论文信息
name_en: AudioLM: a Language Modeling Approach to Audio Generation
name_ch: AudioLM:一种音频生成的语言建模方法
paper_addr: http://arxiv.org/abs/2209.03143
doi: https://doi.org/10.48550/arXiv.2209.03143
date_read: 2023-04-25
date_publish: 2022-09-07
tags: [‘语音合成’,‘深度学习’]
author: Zalán Borsos
citation: 36
demo:https://google-research.github.io/seanet/audiolm/examples
1 读后感
主要解决生成语音的两个问题:一致性和高质量。
2 摘要
这是一个利用长期一致性生成高质量音频的框架,它先将音频输入转成一系列离散的token,然后将生成音频作为表示空间的语言建模。提出了一种混合的分词方案来平衡重建质量和长依赖的结构。
使用Mask方法捕获长距离的关系,最终使用离散编码生成高品质的合成效果。它可以通过简短的提示,来生成自然连贯延续语音。利用大量无监督数据训练,在没有任何文字标注或注释的情况下,AudioLM 会生成句法和语义上合理的语音延续,同时还保持说话人身份和不可见的说话人的韵律。另外,还可以生成钢琴音乐。
3 介绍
在数据都是无监督的情况下,基于Transformer架构。具体使用的技术包括:对抗性神经音频压缩,自监督表示学习,语言建模。学习不同尺度的相互作用,保证语音的一致性。
贡献
- 提出AudioLM框架,分层方式结合语义和声学标记,以实现生成长期一致性和高质量的音频。
- 通过与w2v-BERT以及SoundStream的对比,证明了模型的可辨别性和重建质量优势的互补性。
- 模型可以不依赖文本标注,生成语音,句法和语义。只需要3s语音作为提示,即可生成训练期间未见过的语音,并保持说话人的声音,韵律,录音条件(混响、噪音)。
- 除合成人声外,还可以合成音乐声,其旋律、和声、音调和节奏都与提示一致。
- 为防御生成语音带来的潜在风险,还提出了一个分类器,用于识别合成音频和真实音频。
4 模型

声学token由 SoundStream处理,语义token由 w2v-BERT 的中间层产生。
4.1 组件
- 将输入音频x映射到离散的词表y:y=end(x)。
- 使用仅有decoder的Transformer模型,操作y,用时间t-1的预测t对应的词(预测阶段使用自回归)。
- 解码模型 ,将预测出的y^映射回音频格式。 x=dec(y)
4.2 权衡离散音频表示
使用尽量少的数据同时需要保证生成的音质,这涉及比特率的下限和序列长度。这里引入了语义token和声学token。如图-1所示。它们的产生被解耦;语义token需要时序依赖,声学token需要保证高音质,且使用语义作为条件。
使用 SoundStream 计算声学token,它使用了RQV(残差向量量化)技术将嵌入降维和离散化,并映射到码表。
使用 w2v-BERT 计算语义标记。该模型可以自主学习音频表示,将输入的音频波形映射到一个富有语言特征的向量空间。通过使用两个自监督目标:掩码语言建模(MLM)损失和对比损失训练模型实现。选择w2v-BERT模型的MLM模块中的一个中间层并计算该层的嵌入,可以提取出语义标记。将这些标记进行聚类,并使用聚类中心索引作为语义标记。
实验证明,将二项解耦效果更好。
4.3 语义和声学标记的分层建模
先使用模型产生语义,然后再语义条件下生成高质量音频,有两个好处:
- 语义结果独立于音频结果。
- 减少了每个阶段的标记序列,训练和推理效率更高。
具体实现如图-2所示,包含三个场景:
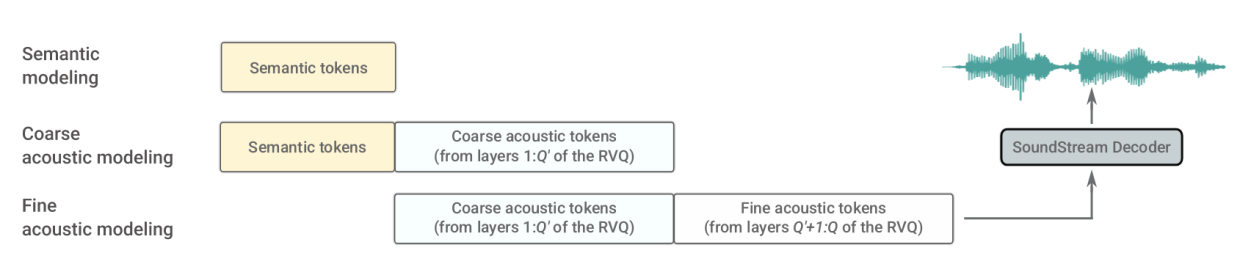
- 长期结构一致性的语义建模:利用上文,使用自回归方法预测语义z。
- 以语义标记为条件的粗略声学建模:利用上文和语义,预测粗糙声的声学标记y。
- 精细声学建模:用粗糙声学标记y以及上文生成精细声学信息,生成高质量标记。
SoundStream 嵌入的采样率是 w2v-BERT 嵌入的两倍。另外拆分两的场景的原因是可以限制序列长度。
4.4 预测
训练后,可以使用 AudioLM 生成音频,测试了以下三种情况:
4.4.1 无条件生成
无条件地对所有语义标记 ^z 进行采样,然后将其用作声学建模的条件。此实验证明了:模型可生成多种多样、句法和语义一致的语言内容,验证了语义与声学的无关性。
4.4.2 声学生成
使用从测试集 x 中提取的真实语义标记 z 作为条件来生成声学标记。生成的音频序列在说话人身份方面有所不同,但语义内容与 x 的真实内容匹配。这表明语义标记捕获了语义内容。
4.4.3 生成语音延续
从短提示 x 生成延续。首先将提示映射到相应的语义标记 z 和粗糙的声学标记 y。第一阶段生成语义标记的延续;第二阶段,将生成的语义与提示粗声学标记y连接起来,并将其作为条件提供给粗声学模型;在第三阶段,用精细的声学模型处理粗略的声学标记;最后,将提示和采样的声学标记都提供给 SoundStream 解码器以重建波形 x^。