文章目录
- 前言
- 正则表达式方法
- re.search方法
- group方法
- re.match方法
- re.findall方法
- re.finditer方法
- re.split方法
- re.sub方法
- 正则表达式的应用
前言
提示:这里可以添加本文要记录的大概内容:
正则表达式是字符串处理的有力工具和技术。
使用正在表达式的目的:
1、给定的字符串是否符合正则表达式的过滤逻辑(称作"匹配")。
2、可以通过正则表达式,从字符串中获取我们想要的特定部分。
Python中,re模块import re提供了正则表达式操作所需要的功能。
常用正则表达式

提示:以下是本篇文章正文内容,下面案例可供参考
正则表达式方法
re.search方法
扫描整个字符串,搜索匹配第一个位置
返回match对象
re.search(pattern, string, flags=0)
参数说明:
Pattern:要匹配的正则表达式String:要匹配的字符串
Flags:控制正则表达式的匹配方式
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
打开上面的网站,右键查看页面源代码,找音频编号(我的在61行,或许每个人的都不一样)
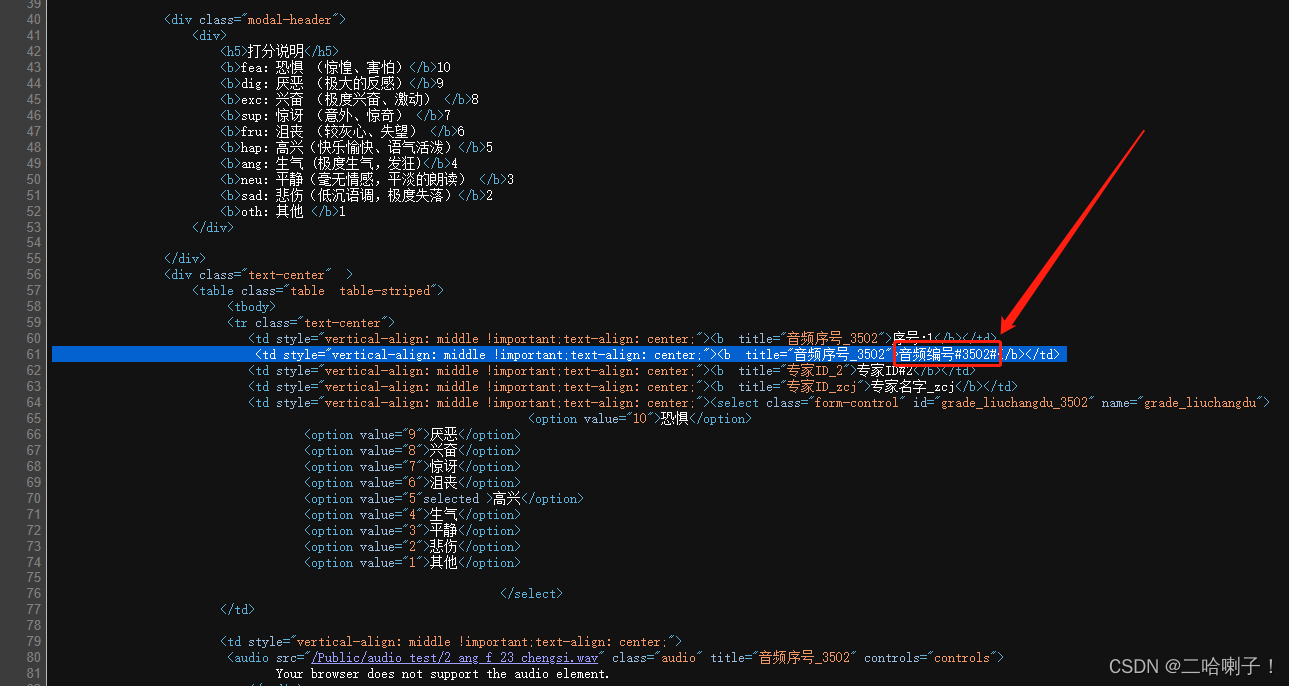
查找音频编号,代码如下(示例):
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo=getHTMLContent(url)
wav_number=re.search(r'音频编号#(.+?)#</b>',demo) # .+?是匹配任意字符,即是上面截图中的#3502#
print(wav_number)

group方法
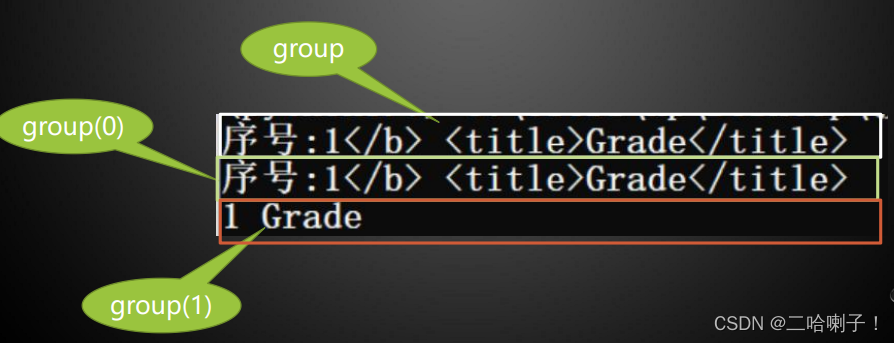
用来提出分组截获的字符串,()用来分组
正则表达式中的三组括号把匹配结果分成三组
• group() 同group(0)是匹配正则表达式整体结果
• group(1) 列出第一个括号匹配部分
• group(2) 列出第二个括号匹配部分
• group(3) 列出第三个括号匹配部分
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
打开上面的网站,右键查看页面源代码,找音频编号(我的在第9和第60行,或许每个人的都不一样)
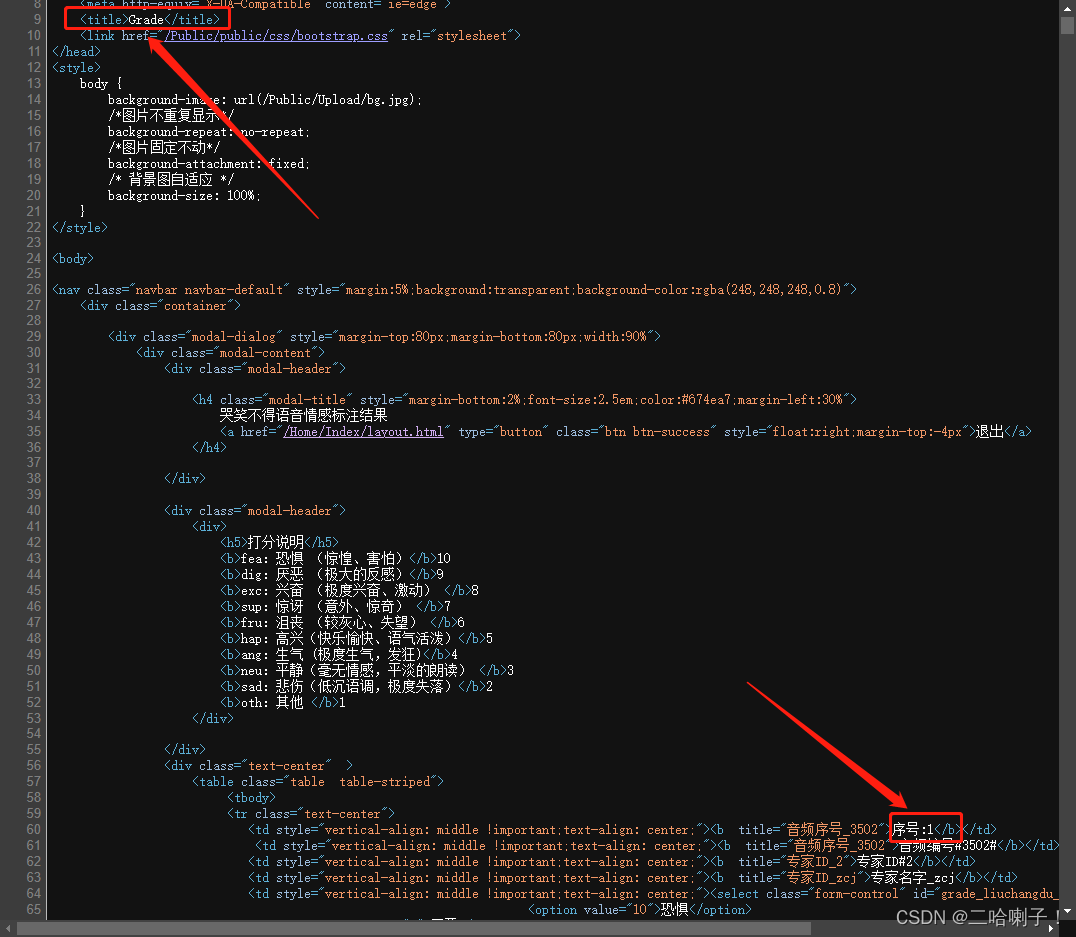
查找<title>标签和序号开头<b>结尾,代码如下(示例):
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,tiemout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
wav_number1=re.search(r'序号:(.+?)</b>',demo) #序号开头</b>结尾
wav_number2=re.search(r'<title>(.+?)</title>',demo) #<title标签>
print(wav_number1.group(),wav_number2.group())
print(wav_number1.group(0),wav_number2.group(0))
print(wav_number1.group(1),wav_number2.group(1))
re.match方法
从字符串的起始位置(第一个字符)匹配正则表达式
re.match(pattern, string, flags=0)
参数说明
• pattern:要匹配的正则表达式
• string:要匹配的字符串
• flags:控制正则表达式的匹配方式
【例1】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
打开上面的网站,右键查看页面源代码
从第一个字符开始匹配,匹配:音频编号
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url, timeout=30)
r.raise_for_status()
return r.text
except:
return "访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo=getHTMLContent(url)
wav_number=re.match(r'音频编号#(.+?)#</b>',demo) # .+?是匹配任意字符
print(wav_number)

【例2】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
多了个切分,从音频编开始切,分为两部分
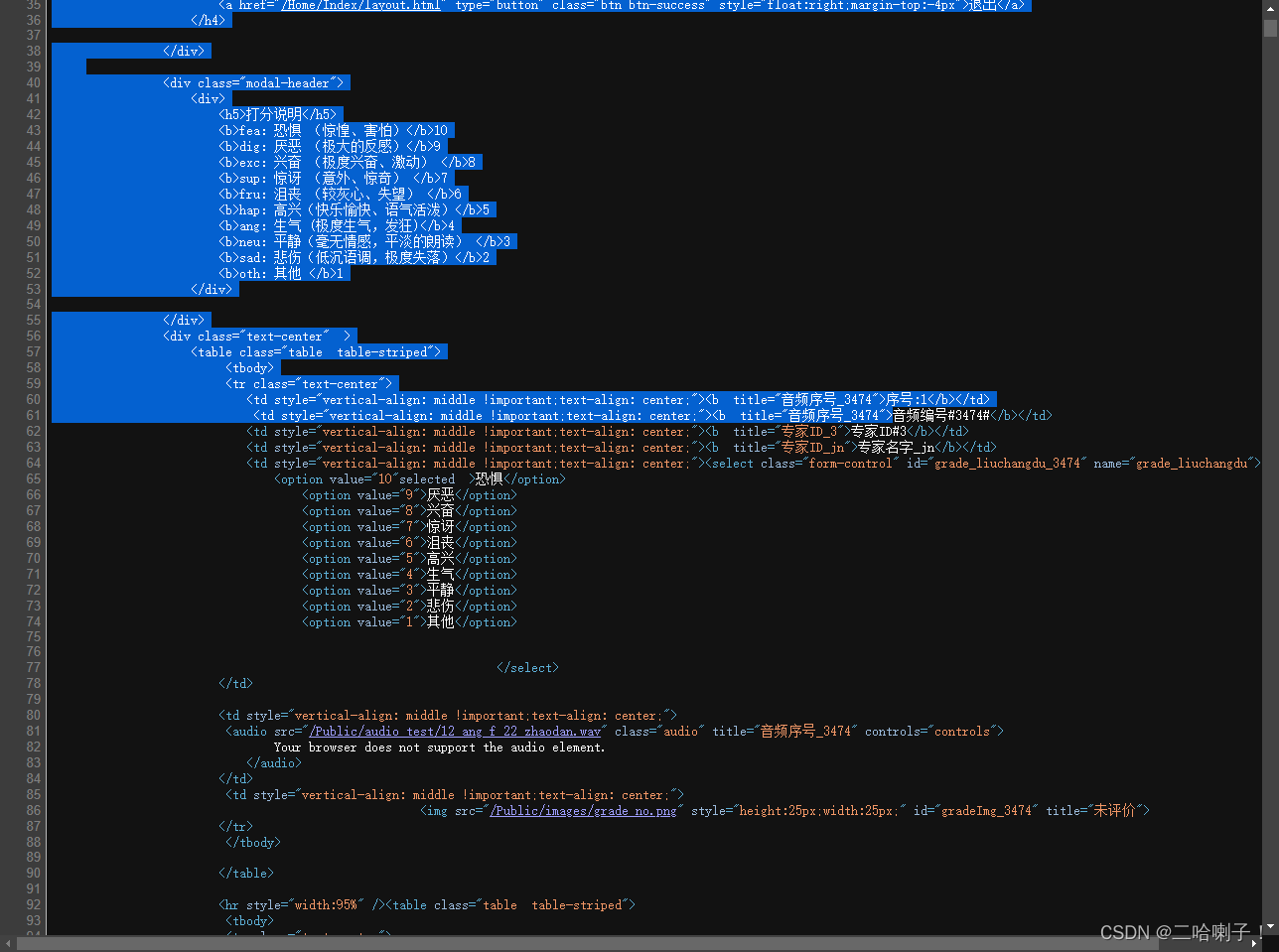
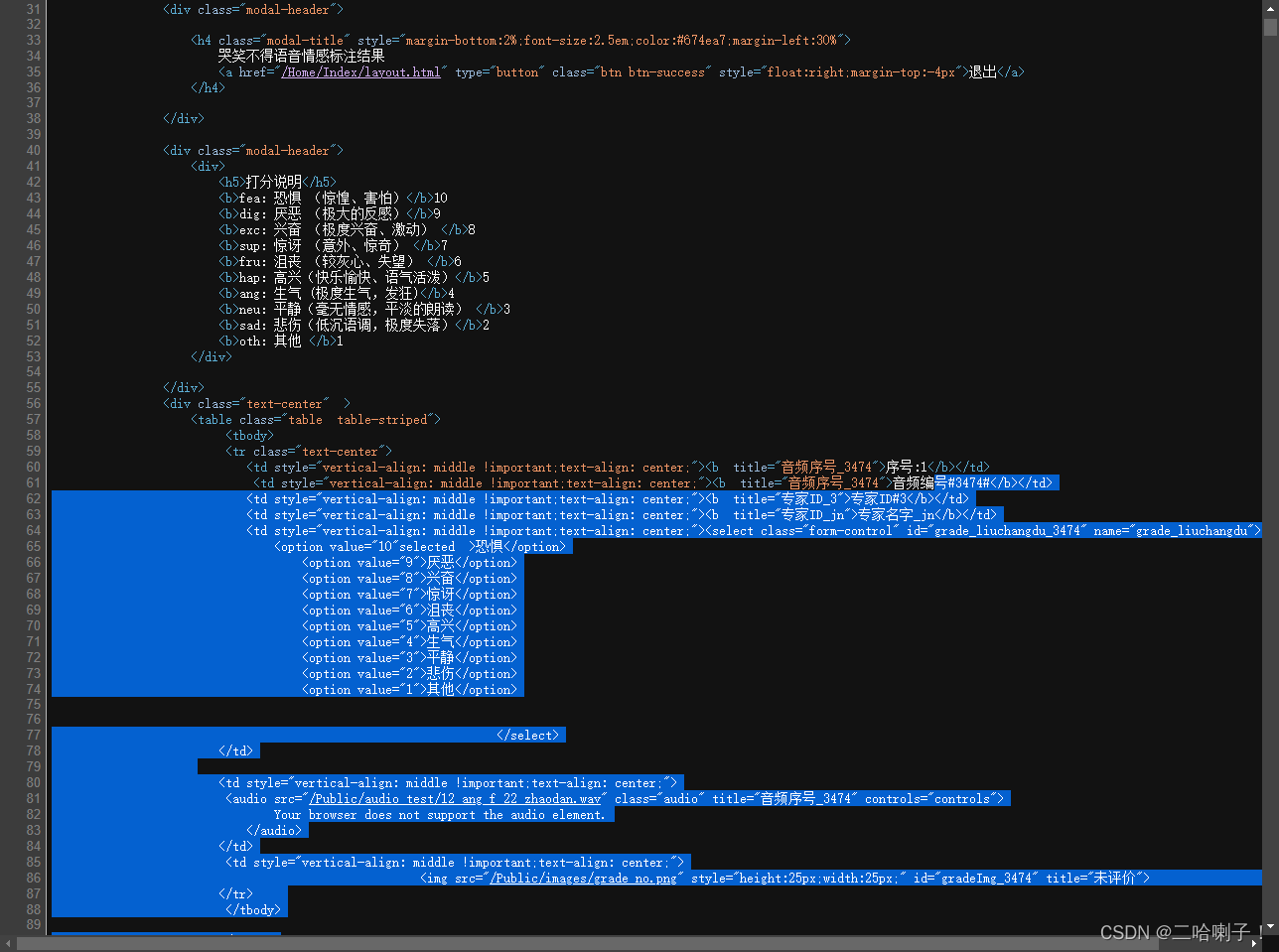
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo=getHTMLContent(url)
demo2=demo.split('音频编',1) #切分2部分
wav_number=re.match(r'号#(.+?)#</b>', demo2[1]) #从头匹配
print(wav_number)

re.findall方法
搜索字符串,返回形式为列表
re.findall(pattern, string, flags=0)
参数说明
pattern:要匹配的正则表达式
string:要匹配的字符串
flags:控制正则表达式的匹配方式
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
要所有的音频编号信息列表
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo=getHTMLContent(url)
wav_number=re.findall(r'音频编号#(.+?)#</b>', demo)
print(wav_number)
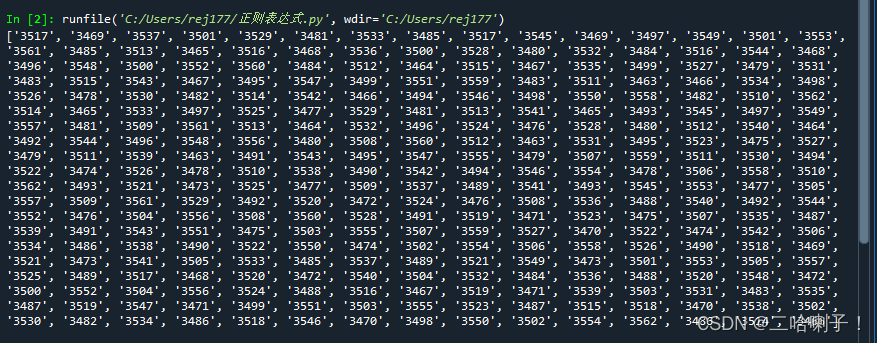
【例2】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html

查所有序号、专家ID、专家名字、grade流畅度、音频名字、png图片
# -*- coding: utf-8 -*-
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
#信息提取
yinpinbianhao = re.findall(r'音频编号#(.+?)#</b>', demo) #拿音频编号
xuhao = re.findall(r'序号:(.+?)</b>', demo) #拿序号
zhuanjiaid = re.findall(r'专家ID#(.+?)</b>', demo) #拿专家id
zhuanjiamingzi = re.findall(r'专家名字_(.+?)</b>', demo) #拿专家名字
liuchangdu = re.findall(r'form-control" id="(.+?)"', demo) #拿流畅度
audio_src = re.findall(r'audio src="(.+?)', demo) #拿音频路径
img_src = re.findall(r'img_src="(.+?)"', demo) #拿图片路径
for i in range(len(yinpinbianhao)):
print(xuhao[i],yinpinbianhao[i],zhuanjiaid[i],zhuanjiamingzi[i],liuchangdu[i],audio_src[i],img_src[i])
re.finditer方法
搜索字符串,返回匹配字符串的迭代器。
re.finditer(pattern, string, flags=0)
参数说明
pattern:要匹配的正则表达式
string:要匹配的字符串
flags:控制正则表达式的匹配方式
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
获取所有信息,返回匹配信息的迭代器
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"产生异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
wav_number = re.finditer(r'音频编号#(.+?)#</b>', demo)
for wave in wav_number:
print(wave.group)
re.split方法
按照匹配的子串,将字符串分割返回列表
re.split(pattern, string, maxsplit=0, flags=0)
参数说明
pattern:匹配模式
string: 待搜索的字符串
maxsplit:最大的分割数
【例1】
import re
if __name__ == "__main__":
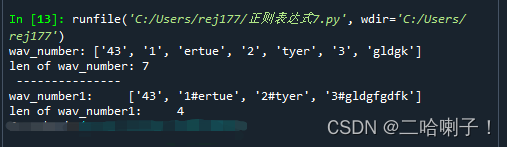
wav_number = re.split(r'ab(.+?)#','43ab1#ertueab2#tyerab3#gldgk',3)
wav_number1 = re.split(r'ab','43ab1#ertueab2#tyerab3#gldgfgdfk',3)
print('wav_number:',wav_number)
print('len of wav_number:',len(wav_number))
print(' ---------------')
print('wav_number1: ',wav_number1)
print('len of wav_number1: ',len(wav_number1))
wav_number =re.split(r'ab(.+?)#,43ab1#ertueab2#tyerab3#gldgk',3)
wav_number1 = re.split(r'ab','43ab1#ertueab2#tyerab3#gldgfgdfk',3)
【例2】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
爬虫的正则表达式,用re.split方法实现
切片,切100刀,看看能切出多少块,切出的每一块是什么
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
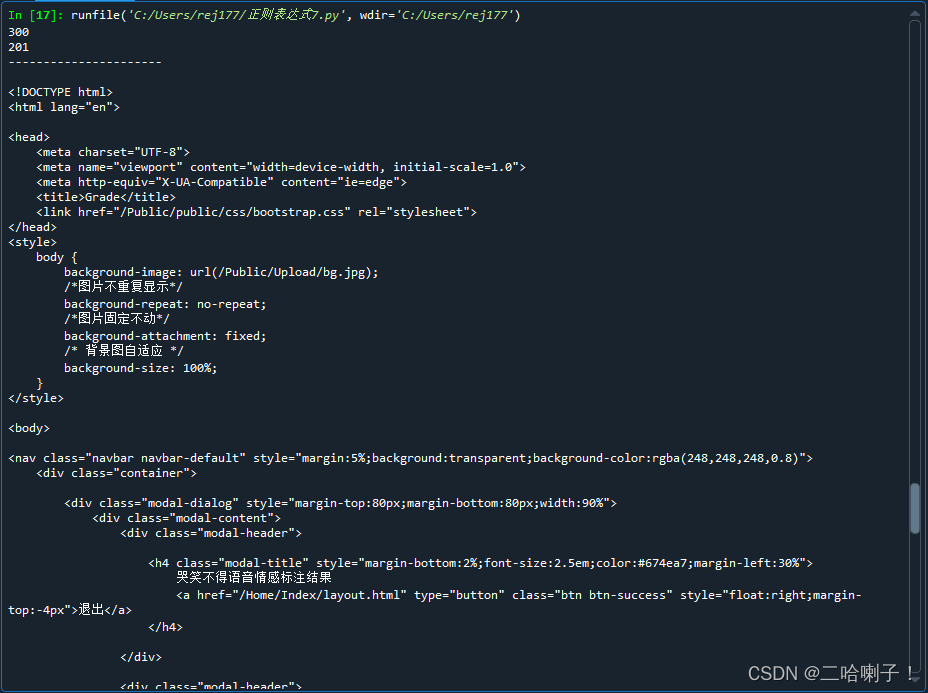
wav_number=re.findall(r'音频编号#(.+?)#</b>', demo)
print(len(wav_number))
wav_number1=re.split(r'音频编号#(.+?)#</b>', demo,100)
print(len(wav_number1))
print('----------------------')
print(wav_number1[0])
print('----------------------')
print(wav_number1[1])
print('----------------------')
print(wav_number1[2])
print('----------------------')
print(wav_number1[3])
print('----------------------')
re.sub方法
替换所有匹配正则表达式的字串,返回替换后的字符串
re.sub(pattern, repl, string,count=0 , flags=0)
参数说明
pattern:匹配模式
repl : 替换的字符串
String: 待搜索的字符串
count : 替换的最大次数
【例】把匹配出来的信息替换成NID
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
wav_number = re.sub(r'音频编号#(.+?)#</b>','NID',demo)
wav_number1 = re.findall(r'音频编号#(.+?)#</b>', wav_number)
wav_number2 = re.findall('NID', wav_number)
print(len(wav_number1))
print(len(wav_number2))

正则表达式的应用
【例1】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
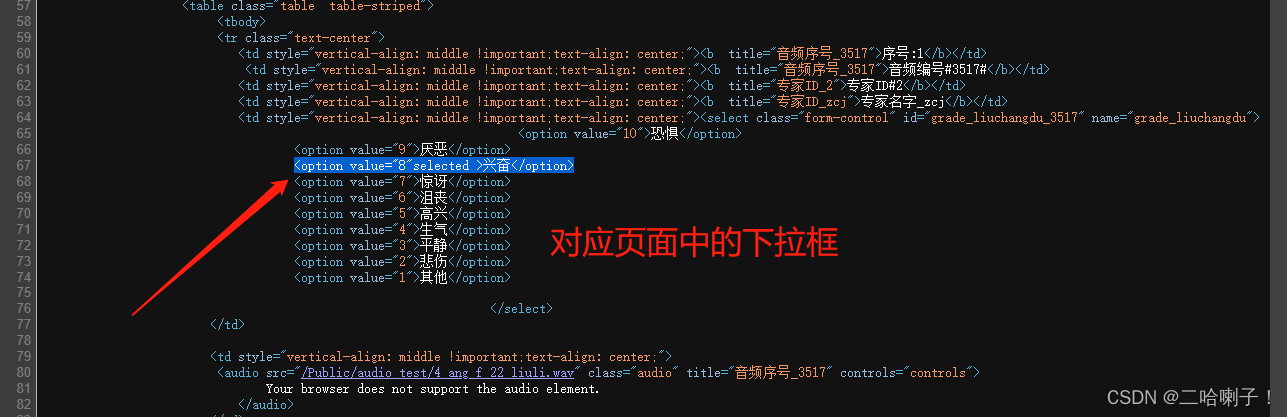
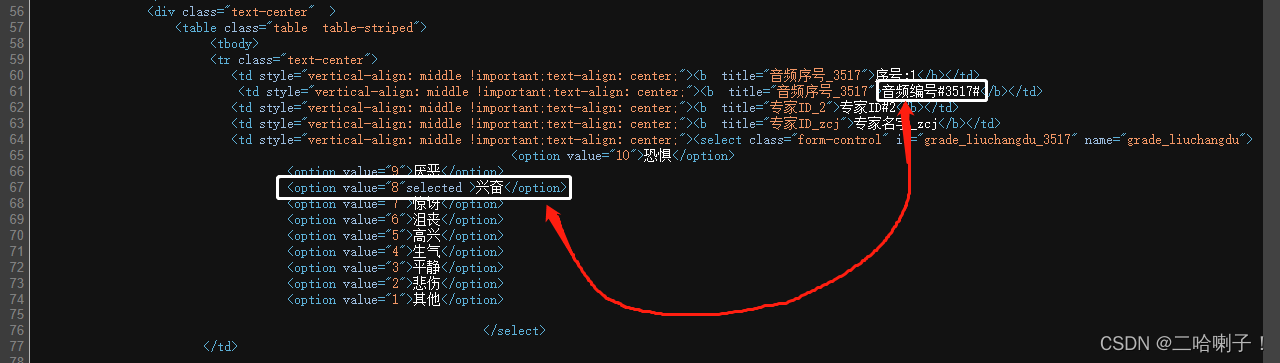
看selected的都有哪些情绪信息
import requests
import re
def getHTMLContent(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
emotion=re.findall(r'<option.+selected\s*>(.+?)</option', demo) #s后面的*代表空格
print(emotion)
【例2】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
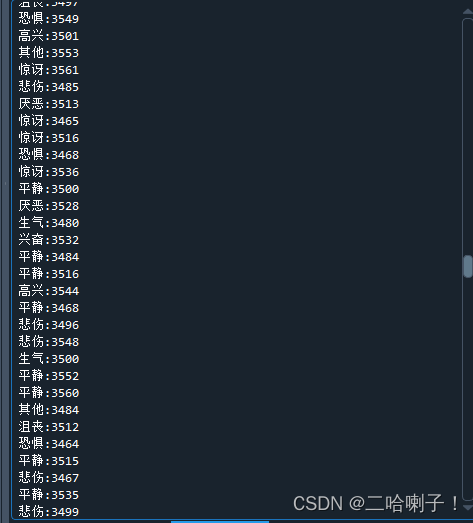
当前音频编号是对应情绪?
import requests
import re
dict = {}
def getHTMLContent(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
wav_number = re.findall(r'音频编号#(.+?)#</b>',demo)
emotion = re.findall(r'<option.+selected\s*>(.+?)</option>',demo)
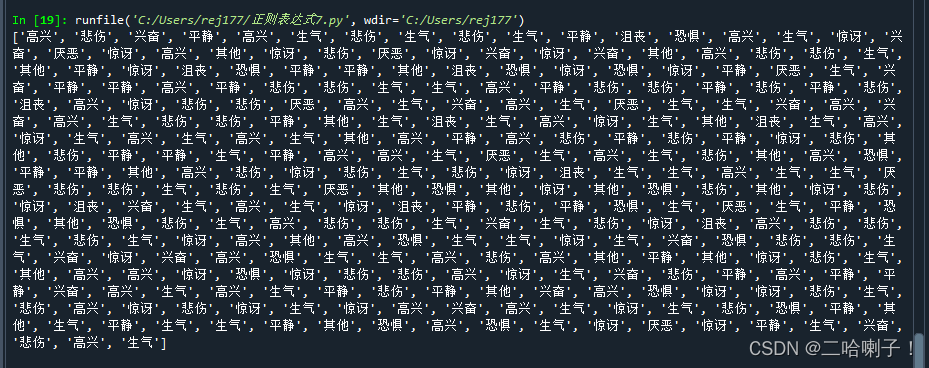
for index in range(len(emotion)):
print("%s:%s"%(emotion[index],wav_number[index]))
【例3】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
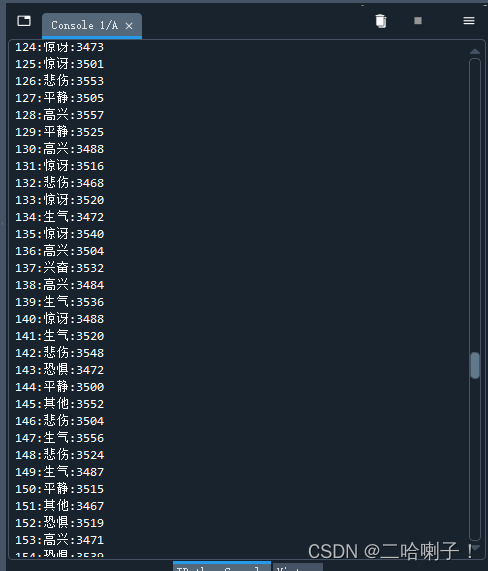
把序号、音频编号、情绪都输出
import requests
import re
dict = {}
def getHTMLContent(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
name = re.findall(r'>序号:(.+?)</b>', demo)
yinpinbianhao = re.findall(r'音频编号#(.+?)#</b>', demo)
plt = re.findall(r'<option.+selected\s*>(.+?)</option>', demo)
#获取<option>与</option>中带有selected的内容,注意selected后面有0个或多个空格
for index in range(len(plt)):
name1=name[index]
emotion = plt[index]
yinpinbianhao1=yinpinbianhao[index]
print("%s:%s:%s"%(name1,emotion,yinpinbianhao1))
dict[name1]=emotion
【例4】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
获取对应的音频链接
src=和class中间的内容,引号会带着(那是字符串)

import requests
import re
new_wav = []
def getHTMLContent(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
return r.text
except:
return"访问异常"
if __name__=="__main__":
url="http://emotion.bxbw-jyz.cn/Home/index/showPartData.html"
demo = getHTMLContent(url)
wav_number=re.findall(r'audio src=(.+?)class', demo)
for index in range(len(wav_number)):
new_wav_index = "http://emoution.bxbw-jyz.cn" + wav_number[index][1:-2]
new_wav.append(new_wav_index)
print(new_wav)
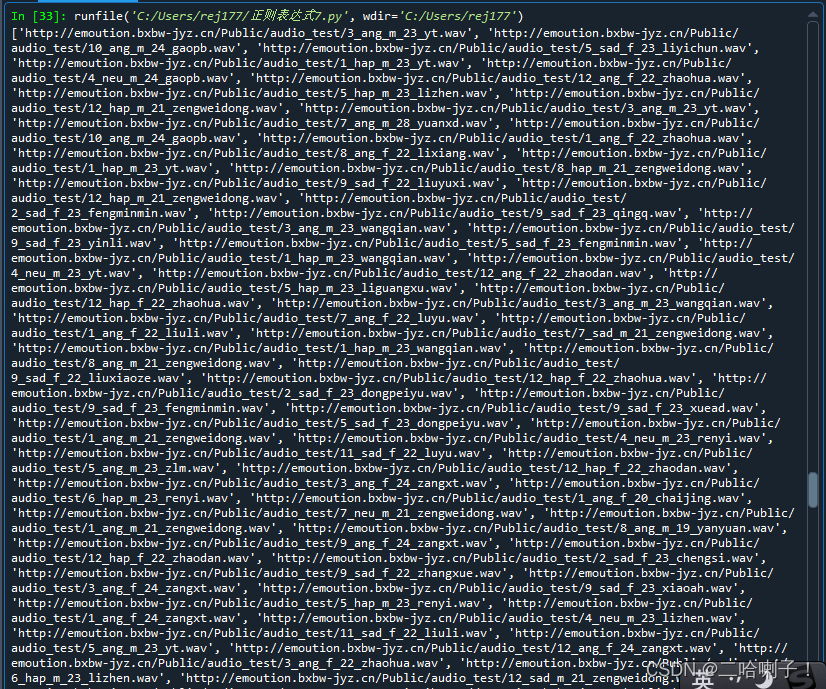
音频只有一百个,每个音频重复了三次