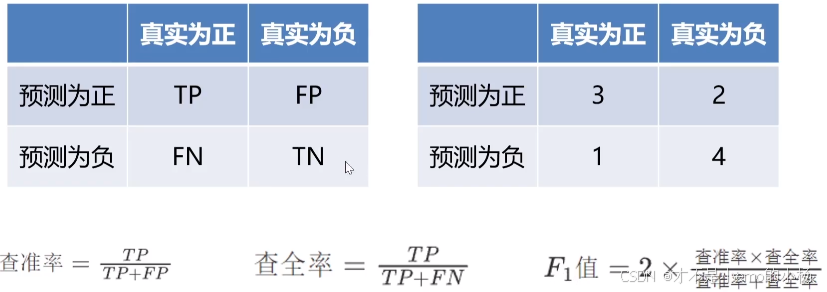
一、安装步骤
1.基础环境安装
安装显卡驱动、cuda,根据自己硬件情况查找相应编号,本篇不介绍这部分内容,只给出参考指令,详情请读者自行查阅互联网其它参考资料。
sudo apt install nvidia-utils-565-server
sudo apt install nvidia-cuda-toolkit
因机器上有其它使用python环境的应用,故使用conda来管理python环境。
(1)安装conda管理器
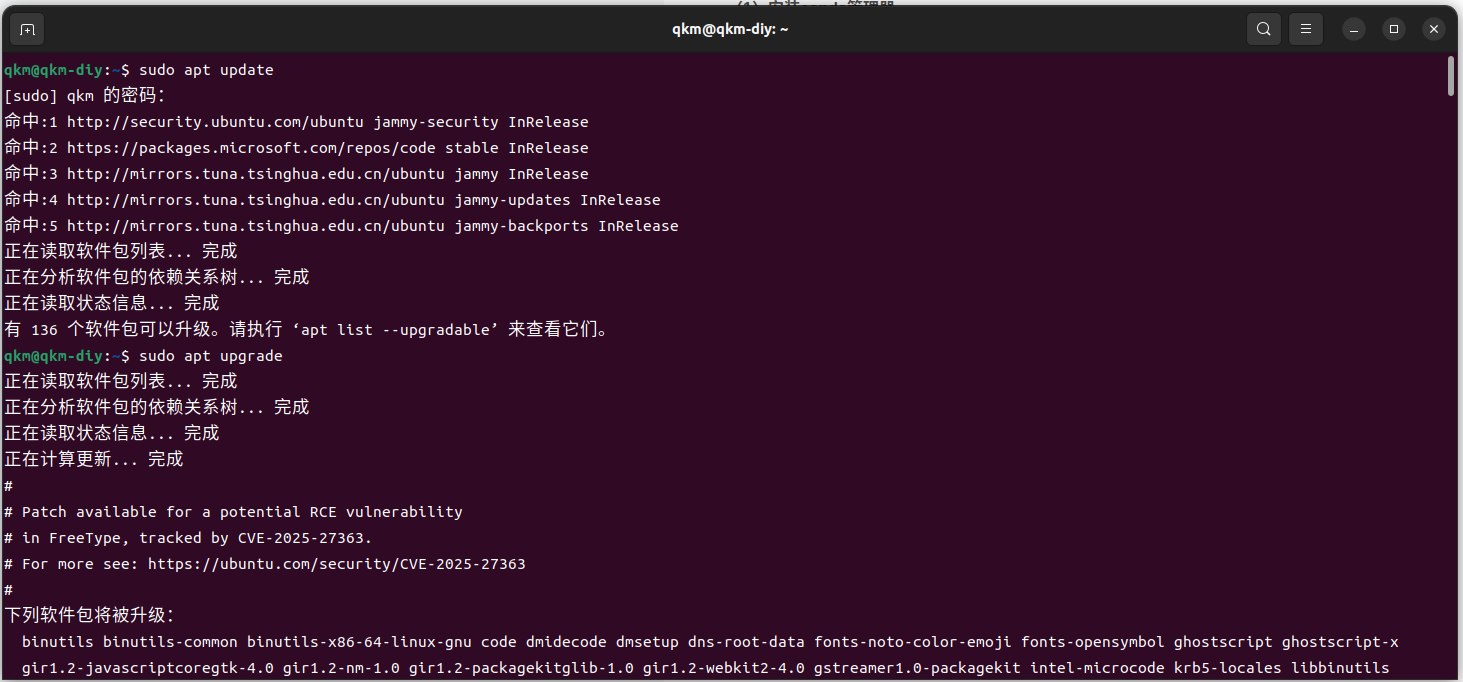
更新软件包
sudo apt update
sudo apt upgrade
安装基本依赖
sudo apt install wget curl bzip2 ca-certificates
下载Anaconda安装脚本
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
运行安装脚本,按提示一路执行下去,中间需要输入yes并确认
bash Anaconda3-2023.03-1-Linux-x86_64.sh
初始化Anaconda,执行下面指令,或者关闭命令窗口后重新开启一个窗口。
source ~/.bashrc
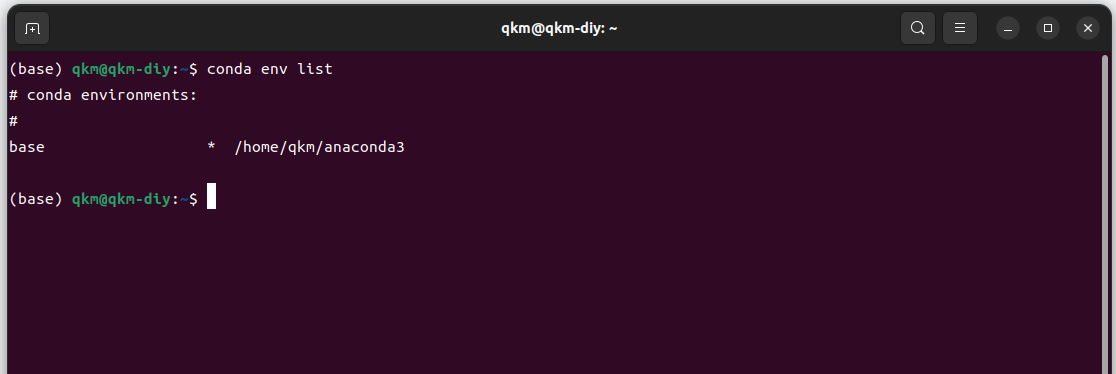
验证安装结果
conda env list
(2)创建xinference所需的虚拟环境并激活它
conda create -n Xinference python=3.10.15
conda activate Xinference
(3)安装chatglm-cpp
https://github.com/li-plus/chatglm.cpp/releases
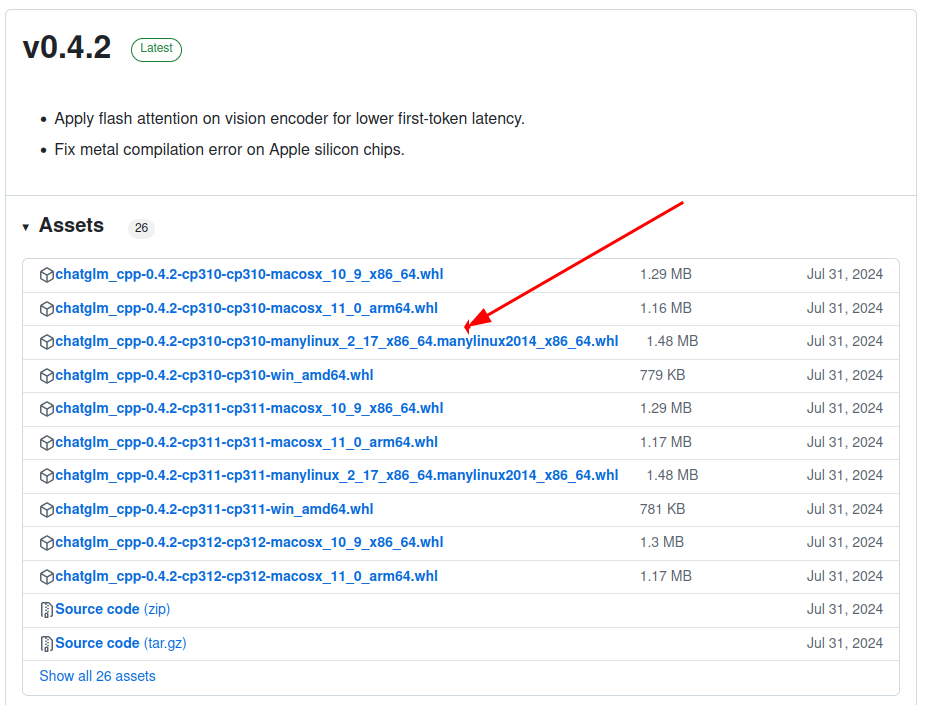
切换到刚下载的文件所在目录,运行指令:
pip install chatglm_cpp-0.4.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
2.安装Xinfernece
pip install xinference[all]

xinference有好几种支持的种类,如gpu/cpu/transformers/vllm/metal,用all参数代表全部安装,这样以后不管接入哪种类型的大模型都不需要再次安装了。
3.检验环境是否安装成功
检验pytorch是否支持gpu,运行python指令
import torch
print(torch.__version__)
print(torch.cuda.is_available())

如果报错,运行下面指令安装支持gpu的依赖包。(根据自己显卡配置确定cuda版本号,ubuntu系统正常在安装xinference过程中已经安装了以下依赖包)
pip install torch==2.6.0+cu128 torchvision==0.21.0+cu128 torchaudio==2.6.0+cu128 --index-url https://download.pytorch.org/whl/cu128
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu128
安装后验证是否成功:

二、启动Xinference
xinference-local --host 0.0.0.0 --port 9999
windows下只能使用127.0.0.1或者局域网中的本机ip地址,linux可以使用0.0.0.0包含127.0.0.1和局域网中的本机ip地址,这样就可以在企业内共享了,同时也能使用127.0.0.1访问。

运行成功后界面如下
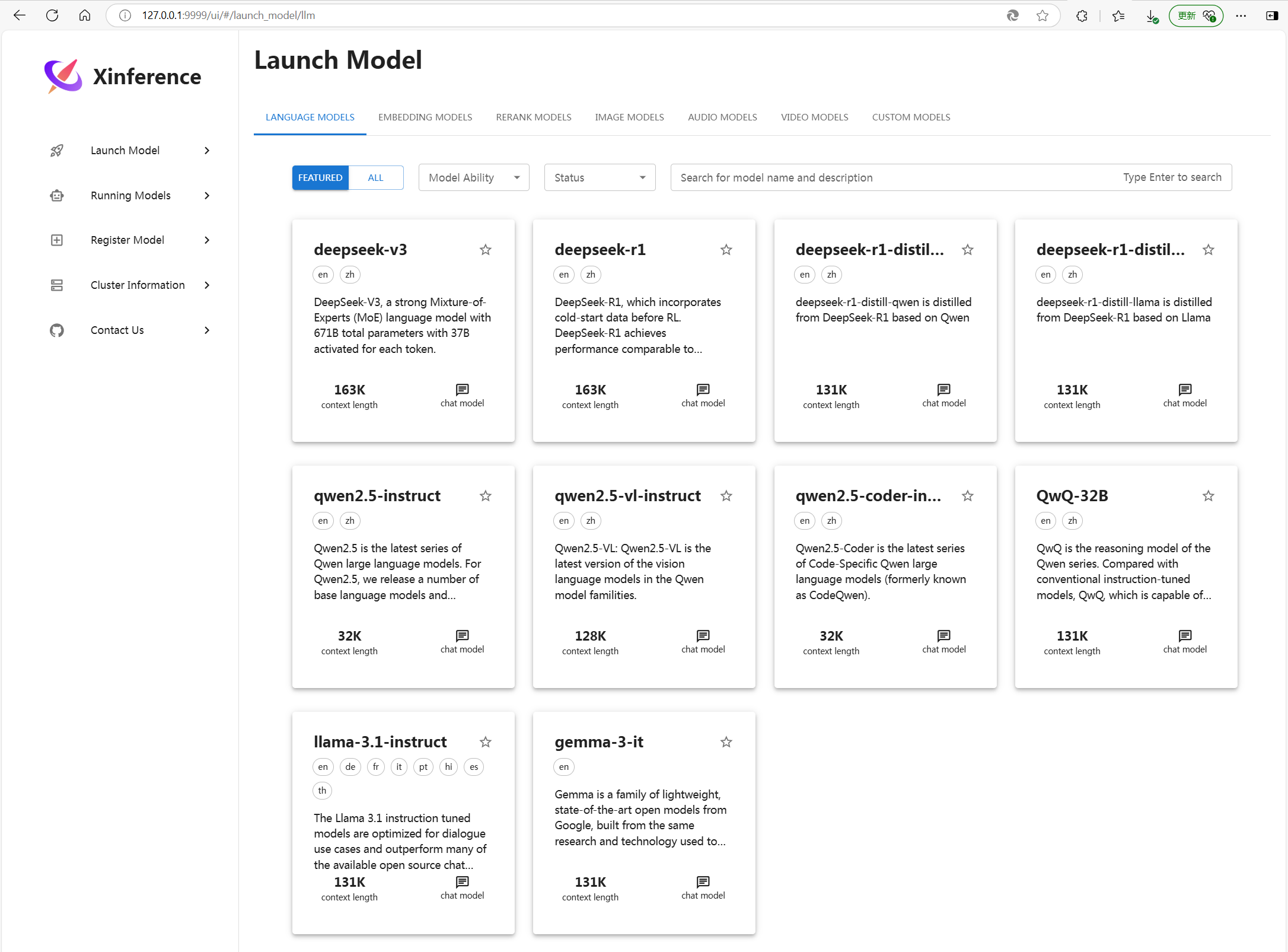
三、配置注册模型文件
1.下载模型文件
到https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
如果不能科学上网,打不开上面网址,也可以到国内阿里的开源网站下载:
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/files
红色框内的文件全部下载,保存到同一个目录中,根据硬件配置选择不同的模型文件,这里我是演示,所以选择1.5B,一般企业内做知识库,建议至少选择32B,显存32GB以上,我试过32GB跑32B的模型很吃力,响应很慢。

2.注册模型文件
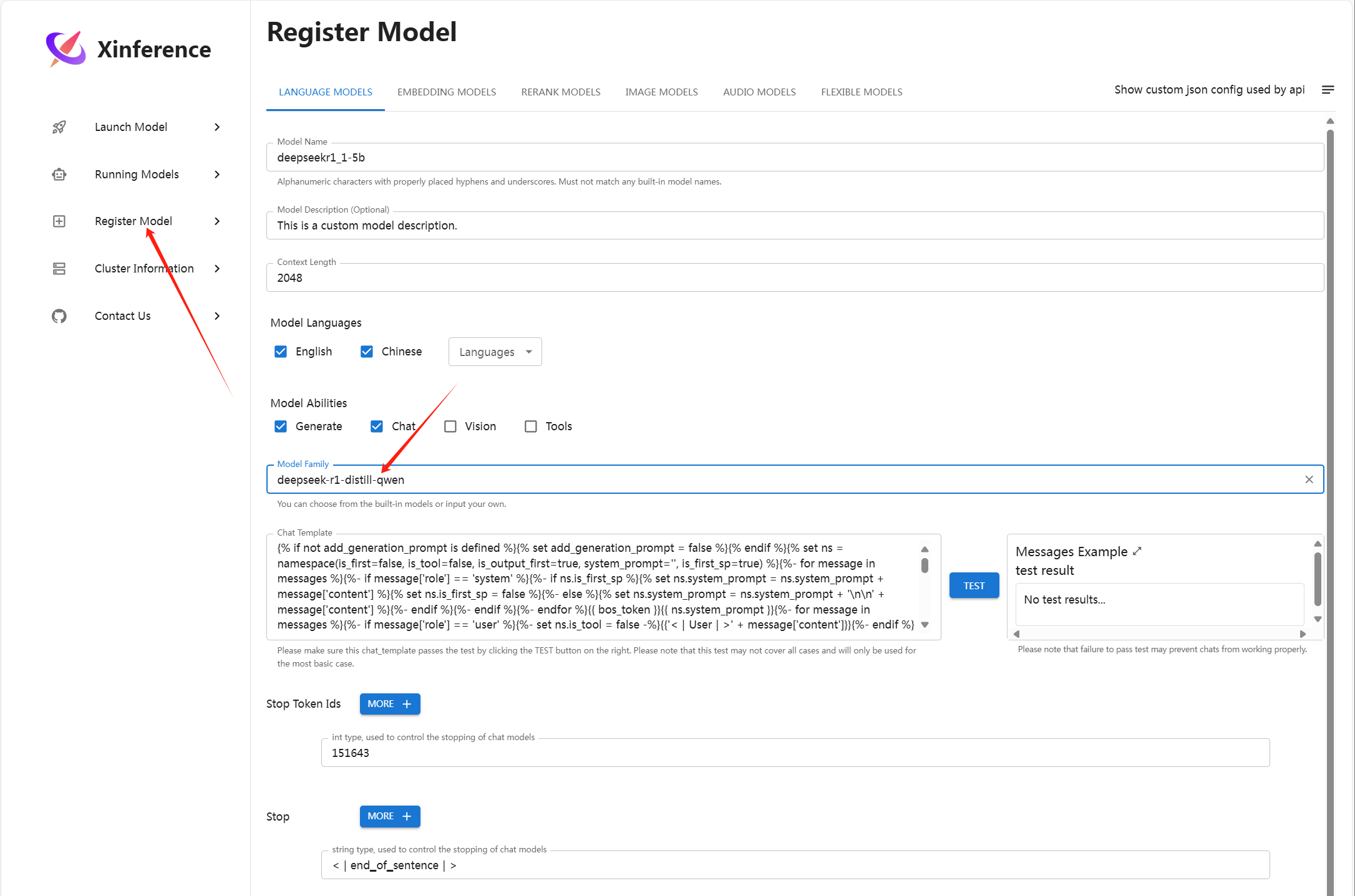
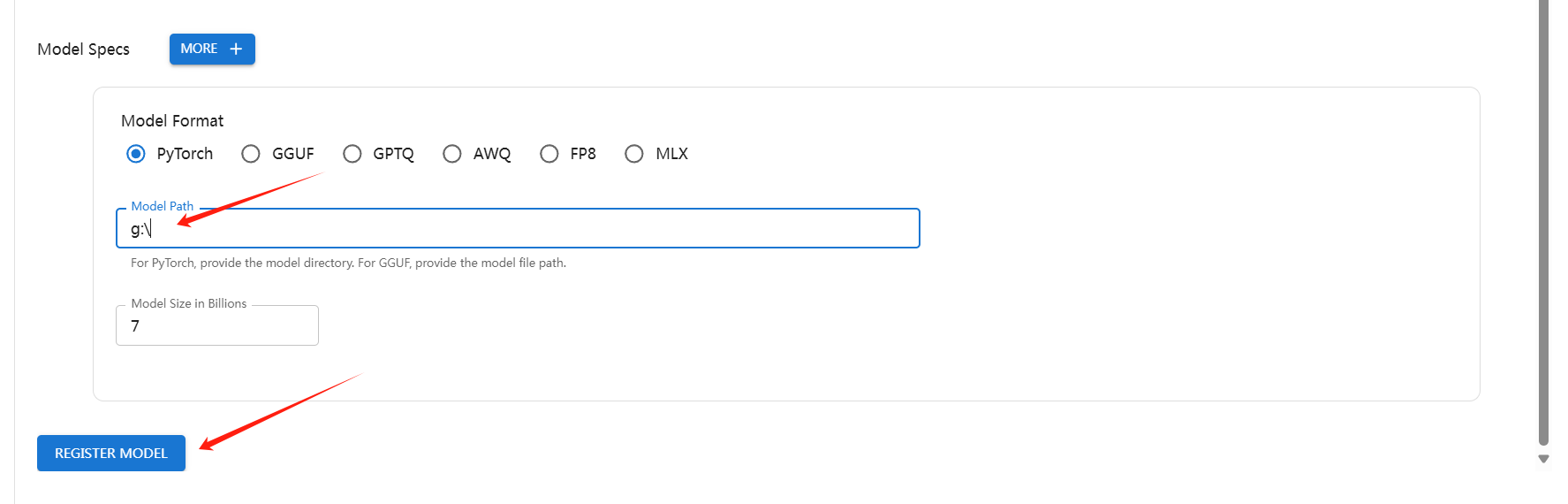
上图中的路径要换成linux的目录格式,如/home/qkm/deepseekR1/1-5B,因为截图忘保存了,用windows模式下的截图替换了一下。
3.启动模型文件
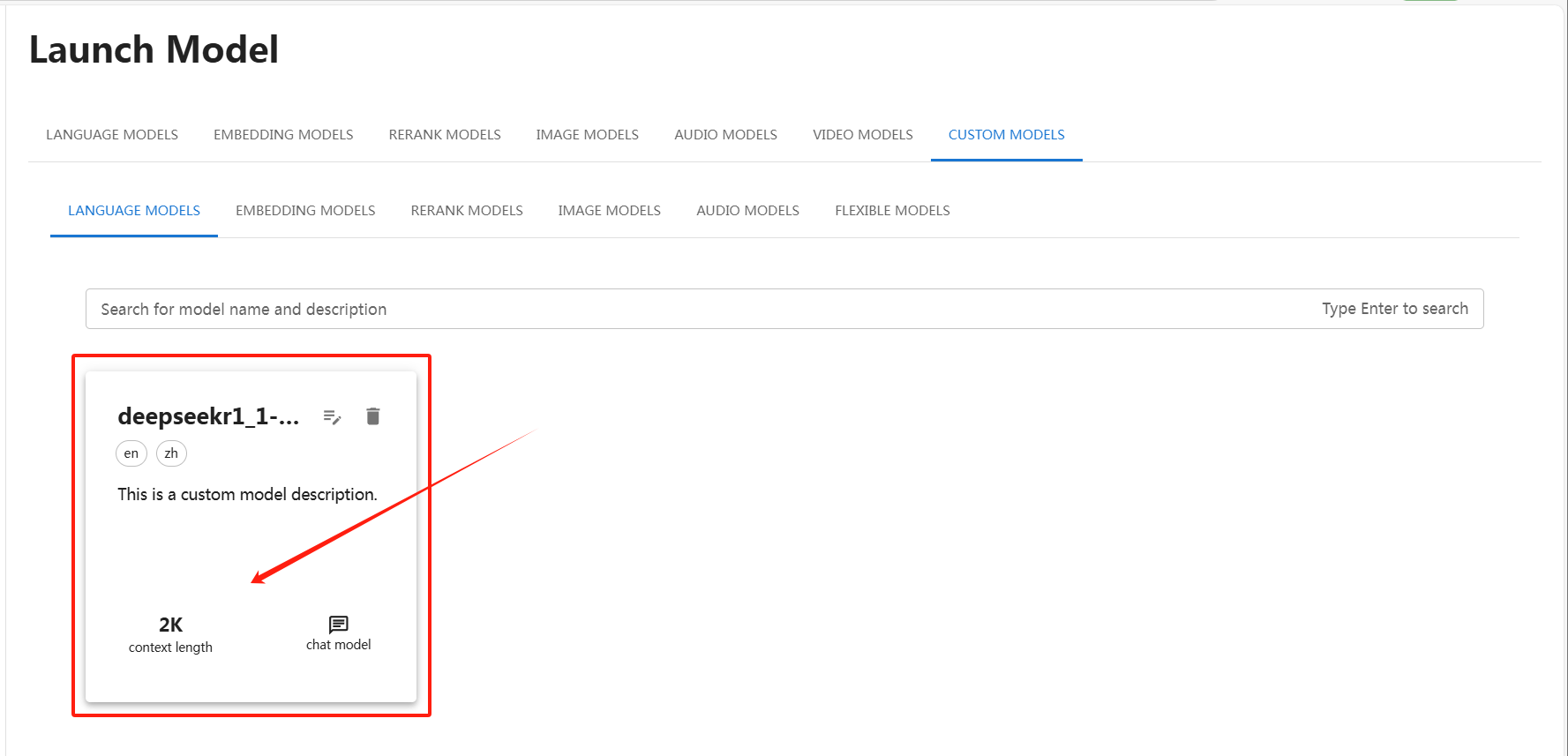
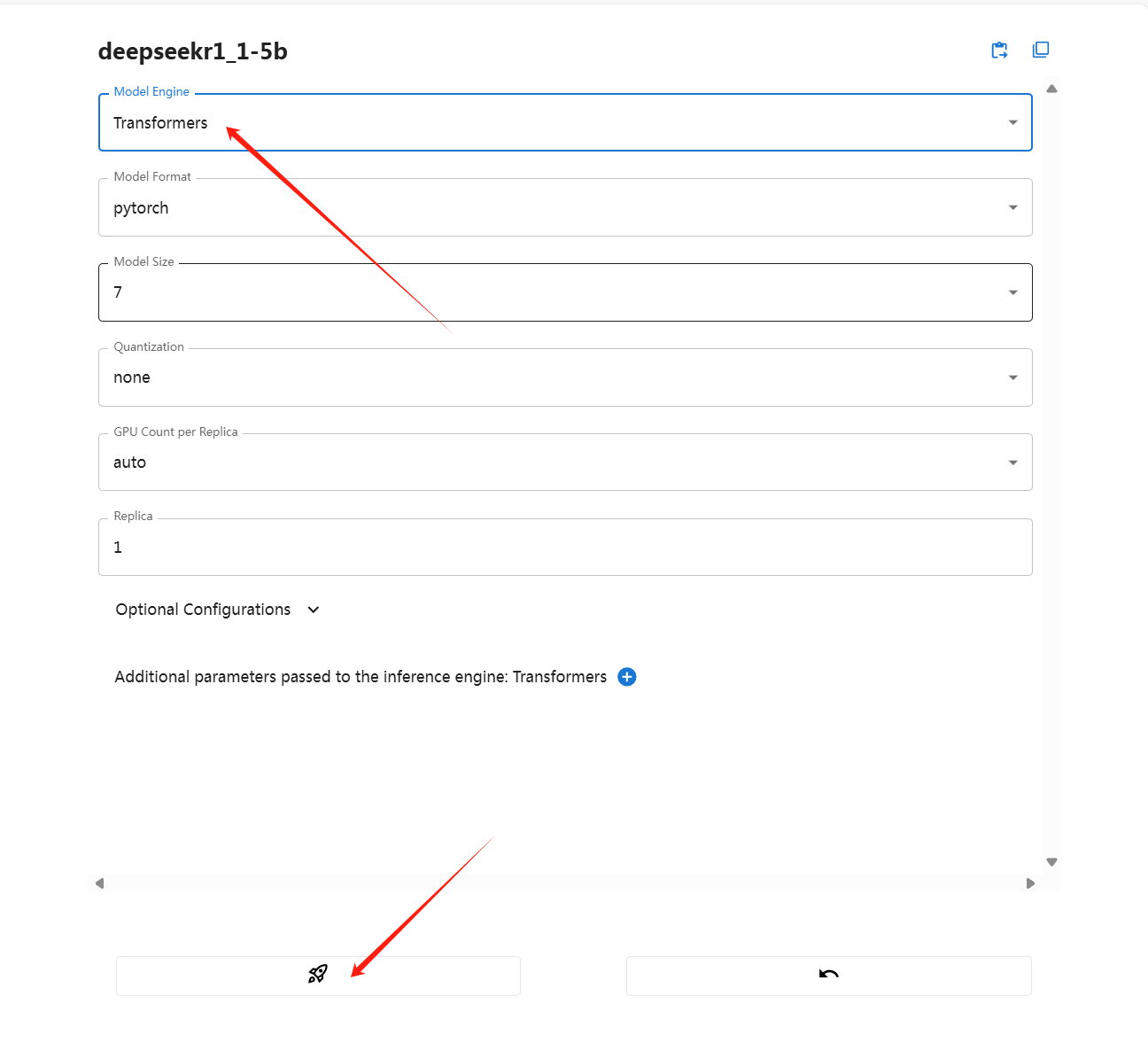
四、体验与模型对话
点击下图箭头处,可以启动与大模型的聊天
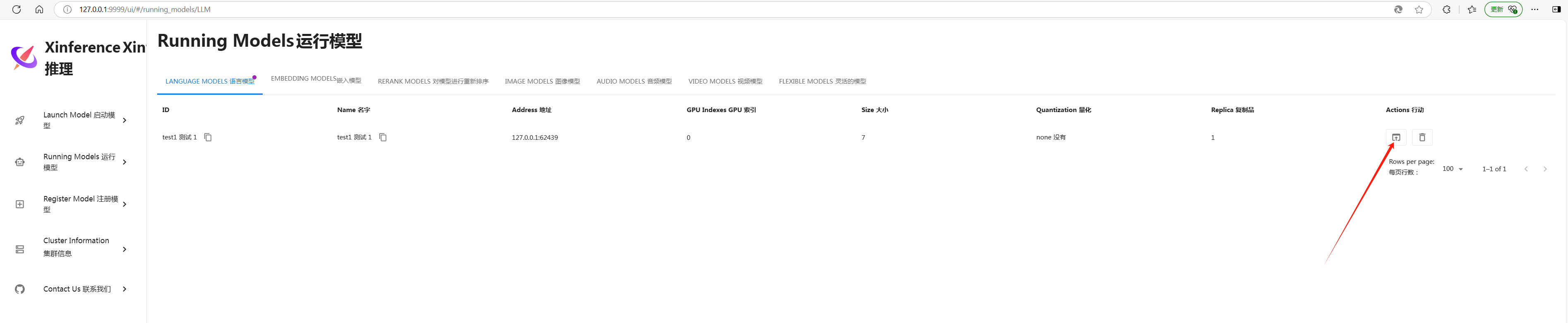
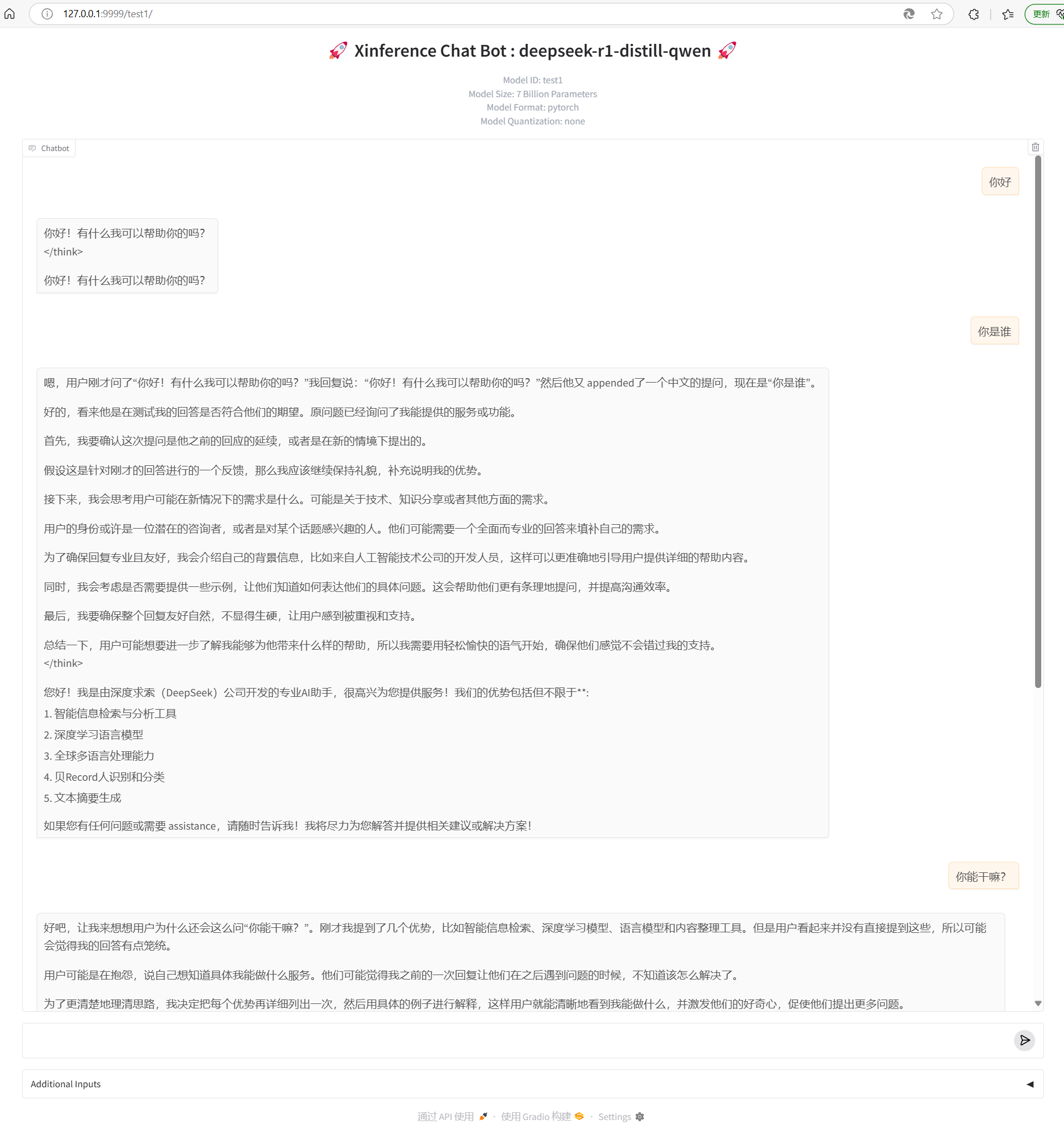
使用conda创建的虚拟环境和安装的依赖包,往同类操作系统复制时,只要直接拷贝过去即可,基本可以与docker的跨系统部署相媲美了。