努力真的要贯穿人的一生吗?
你能活成你想要的样子吗?
真的不知道!

文章目录
- 一、栈的概念及结构
- 二、栈的实现(动态数组栈)
- 2.1 挑选实现栈的结构
- 2.2 栈结构的定义
- 2.3 初始化栈+销毁栈
- 2.4 入栈+出栈
- 2.5 判空+取栈顶元素+栈元素个数
- 2.6 一个小细节
- 2.7 测试模块儿
- 三、队列的概念及结构
- 四、队列的实现(单链表队列)
- 4.1 挑选实现队列的结构
- 4.2 队列结构的定义
- 4.3 初始化+判空+销毁
- 4.4 入队列+出队列
- 4.5 获取队头数据+获取队尾数据
- 4.6 获取队列中有效元素个数
- 4.7 测试模块儿
- 五、栈和队列的总结
一、栈的概念及结构
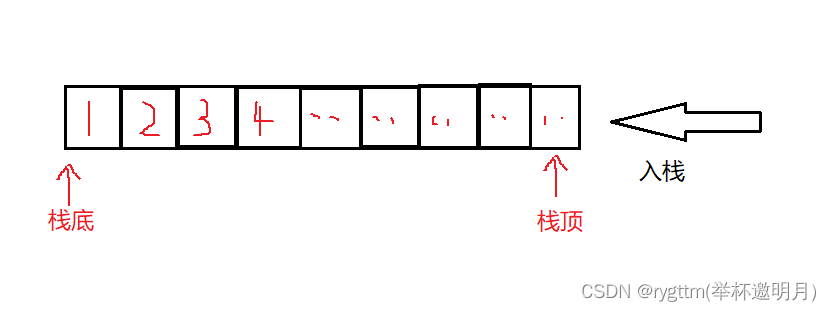
栈是一种特殊的线性表,它只允许 在一端插入和删除数据的操作。进行插入和删除数据的一端称为栈顶,另一端什么也不干的称为栈低。
我们插入数据和删除数据也有专业的名词,分别称为压栈和出栈,栈这样的结构遵循先进后出的原则。

二、栈的实现(动态数组栈)
2.1 挑选实现栈的结构
实现栈我们手头上有两种方式可以实现栈这样的结构,一种是数组一种是链表的形式,我们可以对比两者,挑选一下数组栈 和 链式栈哪个实现起来更优一些。
首先我们的栈需要的接口有,获取栈顶元素,入栈,出栈,判空,销毁栈,判断栈有效数据个数,栈的初始化等接口。
如果我们使用数组栈的话,入栈只需要像数组中下标为top的空间赋值就可以了,出栈只需要top下标减1就可以了,空间不够时,我们直接realloc扩大空间为原来的二倍,获取栈顶元素也简单,通过下标访问就可以了,判断有效数据个数,遍历一遍动态数组就可以了。
如果我们使用链式栈的话,用头部做栈底还需要考虑出栈之后找尾的问题,所以我们想到用双向链表来实现,如果用头部做栈顶的话,我们只要进行头插和头删就可以实现栈的这种结构了。
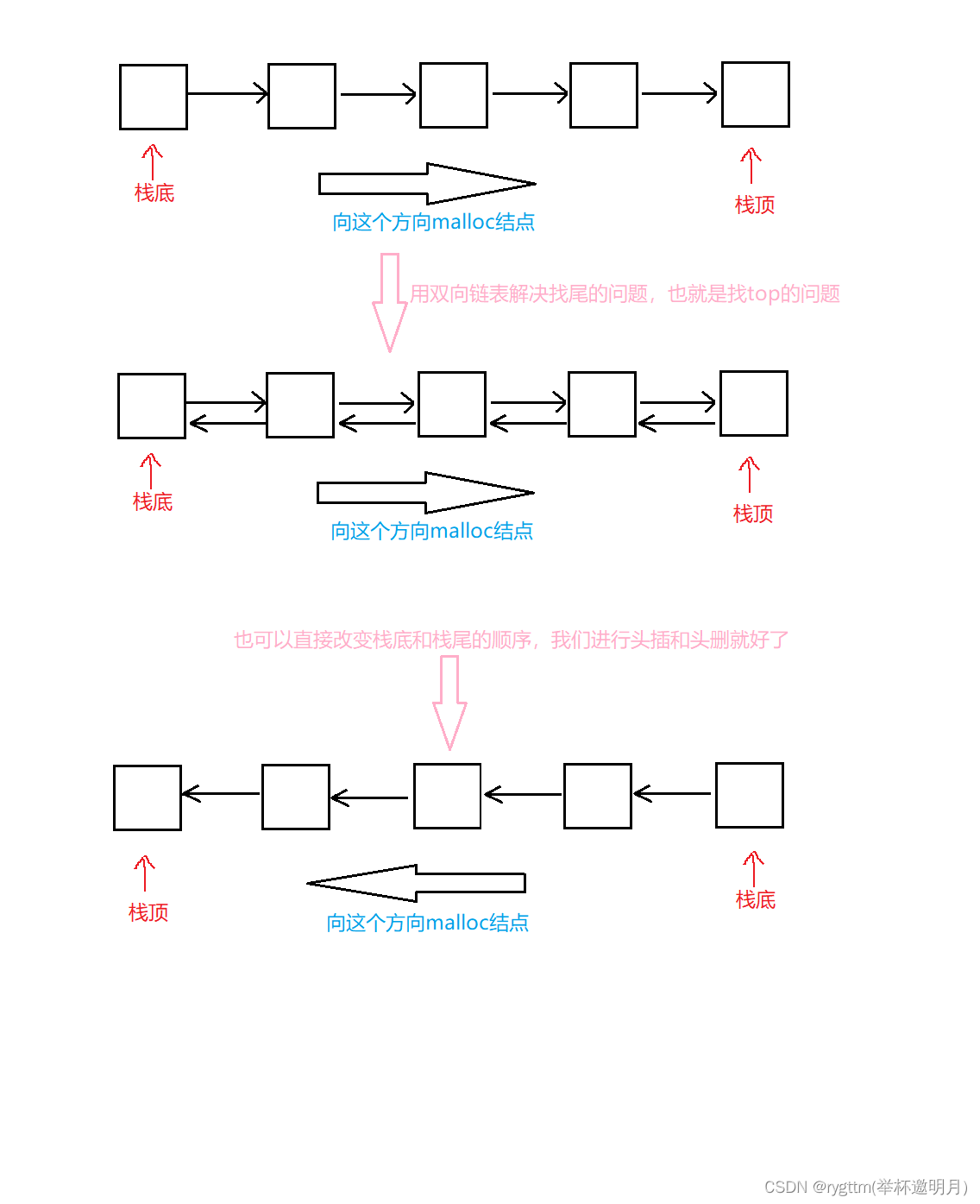
现在已经介绍完这两种结构,显而易见我们的数组栈要更优一些,如果频繁的入栈我们的链表需要不断地malloc这对程序性能的消耗是要大于数组的,因为我们数组一次性就开辟好那么大的空间了,不够的时候在去realloc,明显就可以看到数组栈在实现上结构还是要更优一些
2.2 栈结构的定义
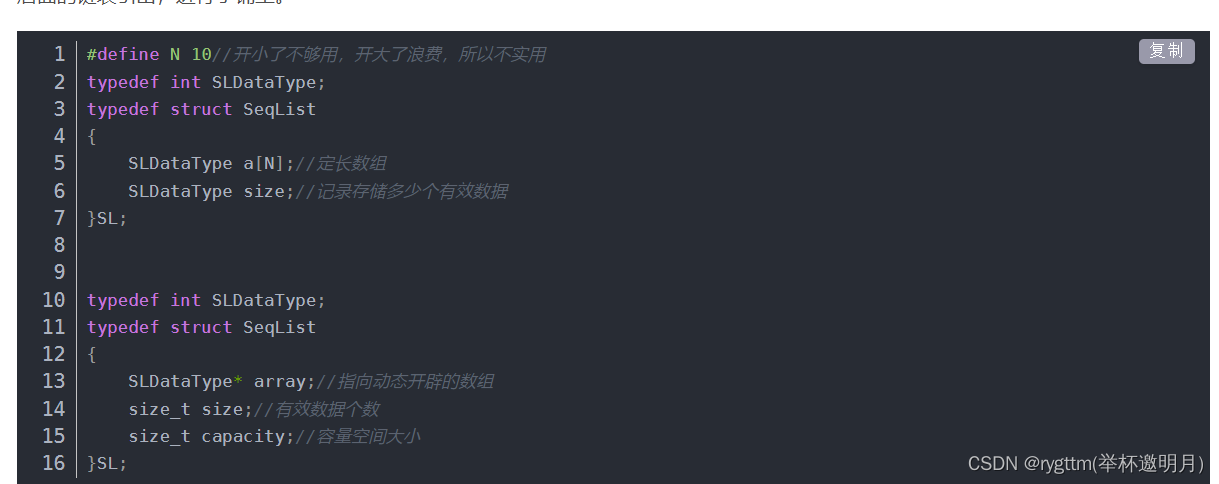
//静态栈结构 - 很不实用
typedef int STDataType;
#define N 10
typedef struct Stack
{
STDataType _a[N];
int _top; // 栈顶
}Stack;
//动态栈结构
typedef int STDataType;
typedef struct Stack
{
STDataType* array;
int top;//这代表我们栈顶的位置,top会随着栈空间数据的扩大随之变换
int capacity;
}ST;
使用定长数组实现的栈,真的是能把人笑死,这种破结构真的是废,改起来还得手动去改,简直low的不要不要的,我们毅然决然的选择动态数组的方式来实现,也可以叫柔性数组,用一个指针来维护我们动态开辟的数组空间,销毁就free,增加就malloc,修改就realloc,又实用又高级,你怎能不爱呢?
栈结构的定义和我们的顺序表结构定义还是很相似的,我们再定义栈顶位置的下标top,方便进行入栈和出栈的操作,然后再定义一个栈的空间大小,其实就是动态开辟的数组的空间大小。
2.3 初始化栈+销毁栈
void StackInit(ST* ps)
{
assert(ps);
ps->array = NULL;
ps->top = 0;//ps->top = -1; 我们的top也是可以给-1的
ps->capacity = 0;
//初始化时,top给的是0,意味着top指向栈顶数据的下一个
//我们的top指向的是最后栈顶数据的下一个,因为我们是先插入数据到下标为top的位置,然后top再++
//初始化时,top给的是-1,意味着top指向栈顶数据
//我们的top指向的是栈顶数据,因为我们要先将top+1,然后再往此时的top位置放数据,下一次也是先将top位置+1再放数据
//这是一个什么问题呢?(就是)是先放数据再移动top呢?还是先移动top再放数据呢?
}
我们大多数人的习惯应该是先将数据插入到下标的位置,然后再让下标++,所以我们这里的初始化top为0。
void StackDestroy(ST* ps)
{
assert(ps);
free(ps->array);
ps->array = NULL;
ps->capacity = ps->top = 0;
}
我们销毁栈之后,除了要将指针置为空,还要将top以及capacity等置为0,这样才算完成我们的销毁
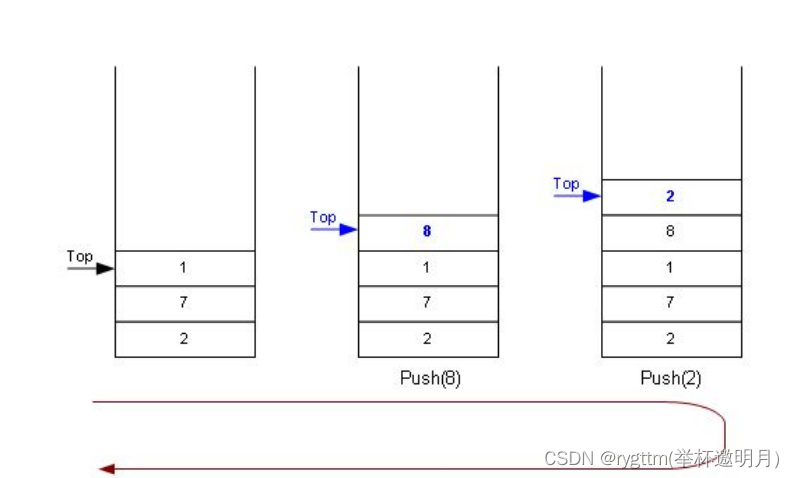
2.4 入栈+出栈
void StackPush(ST* ps, STDataType x)//将元素进行入栈
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->array, sizeof(STDataType) * newCapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
ps->array = tmp;
ps->capacity = newCapacity;
}
ps->array[ps->top] = x;
ps->top++;
}
我们这里的入栈操作和之前的顺序表还是有相似的地方,比如同时利用了realloc来开辟空间和修改空间,入栈的操作也较为简单,我们利用指针和数组的关系用下标为top的位置进行了赋值,实现的重点还是我们之前顺序表中的部分知识,这里不过多强调
void StackPop(ST* ps)//将元素进行出栈,删除数据
{
assert(ps);
assert(!StackEmpty(ps));//top为0的时候是不能进行删除的
ps->top--;
}
出栈也是比较简单的,只要我们的top–其实就意味着我们已经无法访问到原来top位置的数据了,也就相当于删除元素。
另外要注意一个点,在删除元素之前我们要判断栈是否为空,如果为空我们还删的话,top就会变成-1,此时如果我们一不小心引用了push操作,就会惹上大麻烦,产生越界访问的问题,因为我们对下标为-1的位置进行了访问。
2.5 判空+取栈顶元素+栈元素个数
bool StackEmpty(ST* ps)
{
assert(ps);
/*if (ps->top > 0)
{
return false;
}
else
{
return true;
}*/
return ps->top == 0;//这里的判断条件的正确与否,正好就对应上我们返回的是逻辑真还是逻辑假。true or false
}
判空这里我们巧妙地利用了栈为空时,top为0的特点。所以只要返回哪个逻辑表达式就可以了,如果相等返回真,真正好就是我们的栈为空,如果不相等返回假,假就是栈不为空。
STDataType StackTop(ST* ps)//取栈顶的数据
{
assert(ps);
assert(!StackEmpty(ps));//如果栈为空,就会报错
//我们的栈必须得有数据你才能取数据啊,如果没有数据你还取数据的话,就是访问下标-1的数据了,造成越界访问
return ps->array[ps->top - 1];
}
和之前的出栈接口相似,我们取栈顶数据时,栈也是不能为空的,如果为空,还是会造成越界访问的问题。所以我们也是需要断言处理一下。
int StackSize(ST* ps)
{
assert(ps);
return ps->top;//top指向的是栈顶数据的下一个位置,又因为它从0开始增大,所以top的值正好就是栈数据的个数
}
由于每次我们入栈的操作是先入元素后++top,自然top肯定是指向栈顶元素的下一个位置的,所以top下标的值正好就是栈中元素的个数。
2.6 一个小细节
我们在访问一个结构体变量中的成员时,通常有两种方式,一种是直接通过变量+点操作符去访问变量,另一种是创建一个结构体指针,通过这个指针找到结构体的各个成员,但其实还有一个有意思的操作就是我们可以先取结构体变量的地址,然后在通过这个地址访问结构体变量的成员。
(&st)->array;类似于这样的方式,这样的代码还是挺有意思的。
2.7 测试模块儿
#include "Stack.h"
void TestStack()
{
ST st;
//1.用我们的结构体类型定义了一个结构体,结构体里面的array指针会指向我们动态开辟的数组栈,用于维护我们的数组栈
//2.我们其实实现的也是动态的数组栈,如果要实现静态的数组栈的话,我们还需在结构体里面定义定长数组,这非常的不方便
//跟个傻瓜一样,太低级了,所以我们选择柔性数组也就是用指针来维护我们的动态数组栈的方式实现,这还是比前者要高级的。
StackInit(&st);
//(&st)->array;值得注意的是,我们有时候也不必去创建一个结构体类型的指针来访问结构体成员,可以通过结构体变量本身的地址来
//访问其内部的成员,有意思哈。
StackPush(&st, 1);
StackPush(&st, 2);
StackPush(&st, 3);
StackPush(&st, 4);
printf("%d ", StackTop(&st));
StackPop(&st);
printf("%d ", StackTop(&st));
StackPop(&st);
StackPush(&st, 5);
StackPush(&st, 6);
StackPush(&st, 7);
while (!StackEmpty(&st))
{
printf("%d ", StackTop(&st));
StackPop(&st);
}
//入栈1234出栈4321
StackDestroy(&st);//如果我们不destroy的话,就会造成内存泄漏。
}
int main()
{
TestStack();
return 0;
}
三、队列的概念及结构
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出
FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头
队列的特点其实正好和栈反过来了,我们的栈是先入后出,而队列是先入先出。
入队列:进行插入的一端称为队尾
出队列:进行删除的一端称为队头

四、队列的实现(单链表队列)
4.1 挑选实现队列的结构
队列实现时,需要入队列,出队列,获取队头数据,获取队尾数据,判空,队列中有效元素个数,以及一些边角料接口,队列初始化,销毁等接口,通过实现这些接口的优劣性,我们来对比数组和链表实现时的优劣性。
使用数组,在出队列时,如果使用数组是比较浪费时间的,因为我们只要出队列一个数据,其他的数据都要跟着移动,这会很造成时间上的浪费。
使用链表,我们入队列只要malloc一个结点出来就好,出队列也简单只要free掉head指针指向的空间就好。但入队列时我们显然需要一个tail指针,指向队尾,以方便我们进行后续的数据入队列。
所以挑选完毕,我们选择以链表的形式实现队列。
4.2 队列结构的定义
typedef int QDataType;
typedef struct QueueNode//队列结构中的每一个结点
{
struct QueueNode* next;
QDataType data;
}QueueNode;
typedef struct Queue//我们的队列结构
{
QueueNode* head;
QueueNode* tail;
//这里我们其实也可以将这两个队列结点指针单独定义出来,但是这样不太符合代码的主流风格,所以我们将他们包到一个结构体里。
}Queue;
//单链表那里,我们是单独将单链表的头指针拎出来,独立于结点结构体定义的,这里我们是将两个指针合在一起定义到一个
//队列结构里面
这里有关于定义指针的核心原则需要介绍一下:如果有单个指针,我们直接定义就好了,如果有多个指针以便为了我们传参时候的流畅性,我们选择利用结构体将其封装起来,这样在传参时,可以避免多次传参以及无谓的思想消耗。
与我们之前的单链表,双链表等不同的地方在于,他们只需要一个head指针就可以完成诸多接口的实现了而且很方便就完成了实现,但我们的队列如果没有tail的话,实现起来还是挺烦人的,所以我们定义了两个队列指针,用于接口的实现。
另外的队列结点也是一个混合体,所以我们也需要用结构体将其封装一下,这样在实现接口时真的会方便不少。
可能有的人看到这里会觉得方便在哪里啊?我怎么没有看到啊?不封装不好吗?非得整些花里胡哨的。我只能说呵呵,你要不封装,你的接口很有可能就是这样的。
你觉得你传参的时候会舒服吗?小样,累不死你。
//因为我们的队列不会在队尾进行删除,所以我们定义的尾指针的价值就得到了体现,而且用结构体封装这些指针还是有很多
//好处的,我们通过结构体指针就可以找到这些指针了,如果你不用结构体单独定义两个结点的指针,也不是不可以,但是
//你后面接口实现的时候,你就得传两个参数了,一个头指针一个尾指针,而且你要想修改他们的指向还得传二级指针
//就像下面这样来使用,那你调用接口的时候很有可能会被它烦死
void QueueInit(Queue** pphead, Queue** pptail);
4.3 初始化+判空+销毁
void QueueInit(Queue* pq)
{
assert(pq);
pq->head = NULL;
pq->tail = NULL;
}
从第一个接口其实就可以很好的感受到,我们上面定义结构的优点了,我只需要传一个队列指针过来就好了,然后通过这两个指针我可以修改这个队列的任何数据,什么都可以修改。
我们先通过这个队列指针找到头结点指针和尾结点指针,将他们置空。
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->head == NULL;
}
这里的逻辑表达式写出tail也可以,因为队列为空的时候,我们的tail和head都是NULL,所以无需过多考虑,我们依旧利用逻辑表达式的结果进行函数值的返回。
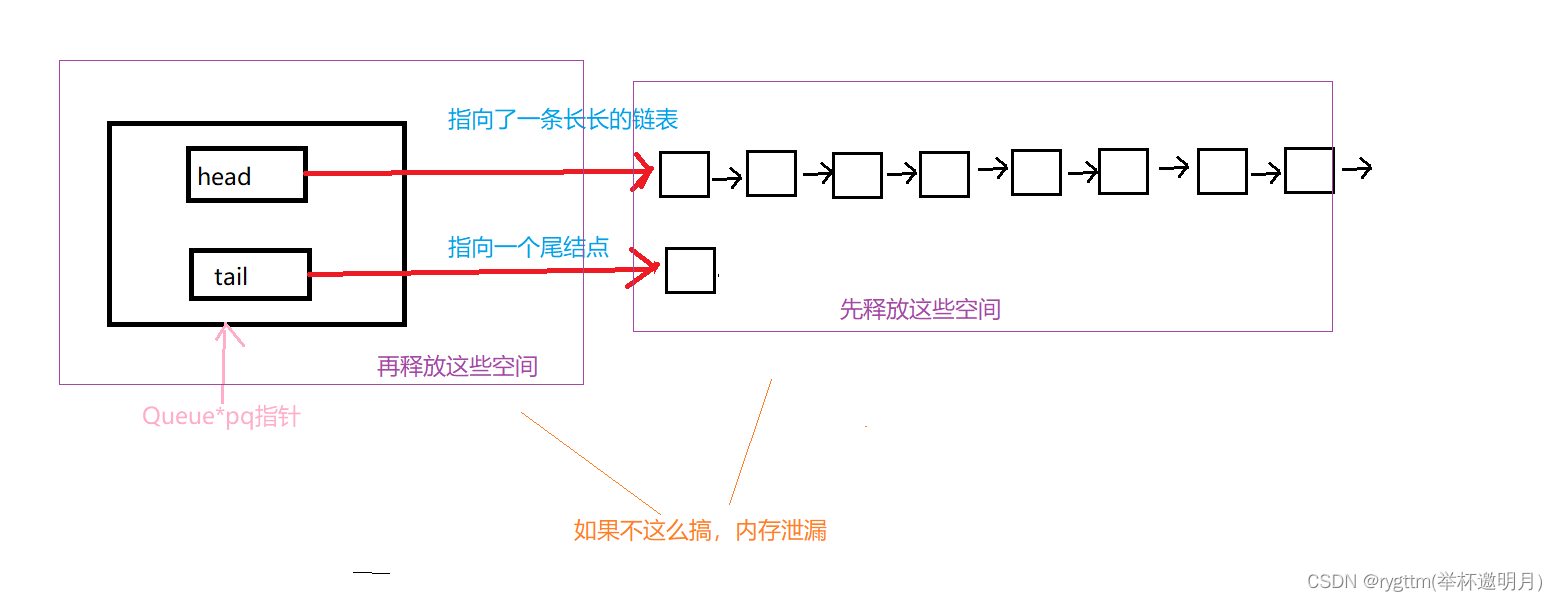
void QueueDestroy(Queue* pq)//销毁队列
{
assert(pq);//head和tail可以为空,但我们的队列结构肯定不可以为空,如果队列结构都为空了,那肯定是我们传的参数出了问题
QueueNode* cur = pq->head;
//while (cur != pq->tail)
//{
// //我们这里进行释放队列结点
// //但这种逻辑其实有问题,因为你最后一个队列结点的空间是没有进行删除的,会造成内存泄漏。
//}
while (cur != NULL)//当我们的cur走到NULL时,正好说明队列结点空间已经释放完毕了
{
QueueNode* next = cur->next;
free(cur);
cur = next;
}
pq->head = pq->tail = NULL;
}
这里的队列销毁大家要注意分层释放空间,否则很容易造成内存泄漏问题。
因为我们有两个空间需要释放,所以为了避免内存泄漏,我们采用分层释放的手段来进行队列的销毁。
4.4 入队列+出队列
void QueuePush(Queue* pq, QDataType x)
{
//这里我们要分两种情况
//1.我们的tail和head都是正常的,然后我们直接在tail后面插入队列结点,这就相当于我们的入队列,然后再更新一下tail的位置。
//2.如果我们的tail和head都为空的话,我们直接将新的队列结点的地址赋值给我们的head和tail,此刻我们的尾和头所指位置是相同的
assert(pq);
QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));
newnode->data = x;
newnode->next = NULL;//将我们队列结点初始化
if (pq->head == NULL)
{
pq->head = pq->tail = newnode;
}
else
{
pq->tail->next = newnode;
pq->tail = newnode;
}
}
入队列这里的代码,似乎让我又回到了实现链表的那段时光了,如果你是第一次入队列,那第一个结点的地址就得赋值给我们的head和tail,如果后续入队列的话,直接尾插到tail的next就好了,然后我们再将tail向后移动,为了下一次的数据入队列。
每入一次队列我们都需要malloc一个结点出来,每次的结点初始化可以保证我们的链表尾部一定指向空。
void QueuePop(Queue* pq)
{
assert(pq);//表达式计算结果为假(0),assert就会报错
assert(!QueueEmpty(pq));//我们的队列不可以为空
QueueNode* next = pq->head->next;//如果我们这里的队列头指针为空,这里就造成内存读取权限访问冲突。
free(pq->head);
//我们队列中的结点全被free掉了,可是tail的指向还是没人给他改一下,它还在指向一个已经被释放掉了的空间,
//tail就是一个典型的野指针
pq->head = next;
if (pq->head == NULL)
{
pq->tail = NULL;//我们的链表已经删除完之后,为了防止tail变为野指针,我们也让tail置为空
}
}
在链表中我们如果对数据进行删除一般都采用free空间的方式来解决,在数组中对数据的删除,其实是通过调整下标的位置,让我们无法访问到先前的数据,来达到删除数据的效果。这也是一个链表和数组的一个不同之处。
同样,在出队列之前,我们需要检查一下队列是否为空,如果为空,我们还出队列的话,就会造成空指针访问的操作,也就是读取访问权限冲突。
另外值得注意的一个点是,我们在不断释放空间的过程中,tail如果不置空,他是会变成野指针的。

4.5 获取队头数据+获取队尾数据
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));//断言为假,程序就会崩
return pq->head->data;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));//粗暴判断队列结构和队列中的结点不为空
return pq->tail->data;
}
以上的这两个接口过于简单,我也就不过多赘述了,只要把握好不管取队头还是取队尾的数据,我们的队列都不可以为空,加上断言就好了。
4.6 获取队列中有效元素个数
int QueueSize(Queue* pq)//我们也可以在队列结构体定义那里加一个成员size_t _size,我们push它就++,pop它就--。
{
assert(pq);
QueueNode* cur = pq->head;
int i = 0;
while (cur)
{
i++;
cur = cur->next;
}
return i;
}
我们只要将队列遍历一遍就可以得到有效元素的个数了。
4.7 测试模块儿
void TestQueue1()
{
Queue q;
QueueInit(&q);//我们要改变队列结构,就传结构体指针过去,有了结构体指针,结构体中的东西就可以随便改了
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);//我们要想清楚我们改的是队列结构,而不是队列结点,所以我们应该传的是队列的地址,
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);//想取到队列的下一个数据,必须得先出队列一个数据
}
printf("\n");
/*QueuePop(&q);
QueuePop(&q);
QueuePop(&q);
QueuePop(&q);*/
while (!QueueEmpty(&q))
{
printf("%d", QueueFront(&q));
QueuePop(&q);
}
//1.我们删除四次之后,通过调试窗口可以看出,我们的head已经变为空指针了,但此时tail所指的位置却不为空,所指结点
//的data却已经变为随机值了,此时tail其实是个野指针,因为删除的过程我们只注意移动head了,却没有管tail的死活
//2.printf("%d",QueueBack(&q));
//正好我们调用的QueueBack中的assert检查出来我们的队列结构此时为空了,但如果注释掉assert,其实是会打印出一个随机值
QueueDestroy(&q);
}
//int main()
{
TestQueue1();
return 0;
}
五、栈和队列的总结
总结起来,栈是先进后出的,队列是先进先出的,我们通过数组和链表的形式分别实现了栈和队列,我自己感觉也是有些混的,加上之前的链表以及顺序表部分的实现,确实有点恶心,不过只要多敲几遍,多体会几遍,相信还是能够熟练掌握的,毕竟这些和树比起来还是难度较低啊。