内容来自李宏毅-2021机器学习
##先说结论:同一个模型,大batch结果往往会较差。
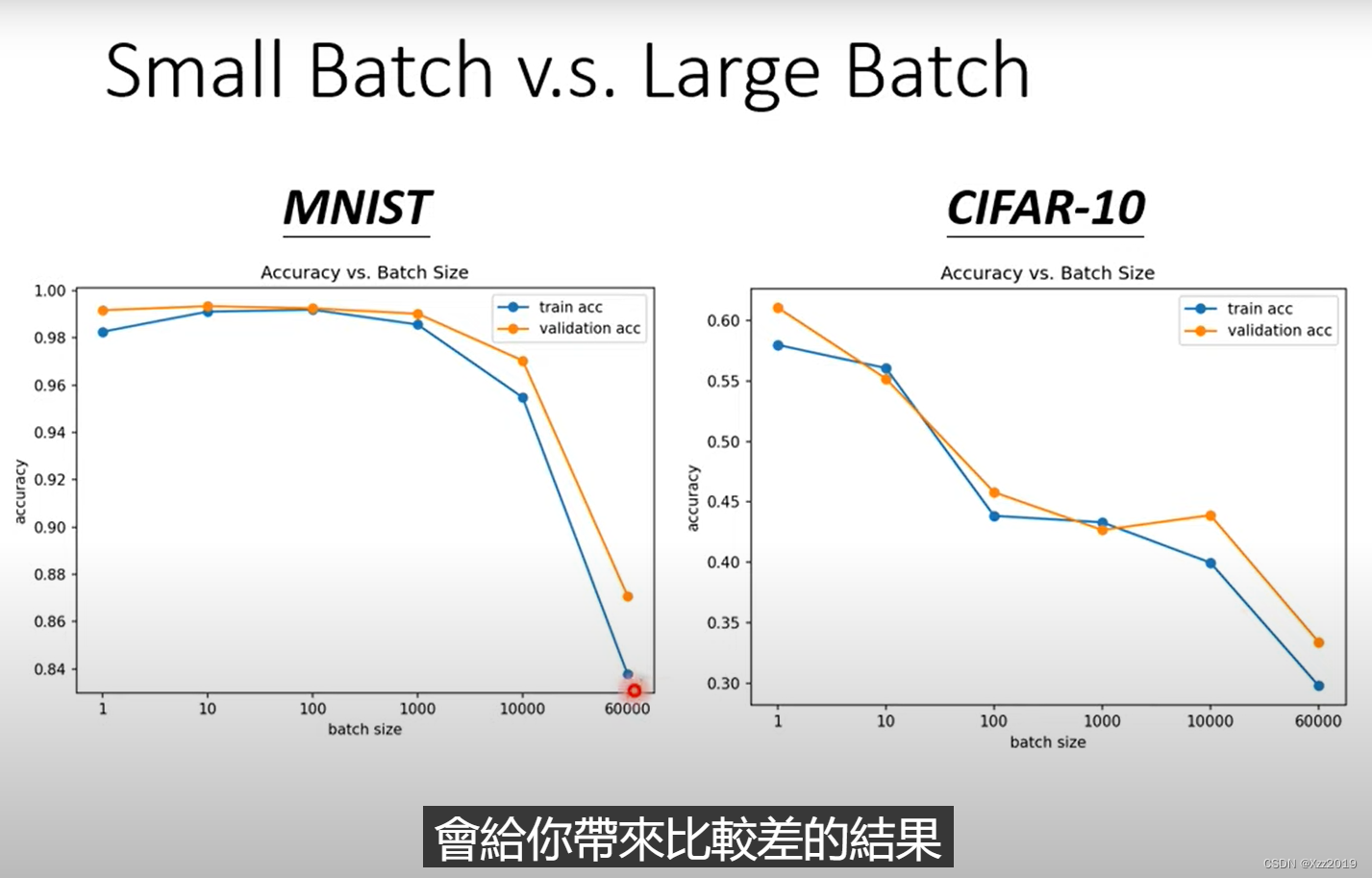
上图中,横轴代表batch size,从左到右越来越大;纵轴代表准确率acc,越往上正确率越来越高。
在观察validation上的结果时,会发现随着batch size增加,acc结果越来越差。
但这个现象并不是overfitting,因为在training上的acc结果也是随着batch size增加而变差。
结论:同一个模型,大的batch size往往会带来比较差的结果。
由于使用的是同一个模型,可以排除model bias的问题,而是optimization的问题。使用大的batch size时,optimization可能会有问题,小的batch size的结果可能是比较好的。
##为什么小batch有更好的表现,有噪声的参数更新对训练更有帮助?
一种解释:
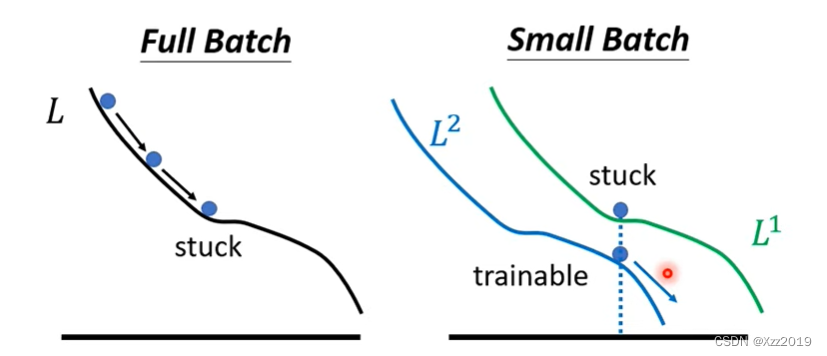
如果使用的是full match(上图左1),在更新参数时会沿着一个Loss函数来更新参数。可能会陷入一个局部极小值点或者是鞍部点,梯度变为0,不会再进行参数的更新。
但是如果使用small batch(上如左2),训练时每个batch会根据自己的Loss函数来算梯度,不同的batch间的Loss函数是有差异的。第一个batch用L1算梯度,第二个batch用L2算梯度。假如用L1在某一点算出来梯度为0卡住了,但在L2的这一点算出来梯度很可能并不是0,所以还是有办法让梯度不为0,进而可以继续训练,让Loss变小。
所以有噪声的参数更新对训练更有帮助。
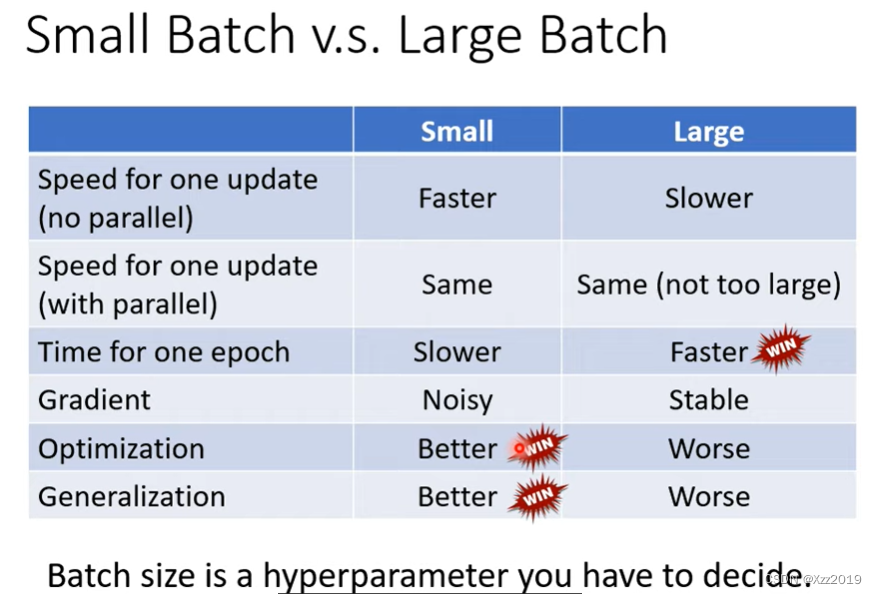
小batch 和大batch有各自的特点,根据需要来选择合适的参数。




![[比赛简介]Predict Student Performance from Game Play](https://img-blog.csdnimg.cn/bd3f7b2f44e348ad8659b82c2911abca.png)