摘要
传统的计算机断层扫描(CT)通过使用不同角度的X射线投影计算逆氡变换来生成体积图像,这导致高剂量辐射、长重建时间和伪影。生物学上,可以利用先前的知识或经验在一定程度上从2D图像中识别体积信息。提出了一种深度学习网络XctNet,以从2D像素中获得该先验知识并生成体积数据。在所提出的框架中,自注意机制用于特征自适应优化;采用多尺度特征融合进一步提高重建精度;提出了一种3D分支生成模块来生成不同生成字段的细节。使用公共数据集与最先进的方法进行了比较,XctNet显示出显著更高的图像质量和更好的精度(XctNet的SSIM和PSNR值分别为0.8681和29.2823)。
1、介绍
基于图像的三维重建是从单个或多个2D图像中推断出3D形状,在计算机视觉领域已经探索了几十年(Han等人,2021),并且已经成为许多领域的基础,例如机器人导航、3D建模和动画、对象识别、场景理解、医疗诊断等。然而,由于缺乏从像素导出深度信息的方法,在没有立体对应的视差知识的情况下,从数字图像中提取体积信息是不直接的。投影射线照相术是一种观察物体或身体内部的常规方法,与普通摄影术没有区别,只是像素对透明的体积结构而不是不透明的表面进行了丰富的观察。具体而言,在X射线照片中,每个像素是二维空间中氡变换后衰减数据的线积分,因此,射线照片的反转不是二维-三维点转换,而是从二维像素到空间线分布的转换。因此,从射线照片进行3D重建是一项更具挑战性的任务。
临床上,3D重建的可用方法数量有限。计算机断层摄影(CT)是一种基于射线照片的3D重建的成熟方法,是获取患者体积信息的常用方法,具有许多变化,如CBCT、PET-CT等。CT本质上是一种反氡变换过程,其中X射线衰减的空间分布函数通过==傅里叶逆变换(IFT)==求解,从而计算来自所有方向的投影视图的角积分。在实践中,来自大量不同角度位置的投影是必要的,以保持可接受的分辨率并减轻断层图像的基于物理的伪影。重建过程本质上决定了CT不可避免的局限性,如高辐射、长重建时间和基于患者运动的伪影。除了CT,新型EOS成像系统为全身双平面X射线扫描和整个骨骼的3D重建提供了更好的选择。新技术对骨科疾病的诊断非常有帮助,如青少年特发性脊柱侧弯(AIS)和成人退行性膝关节炎(Lenke等人,2001;Ovadia,2013)。然而,EOS成像的重建过程基于统计形状模型(SSM),因此所获得的模型不是患者的完全相同的反映,而是语义上相似的虚拟模型。
从生物学上讲,尽管我们的眼-脑视觉系统不能从普通像素进行3D重建,但我们仍然可以从细微的证据中获得部分隐藏的空间信息,如阴影、遮挡、光/阴影、相对大小等。我们在这个基于证据的立体重建过程中使用的知识可以被定义为先验知识,它在基于人类视觉的判断和识别系统中起着至关重要的作用。当我们裸眼观看照片或图像时,通过将像素信息与先验知识相结合,总是可以推断出物体或物体的相对空间关系。同样,放射科医生能够通过应用解剖学和日常实践中的先验知识,从射线照片中分辨出人体的空间信息。因此,从仿生的角度来看,先验知识在理论上至少部分地从射线照片重建3D信息。
深度学习在拟合复杂的非线性数学关系方面显示出优于传统方法的巨大优势,它为医学图像分割、病变区域识别、医学图像配准等众多医学领域带来了发展。
(Feng等人,2020;Schwartz等人,2019;Singh等人,2020)。从2D射线照片进行3D重建的可能性还没有观察到多久,但直到最近几年才出现了逆映射的尝试。
Henzler等人(2018)首先,据我们所知,将深度卷积神经网络(CNN)应用于单次X线断层扫描,并从2D X射线重建3D颅骨体积。Kasten等人(2020)使用端到端CNN从双平面X射线图像中重建膝盖骨。
Shen等人(2019)开发了具有表示、转换和生成模块的深度网络系统,以从单个或多个2D X射线生成体积层析图像。
通过目前的文献研究可以发现,目前基于CNN的重建方法使用端到端的网络结构,这会由于网络采样过程而造成一定的图像分辨率损失;其次,基于X射线图像的CT体积图像重建的任务在计算上相当昂贵。
因此,本文构建了一个轻量级的基于CNN的重建网络XctNet,该网络不仅可以改善采样过程中造成的信息损失,还可以大大减少所需的计算资源。总之,贡献如下:
(1)本文构建了一个轻量级的基于CNN的重建网络XctNet,该网络也可以在大大减少所需计算资源的前提下确保网络的重建精度。
(2)我们尝试将注意力机制和多尺度特征融合模块添加到特征提取过程中,以消除重建图像上的冗余特征,并进一步改善重建过程中的像素损失。
(3)我们提出了一个3D分支生成模块,即New Inception模块,它可以通过使用不同大小的卷积核来更好地生成不同生成域的细节。
2、相关工作
2.1.通过深度学习进行2D–3D重建
在自然图像的3D重建中,已经提出了各种深度学习算法,包括监督学习、无监督学习和半监督学习等(Han等人,2019)。
Wu等人(2015)提出了一种卷积深度信念网络,以将几何3D形状(3D ShapeNet)表示为3D体素网格上二进制变量的概率分布,并构建了ModelNet,以训练3D深度学习模型。
Wu等人(2016)利用体积卷积网络和生成对抗网络(3D-GAN)的最新进展,使用生成对抗网络从概率空间生成3D对象。
Wang等人(2017)引入了一种混合框架,该框架结合了3D编码器-解码器生成对抗网络(3D-ED-GAN)和长期递归卷积网络(LRCN),与其他3D CNN方法相比,其模型适合于GPU内存。
Li等人(2017)介绍了一种用于形状结构的生成递归自动编码器(GRASS),并证明了在没有监督的情况下,他们的网络可以学习有意义的结构层次。
Yan等人(2016)制定了用于从单视图2D图像预测3D模型的编码器-解码器网络。
Choy等人(2016)设计了一个递归网络,以从一系列多视图图像中重建3D模型。
2.2.从X射线重建体积图像
CT重建是一个逆映射数学过程,它从患者周围多个不同角度采集的X射线投影数据生成断层图像(Stierstorfer等人,2004)。重建的质量对所用的辐射剂量有着根本性的影响,研究人员正试图找到更好的重建算法,以确保重建图像的准确性和分辨率,同时最小化辐射剂量(Kak和Slaney,1987;Hsieh,2003)。
提出了一种基于锥束几何的多探测器螺旋CT重建方法(Taguchi和Aradate,1998)。
Hu(1999)研究了多层螺旋CT的扫描和重建原理,特别是4层螺旋CT的扫查和重建原理并得出结论,4层螺旋CT的体积覆盖速度是单层螺旋CT的2-3倍,可以提供相同的图像质量。
Schaller等人(2001)介绍了螺旋CBCT的高质量图像重建方法,
Flohr等人(2003)在16层CT扫描仪中证明了其有效性。
EOS系统起源于诺贝尔奖获得者MWPC(多线比例室)粒子探测器。
Georges Charpak能够使用双平面低剂量X射线扫描生成患者的全身立体图像,被视为目前骨科最先进的图像采集设备(Melhem等人,2016;Song等人,2020)。
Rehm等人(2017)将EOS成像设备与CT成像设备进行了比较,并表明EOS系统可以以较少的剂量获得高质量的图像。
Post等人(2018)提出了一种基于EOS系统的三维脊柱分类方法。
然而,EOS的3D重建依赖于参数模型和收集的双平面X射线扫描的统计推断,因此生成的骨骼模型仅是参数虚拟替代物,在严重骨骼畸形或异常情况下(如先天性脊柱侧弯(CS)和强直性脊柱炎(AS))受到限制。
近年来,深度学习已在医学成像领域被广泛采用。
Meng等人(2020)使用半监督学习从低剂量体积图像重建高剂量体积图像。
Henzler等人(2018)提出了一种深度卷积,以从单个X射线动物头骨图像生成3D图像。它的网络结构采用端到端结构,与之前提出的一些网络结构相比,证明了它们的网络可以获得更好的重建结果。
Shen等人(2019)提出了一种2D到3D网络模型架构,并提出了将2D特征信息转换为空间张量的想法,以执行3D反褶积。然而,沈的重建网络包含大量需要更新的参数,这导致了计算效率低下。在牙科、脊柱、胸部等领域也开展了基于机器学习的3D重建的多项研究(Ying等人,2019;Bayat等人,2020;Cavojsk´a等人,2020)。
上述工作在泛化方面也有局限性,在实践中往往在不同的数据集上表现不佳。本文构建了一个更轻量级的基于CNN的网络,以提高重建精度并降低计算成本。
3.方法
XctNet重建网络的架构如图1所示,包括两个主要部分:X射线特征提取模块、多尺度特征融合模块和体积图像生成。每个模块和损失函数的详细信息将在以下章节中解释。
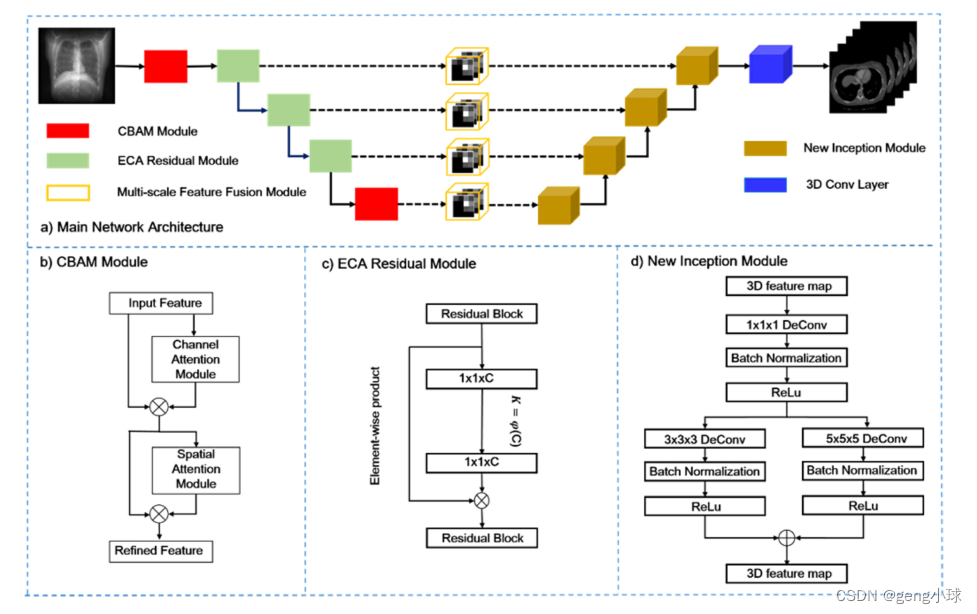
图1.XctNet的体系结构。该模型包括X射线特征提取模块、多尺度特征融合模块和体图像生成模块。
模型的输入是单个2D投影图像。
X射线特征提取模块从输入X射线图像提取特征信息。
多尺度特征提取模块将2D特征转换为3D特征,并与相应的3D生成模块执行特征融合。
体积图像生成模块由一系列新开始模块组成,使用提取的特征数据生成相应的体积图像。
3.1.XctNet重建网络架构
X射线特征提取模块:引入==深度残差网络是为了解决训练过程中网络层过多导致的梯度消失问题。残余网络最具代表性的结构是ResNet(He等人,2016),它通过快捷结构将输入终端直接连接到下一层,从而保护传输数据的完整性。特征提取模块基于ResNet-34构建。输入是单个X射线图像,大小为128×128,模型的第一层由核大小为7×7和步长为2的卷积层组成,第二到第五层由四个残差块组成,其中包含两个3×3卷积层。每个残差块中卷积层的信道数量保持相同,以确保快捷路径和残差路径可以在逐元素加法操作期间保持相同的大小。特征表示输出的大小为4×4。此外,通过实验,我们发现当将编码器/解码器结构用于像素级视觉任务时,卷积层只能使用局部信息来计算目标像素值。因此,缺乏全球信息无疑会导致偏差。卷积层引起的误差可以由等式(1)中所示的像素值之间的协方差来描述。通过卷积层获得的特征图中的每个像素值xi可以用作随机变量,
x
‾
\overline{\text{x}}
x是特征图的平均值。两个变量之间的相似性可以通过计算两个随机变量的协方差来评估。注意机制是利用像素之间的相似度来提高卷积层的性能。
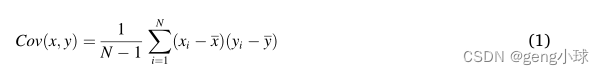
为了减少卷积过程导致的误差,本文引入了两种注意机制,即CBAM(卷积块注意模块)(Woo等人,2018)和ECA(高效信道注意模块)模块(Wang等人,2020),以自适应地提高特征提取能力并减少误差。具体而言,CBAM从空间和信道的2D信息中导出关注图,然后,将关注图与输入特征相乘,以自适应地优化特征值。模块结构如图1(b)所示。在2D特征提取模块中,CBAM主要用于第一层和最后一层的卷积特征提取,以在确保整体网络结构不受影响的前提下提高特征自适应提取的能力。对于中间卷积层,使用ECA模块来提高其特征提取性能。作为不降低特征维度的本地跨信道交互模块,ECA模块通过组合每个信道及其相邻的k个信道来获得本地跨信道的交互信息。ECA模块可以通过尺寸为k的一维卷积层实现。值得注意的是,ECA作为一个轻量级模块,并没有添加大量的附加参数。网络结构图如图1(c)所示。本文将残差模块和ECA模块相结合,提高了中间层的特征提取能力。残差模块获得的特征图将被输入ECA模块以进行自适应优化。此外,残差模块获得的特征图还将通过逐元素乘积与自适应优化的特征图相结合,从而获得细化的特征图。
多尺度特征融合模块:基于CNN的重建网络结构通过下采样逐层提取2D特征,然后通过上采样操作重建3D信息。在下采样过程中,浅层网络具有较强的语义信息表示能力,但缺乏空间几何细节;深度网络具有较强的几何细节信息表示能力,但缺乏语义表示能力。传统的编码器/解码器结构在下采样过程之后将特征直接输入到解码器用于上采样。对于体图像重建任务,体图像通常具有大量的细节信息。而基于传统编码器/解码器结构生成的图像将缺少大量细节信息。为了解决体积图像的细节丢失问题,提高网络生成图像的细粒度特征,提出了一种多尺度特征融合方法。
多尺度卷积的过程主要包括两个因素:特征传播和跨尺度通信(Feng等人,2020)。在本文提出的多尺度特征提取结构中,将输入特征划分为高尺度特征Xhigh和低尺度特征Xlow,以分别获得相应的高尺度特征输出Yhigh和小尺度特征输出Ylow。多尺度特征变换过程如下:

等式(2)可以被封装为对输入特征图执行的聚集变换。其中I表示信息映射,ω表示相同尺度的变换。换言之,高尺度特征将通过跳层连接与相应的生成模块连接,而低尺度特征则通过一系列卷积层进行下采样。
总体网络结构如图1(a)所示。从原始网络结构中提取不同层次的特征图,并通过变换模块将其转换为相应的三维特征图,然后将多尺度三维特征图与相应的3D特征生成层相结合,以提高生成结果的精细粒度,减少重建过程中的信息损失。详细来说,要将2D投影数据转换为体积图像数据,需要进行数据转换。添加变换模块以桥接2D特征提取模块和3D生成模块。将尺寸为(C,H,W)的多尺度2D特征通过维度转换函数转换为(C、1、H、W),然后通过核尺寸为D×1x1,还包括ReLU激活函数和批归一化函数,以更好地学习变换过程中的变换关系。
体积图像生成模块:受GoogleNet的Inception结构(Szegedy等人,2015)的启发,它可以解决过度拟合和梯度消失问题,将Inception(新Inception)结构的3D反褶积形式添加到3D生成网络中,它由核大小为1×1×1的3D逐点卷积和核大小为3×3×3以及5×5×5的两个3D反褶积组成。如图所示。1(d),反褶积模块的三维逐点卷积层可以在相同大小的生成场中叠加更多的反褶积,从而可以在生成的图像中获得更多细节。此外,三维逐点卷积在降维中也起着基础作用。执行3D反褶积操作将产生大量计算。通过添加3D逐点卷积可以有效地减少输入特征的数量,从而提高计算效率。New Inception结构由两个分支组成,每个分支使用不同大小的滤波器进行反褶积。分支可以生成不同规模的信息,并生成更丰富的结果。New Inception结构使用将稀疏矩阵分解为密集矩阵的原理进行计算。特征维度被分解为多个密集分布的子特征集。高度相关的特征聚集在一起,不相关的特征将被削弱。最后,它们将在特征维度中拼接在一起,并与输入维度一致。这种方法降低了计算成本,并确保最终训练结果不会受到影响。
3.2. 数据预处理
原始数据需要在输入网络模型进行训练之前进行预处理。首先,所有输入数据都需要调整到相同的大小。用于训练的2D图像和相应的3D CT图像分别调整为128×128和128×128×128。在实践中,2D–3D数据对应该由X射线和CT图像组成,由于缺少相应的成对图像,本文使用数字重建无线电算法(DRR)生成近似的单个2D投影图像,以获得相应的2D–3D图像对。如图2所示,本文使用基于点源视觉的DRR投影算法生成2D投影(Moturu和Chang,2018)。这种方法的优点是可以随机选择点源以获得X射线,这使得数据略有变化。具体地说,在选择光源点并固定投影距离(以CT体积图像的前方为中心)之后,根据比尔定律(Feeman,2010)生成2D投影,其中通过身体的X射线的强度损失测量由比尔定律建模。获得CT图像的信息(间距、大小、方向),并将图像用作DRR算法的输入,然后通过坐标变换对图像进行重新采样。此外,我们将光源到投影平面的距离设置为400mm,投影像素平面的默认像素间距为0.8×0.8,并将阈值设置为− 80,并且使用双线性插值来积分所遍历的每个体素平面,从而获得2D投影图像的前后位置。为了丰富训练数据的样本量,在训练之前进行数据增强,包括尺度变化、旋转变化、镜像和平移变化、亮度变化、色度变化、对比度变化和锐度变化。此外,逐像素输入数据被归一化为区间[0,1]
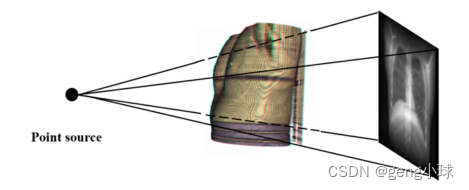
图2.基于点源视觉的DRR投影算法。
3.3.评估指标
为了评估模型的性能,我们在测试集上测试了训练的模型,并使用不同的评估度量来评估预测的重建结果。本文使用四个评估函数进行模型评估,即:MSE(均方误差)、MAE(平均绝对误差)、SSIM(结构相似性)和PSNR(峰值信噪比)。MSE和MAE用于评估预测重建结果与目标值之间的偏差。MSE/MAE值越小,重建结果越接近真实情况。图像评估度量SSIM结合了亮度、对比度和结构的信息,用于评估图像之间的相似度。常用的PSNR被用于评估我们重建的体积图像的质量。通常,具有更好结构和更高分辨率的合成图像将具有更高的SSIM和PSNR值。对所有测试样本的每个度量值进行平均,并将不同方法进行比较,如表2所示。
4.重建实验结果
4.1. Datasets
输入样本由单个2D投影图像X和体积CT图像Y组成。在训练过程中,将单个X射线图像作为输入X∈ RH×W,模型输出为体积图像Ypre∈ RC×H×W,而YGT∈ RC×H×W是ground true,它是模型训练的参考标准。
为了验证模型的有效性,我们使用了公共数据集,即肺图像数据库联盟图像集(LIDC-IDRI)(Armato等人,2011),其中包含1081个CT体积图像病例。原始数据将分别分为训练集、测试集和验证集,在此基础上,通过数据扩充将原始数据扩展到59708例。其中,训练集为35825例,验证集为11941例,测试集为11942例。同时,通过DRR投影生成每种情况的对应输入X。
4.2训练细节
输入X的大小为128×128,地面真相YGT的大小为128×128×128。网络在配备三个NVIDIA Tesla V100图形处理单元的设备上进行训练,训练平台为Pytorch。训练时长为64。作为深度学习训练中的一个重要参数,选择合适的学习速率尤为重要。本文构建了一种自适应学习率调整策略,该策略可以根据训练过程中的具体情况修改学习率,以确保训练的最佳效果。如等式(3)所示,所有三个训练网络中使用的损失函数均为MSE。训练结果如图3所示。

此外,为了验证本文提出的多尺度特征模块和注意力机制特征提取模块的有效性,我们构建了三个具有不同结构的网络模型(ResXct、CBAM/ECAXct、XctNet),并再现了Shen等人(2019)提出的网络结构,即ReconNet。具体结构如表1所示:
4.3训练结果分析
我们在LIDC-IDRI数据集上显示了ResXct、CBAM/ECAXct、XctNet以及ReconNet的重建结果。这些异常可以进一步证明XctNet模型的有效性。
如图3所示,随机选择一个测试样本以显示不同模型的生成结果,所选切片的数量为3、15、35、65和85。图3(a)-(d)所示的结果是从测试样本中随机选择的切片图像;图3(e)是相应的地面实况。从重建的总体结果来看,我们的XctNet生成的结果更接近实际情况。在细节方面,原始版本模型生成的切片图像的内容相对模糊;与ReconNet模型相比,中间版本模型的整体轮廓更清晰,一些内部细节(如肋骨区域)可以重建。另一方面,从不同位置的胸部切片数据来看,最佳的重建细节是骨骼区域,而胸部内部器官的重建精度不同程度地模糊。此外,通过随机选择多个测试数据进行分析,可以发现在重建的体积数据中,体积中部的重建性能通常优于体积前部和体积末端的重建性能。造成这种现象的主要原因如下:首先,由于本文是重建整个胸腔,我们不根据不同组织和器官的HU值进行预处理,而是处理整个胸腔的CT数据。因此,重建过程中对于内脏等细节会有一些偏差。其次,由于数据集的来源不同,无法保证胸腔区域的质量完全一致,导致重建CT体积图像的前端和端部体积数据的质量将相对较差。可以看出,这种现象的主要原因是由于数据的复杂性,但这并不意味着我们的模型有局限性。可以看出,与上述不同的模型相比,XctNet在整体轮廓和内部细节方面具有最佳的重建性能。
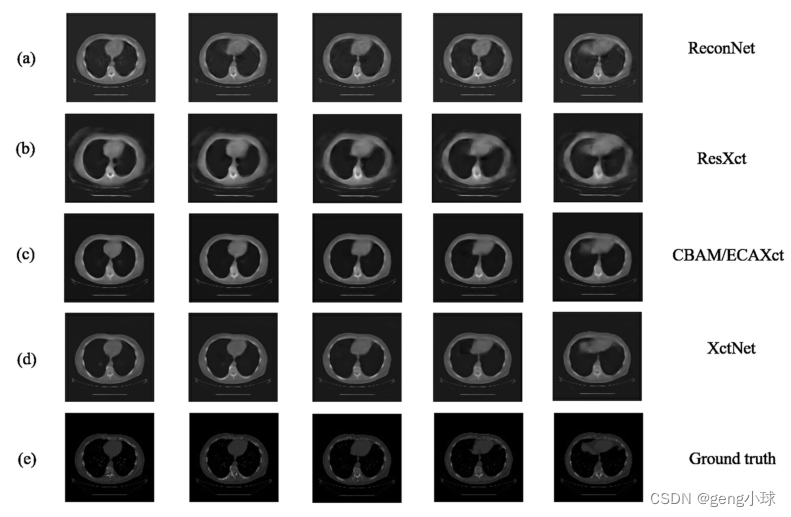
图3.测试集的体积图像示例。(a) –(d)分别表示ReconNet、ResXct、CBAM/ECAXct和XctNet生成的结果;(e) 这是基本事实。图中显示的结果来自随机选择的体积图像中的不同切片图。
为了显示不同模型之间结果差异的细节,如图4所示,灰色值表示差异不大的区域,而白色和黑色值表示差异较大的区域。从图中可以看出,与其他模型相比,XctNet与地面真相的差异最小。
4.4.与最先进技术的比较
为了对XctNet和所提出的对比度网络进行定量分析,使用四个评估度量函数来分析预测的重建图像和地面真实之间的差异。此外,通过比较模型之间的评估度量差异,可以进一步说明注意机制和多尺度融合模块的有效性。
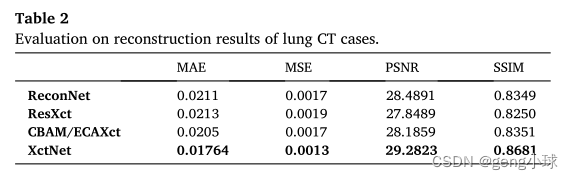
值得注意的是,本文使用的体积数据由128个数据切片组成。值得注意的是,本文使用的体积数据由128个数据切片组成。通过使用不同的评估度量函数分别评估128个切片的体积数据,然后通过取所有切片的平均值来获得最终评估结果。如表2所示,我们的XctNet可以获得最佳的评估结果,其PSNR和SSIM分别达到29.2823和0.8681。顺便提及,表2中的所有评价度量值都是测试样品的平均值。另一方面,ReconNet获得的评估结果比我们的基线模型RexXct表现得更好,这表明增加网络深度对于重建结果是有效的。此外,CBAM/ECAXct的评估结果与ReconNet相似,即添加轻量级注意力机制也是在不增加网络深度的情况下增强模型性能的有效方法。
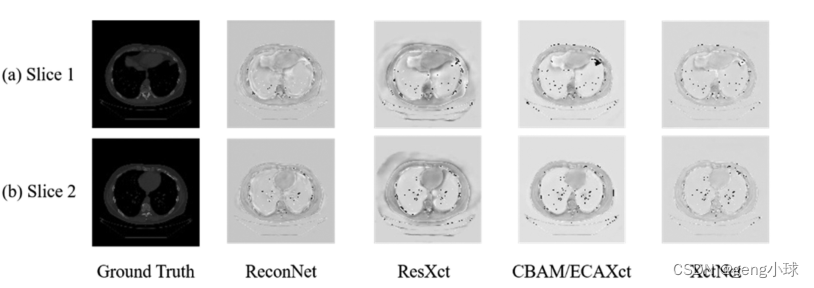
图4:相对于地面真实情况的偏差比较。第一列对应于基本事实。第二列显示了侦察网和地面真相之间的差异。其他列表示相应模型和地面真相之间的差异。
从测试集评估结果的总体分布来看,如图5所示,四个小提琴图代表了不同评估函数的结果。总体而言,XctNet在所有评估指标中都取得了更好的结果。另一方面,如图5(c)所示,所有模型的PSNR值分布大多集中在下四分位数附近,这主要是因为PSNR评估图像之间的灰度差异,并且由于本文中使用的数据集复杂,预测结果通常不同。从比较结果来看,XctNet的四分位间距(IQR)小于其他三个模型,这表明XctNet模型更稳定。通过以上数据分析,我们可以得出结论,自我关注机制和多尺度特征融合模块可以大大提高重建模型的输出精度。
通过总结和分析四组模型的训练结果,我们的XctNet获得的评估指标超过了ReconNet。这一结果证实,在没有额外网络深度的情况下,注意力机制和多尺度特征融合模块也可以提高模型的准确性。
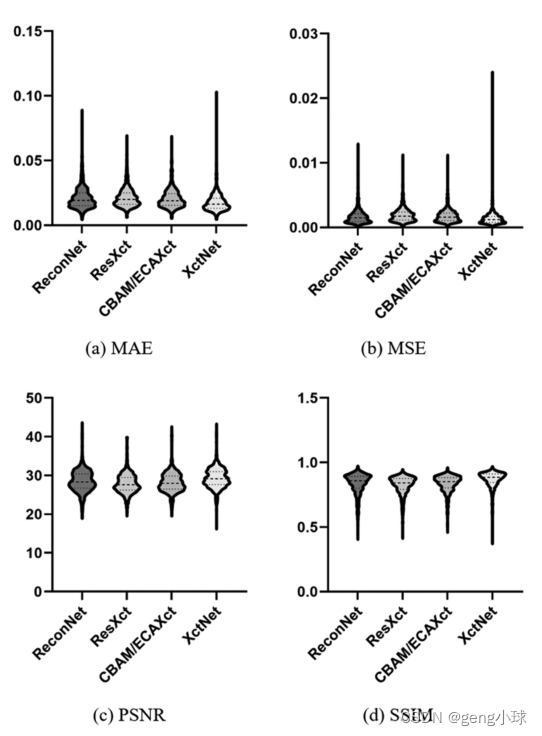
图5:不同模型的评估结果分布。(a) –(d)分别表示MAE、MSE、PSNR和SSIM的评估结果在LIDC-IDRI数据集上的分布。可以看出,(a)–(c)接近下四分位数和(d)接近上四分位数的结果分布。
5.讨论
通过分析模型的语义表示,进一步说明了XctNet模型的优点。对于基于2D投影图像的重建任务,只有当特征提取模块提取关键和有用的特征信息时,才能正确地重建体积图像。本文构建的三个模型包含512个大小为4×4的特征图。为了更好地可视化,随机选择了16个特征图来说明不同模型之间的特征表示。如图6(a)–(b)所示,可以看出,具有自注意机制的特征提取模块生成的特征图比没有自注意机制时的特征图更简洁。比较(b)–(c)可以看出,CBAM/ECA注意机制可以进一步去除冗余特征。另一方面,从生成的体积图像的角度来看,由具有自关注机制的模型生成的图像质量明显更好。换句话说,没有自我注意机制的特征提取模块学习了大量冗余信息,这导致了模糊生成结果的现象。因此,可以得出结论,自我注意机制可以帮助模型更好地学习特征信息。
为了进一步验证XctNet模型的性能,比较了当前最先进的CNN模型。如表3所示,ReconNet模型具有最高的模型复杂度,其FLOT(浮点运算)达到1.304×1012。ResXct作为我们的基线模型,其复杂度低于ReconNet,错误率几乎相同。我们的XctNet大大提高了它的错误率,只增加了一点点复杂性。这种现象表现出以下两个方面。首先,轻量级注意力机制可以在不增加模型复杂性的情况下提高模型的性能。其次,本文提出的新Inception模块可以大大减少模型计算量,并生成内容更丰富的体积图像。
根据信息熵的定义,它代表了平均意义上信息源的总体特征。对于图像信息,我们可以根据图像熵来描述图像中包含的信息量。如等式(4)所示,x表示图像中的每个像素,图像熵反映图像的平均信息,并且针对特定图像信息获得的图像熵是唯一的。因此,可以从图像熵的角度来评估体积图像的生成质量
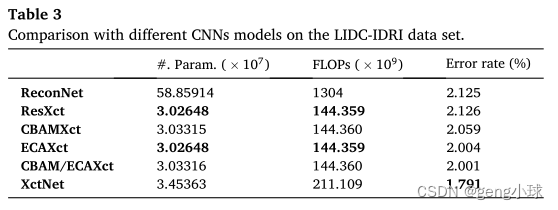

如图7所示,随机选择了两个测试样本来说明来自不同模型的图像熵的分布,这显示了不同模型的地面真相和熵图。可以看出,熵图趋于冷的区域指示它包含较少的信息,而熵图趋于热的区域指示其包含较多的信息。通过将三个模型的结果与地面真相进行比较,我们可以发现XctNet可以通过添加自我关注机制和多尺度融合模块来获得更倾向于地面真相的分布图。通过将ReconNet和ResXct与其他两个模型进行比较,进一步表明传统的端到端网络会在卷积过程中带来偏差,并验证了本文提出的改进方法的有效性。
为了验证该模型在临床X射线图像上的性能,我们通过深圳大学总医院的脊柱手术获得了10张原始X射线胸部图像。如图8所示,显示了两组临床X射线图像的重建结果。可以看出,重建结果的精度比本文中使用的2D投影的精度差。这种现象的主要原因是临床X射线图像和2D投影之间存在一些差异。因此,在未来的工作中,需要从临床X射线进行更深入的研究。然而,从本文提出的ReconNet和XctNet的生成结果来看,XctNet在临床X射线数据中表现更好,这也证实了我们构建的网络具有相当大的优势。
6.结论
在本文中,我们关注的是体积图像的重建质量。为了获得更精确的重建结果,构建了一个轻量级的重建网络XctNet。网络结构有以下三个创新:
首先,在原有的残差特征提取模块中加入自关注机制,去除冗余特征;其次,本文提出了一种多尺度特征融合模块,以提高重建图像的质量和其他细节。最后,构造了一个称为新初始模块的特征生成模块,以获得更丰富的特征信息和更准确的重建结果。同时,本文还存在一些问题需要解决。在实际应用场景中,对应的2D投影图像应该是X射线图像,但本文中使用的2D投影是通过DRR算法投影的。为了解决这个问题,可以考虑使用样式转换算法来解决临床X射线和DRR投影之间的差异。总之,XctNet作为一个轻量级框架可以进一步提高体积图像重建的结果。

图6.特征提取和网络结构分析。a) 从没有注意机制的2D特征提取模块学习的特征图;b) 仅使用CBAM注意机制从2D特征提取模块学习的特征图;c) 从具有CBAM/ECA注意机制的2D特征提取模块学习的特征图。
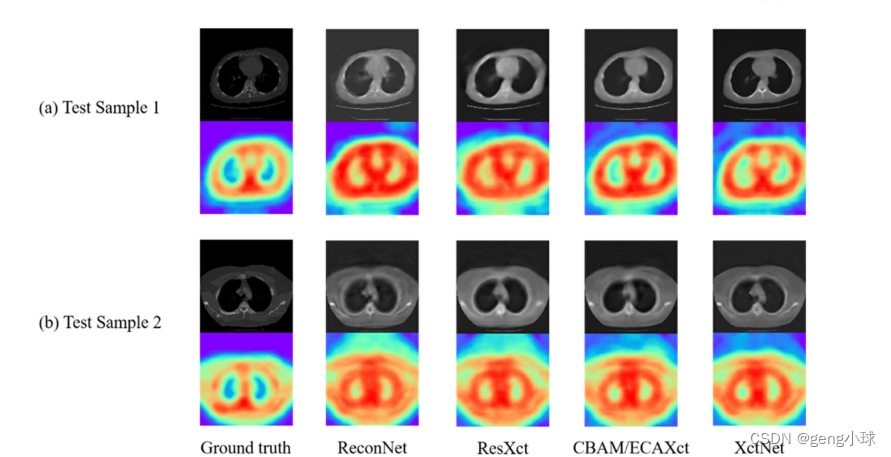
图7.不同网络结构生成的熵图。a–b)表示不同的测试样本及其相应的条目信息。图像熵的变化与图像中包含的内容密切相关。可以看出,图像包含的内容越少,图像信息熵就越低,也就是说,熵图的颜色往往是冷的。
图8.不同病例的临床X线重建结果。a–b)表示从不同X射线图像重建的体积图像。图中显示的切片数为30、60、70和90。


![[附源码]计算机毕业设计springboot现代诗歌交流平台](https://img-blog.csdnimg.cn/dd85a0541e11478a8e0d8fde0a230ba1.png)

![[附源码]Python计算机毕业设计SSM开放式在线课程教学与辅助平台(程序+LW)](https://img-blog.csdnimg.cn/599888a6c0de498789464ba3346d8e04.png)
![[附源码]计算机毕业设计JAVA校园闲置物品租赁系统](https://img-blog.csdnimg.cn/d5c4b408de2d44349ad74550d7c66160.png)



![[附源码]计算机毕业设计-菜篮子系统Springboot程序](https://img-blog.csdnimg.cn/f238c89d8253447cba4f5c4ba60f3c4d.png)