目录
一:[LitCTF 2023]snake
pyc文件magic修复:
pycdc工具转pyc文件为py文件:
[LitCTF 2023]enbase64
[LitCTF 2023]ez_XOR
[LitCTF 2023]For Aiur
在python38环境中将exe文件反编译为pyc文件
pycdc使用:
[LitCTF 2023]程序和人有一个能跑就行了
C++异常处理问题:
[LitCTF 2023]debase64
一:[LitCTF 2023]snake
打开附件,是一个pyc文件,尝试进行转py文件,没成功
后来,经过好学长提点,需要进行python文件magic的修复
pyc文件magic修复:
放到winhex里可以发现E3前面全是0,正常的pyc文件E3前面包含Magic Number和时间戳
Python3.3以下的版本中,只有Magic Number和四位时间戳
Python3.3到Python3.7(不包含3.7)版本中,只有Magic Number和八位时间戳 + 大小信息
Python3.7及以上版本的编译后二进制文件中,头部除了四字节Magic Number,还有四个字节的空位和八个字节的时间戳 + 大小信息,后者对文件反编译没有影响,全部填充0即可
不同的python版本对应不同的magic, 时间戳是这个文件处理的时间信息,其中magic影响文件的反编译,如果pyc文件缺失magic或者magic损坏,就可能出现无法反编译情况
此题是由pyhton.3.7版本编写,查看python.3.7的魔数,修复文件(这里可以参考一位大佬的文章:https://www.cnblogs.com/Here-is-SG/p/15885799.html)
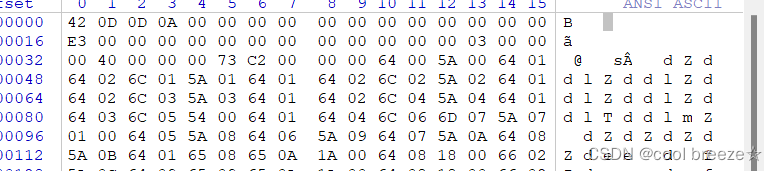
修复成功,注意:可以只修复前四位magic值,后面的时间戳数据可以直接为0
现在可以进行pyc文件转py,使用pycdc工具
pycdc工具转pyc文件为py文件:
使用指令
pycdc.exe 文件名.pyc
直接得到源码
import random
import sys
import time
import pygame
from pygame.locals import *
from collections import deque
SCREEN_WIDTH = 600
SCREEN_HEIGHT = 480
SIZE = 20
LINE_WIDTH = 1
SCOPE_X = (0, SCREEN_WIDTH // SIZE - 1)
SCOPE_Y = (2, SCREEN_HEIGHT // SIZE - 1)
FOOD_STYLE_LIST = [
(10, (255, 100, 100)),
(20, (100, 255, 100)),
(30, (100, 100, 255))]
LIGHT = (100, 100, 100)
DARK = (200, 200, 200)
BLACK = (0, 0, 0)
RED = (200, 30, 30)
BGCOLOR = (40, 40, 60)
def print_text(screen, font, x, y, text, fcolor = ((255, 255, 255),)):
imgText = font.render(text, True, fcolor)
screen.blit(imgText, (x, y))
def init_snake():
snake = deque()
snake.append((2, SCOPE_Y[0]))
snake.append((1, SCOPE_Y[0]))
snake.append((0, SCOPE_Y[0]))
return snake
def create_food(snake):
food_x = random.randint(SCOPE_X[0], SCOPE_X[1])
food_y = random.randint(SCOPE_Y[0], SCOPE_Y[1])
while (food_x, food_y) in snake:
food_x = random.randint(SCOPE_X[0], SCOPE_X[1])
food_y = random.randint(SCOPE_Y[0], SCOPE_Y[1])
return (food_x, food_y)
def get_food_style():
return FOOD_STYLE_LIST[random.randint(0, 2)]
def main():
pygame.init()
screen = pygame.display.set_mode((SCREEN_WIDTH, SCREEN_HEIGHT))
pygame.display.set_caption('\xe8\xb4\xaa\xe5\x90\x83\xe8\x9b\x87')
font1 = pygame.font.SysFont('SimHei', 24)
font2 = pygame.font.Font(None, 72)
(fwidth, fheight) = font2.size('GAME OVER')
b = True
snake = init_snake()
food = create_food(snake)
food_style = get_food_style()
pos = (1, 0)
game_over = True
start = False
score = 0
orispeed = 0.5
speed = orispeed
last_move_time = None
pause = False
while None:
for event in pygame.event.get():
if event.type == QUIT:
sys.exit()
continue
if event.type == KEYDOWN or event.key == K_RETURN or game_over:
start = True
game_over = False
b = True
snake = init_snake()
food = create_food(snake)
food_style = get_food_style()
pos = (1, 0)
score = 0
last_move_time = time.time()
continue
if not event.key == K_SPACE or game_over:
pause = not pause
continue
if not (event.key in (K_w, K_UP) or b) and pos[1]:
pos = (0, -1)
b = False
continue
if not (event.key in (K_s, K_DOWN) or b) and pos[1]:
pos = (0, 1)
b = False
continue
if not (event.key in (K_a, K_LEFT) or b) and pos[0]:
pos = (-1, 0)
b = False
continue
if not event.key in (K_d, K_RIGHT) and b and pos[0]:
pos = (1, 0)
b = False
screen.fill(BGCOLOR)
for x in range(SIZE, SCREEN_WIDTH, SIZE):
pygame.draw.line(screen, BLACK, (x, SCOPE_Y[0] * SIZE), (x, SCREEN_HEIGHT), LINE_WIDTH)
for y in range(SCOPE_Y[0] * SIZE, SCREEN_HEIGHT, SIZE):
pygame.draw.line(screen, BLACK, (0, y), (SCREEN_WIDTH, y), LINE_WIDTH)
if not game_over:
curTime = time.time()
if not curTime - last_move_time > speed and pause:
b = True
last_move_time = curTime
next_s = (snake[0][0] + pos[0], snake[0][1] + pos[1])
if next_s == food:
snake.appendleft(next_s)
score += food_style[0]
speed = orispeed - 0.03 * (score // 100)
food = create_food(snake)
food_style = get_food_style()
elif next_s[0] <= next_s[0] or next_s[0] <= SCOPE_X[1]:
pass
else:
SCOPE_X[0]
elif next_s[1] <= next_s[1] or next_s[1] <= SCOPE_Y[1]:
pass
else:
SCOPE_Y[0]
elif next_s not in snake:
snake.appendleft(next_s)
snake.pop()
else:
game_over = True
if not game_over:
pygame.draw.rect(screen, food_style[1], (food[0] * SIZE, food[1] * SIZE, SIZE, SIZE), 0)
for s in snake:
pygame.draw.rect(screen, DARK, (s[0] * SIZE + LINE_WIDTH, s[1] * SIZE + LINE_WIDTH, SIZE - LINE_WIDTH * 2, SIZE - LINE_WIDTH * 2), 0)
print_text(screen, font1, 450, 7, f'''\xe5\xbe\x97\xe5\x88\x86: {score}''')
if score > 1000:
flag = [
30,
196,
52,
252,
49,
220,
7,
243,
3,
241,
24,
224,
40,
230,
25,
251,
28,
233,
40,
237,
4,
225,
4,
215,
40,
231,
22,
237,
14,
251,
10,
169]
for i in range(0, len(flag), 2):
flag[i] = flag[i + 1] ^ 136
flag[i + 1] = flag[i] ^ 119
print_text(screen, font2, (SCREEN_WIDTH - fwidth) // 2, (SCREEN_HEIGHT - fheight) // 2, bytes(flag).decode(), RED)
pygame.display.update()
if game_over and start:
print_text(screen, font2, (SCREEN_WIDTH - fwidth) // 2, (SCREEN_HEIGHT - fheight) // 2, 'GAME OVER', RED)
pygame.display.update()
if __name__ == '__main__':
main()写脚本解密:
#include<stdio.h>
#include<string.h>
int main(){
char flag [] = {
30,
196,
52,
252,
49,
220,
7,
243,
3,
241,
24,
224,
40,
230,
25,
251,
28,
233,
40,
237,
4,
225,
4,
215,
40,
231,
22,
237,
14,
251,
10,
169};
int i,j;
for(i=0;i<strlen(flag);i+=2){
j=flag[i];
flag[i] = flag[i + 1] ^ 136;
flag[i + 1] = j ^ 119;
}
puts(flag);
return 0;
}[LitCTF 2023]enbase64
打开文件,查壳,发现无壳
__main();
memset(Str, 0, 1000);
memset(Str1, 0, sizeof(Str1));
*Source = *"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
strcpy(v5, "9+/");
qmemcpy(&Source[1], &aAbcdefghijklmn[-(Source - &Source[1])], 4 * (((Source - &Source[1] + 65) & 0xFFFFFFFC) >> 2));
puts("Please input flag:");
gets(Str);
if ( strlen(Str) == 33 )
{
base64(Source, Str, Str1);
basecheck(Str1);
}
return 0;
}分析代码可以发现,strcp(v5..)和qmemcpy函数没有实际作用, &aAbcdefghijklmn里面还是base64表,qmemcpy函数实际上是qmemcpy(&Source[1],&aAbcdefghijklmn[1]..)所以base64表根本没变
但看到下面的函数bas64()可以发现里面有换表操作
{
signed int result; // eax
signed int v4; // [esp+14h] [ebp-14h]
signed int i; // [esp+18h] [ebp-10h]
int v6; // [esp+1Ch] [ebp-Ch]
basechange(Source);
v4 = strlen(Str);
v6 = 0;
for ( i = 0; ; i += 3 )
{
result = i;
if ( i >= v4 )
break;
a3[v6] = Source[Str[i] >> 2];
a3[v6 + 1] = Source[(16 * Str[i]) & 0x30 | (Str[i + 1] >> 4)];
a3[v6 + 2] = Source[(4 * Str[i + 1]) & 0x3C | (Str[i + 2] >> 6)];
a3[v6 + 3] = Source[Str[i + 2] & 0x3F];
v6 += 4;
}
return result;
}可以发现,刚开始会有一个basechange()函数,然后下面是base64加密过程,进入basechang()函数查看
char *__cdecl basechange(char *Source)
{
char *result; // eax
char Destination[65]; // [esp+13h] [ebp-155h] BYREF
int v3[65]; // [esp+54h] [ebp-114h] BYREF
int j; // [esp+158h] [ebp-10h]
int i; // [esp+15Ch] [ebp-Ch]
memset(v3, 0, sizeof(v3));
v3[0] = 16;
v3[1] = 34;
v3[2] = 56;
v3[3] = 7;
v3[4] = 46;
v3[5] = 2;
v3[6] = 10;
v3[7] = 44;
v3[8] = 20;
v3[9] = 41;
v3[10] = 59;
v3[11] = 31;
v3[12] = 51;
v3[13] = 60;
v3[14] = 61;
v3[15] = 26;
v3[16] = 5;
v3[17] = 40;
v3[18] = 21;
v3[19] = 38;
v3[20] = 4;
v3[21] = 54;
v3[22] = 52;
v3[23] = 47;
v3[24] = 3;
v3[25] = 11;
v3[26] = 58;
v3[27] = 48;
v3[28] = 32;
v3[29] = 15;
v3[30] = 49;
v3[31] = 14;
v3[32] = 37;
v3[34] = 55;
v3[35] = 53;
v3[36] = 24;
v3[37] = 35;
v3[38] = 18;
v3[39] = 25;
v3[40] = 33;
v3[41] = 43;
v3[42] = 50;
v3[43] = 39;
v3[44] = 12;
v3[45] = 19;
v3[46] = 13;
v3[47] = 42;
v3[48] = 9;
v3[49] = 17;
v3[50] = 28;
v3[51] = 30;
v3[52] = 23;
v3[53] = 36;
v3[54] = 1;
v3[55] = 22;
v3[56] = 57;
v3[57] = 63;
v3[58] = 8;
v3[59] = 27;
v3[60] = 6;
v3[61] = 62;
v3[62] = 45;
v3[63] = 29;
result = strcpy(Destination, Source);
for ( i = 0; i <= 47; ++i )
{
for ( j = 0; j <= 63; ++j )
Source[j] = Destination[v3[j]];
result = strcpy(Destination, Source);
}
return result;
}是换表没错了, 每次将v3的值作为下标在base64表中查找,查找到的值赋给base64密码表,重复64次,可以写一个脚本,解出新的base64密码表
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
int i=0,j;
char a[65]="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
char b[65];
unsigned int v3[65];
char Source[65];
v3[0] = 16;
v3[1] = 34;
v3[2] = 56;
v3[3] = 7;
v3[4] = 46;
v3[5] = 2;
v3[6] = 10;
v3[7] = 44;
v3[8] = 20;
v3[9] = 41;
v3[10] = 59;
v3[11] = 31;
v3[12] = 51;
v3[13] = 60;
v3[14] = 61;
v3[15] = 26;
v3[16] = 5;
v3[17] = 40;
v3[18] = 21;
v3[19] = 38;
v3[20] = 4;
v3[21] = 54;
v3[22] = 52;
v3[23] = 47;
v3[24] = 3;
v3[25] = 11;
v3[26] = 58;
v3[27] = 48;
v3[28] = 32;
v3[29] = 15;
v3[30] = 49;
v3[31] = 14;
v3[32] = 37;
v3[34] = 55;
v3[35] = 53;
v3[36] = 24;
v3[37] = 35;
v3[38] = 18;
v3[39] = 25;
v3[40] = 33;
v3[41] = 43;
v3[42] = 50;
v3[43] = 39;
v3[44] = 12;
v3[45] = 19;
v3[46] = 13;
v3[47] = 42;
v3[48] = 9;
v3[49] = 17;
v3[50] = 28;
v3[51] = 30;
v3[52] = 23;
v3[53] = 36;
v3[54] = 1;
v3[55] = 22;
v3[56] = 57;
v3[57] = 63;
v3[58] = 8;
v3[59] = 27;
v3[60] = 6;
v3[61] = 62;
v3[62] = 45;
v3[63] = 29;
strcpy(b, a);
for(i=0;i<=47;i++){
for ( j = 0; j <= 63; ++j )
a[j] =b[v3[j]];
strcpy(b, a);
}
puts(a);
return 0;
}
得到新表值为: gJ1BRjQie/FIWhEslq7GxbnL26M4+HXUtcpmVTKaydOP38of5v90ZSwrkYzCAuND
base()函数分析完,再返回主函数分析basecheck()函数
int __cdecl basecheck(char *Str1)
{
if ( !strcmp(Str1, "GQTZlSqQXZ/ghxxwhju3hbuZ4wufWjujWrhYe7Rce7ju") )
return puts("You are right!");
else
return puts("False");
}直接找到了加密后的数据,上脚本解密咯
import base64
import string
str = "GQTZlSqQXZ/ghxxwhju3hbuZ4wufWjujWrhYe7Rce7ju" # 欲解密的字符串
outtab = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" # 原生字母表
intab = "gJ1BRjQie/FIWhEslq7GxbnL26M4+HXUtcpmVTKaydOP38of5v90ZSwrkYzCAuND" # 换表之后的字母表
print (base64.b64decode(str.translate(str.maketrans(intab,outtab))))[LitCTF 2023]ez_XOR
__main();
strcpy(Str2, "E`}J]OrQF[V8zV:hzpV}fVF[t");
v9 = 0;
v10 = 0;
v11 = 0;
v12 = 0;
v13 = 0;
v14 = 0;
v15 = 0;
printf("Enter The Right FLAG:");
scanf("%s", Str1);
XOR(Str1, 3);
if ( !strcmp(Str1, Str2) )
{
printf("U Saved IT!\n");
return 0;
}
else
{
printf("Wrong!Try again!\n");
return main(v4, v5, v6);
}
}进入xor函数查看
size_t __cdecl XOR(char *Str, char a2)
{
size_t result; // eax
unsigned int i; // [esp+2Ch] [ebp-Ch]
for ( i = 0; ; ++i )
{
result = strlen(Str);
if ( i >= result )
break;
Str[i] ^= 3 * a2;
}
return result;
}一个异或过程,写脚本解密
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
int main(){
int i;
unsigned char arr[]="E`}J]OrQF[V8zV:hzpV}fVF[t";
for(i=0;i<25;i++){
arr[i] ^= 9;
printf("%c",arr[i]);
}
return 0;
}
//LitCTF{XOR_1s_3asy_to_OR}[LitCTF 2023]For Aiur
打开附件,可以看到是一个exe文件,用exeinfope查看可以看到是python编写的文件

在python38环境中将exe文件反编译为pyc文件
需要将exe文件反编译为pyc文件,进而得到py文件,拿到python源码
我们可以使用pyinstxtractor.py来将exe文件反编译为pyc文件。
注意:
此题必须使用python38环境,否则会导致编译文件缺失
如果原本是其它python环境,可以使用anaconda来切换环境
下载配置可以看这个文章:Anaconda安装及配置(详细版)_旅途中的宽~的博客-CSDN博客
相关指令可以看这篇文章:anaconda常用命令_anaconda指令-CSDN博客
- 将exe和pyinstxtractor.py放在同一级文件夹中
- 在下载配置好的anaconda中使用conda activate python38把环境换到python38中
- 在conda环境中切换到pyinstxtractor文件夹
- 使用指令:python pyinstxtractor 文件名.exe

这样再回到pyinstxtractor文件中就可以看到生成了extracted文件,进入查看可以找到同名.pyc文件和struct.py文件
- 将同名.py文件和struct.py文件放到winhex中
- 将struct.py文件头中E3前的数据复制到同名.py文件的E3前(此题的同名.py文件没有缺失magic,不用进行这两步)



Probee.pyc文件的magic没有缺失,可以直接编译
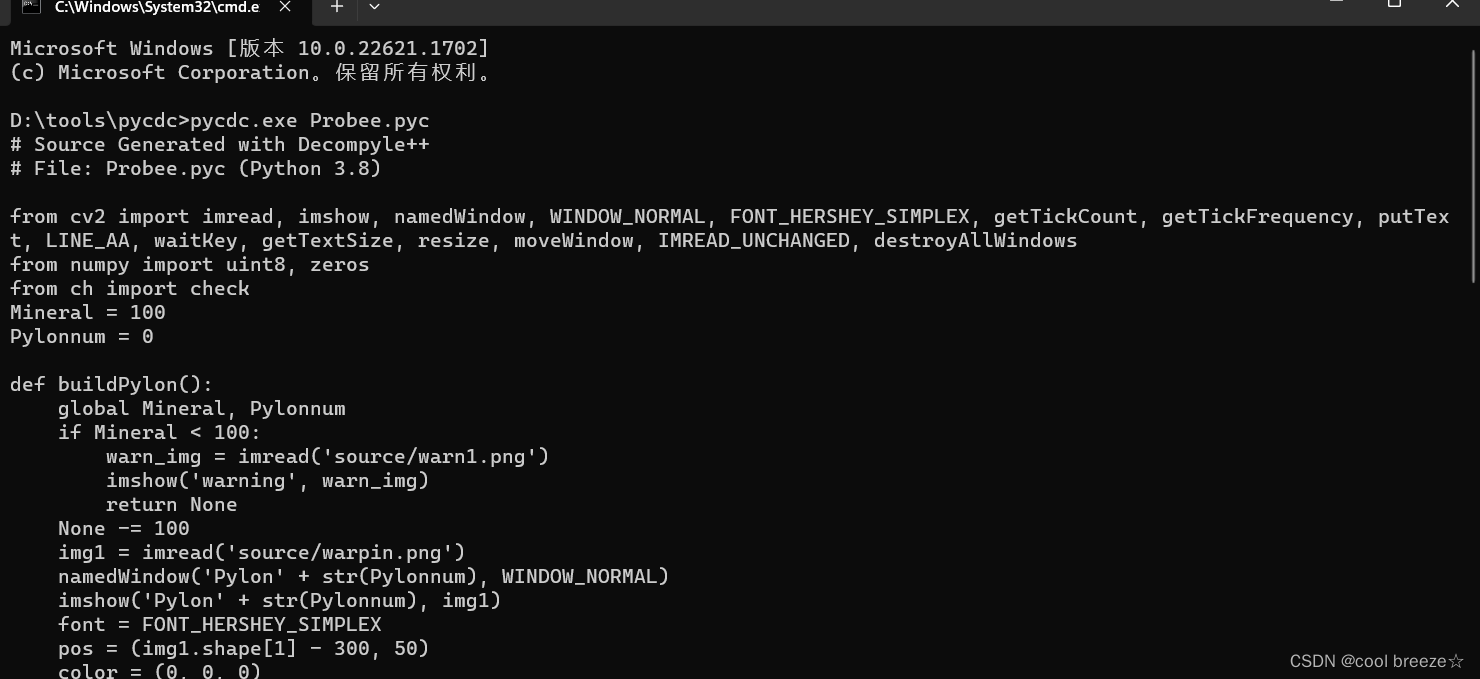
接着使用pycdc工具将pyc文件反编译为py文件,得到python源码
pycdc使用:
1.将文件放到pycdc同级文件夹中
2.使用指令pycdc.exe 文件.pyc
这样就可以得到python源码
注意:单看这一个源码无法得到flag,还生成了一个extracted文件(如果之前不是在python3.8环境中反编译exe文件,这个ectracted文件夹里就不会有内容哦),里面有需要的ch.pyc文件(大坑,好难想到)


重复上面pycdc工具使用操作,将ch.pyc编译为ch,py,得到ch.py源码

Probee源码:
from cv2 import imread, imshow, namedWindow, WINDOW_NORMAL, FONT_HERSHEY_SIMPLEX, getTickCount, getTickFrequency, putText, LINE_AA, waitKey, getTextSize, resize, moveWindow, IMREAD_UNCHANGED, destroyAllWindows
from numpy import uint8, zeros
from ch import check
Mineral = 100
Pylonnum = 0
def buildPylon():
global Mineral, Pylonnum
if Mineral < 100:
warn_img = imread('source/warn1.png')
imshow('warning', warn_img)
return None
None -= 100
img1 = imread('source/warpin.png')
namedWindow('Pylon' + str(Pylonnum), WINDOW_NORMAL)
imshow('Pylon' + str(Pylonnum), img1)
font = FONT_HERSHEY_SIMPLEX
pos = (img1.shape[1] - 300, 50)
color = (0, 0, 0)
thickness = 2
timer = getTickCount() + 18 * getTickFrequency()
if getTickCount() < timer:
img1_copy = img1.copy()
time_left = int((timer - getTickCount()) / getTickFrequency())
text = 'Time left: {}s'.format(time_left)
putText(img1_copy, text, pos, font, 1, color, thickness, LINE_AA)
imshow('Pylon' + str(Pylonnum), img1_copy)
if waitKey(1) & 255 == ord('q'):
pass
img2 = imread('source/Pylon.png')
imshow('Pylon' + str(Pylonnum), img2)
waitKey(1)
Pylonnum += 1
def gather():
global Mineral
digit_value = Mineral
icon_img = imread('source/jingtikuang.png', IMREAD_UNCHANGED)
icon_img = resize(icon_img, (120, 120))
bg_img = zeros(icon_img.shape, uint8, **('dtype',))
bg_img[(0:icon_img.shape[0], 0:icon_img.shape[1], :)] = icon_img
digit_text = str(digit_value)
digit_size = getTextSize(digit_text, FONT_HERSHEY_SIMPLEX, 1, 2)[0]
digit_x = bg_img.shape[1] - digit_size[0]
digit_y = digit_size[1] + 10
putText(bg_img, digit_text, (digit_x, digit_y), FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
imshow('Mineral', bg_img)
moveWindow('Mineral', 1200, 100)
Mineral += 5
img = imread('source/Probe.png')
(new_width, new_height) = (200, 200)
img = resize(img, (new_width, new_height))
(screen_width, screen_height) = (800, 120)
(x, y) = (600, 100)
(dx, dy) = (0, 5)
namedWindow('Probe', WINDOW_NORMAL)
imshow('Probe', img)
check(Pylonnum)
imshow('Probe', img)
if y < screen_height:
dy = 5
if y > screen_height:
dy = -5
x = x + dx
y = y + dy
moveWindow('Probe', x, y)
if waitKey(50) & 255 == ord('g'):
gather()
if waitKey(50) & 255 == ord('b'):
buildPylon()
if waitKey(50) & 255 == ord('e'):
pass
destroyAllWindows()ch.py源码:
enc = [
98,
77,
94,
91,
92,
107,
125,
66,
87,
70,
113,
92,
83,
70,
85,
81,
19,
21,
109,
99,
87,
107,
127,
65,
65,
64,
109,
87,
93,
90,
65,
64,
64,
65,
81,
3,
109,
85,
86,
80,
91,
64,
91,
91,
92,
0,
94,
107,
66,
77,
94,
91,
92,
71]
lis = []
def check(num):
flag = 'LitCTF{'
if num % 2 == 0 and num % 4 == 0 and num % 6 == 0 and num % 8 == 0 and num % 12 == 0 and num % 13 == 11:
k = str(num)
for i in range(len(enc)):
flag += chr(ord(k[i % len(k)]) ^ enc[i])
lis.append(ord(k[i % len(k)]) ^ enc[i])
flag += '}'
imread = imread
imshow = imshow
namedWindow = namedWindow
WINDOW_NORMAL = WINDOW_NORMAL
FONT_HERSHEY_SIMPLEX = FONT_HERSHEY_SIMPLEX
getTickCount = getTickCount
getTickFrequency = getTickFrequency
putText = putText
LINE_AA = LINE_AA
waitKey = waitKey
getTextSize = getTextSize
resize = resize
moveWindow = moveWindow
IMREAD_UNCHANGED = IMREAD_UNCHANGED
destroyAllWindows = destroyAllWindows
import cv2
uint8 = uint8
zeros = zeros
import numpy
img = zeros((200, 20000, 3), uint8)
img.fill(255)
text = flag
font = FONT_HERSHEY_SIMPLEX
pos = (50, 120)
color = (0, 0, 0)
thickness = 2
putText(img, text, pos, font, 1, color, thickness, LINE_AA)
imshow('flag', img)
waitKey(0)
destroyAllWindows()两个源码对比来看,该函数将数字num作为输入并检查它是否满足某些条件。如果满足条件,该函数通过在字符串的每个字符与加密列表的相应元素之间执行按位异或运算来生成标志字符串
写解密脚本,得到flag
enc = [
98,
77,
94,
91,
92,
107,
125,
66,
87,
70,
113,
92,
83,
70,
85,
81,
19,
21,
109,
99,
87,
107,
127,
65,
65,
64,
109,
87,
93,
90,
65,
64,
64,
65,
81,
3,
109,
85,
86,
80,
91,
64,
91,
91,
92,
0,
94,
107,
66,
77,
94,
91,
92,
71
]
flag = 'LitCTF{'
lis = []
for num in range(0, 120):
if num % 2 == 0 and num % 4 == 0 and num % 6 == 0 and num % 8 == 0 and num % 12 == 0 and num % 13 == 11:
k = str(num)
for i in range(len(enc)):
flag += chr(ord(k[i % len(k)]) ^ enc[i])
lis.append(ord(k[i % len(k)]) ^ enc[i])
flag += '}'
print(flag)
[LitCTF 2023]程序和人有一个能跑就行了
下载附件,查壳,无壳,32位,ida打开
找到主函数
int __cdecl main(int argc, const char **argv, const char **envp)
{
_DWORD *v3; // eax
_DWORD *v5; // eax
char *v6; // eax
int v7; // [esp+0h] [ebp-2ACh] BYREF
int v8; // [esp+14h] [ebp-298h]
int *v9; // [esp+18h] [ebp-294h]
int v10; // [esp+1Ch] [ebp-290h] BYREF
int v11; // [esp+20h] [ebp-28Ch]
int (__cdecl *v12)(int, int, __int64, _BYTE *, int); // [esp+34h] [ebp-278h]
int *v13; // [esp+38h] [ebp-274h]
int *v14; // [esp+3Ch] [ebp-270h]
void *v15; // [esp+40h] [ebp-26Ch]
int *v16; // [esp+44h] [ebp-268h]
char Buf1[27]; // [esp+68h] [ebp-244h] BYREF
char data[256]; // [esp+A0h] [ebp-20Ch] BYREF
char key[268]; // [esp+1A0h] [ebp-10Ch] BYREF
int savedregs; // [esp+2ACh] [ebp+0h] BYREF
v9 = &v10;
v12 = sub_4752F0;
v13 = dword_476078;
v14 = &savedregs;
v15 = &loc_475B38;
v16 = &v7;
sub_40A8F0(&v10);
sub_409B80();
v11 = -1;
sub_472810(&dword_47DD80, data);
strcpy(key, "litctf");
function(data, strlen(data), key, 6u);
Buf1[0] = 0x8D;
Buf1[1] = 0x6C;
Buf1[2] = 0x85;
Buf1[3] = 0x76;
Buf1[4] = 0x32;
Buf1[5] = 0x72;
Buf1[6] = 0xB7;
Buf1[7] = 0x40;
Buf1[8] = 0x88;
Buf1[9] = 0x7E;
Buf1[10] = 0x95;
Buf1[11] = 0xEE;
Buf1[12] = 0xC5;
Buf1[13] = 0xED;
Buf1[14] = 0x2E;
Buf1[15] = 0x71;
Buf1[16] = 0x37;
Buf1[17] = 0xF1;
Buf1[18] = 0x4A;
Buf1[19] = 0x99;
Buf1[20] = 0x35;
Buf1[21] = 0x18;
Buf1[22] = 0xA7;
Buf1[23] = 0xB0;
Buf1[24] = 0;
Buf1[25] = 0x96;
Buf1[26] = 0xB7;
v8 = memcmp(Buf1, data, 0x1Bu);
if ( v8 ) // 不相等时执行
{
v11 = 1;
v5 = sub_471AE0(&dword_47DF60, "U are wrong?");
sub_46FBA0(v5); // 字符串转换为相应的数字
v6 = sub_474310(4); // 为加密操作分配一块内存,并返回指向该内存块的指针。
*v6 = data; // 数据传给分配的内存
sub_475190(v6, &off_483660, 0); // 抛出一个异常,提示出现了无法处理的错误
}
v11 = 1;
v3 = sub_471AE0(&dword_47DF60, "U are right?");
sub_46FBA0(v3);
sub_40AA70(v9);
return v8;
}可以看到主函数中有function函数,function函数中进行了rc4加密,进入查看,
int __cdecl function(int data, int datalen, int key, unsigned int len)
{
unsigned int i; // ecx
char *v5; // eax
int v6; // ecx
char v7; // si
int ii; // eax
int jj; // ecx
int v10; // edx
char v11; // di
char v12; // si
int v13; // edi
int v14; // [esp+0h] [ebp-214h]
char S[256]; // [esp+4h] [ebp-210h] BYREF
char K[272]; // [esp+104h] [ebp-110h] BYREF
for ( i = 0; i != 256; ++i ) // 初始化S表和K表
{
S[i] = i;
K[i] = *(key + i % len);
}
v5 = S;
LOBYTE(v6) = 0;
do
{
v7 = *v5++; // 先取*再++
v6 = (v5[255] + v7 + v6);
*(v5 - 1) = S[v6]; // s[i],交换
S[v6] = v7;
}
while ( v5 != K );
ii = datalen;
if ( datalen )
{
LOBYTE(jj) = 0;
LOBYTE(ii) = 0;
v10 = 0;
v14 = 0;
do
{
++v10;
ii = (ii + 1);
v11 = S[ii];
v12 = v11;
jj = (v11 + jj); // 交换
S[ii] = S[jj];
S[jj] = v11;
v13 = v14;
v14 = v10; // 相当于n++
*(data + v13) ^= S[(S[ii] + v12)];
}
while ( v10 != datalen );
}
return ii;
}使用主函数下面的Buf数据进行rc4解密,得到错误的flag
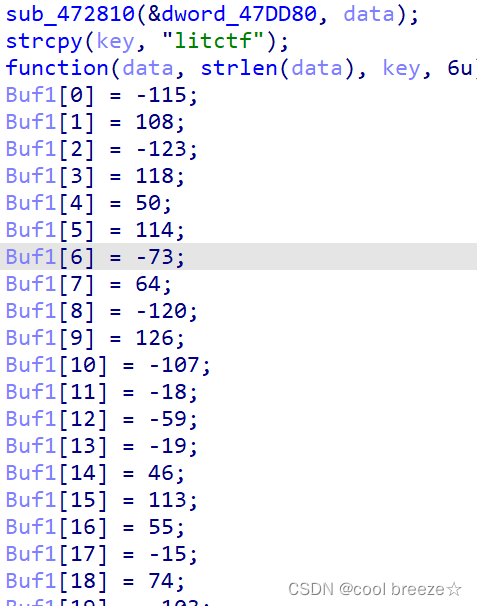
这个BUF数据得到的是错误的flag
def rc4(key, ciphertext):
# 初始化S盒
sbox = list(range(256))
j = 0
for i in range(256):
j = (j + sbox[i] + key[i % len(key)]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
# 生成密钥流
i = 0
j = 0
keystream = []
for _ in range(len(ciphertext)):
i = (i + 1) % 256
j = (j + sbox[i]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
k = sbox[(sbox[i] + sbox[j]) % 256]
keystream.append(k)
# 解密密文
plaintext = []
for i in range(len(ciphertext)):
m = ciphertext[i] ^ keystream[i]
plaintext.append(m)
# 将明文转换为字符串
return ''.join([chr(p) for p in plaintext])
# 测试
key = b'litctf'
ciphertext = [0x8D,0x6C,0x85,0x76,0x32,0x72,0xB7,0x40,0x88,0x7E,0x95,0xEE,0xC5,0xED,0x2E,0x71,0x37,0xF1,0x4A,0x99,0x35,0x18,0xA7,0xB0,0x0,0x96,0xB7]
plaintext = rc4(key, ciphertext)
print(plaintext)
#LitCTF{this_is_a_fake_flag}
接着回到主程序查看,当判断不相等时还对数据进行了操作

通过调试查看具体作用
下断点:
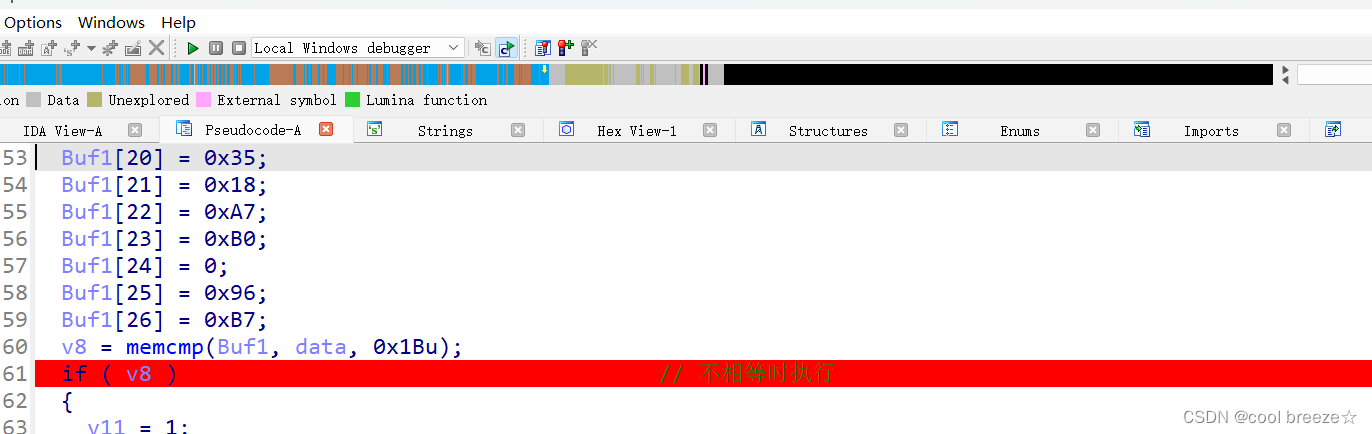
任意输入一个值,程序进入U are wrong的部分

一直执行,可以看到还有一个Buf数据,这里的数据和主函数不同,拿去解密得到真正的flag

def rc4(key, ciphertext):
# 初始化S盒
sbox = list(range(256))
j = 0
for i in range(256):
j = (j + sbox[i] + key[i % len(key)]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
# 生成密钥流
i = 0
j = 0
keystream = []
for _ in range(len(ciphertext)):
i = (i + 1) % 256
j = (j + sbox[i]) % 256
sbox[i], sbox[j] = sbox[j], sbox[i]
k = sbox[(sbox[i] + sbox[j]) % 256]
keystream.append(k)
# 解密密文
plaintext = []
for i in range(len(ciphertext)):
m = ciphertext[i] ^ keystream[i]
plaintext.append(m)
# 将明文转换为字符串
return ''.join([chr(p) for p in plaintext])
# 测试
key = b'litctf'
ciphertext = [0x8D, 0x6C, 0x85, 0x76, 0x32, 0x72, 0xB7, 0x43, 0x85, 0x7B, 0x85, 0xDE, 0xC1, 0xFB, 0x2E, 0x64, 0x07, 0xC8, 0x5F, 0x9A, 0x35, 0x18, 0xAD, 0xB5, 0x15, 0x92, 0xBE, 0x1B, 0x88]
plaintext = rc4(key, ciphertext)
print(plaintext)后来知道这题考察的是C++异常处理,补充上
C++异常处理问题:
当程序出现 C++ 异常时,通常需要对异常进行处理,以便尽可能地避免程序崩溃或产生不可预料的错误行为。这种异常可能是除0错误。处理方法有
- 使用try-catch块:在可能抛出异常的代码块中使用try-catch块来捕获和处理异常。try块用于包裹可能会抛出异常的代码,catch块则用于捕获和处理异常。在catch块中,可以输出错误信息,或者采取其他措施来处理异常。注意,必须是包含在try块中的代码出现异常时才会使用catch捕捉处理,try块外面的使用其他方式,可能有多个catch
- 抛出异常:在出现错误时,可以抛出自定义的异常,以提供更详细的错误信息。在 C++ 中,可以使用throw语句抛出异常,抛出的异常可以是任何类型,包括内置类型、自定义类型、指针等。
- 终止程序:在某些情况下,程序出现异常后可能无法正常运行,这时可以选择终止程序。在 C++ 中,可以使用abort函数或exit函数来终止程序。abort函数会向操作系统发送一个中断信号,导致程序立即终止;exit函数则会正常退出程序,但是可以通过设置退出码来指示程序出现了异常。
此题出现的就是try-catch块捕捉处理的方法,抛出异常,实现程序的大跳转,将真正的flag数据隐藏起来
得到flag:LitCTF{welcome_to_the_litctf}
[LitCTF 2023]debase64
打开附件,找到主函数
int __cdecl main(int argc, const char **argv, const char **envp)
{
_BYTE result[14]; // [esp+10h] [ebp-44h] BYREF
char v5; // [esp+1Eh] [ebp-36h]
char v6; // [esp+20h] [ebp-34h]
__int16 v7; // [esp+21h] [ebp-33h]
__int16 v8; // [esp+23h] [ebp-31h]
__int16 v9; // [esp+25h] [ebp-2Fh]
__int16 v10; // [esp+27h] [ebp-2Dh]
__int16 v11; // [esp+29h] [ebp-2Bh]
__int16 v12; // [esp+2Bh] [ebp-29h]
char v13; // [esp+2Dh] [ebp-27h]
char v14; // [esp+2Eh] [ebp-26h]
char input[20]; // [esp+3Ch] [ebp-18h] BYREF
sub_402290();
puts(&Buffer); // 请开始你的表演
memset(result, 0, sizeof(result));
v5 = 0;
memset(input, 0, sizeof(input));
scanf("%s", input);
if ( strlen(input) != 20 )
{
puts(&aE_0); // 长度不对哦
return 0;
}
v6 = 0x46;
v7 = 0x18ED;
v8 = 0x5696;
v9 = 0xD29E;
v10 = 0xB272;
v11 = 0x80B3;
v12 = 0xFF70;
v13 = 0;
v14 = 0;
function(input, result); // 加密函数
if ( v6 != result[0] // 最后结果判断
|| v7 != *&result[1]
|| v8 != *&result[3]
|| v9 != *&result[5]
|| v10 != *&result[7]
|| v11 != *&result[9]
|| v12 != *&result[11]
|| v13 != result[13]
|| v14 != v5 )
{
puts("不对哦");
return 0;
}
return puts(asc_404065); // 恭喜你答对了
}可以看到程序先输入一串数据,然后在function函数中进行加密,加密后的数据与v6~v14进行比较,相等则输出,恭喜答对了,否则输出 不对哦。
进入加密function函数查看
int __cdecl sub_401520(_BYTE *a1, int a2)
{
_BYTE *v2; // ebp
_BYTE *v3; // ecx
int v4; // ebx
int v5; // eax
int i; // edx
_BYTE *v7; // edx
int j; // ecx 每四个一组查找字符在base64表中的下标位置,将下标位置写入数组中,
_BYTE *v9; // ecx 最后将数组元素的四个字节变换为3个数据(类似base64)
int k; // ebx
int v12; // [esp+0h] [ebp-38h]
int v13; // [esp+4h] [ebp-34h]
int v14; // [esp+Ch] [ebp-2Ch]
if ( !*a1 )
return 0;
v2 = a1 + 4;
v3 = a1;
v4 = 0;
v5 = 0;
v13 = 0;
while ( 1 )
{
v14 = -1;
for ( i = 0; i != 64; ++i )
{
while ( aAbcdefghijklmn[i] != *v3 )
{
if ( ++i == 64 )
goto LABEL_7;
}
LOBYTE(v14) = i;
}
LABEL_7:
LOBYTE(i) = 0; // 最低位字节,查找第一个字符
do
{
while ( aAbcdefghijklmn[i] != a1[v4 + 1] )
{
if ( ++i == 64 )
goto LABEL_11;
} // 查找第二个字符
BYTE1(v14) = i++; // 第二位字节
}
while ( i != 64 );
LABEL_11:
v7 = &a1[v4 + 2];
for ( j = 0; j != 64; ++j )
{
while ( aAbcdefghijklmn[j] != *v7 )
{
if ( ++j == 64 )
goto LABEL_15;
} // 查找第三个字符
BYTE2(v14) = j; // 第三位字节
}
LABEL_15:
v9 = &a1[v4 + 3];
for ( k = 0; k != 64; ++k )
{
while ( aAbcdefghijklmn[k] != *v9 )
{
if ( ++k == 64 )
goto LABEL_19;
} // 查找第四个字符
HIBYTE(v14) = k; // 最高位字节
}
LABEL_19:
v12 = v5 + 1;
*(a2 + v5) = (4 * HIBYTE(v14)) | (BYTE2(v14) >> 4) & 3;
if ( *v7 == 61 )
return v12;
v12 = v5 + 2;
*(a2 + v5 + 1) = (16 * BYTE2(v14)) | (BYTE1(v14) >> 2) & 0xF;
if ( *v9 == 61 )
return v12;
v5 += 3;
v3 = v2;
v2 += 4;
v13 += 4;
v4 = v13;
*(a2 + v5 - 1) = (BYTE1(v14) << 6) | v14 & 0x3F;
if ( !*(v2 - 4) )
return v5;
}
}分析函数,具体是将Base64编码字符串每四个一组进行处理。
首先,代码找到第一个字符在字符表中的下标,将其存储在v14的最低位字节中。
然后,代码找到第二个字符在字符表中的下标,将其存储在v14的第二位字节中。
接着,代码找到第三个和第四个字符在字符表中的下标,并将它们分别存储在v14的第三位字节和最高位字节中。当查找不到时使用goto语句来跳过下面的循环
具体参考chatgpt解读:
- 首先判断输入的字符串是否为空,如果为空则返回0。
- 然后从输入字符串的第一个字符开始,每四个字符一组,查找每个字符在base64表中的下标位置,并将这四个下标位置存储到一个32位的整数变量v14中,其中最低位字节存储第一个字符在base64表中的下标位置,最高位字节存储第四个字符在base64表中的下标位置。
- 将v14中的四个字节变换为三个数据,每个数据占8位,类似于base64的编码方式,存储到输出缓冲区中。
- 如果在输入字符串中出现了'='字符,则说明输入字符串的长度不是4的倍数,需要特殊处理。
- 如果已经处理完了整个输入字符串,则返回输出数据的长度。
- 函数使用了一些位运算技巧来将v14中的四个字节变换为三个数据,例如
(4 * HIBYTE(v14)) | (BYTE2(v14) >> 4) & 3将v14的最高位字节左移两位乘以4,并与v14的第三位字节右移4位后的结果取低两位进行或运算,得到一个8位的数据
写脚本解密(借鉴一位大佬的脚本,具体文章参考:https://blog.csdn.net/m0_72989226/article/details/130673183)
import base64
list = [0x46, 0xED, 0x18, 0x96, 0x56, 0x9E, 0xD2, 0x72, 0xB2, 0xB3, 0x80, 0x70, 0xFF]
list_b = bytes(list)
print(base64.b64encode(list_b))最后一位根据提示爆破
import hashlib
key = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
for i in key:
str1 = "Y0uReallyKn0wB4s" + i + "==="
if hashlib.md5(str1.encode('utf-8')).hexdigest() == "5a3ebb487ad0046e52db00570339aace":
print(str1)
break