文章目录
- BERT:用于语言理解的深度双向转换器的预训练
- 一、摘要
- 三、BERT
- 介绍BERT及其详细实现
- 答疑:为什么没有标注的数据可以用来预训练模型?
- 1. 掩码语言模型(Masked Language Model, MLM)
- 2. 下一句预测(Next Sentence Prediction, NSP)
- 3. 预训练数据与目标
- 4. 为什么未标记数据能用于预训练?
- 5. 补充说明
- 模型架构
- 输入输出表示
- 3.1 预训练BERT
- 3.2 微调BERT
- 总结:BERT的突出贡献
- 1. 解决了传统语言模型的「单向上下文限制」问题
- 2. 解决了NLP任务的「任务特定架构依赖」问题
- 3. 缓解了「长距离依赖」和「语义消歧」问题
- 4. 降低了「高质量标注数据依赖」问题
- 5. 统一了NLP的「迁移学习范式」
- 实际应用中的效果举例
- 局限性与后续改进
- 总结
BERT:用于语言理解的深度双向转换器的预训练
论文:https://arxiv.org/abs/1810.04805
一、摘要
引入一种新的语言表示模型BERT,它源于Transformers的双向编码器表示。Bidirectional Encoder Representations from Transformers。
BERT的原理简述——便捷性
BERT旨在通过联合调节所有层中的左右上下文,从未标记文本中预训练深度双向表示。因此,只需一个额外的输出层即可对预训练的BERT模型进行微调,为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定任务的架构进行实质性修改。
BERT的效果
BERT在概念上简单,在经验上强大,它在11个自然语言处理任务上获得了新的最先进的结果,包括将GLUE得分提高到80.5%(7.7%的绝对改善),MultiNLI准确度达到86.7%(绝对改善4.6%),SQuAD v1.1问答测试F1为93.2(绝对改善1.5分),SQuAD v2.0测试F1为83.1(绝对改善5.1分)。
三、BERT
介绍BERT及其详细实现
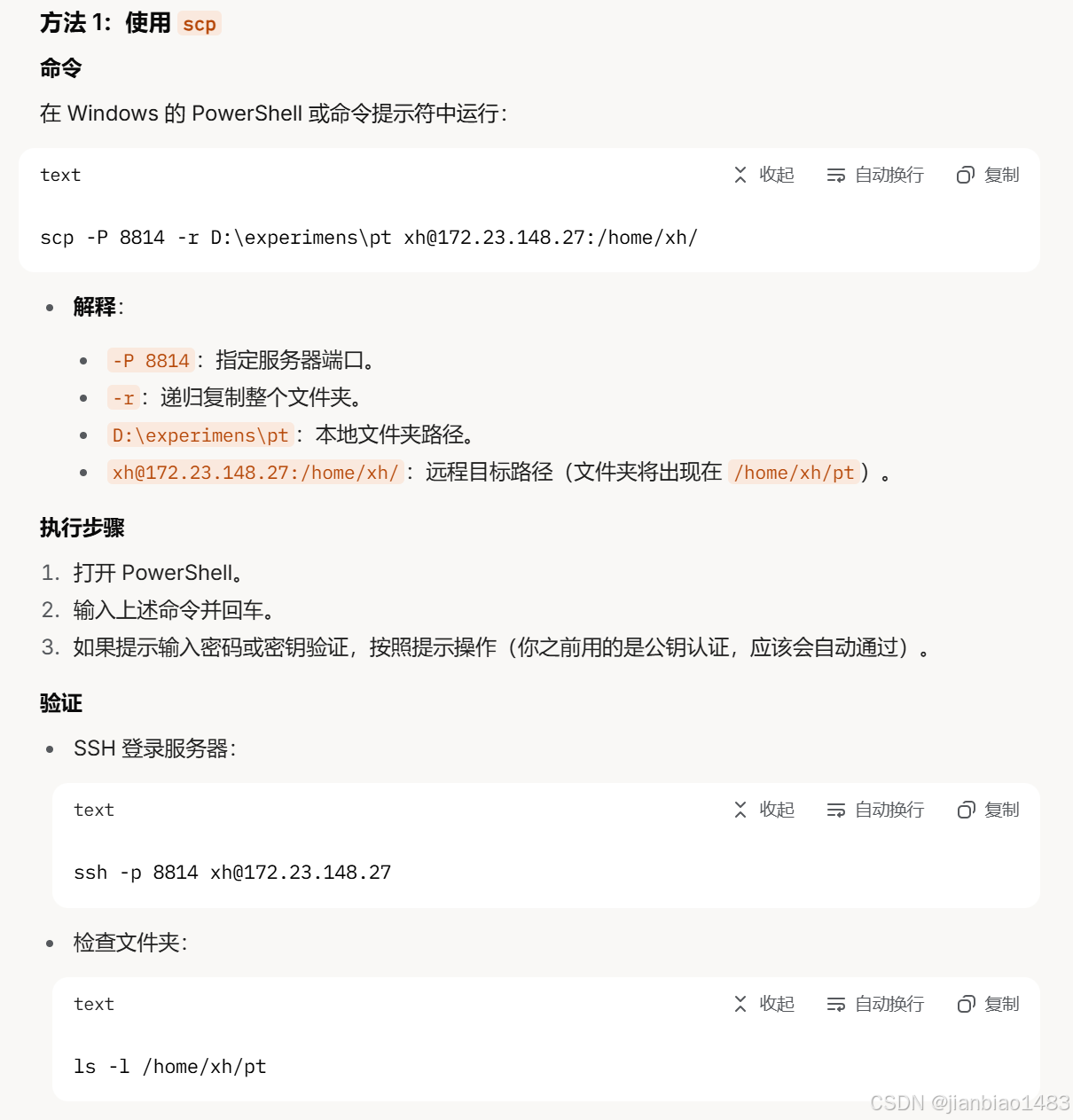
BERT框架分为两个步骤:预训练和微调。
- 预训练阶段,模型在不同的预训练任务中对未标记的数据进行训练;
- 对于微调,BERT模型首先使用预训练的参数进行初始化,并且所有参数都使用来自下游任务的标记数据进行微调。每个下游任务具有单独的微调模型;
图1中的问答示例将作为本节的运行示例。
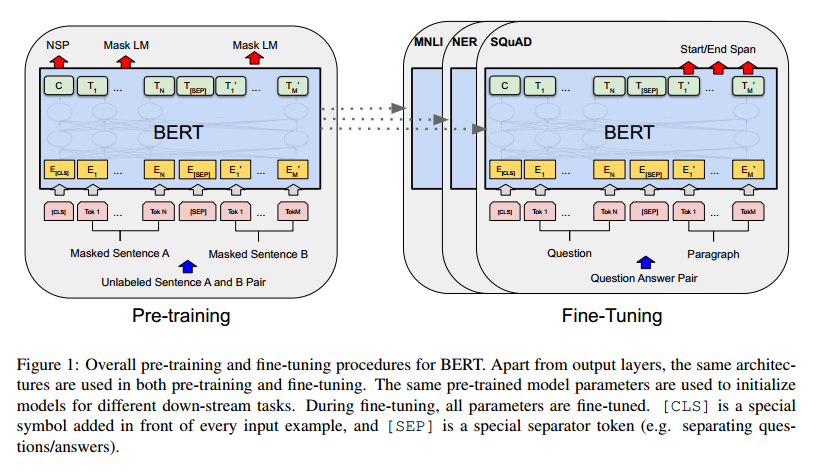
图一:BERT的总体预训练和微调过程。除了输出层,预训练和微调都使用相同的架构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调期间,所有参数都进行微调。[CLS]是在每个输入示例前面添加的特殊符号,而[SEP]是一个特殊的分隔符标记(例如分隔问题/答案)。
答疑:为什么没有标注的数据可以用来预训练模型?
BERT的预训练阶段确实是在未标记的数据上进行的,但它通过设计自监督学习(Self-supervised Learning) 任务,从无标签数据中自动生成监督信号。具体来说,BERT通过以下两个预训练任务来学习语言表示:(后面论文中有详情)
1. 掩码语言模型(Masked Language Model, MLM)
- 核心思想:随机遮盖输入文本中的部分单词(通常比例为15%),让模型预测被遮盖的单词。
- 具体步骤:
- 输入文本中的部分单词会被替换为
[MASK]标记(如:"The cat sat on the [MASK].")。 - 模型需要根据上下文预测被遮盖的原始单词(如预测
[MASK]位置应为"mat")。
- 输入文本中的部分单词会被替换为
- 改进细节:
- 为了缓解预训练(有
[MASK])和微调(无[MASK])的不一致性,BERT在遮盖时采用以下策略:- 80%的概率替换为
[MASK]。 - 10%的概率替换为随机单词。
- 10%的概率保留原单词。
- 80%的概率替换为
- 模型通过交叉熵损失函数优化预测结果。
- 为了缓解预训练(有
2. 下一句预测(Next Sentence Prediction, NSP)
- 核心思想:判断两个句子是否是连续的上下文关系,学习句子级别的语义关联。
- 具体步骤:
- 输入一对句子
A和B,其中:- 50%的概率
B是A的真实下一句(正例)。 - 50%的概率
B是随机采样的其他句子(负例)。
- 50%的概率
- 模型需要预测
B是否是A的下一句(二分类任务)。
- 输入一对句子
- 示例:
- 正例:
("[CLS] The cat sat on the mat. [SEP] It was very cozy. [SEP]")→ 标签IsNext。 - 负例:
("[CLS] The cat sat on the mat. [SEP] The sky is blue. [SEP]")→ 标签NotNext。
- 正例:
3. 预训练数据与目标
- 数据来源:大规模无标注文本(如Wikipedia、BookCorpus)。
- 训练目标:同时优化MLM(单词级别)和NSP(句子级别)的损失函数,使模型学会:
- 双向上下文表示(通过MLM)。
- 句子间逻辑关系(通过NSP)。
4. 为什么未标记数据能用于预训练?
- 自监督的巧妙设计:通过破坏输入数据(如遮盖单词或打乱句子)并让模型修复,无需人工标注即可生成监督信号。
- 通用表征学习:模型从海量文本中学习通用的语言规律(如语法、语义、常识),为下游任务提供良好的初始化参数。
5. 补充说明
- BERT的预训练需要极大的计算资源(TPU/GPU集群),因此通常直接使用已预训练好的模型进行微调。
- 后续研究(如RoBERTa)发现NSP任务并非必要,仅MLM也能取得良好效果,但BERT的原始设计包含两者。
回到论文
通过这两个任务,BERT能够从未标记数据中学习丰富的语言表示,进而通过微调适配各种下游任务(如文本分类、问答等)。
BERT的一个显著特点是其跨不同任务的统一架构。预训练架构和最终下游架构之间的差异最小。
模型架构
模型架构时基于Transformer的,但是是双向的。
模型架构 BERT的模型架构是一个多层双向Transformer编码器,基于Vaswani的Transformer(2017)(就是著名的那篇"Attention all you need")实现,并在tensor2tensor库中发布。由于Transformer的使用已经变得普遍,我们的实现与原始几乎相同,我们将省略模型架构的详尽背景描述,并请读者参考Vaswani等人(2017)以及优秀的指导。
在这项工作中,我们将层数(即Transformer块)表示为L,隐藏大小表示为H,自注意头的数量表示为A。我们主要报告两种模型大小的结果:BERT-BASE(L=12,H=768,A=12,总参数=110M)和BERT-LARGE(L=24,H=1024,A=16,总参数= 340M)。
为了进行比较,我们选择了BERT-BASE与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer使用双向自注意,而GPT Transformer使用约束自注意,其中每个令牌只能关注其左侧的上下文。
输入输出表示
WordPiece嵌入:基于子词的分词方法,但它在合并子词对时使用最大化似然估计(MLE),即基于语言模型的概率建模
输入嵌入分为:标记嵌入(标识每个子词),分割嵌入(标识句子),位置嵌入(标识位置)
输入/输出表示 为了使BERT处理各种下游任务,我们的输入表示能够在一个令牌序列中明确地表示单个句子和一对句子(例如,问题,答案)。在整个工作中,“句子”可以是连续文本的任意跨度,而不是实际的语言句子。“序列”是指BERT的输入令牌序列,它可以是单个句子或两个句子组合在一起。
我们使用WordPiece嵌入(Wu et al,2016),具有30000个标记词汇表。每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此标记对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被打包在一起成为单个序列。我们以两种方式区分句子。首先,我们用一个特殊的标记([SEP])将它们分开。2其次,我们向每个标记添加一个学习的嵌入,指示它是属于句子A还是句子B。3如图1所示,我们将输入嵌入表示为E,将特殊[CLS]标记的最终隐藏向量表示为 C ∈ R H C \in R^H C∈RH,将第i个输入标记的最终隐藏向量表示为 T i ∈ R H T_i \in R^H Ti∈RH。
对于一个给定的token,它的输入表示是通过对相应的token、segment和position嵌入求和来构造的。

图二:BERT输入表示。输入嵌入是标记嵌入、分割嵌入和位置嵌入的总和。
3.1 预训练BERT
与Peters等人(2018 a)和拉德福等人不同(2018),我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,我们使用本节中描述的两个无监督任务来预训练BERT。该步骤在图1的左侧部分中呈现。
任务#1:Masked LM 直觉上,我们有理由相信,深度双向模型比从左到右模型或从左到右和从右到左模型的浅层连接更强大。不幸的是,标准的条件语言模型只能从左到右或从右到左训练,因为双向条件会让每个单词间接地“看到自己”,并且该模型可以在多层上下文中简单地预测目标词。
为了训练深度双向表征,我们简单地随机屏蔽一定比例的输入标记,然后预测那些被屏蔽的标记词。我们将这个过程称为“屏蔽LM”(MLM),尽管在文献中它通常被称为完形填空任务(Taylor,1953)。在这种情况下,对应于掩码标记的最终隐藏向量被馈送到词汇表上的输出softmax中,在我们所有的实验中,我们随机屏蔽每个序列中所有WordPiece标记的15%。与去噪自动编码器(Vincent et al,2008)相比,我们只预测被屏蔽的单词,而不是重建整个输入。
实际上就是用完型填空的方式,来进行预训练。
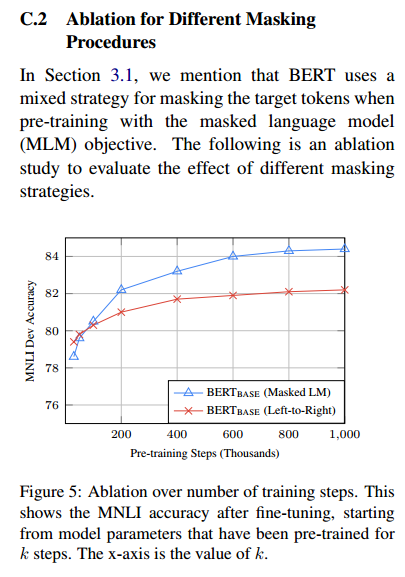
虽然这允许我们获得双向预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为[MASK]令牌在微调期间不会出现。为了缓解这一点,我们并不总是用实际的[MASK] token替换“masked”单词。训练数据生成器随机选择15%的token位置进行预测。如果第i个token被选中,我们用(1)80%用[MASK] token(2)10%的时间用随机token(3)10%的时间用未改变的第i个token。然后,Ti将用于预测具有交叉熵损失的原始token。我们在附录C.2中比较了这个过程的变化。
任务#2:下一句预测(NSP) 许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都是基于理解两个句子之间的关系,而语言建模并不能直接捕捉到这一点。为了训练一个理解句子关系的模型,我们对一个二值化的下一句预测任务进行了预训练,这个任务可以从任何单语语料库中简单地生成。具体来说,当为每个预训练示例选择句子A和B时,50%的时间B是A之后的实际下一个句子(标记为IsNext),并且50%的时间它是来自语料库的随机句子(标记为NotNext)。如图1所示,C用于下一句预测(NSP)。尽管简单,我们在第5.1节中证明,针对这一任务的预训练对QA和NLI都非常有益。
NSP任务与Jernite et al(2017)和Logeswaran and Lee(2018)中使用的表征学习目标密切相关。然而,在之前的工作中,只有句子嵌入被转移到下游任务,BERT将所有参数转移到初始化最终任务模型参数。
训练了哪些语料
预训练数据预训练过程在很大程度上遵循现有的语言模型预训练文献。对于预训练语料库,我们使用BooksCorpus(8亿单词)(Zhu et al,2015)和英文维基百科(25亿单词)。对于维基百科,我们只提取文本段落,而忽略列表,表格和标题。为了提取长的连续序列,使用文档级语料库而不是像十亿字基准(Chelba et al,2013)那样的混洗的文本级语料库是至关重要的。
3.2 微调BERT
微调是直接的,因为Transformer中的自我注意机制允许BERT通过交换适当的输入和输出来建模许多下游任务-无论它们涉及单个文本还是文本对。对于涉及文本对的应用程序,一个常见的模式是在应用双向交叉注意之前独立编码文本对,例如Parikh et al(2016); Seo et al(2017). BERT使用自注意机制来统一这两个阶段,因为使用自注意编码串联文本对有效地包括两个句子之间的双向交叉注意。
对于每个任务,我们只需将特定于任务的输入和输出插入BERT,并端到端地微调所有参数。在输入端,来自预训练的句子A和句子B类似于(1)释义中的句子对,(2)蕴涵中的假设-前提对,(3)问答中的问题-段落对,以及(4)一个堕落的文本- 在输出端,标记表示被馈送到输出层中用于标记级任务,例如序列标记或问题回答,并且[CLS]表示被馈送到输出层中用于分类,例如蕴涵或情感分析。
与预训练相比,微调相对简单。从完全相同的预训练模型开始,本文中的所有结果最多可以在单个Cloud TPU上复现1小时,或者在GPU上几个小时。我们在第4节的相应小节中描述了特定于任务的详细信息。更多详细信息可以在附录A.5中找到。

总结:BERT的突出贡献
BERT(Bidirectional Encoder Representations from Transformers)是自然语言处理(NLP)领域的里程碑式模型,它通过预训练-微调范式解决了多个核心问题,显著提升了各类NLP任务的性能。以下是BERT主要解决的问题及其贡献:
1. 解决了传统语言模型的「单向上下文限制」问题
- 传统方法的缺陷:
- 在BERT之前,主流语言模型(如GPT、ELMo)要么是单向的(从左到右或从右到左),要么是浅层双向的(如ELMo通过拼接左右向LSTM的结果)。
- 单向模型无法同时利用单词的完整上下文信息(例如,预测单词"bank"时,无法同时考虑左右侧的上下文:“river bank” vs. “bank account”)。
- BERT的解决方案:
- 通过Masked Language Model (MLM) 预训练任务,强制模型基于双向上下文预测被遮盖的单词,真正实现了深度双向编码。
- 效果:模型能更准确地理解词语的语义(如一词多义)和句法结构。
2. 解决了NLP任务的「任务特定架构依赖」问题
- 传统方法的缺陷:
- 不同NLP任务(如文本分类、问答、命名实体识别)需要设计不同的模型架构,且通常需要大量任务特定的标注数据。
- BERT的解决方案:
- 通过统一的预训练-微调框架,使用相同的预训练模型结构适配多种下游任务,仅需在预训练模型基础上添加轻量级的任务相关输出层(如分类头)。
- 效果:
- 减少了对任务特定架构设计的依赖。
- 在小样本场景下表现更好(预训练模型已学习通用语言知识)。
3. 缓解了「长距离依赖」和「语义消歧」问题
- 传统方法的缺陷:
- 基于RNN的模型难以捕捉长距离依赖(梯度消失/爆炸)。
- 词向量(如Word2Vec)是静态的,无法根据上下文调整词义(如"apple"在水果和公司场景下的不同含义)。
- BERT的解决方案:
- 基于Transformer的自注意力机制,直接建模任意距离的单词关系。
- 生成动态上下文词向量(同一单词在不同句子中的表示不同)。
- 效果:显著提升了对复杂语境的理解能力(如指代消解、语义角色标注)。
4. 降低了「高质量标注数据依赖」问题
- 传统方法的缺陷:
- 监督学习需要大量人工标注数据,成本高昂。
- BERT的解决方案:
- 通过自监督学习(MLM和NSP)从无标注文本中预训练,仅需在下游任务微调时使用少量标注数据。
- 效果:在低资源任务(如小语种、垂直领域)中仍能表现良好。
5. 统一了NLP的「迁移学习范式」
- 传统方法的缺陷:
- 迁移学习在计算机视觉(CV)中已成熟(如ImageNet预训练),但NLP领域缺乏通用方案。
- BERT的解决方案:
- 提供了一种可扩展的预训练框架,后续模型(如RoBERTa、ALBERT)均基于此范式改进。
- 效果:推动NLP进入「预训练大模型」时代,成为工业界和学术界的基础工具。
实际应用中的效果举例
| 任务类型 | BERT的改进 |
|---|---|
| 文本分类(如情感分析) | 准确率提升5-10%以上(如GLUE基准) |
| 问答系统(如SQuAD) | F1分数首次超过人类基线(从85.8%提升到93.2%) |
| 命名实体识别(NER) | 实体边界和类型识别更精准 |
| 机器翻译 | 作为编码器提升低资源语言翻译质量 |
局限性与后续改进
尽管BERT解决了上述问题,但仍存在一些不足,后续研究在此基础上优化:
- 计算资源需求高 → 模型压缩技术(如DistilBERT)。
- NSP任务效果有限 → RoBERTa移除NSP,仅用MLM。
- 长文本处理弱 → Transformer-XH、Longformer改进位置编码。
总结
BERT的核心贡献是通过双向Transformer和自监督预训练,统一了NLP任务的表示学习框架,解决了语义理解、迁移学习和架构碎片化等关键问题,成为现代NLP的基础技术。