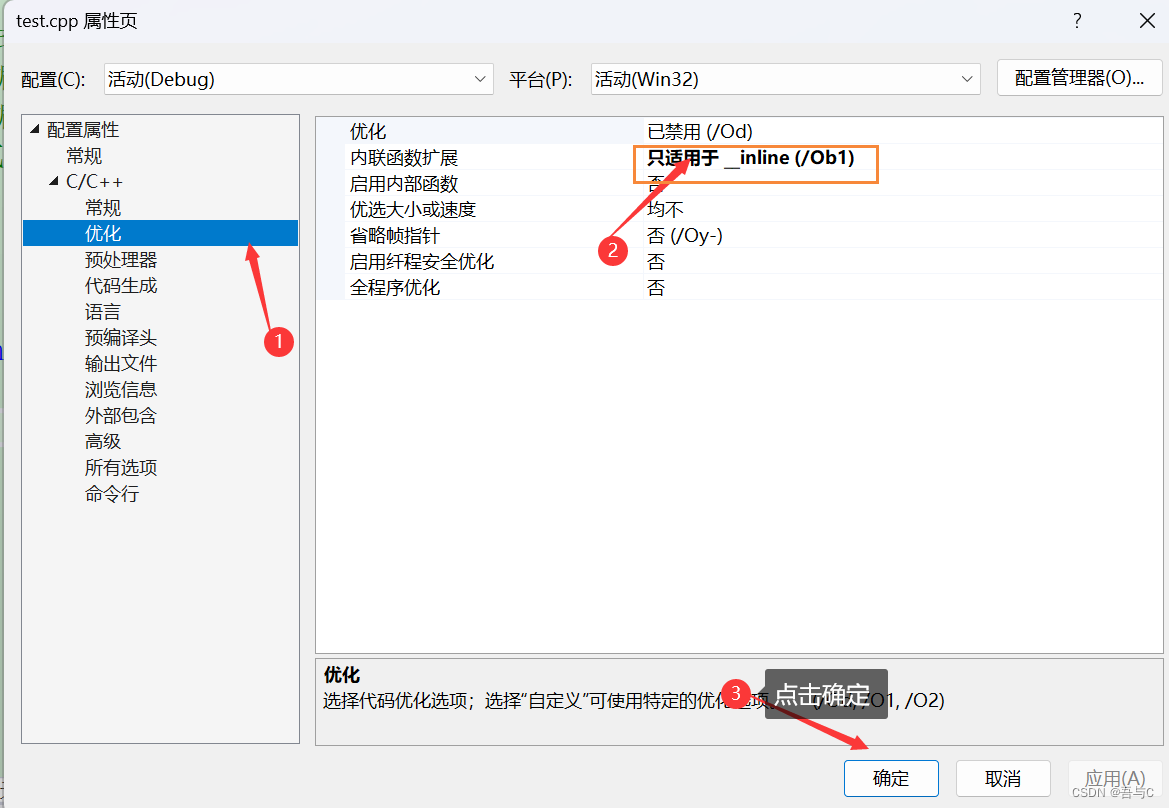
查看是否使用内联函数的方式
1.在release模式下,查看编译器生成的汇编代码是否存在Call Add。
2.在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化)。
debug版本操作如下:
//用inline修饰
#include<iostream>
using std::count;
using std::endl;
inline int Add(int left, int right)
{
return left + right;
}
int main()
{
int ret = 0;
ret = Add(1, 2);
return 0;
}
转化为汇编代码为:
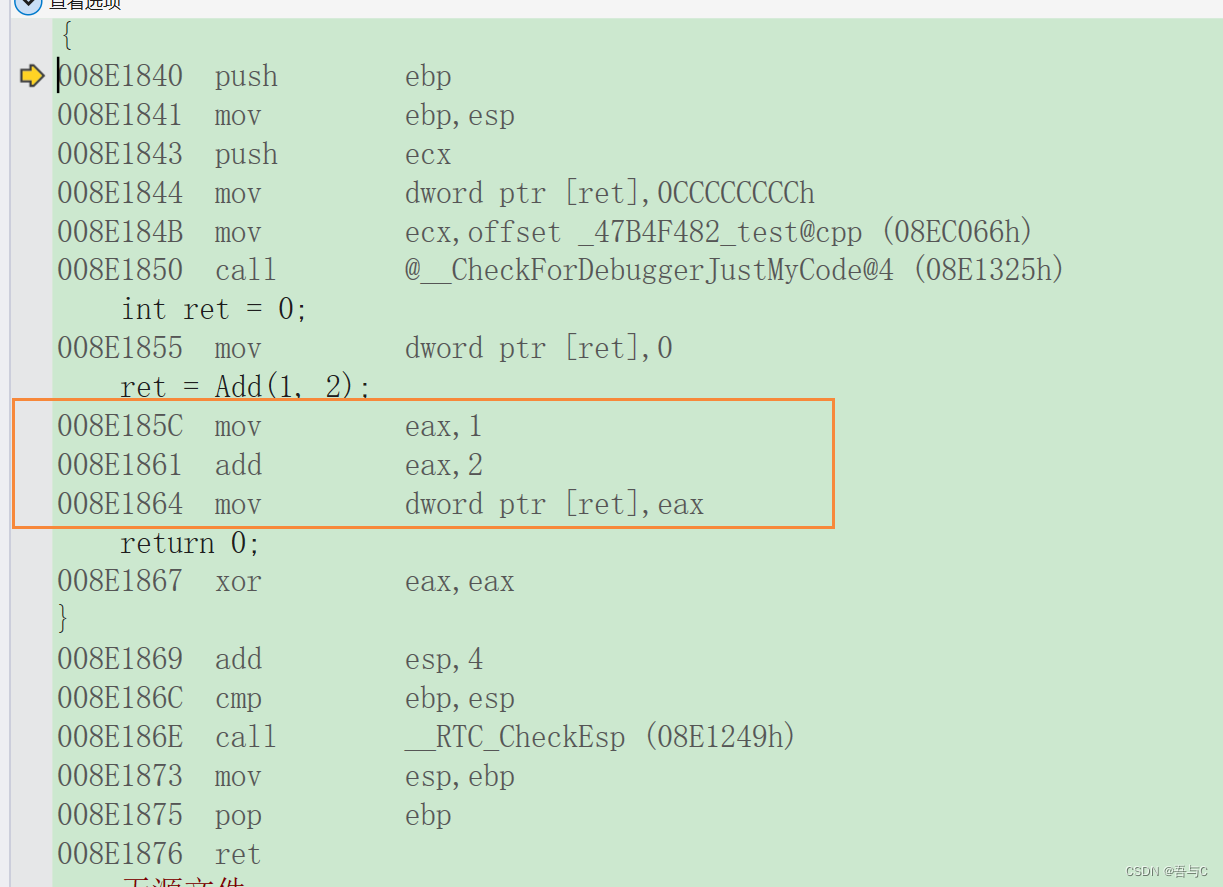
在正常调用函数的汇编代码中,需要进行压栈、出栈的操作;而在使用内联函数的代码中,则不需要创建函数栈帧,直接执行Add函数操作的汇编指令。
//func.h
#include<iostream>
using namespace std;
inline void f(int i);
//func.cpp
#include"fun.h"
void f(int i)
{
cout << i << endl;
}
//test.cpp
#include"fun.h"
int main()
{
f(10);
return 0;
}
编译器报错的结果:
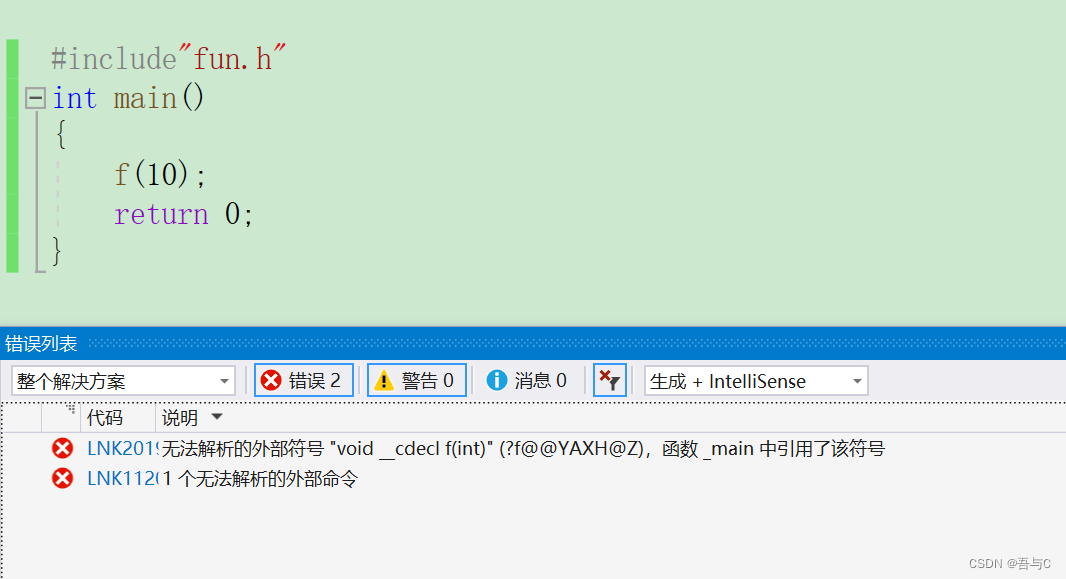
正确的示例:
#include<iostream>
using namespace std;
inline void f(int i)
{
cout << i << endl;
}
#include"fun.h"
int main()
{
f(10);
return 0;
}
代码运行的结果为:
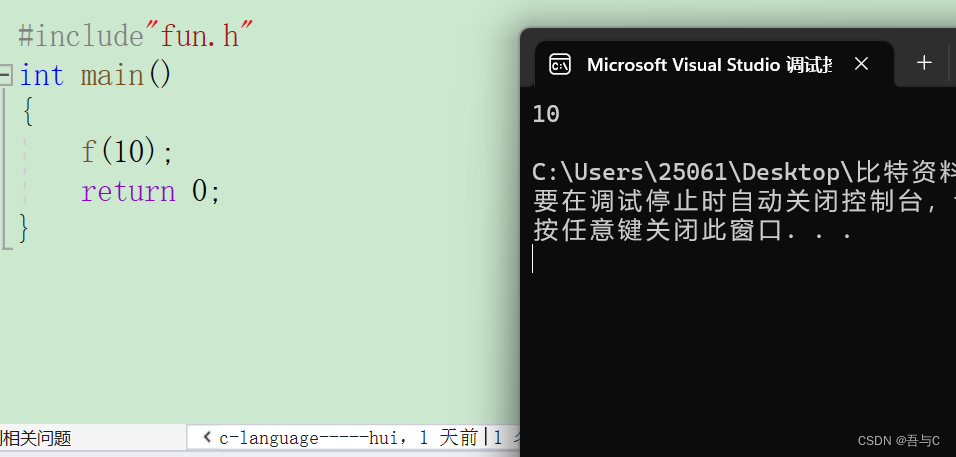
在编译的时候,
#include"fun.h"包含的内联函数f声明,编译器就回事f(10)展开,但是只有声明不能展开,所以只能call修饰的f函数的地址,然而在链接的时候,因为f是内联函数,它的地址不会进入符号表,call指令失效,发生链接错误。
4.2内联函数的特性
内联函数的特性
1.内联函数是一种以空间换时间的做法,如果编译器将函数当成内联函数处理会替换函数调用,缺陷:可能会使目标文件变大,优势:减少调用开销,提高程序运行效率。
2.inline对于编译仅仅只是一个建议,最终是否成为inline,取决于编译器。①比较长的函数②递归函数像类似这样的函数就像加了inline也会被编译器否决掉。
3.inline不建议声明和定义分离,分离会导致链接错误。建议内联函数声明定义在一起,即直接在func.h写内联函数的定义,#include"fun.h"包含的内联函数f定义,这样在编译的时候,使用内联函数的地方都会被展开,有定义,直接用,直接展开,不会有链接的问题。
5.总结
本章我们一起学习了C++auto关键字、内联函数的知识,希望能帮助大家进步了解C++!感谢大家阅读!如有不对,欢迎纠正!🍭🍭🍭