文章目录
- 关键路径的理解
- 关键路径求解的图解与分析
- 关键路径查找的代码实现
- 多支交叉路径的分离输出
- 总结
此文代码均可在Windows与Linux操作系统下的常用编译器上运行,例如:vs、vscode、Dev-C++等等。
关键路径的理解
图的关键路径一般是在求从一个顶点到另一个顶点的最长路径,这个是建立在图的拓扑序列(传送门)之上进行的。所谓的关键路径,就是同时从一个顶点出发,无论其他路径走的怎么样,最后都得等待关键路径走完,才能到达最后的顶点。也就整个图的所有顶点访问完所需要的时间只由关键路径决定,这也是它为什么叫关键路径的原因。
就比如:
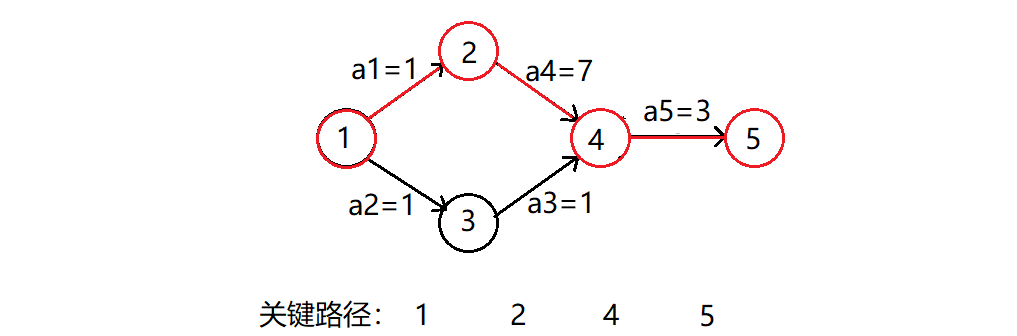
明明走1->3->4->5更快一点,但是要想访问顶点4,得先把顶点2和顶点3访问完(拓扑序列决定的)。因此虽然另一条路很快也很急,但是先别急,急也没用,等着1->2->4进行完了之后才能一起往下走4->5。为了方便理解,我们后面还是将顶点抽象为事件,弧抽象为活动,这样更好理解一点。
关键路径求解的图解与分析
源点:整个图开始的事件
汇点:整个图结束的事件
关键路径:路径耗时最长的路径就是关键路径。
现在要求关键路径怎么求呢?首先我们先要求解事件最早时间与最晚时间,然后再求活动的最早和最晚时间。至于原因嘛,这里我先提几句:关键路径耗时最长,轮不到它等其它路径,意味着它的每项活动与事件都没有空余的时间来耽误,所以最早时间与最晚时间肯定会相同啦。详细解说以及细节的求解过程都在下面:
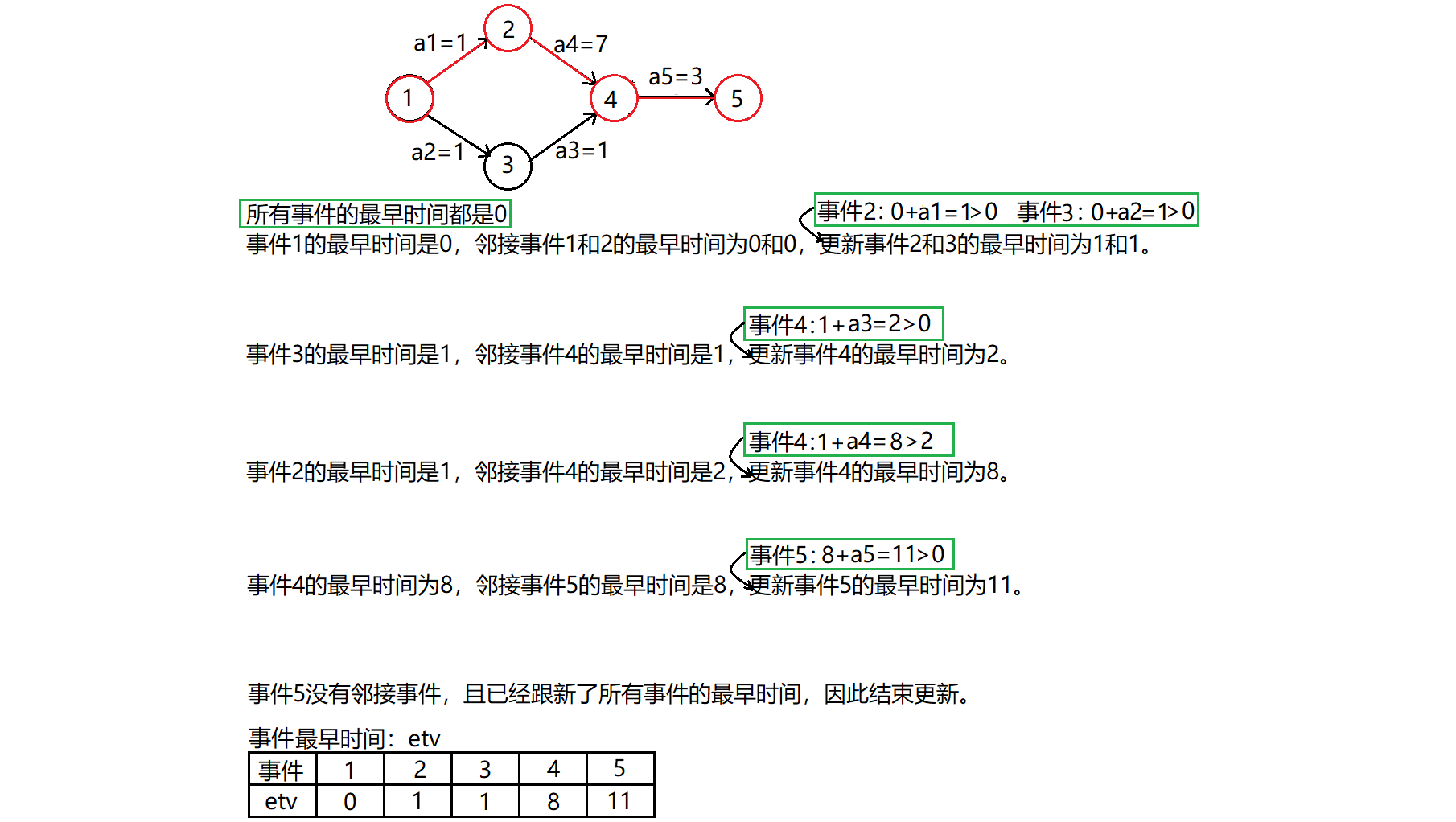
首先,每个事件最早发生的时间初始化为0,意味着现在所有的事件都可能一下子从源点走到各个点(这种极端情况是会存在的,并且源点到源点的时间就是0,因此在初始化的阶段直接处理掉以上情况)。
然后从源点开始计算每个事件的最早时间。
事件最早时间:从源点事件到某个事件V每一步都按规划时间走所需要的最短时间。由于事件V的发生需要之前所有从源点到V的路径上的所有事件都要发生(每条路径的事件都为V事件的发生提供基础,这是拓扑排序的特点的另一体现。拓扑序列就是入度为0的事件才能发生,意味着之前的事件都必须发生它才能发生!)因此,最短的时间反而是源点事件到V事件的所有路径中的所需要的最长时间。(有点类似于集体活动的出发的最早时间不是最早到的人决定的,而是最晚到的人决定的,最晚的人来的早了,集体活动出发的时间就早了。)
这也是从源点事件开始计算最早时间的原因了。
从源点开始,检测V事件的所有邻接点事件的最早时间是否大于V事件的最早时间+活动所需要的时间(权值),如果是的话,就说明临界点事件的最早时间被V事件给推迟了(事件V之前的事件与活动都可能有责任嘞,但是并不用关心责任哥是谁,反正是推迟了,找到是谁也没有意义),因此得更新一下此时该临界点的最早时间。
假如有n个事件,那么就进行n次更新,将第i个事件(1≤i≤n)的邻接点的最早时间都进行一次判断并决定是否更新(更新的顺序走的是拓扑排序的路径,原因还是为了保持入度为0的事件才能发生的条件。)
事件最晚时间:从源点到某个事件V所能拖延的最长时间。为什么这么理解呢?假设最终汇点的事件被完成了,从源点出发有那么多路径,其中肯定有一条路径是花费时间最长的那个,也就是最终这一套事件结束所需要的时间。那么除了这条路径,其他的路径如果是按照规定的时间走的话,肯定要早到,等着那条时间最长的关键路径,这就给其他路径传递了一个信息:你不用每个事件都走那么快,中间浪费拖延一点时间也不影响,但是也不能浪费太多时间,否则的话就会使得其时间超过了关键路径的时间,最终导致整套事件得完成时间变长了。这就是过分拖延影响其他路径了。因此拖延的时间得有个度,那么肯定有个最大极限,使得非关键路径的时间总和变为关键路径的时间总和。这就意味着,在一条非关键路径中,假设有一个事件V,从V到汇点事件都按规划时间走,不拖延时间,然后从源点事件到V事件最多也就能拖延到: 最长时间(关键路径的时间) 减去 V事件到汇点事件的规划时间 。因为V事件后面都按规划时间走了,那么此时计算出来的时间差值不就是V事件被完成的最晚的时间吗?(并不关心源点事件到V事件到底是谁在拖延时间,反正到V事件时已经是最后的时间期限了。)
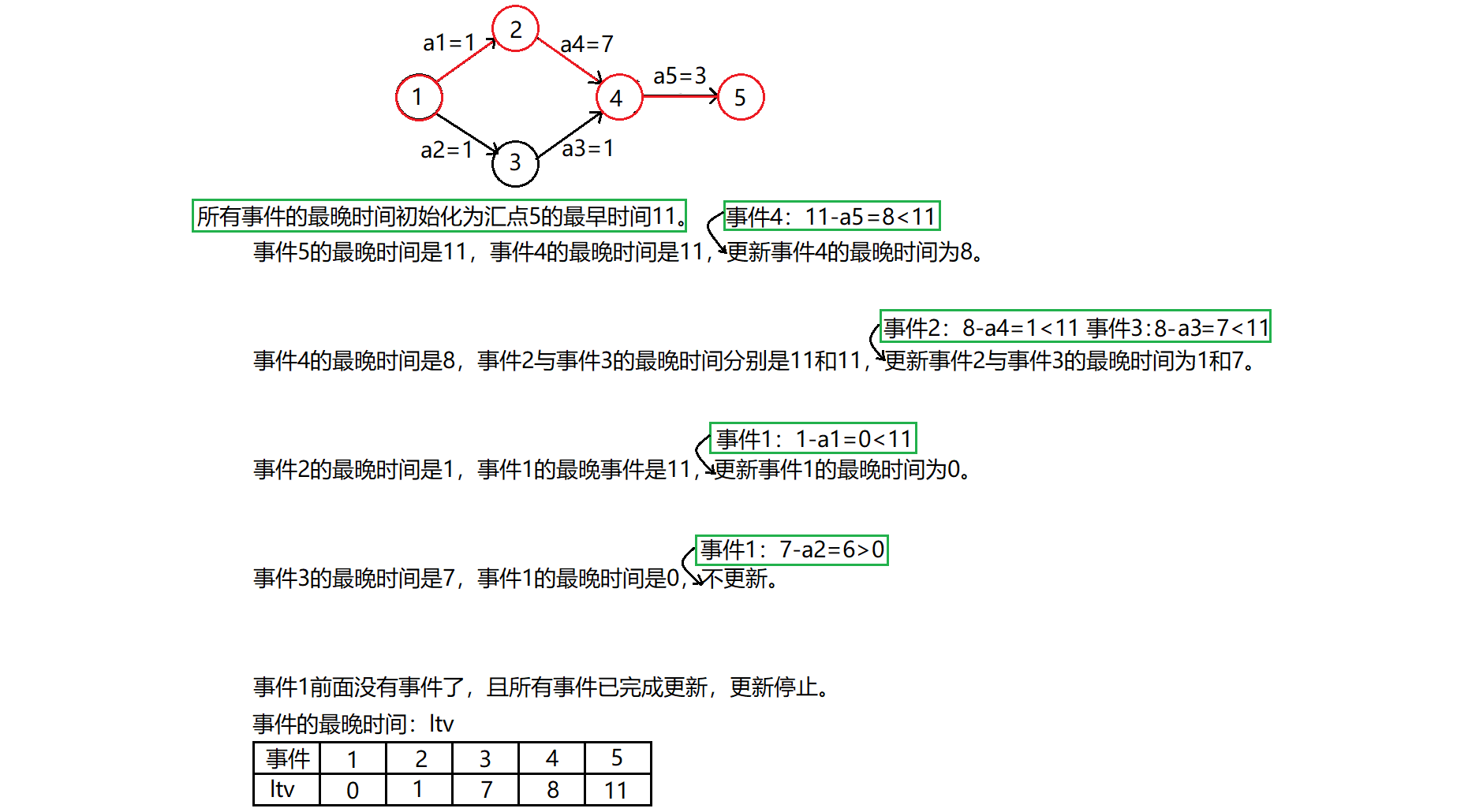
由于关键路径就是每一步都按规划时间走还需要最长时间,也就意味着每个事件的最早时间也是按规划时间走的结果,每个事件的最晚时间也是按规划时间走的结果,那么就意味着最早时间和最晚时间是一样的,此时关键路径的特点不就出来了吗?–>每个事件的最早时间与最晚时间相等。

上面关键事件的顺序只是刚好与路径的一样,假如事件映射的下标稍微变一下就会出现顺序完全紊乱的情况,例如:

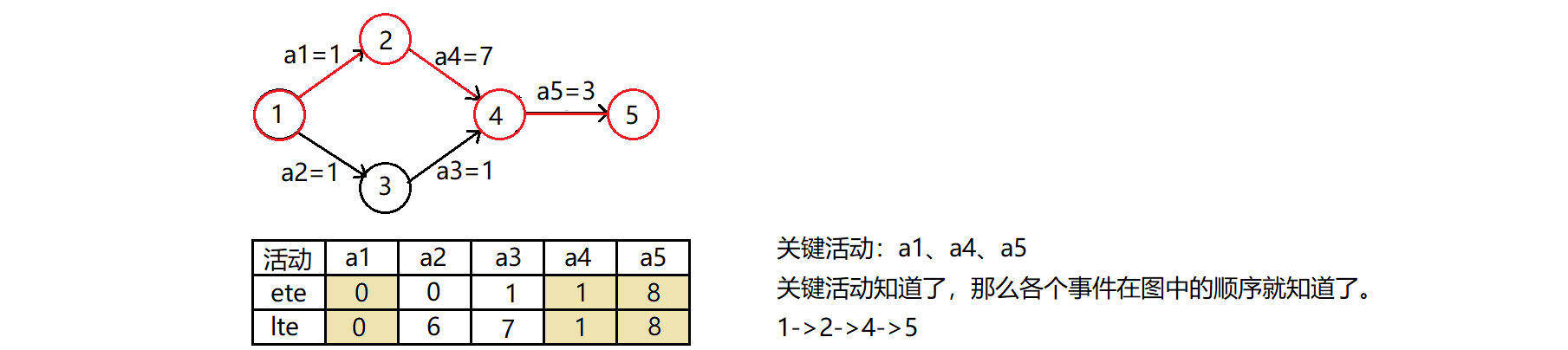
因此,我们要找关键路径,除了要知道各个事件,一般都要知道事件之间的先后顺序,而由事件找它们在图中的顺序是不好找的,由弧找顶点与它们在图中的顺序更方便一点,顺便还能把弧的权值给整出来。所以这里我们就从找关键事件又转换到了找关键活动的求解,不过不用担心,这个过程还是比较容易完成的。
活动的最早开始时间:在事件A与事件B之间,有一个活动<A,B>,活动<A,B>最早的开始时间是由A决定的,只有A事件完成了,活动<A,B>才能开始,因此活动<A,B>的最早开始时间是事件A的最早时间。

活动的最晚开始时间:活动<A,B>的最晚时间不是由事件A来控制的,而是由事件B来控制的,因为活动<A,B>的完成时间就是是事件B的时间,也就意味着事件B的最晚时间要想不超时就得规定活动<A,B>的开始时间,这就是活动<A,B>的最晚时间。

此时再次理解关键路径,就会发现关键路径上的所有活动也都是按照规定的时间走的,那么路径上的每个活动的最早时间与最晚时间肯定相等,这个时候也能通过活动的最早时间与最晚时间来判定关键路径。
关键路径查找的代码实现
实现之前老规矩,还是将图的一些基本结构与功能给附加上。
#include <iostream>
#include <vector>
#include <map>
#include <stack>
#include <string>
#include <cstring>
using namespace std;
template <class W>
struct Edge //边(弧)的结构体
{
size_t _srci; //起始顶点下标
size_t _dsti; //终端顶点下标
W _w; //边的权值
Edge(const size_t srci, const size_t dsti, const W &w)
: _srci(srci), _dsti(dsti), _w(w)
{}
bool operator>(const Edge &e) const //两条边的比较(权值的大小比较)
{
return _w > e._w;
}
};
//V:顶点的数据类型。 W:权值类型。 权值的最大值默认为INT32_MAX,即∞ 默认为无向图
template <class V, class W, W MAX_W = INT32_MAX, bool Direction = false>
class Graph//图的类框架
{
public:
typedef Graph<V, W, MAX_W, Direction> Self;
typedef struct Edge<W> Edge;
Graph() = default;//默认构造
//初始化图
Graph(const V *vertexs, int n)//顶点数组与个数传参
{
_vertexs.reserve(n);//初始化顶点数组与下标集
for (int i = 0; i < n; ++i)
{
_vertexs.push_back(vertexs[i]);
_indexMap[vertexs[i]] = i;
}
_matrix.resize(n);
for (int i = 0; i < n; ++i)
{
_matrix[i].resize(n, MAX_W);//初始化邻接矩阵,每个元素默认赋值为∞
_matrix[i][i]=W();//对角线上的权值为0
}
}
size_t GetVertexIndex(const V& x)//获得顶点在顶点数组中的下标
{
auto it = _indexMap.find(x);
if (it != _indexMap.end())//找到的话返回下标
{
return it->second;
}
else
{
throw invalid_argument("顶点不存在");//找不到的话就抛异常
return -1;
}
}
//添加关系(边)
void _AddEdge(const size_t srci, const size_t dsti, const W& wight)
{
_matrix[srci][dsti] = wight;//两个顶点之间的权值进行赋值
if (Direction == false) //是无向图的话就在矩阵的对应位置也对边的权值进行赋值
{
_matrix[dsti][srci] = wight;
}
}
// 参数: 起始顶点 终端顶点 权值
void AddEdge(const V& src, const V& dst, const W& wight)
{
int srci = GetVertexIndex(src);//拿到起始顶点映射的下标
int dsti = GetVertexIndex(dst);//拿到终端顶点映射的下标
_AddEdge(srci, dsti, wight); //嵌套一下用下标的方式添加边,方便在之后处理矩阵的特定情境通过下标加边。
}
//找所有顶点的入度
void FindInDegree(vector<int> &indegree) // indegree存的是所有顶点的入度
{
size_t n = _vertexs.size(); // n为顶点的个数
indegree.resize(n, 0); //入度初始化为0
for (size_t i = 0; i < n; ++i) //对n个顶点进行各自的入度累计
{
for (size_t j = 0; j < n; ++j)
{
if (_matrix[i][j] != MAX_W && _matrix[i][j] != W()) //有顶点i指向顶点j,顶点j的入度就自加1。
{
indegree[j]++;
}
}
}
}
//拓扑排序 输出型参数 拓扑序列放在topo中
void TopologicalSort(vector<int> &topo)
{
size_t n = _vertexs.size(); // n为顶点的个数
topo.resize(n, 0); //给topo开辟n个空间
int index = 0; //拓扑序列的实时下标,初始为0
stack<int> st; //存放入度为零的顶点
vector<int> indegree; //所有顶点的初始入度
vector<bool> visited(n, false); //标记映射的顶点是否被访问过
FindInDegree(indegree); //查找所有顶点的入度
for (size_t i = 0; i < n; ++i) // n个节点n次循环
{
for (size_t j = 0; j < n; ++j) //找未被访问且入度为零的顶点,将本次循环所有入度为0的顶点入栈
{
if (visited[j] == false && indegree[j] == 0)
{
st.push(j);
visited[j] = true; //只要进栈,就意味着一定会被访问,直接先标记为已访问,避免重复检查
}
}
int v = st.top(); //取栈顶的入度为0的顶点
topo[index] = v; //将该顶点存在拓扑序列中
st.pop(); //将该顶点出栈
for (size_t j = 0; j < n; ++j) //已访问的顶点的所有未被访问的
{
if (visited[j] == false && _matrix[v][j] != MAX_W && _matrix[v][j] != W())
{
indegree[j]--; //更新已访问的顶点的邻接点的入度
}
}
index++; //更新拓扑序列的实时下标
}
}
private:
vector<V> _vertexs; //顶点
map<V, int> _indexMap; //顶点对应的下标
vector<vector<W>> _matrix; //矩阵
};
接下来才是真正的关键路径查找:
//关键路径的查找 cPath用来存放关键活动(弧) 返回值是关键路径的权值
W CriticalPathFind(vector<Edge> &cPath)
{
size_t n = _vertexs.size();
vector<int> topo; //存放拓扑序列
TopologicalSort(topo); //拓扑排序
vector<int> etv, ltv; // etv存放每个事件的最早时间,ltv存放每个事件的最晚时间
//事件的最早时间求解
etv.resize(n, 0); //每个事件的最早时间初始化为0
for (size_t k = 0; k < n; ++k)
{
int i = topo[k]; //拓扑序列的第k个数据所指向的顶点i
for (size_t j = 0; j < n; ++j) //遍历顶点i的邻接点j i-->j
{
if (_matrix[i][j] != MAX_W && _matrix[i][j] != W())
{
if (etv[j] < etv[i] + _matrix[i][j]) //事件j的最早时间比(事件i的最早时间 + i->j的活动事件)小
{
etv[j] = etv[i] + _matrix[i][j]; //更新事件j的最早时间
}
}
}
}
//事件的最晚时间求解
ltv.resize(n, etv[topo[n - 1]]); //每个事件的最晚时间初始化为最后一个事件的最早时间
for (int k = n - 1; k >= 0; --k)
{
int i = topo[k]; //事件i
for (size_t j = 0; j < n; ++j) //找到事件i的邻接点j i-->j
{
if (_matrix[i][j] != MAX_W && _matrix[i][j] != W())
{
if (ltv[i] + _matrix[i][j] > ltv[j]) //(事件i的最晚时间 + i->j的活动事件)大于事件j的最晚时间,说明事件i要提早一点
{
ltv[i] = ltv[j] - _matrix[i][j]; //更新事件i的最晚时间。
}
}
}
}
//活动的最早与最晚开始时间求解,并找到关键路径。
int ete, lte;
for (size_t i = 0; i < n; ++i) //对n个事件各自所关联的活动进行检测
{
for (size_t j = 0; j < n; ++j) //找事件i的邻接事件j之间的活动
{
if (_matrix[i][j] != MAX_W && _matrix[i][j] != W())
{
ete = etv[i]; //活动的最早开始时间为事件i的最早时间
lte = ltv[j] - _matrix[i][j]; //活动的最晚开始时间为事件j的最晚时间减去活动本身的时间
if (ete == lte) //活动的最早开始时间与最晚开始时间相等,那么就表示找到了关键活动
{
//由于是依次遍历二维矩阵,所以活动的顺序极有可能是混乱的,输出关键路径的话要做专门的处理,这里就先保存起来
cPath.push_back(Edge(i, j, _matrix[i][j]));
}
}
}
}
return ltv[topo[n - 1]]; //拓扑排序的最后一个事件的最晚时间就是关键路径的时间
}
多支交叉路径的分离输出
上面的代码中提到了关键活动的先存起来而不输出的问题,这是由于关键活动的遍历顺序极有可能不是关键路径的顺序,并且还有可能出现多个关键路径以及路径分叉与合叉的情况。说实话,将这些路径剥离开并单独输出来是有一点复杂的,但是可以做一些尝试去梳理。具体的思路就是先根据关键活动建立一个新的图,我称之为关键路径图。它的特点就是所有的路径都是关键路径,在此基础之上再进行深度优先遍历(传送门),由于每个路径都要单独输出,因此在递归语句之后还要判断一个事件是否还有剩余的邻接事件,有的话,一旦当前事件递归结束,就先输出当前事件之前访问的事件,再进行深度遍历输出,那么这条新的路径递归到最后给人的感觉就又是一条单独的路径了。
文字描述还是有点复杂难懂,我们先看代码,再结合流程图会更好理解上面话的意思。
//参数:CPG:关键路径所构成的图(关键图) cPath:关键路径上活动(弧)的集合 visitedP:已访问过的路径
void CriticalPathPrint(Self &CPG, vector<Edge> &cPath, vector<int> &visitedP)
{
size_t n = _vertexs.size();
CPG._vertexs = _vertexs; //首先把原图的所有顶点拷贝过来,关键路径不一定会用到所有的顶点,但是没关系,空间稍稍浪费一点也没问题(待优化)
CPG._indexMap = _indexMap;
CPG._matrix.resize(n); //将关键图的矩阵先初始化
for (size_t i = 0; i < n; ++i)
{
CPG._matrix[i].resize(n, MAX_W);
CPG._matrix[i][i] = W();
}
for (auto &e : cPath) //将各个关键边放进关键图中,造图
{
CPG._AddEdge(e._srci, e._dsti, e._w);
}
//寻找最开始的活动
size_t srci;
for (size_t i = 0; i < cPath.size(); ++i)
{
int flag = 1;
for (size_t j = 0; j < cPath.size(); ++j) //只要活动i满足不是其他活动j之后,就说明活动i是初始活动
{
if (cPath[i]._srci == cPath[j]._dsti) //活动i的起始事件不能是活动j的结束事件,否则的话就说明i不是初始活动
{
flag = 0;
break;
}
}
if (flag)
{
srci = cPath[i]._srci; //此时说明走了一个循环所有的关键活动都没指向关键活动i,关键活动i就是
}
}
_CriticalPathPrint(CPG, srci, visitedP); //递归深度遍历
}
//参数:CPG:关键路径所构成的图(关键图) srci:要访问的事件 visitedP:已访问过的路径
//传参的时候已经访问过的路径要用传值传参,原因在于递归式的访问岔路时,每次已访问过的路径是与当前事件相关的。
void _CriticalPathPrint(Self &CPG, size_t srci, vector<int> visitedP)
{
cout << "->" << CPG._vertexs[srci];//访问事件,并且将其归到已访问的路径中去。
visitedP.push_back(srci);
for (size_t i = 0; i < CPG._vertexs.size(); ++i)//找该事件的所有邻接事件
{
if (CPG._matrix[srci][i] != MAX_W && CPG._matrix[srci][i] != W())//找到了就递归式访问下去。
{
_CriticalPathPrint(CPG, i, visitedP);
//运行到这里说明其中有一条路径已经被访问到底了,那么就要检测此时的事件除了已经访问过的邻接事件是否还有没访问过的。
for (size_t j = i + 1; j < CPG._vertexs.size(); ++j)
{
if (CPG._matrix[srci][j] != MAX_W && CPG._matrix[srci][j] != W())
{
cout << " | ";//与上一条路径分隔开
for (size_t j = 0; j < visitedP.size(); ++j)//将已访问过的事件输出
{
cout << "->" << CPG._vertexs[visitedP[j]];
}
break;//输出一条路径后一定要跳出循环,保证只输出一条分叉路经的已访问事件。
}
}
}
}
}
共使用两个图例测试
先整一个比较特殊的图来说明一下:
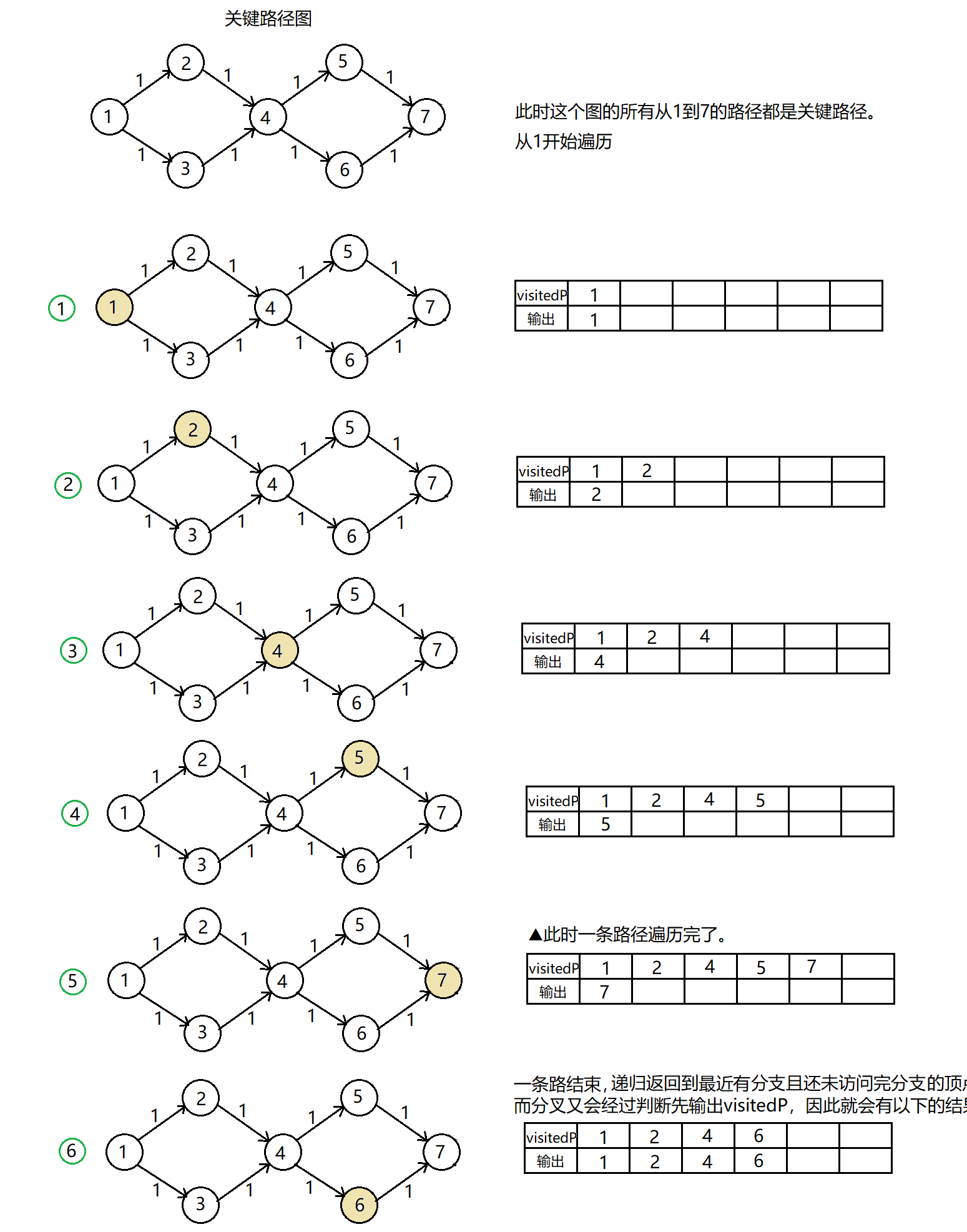
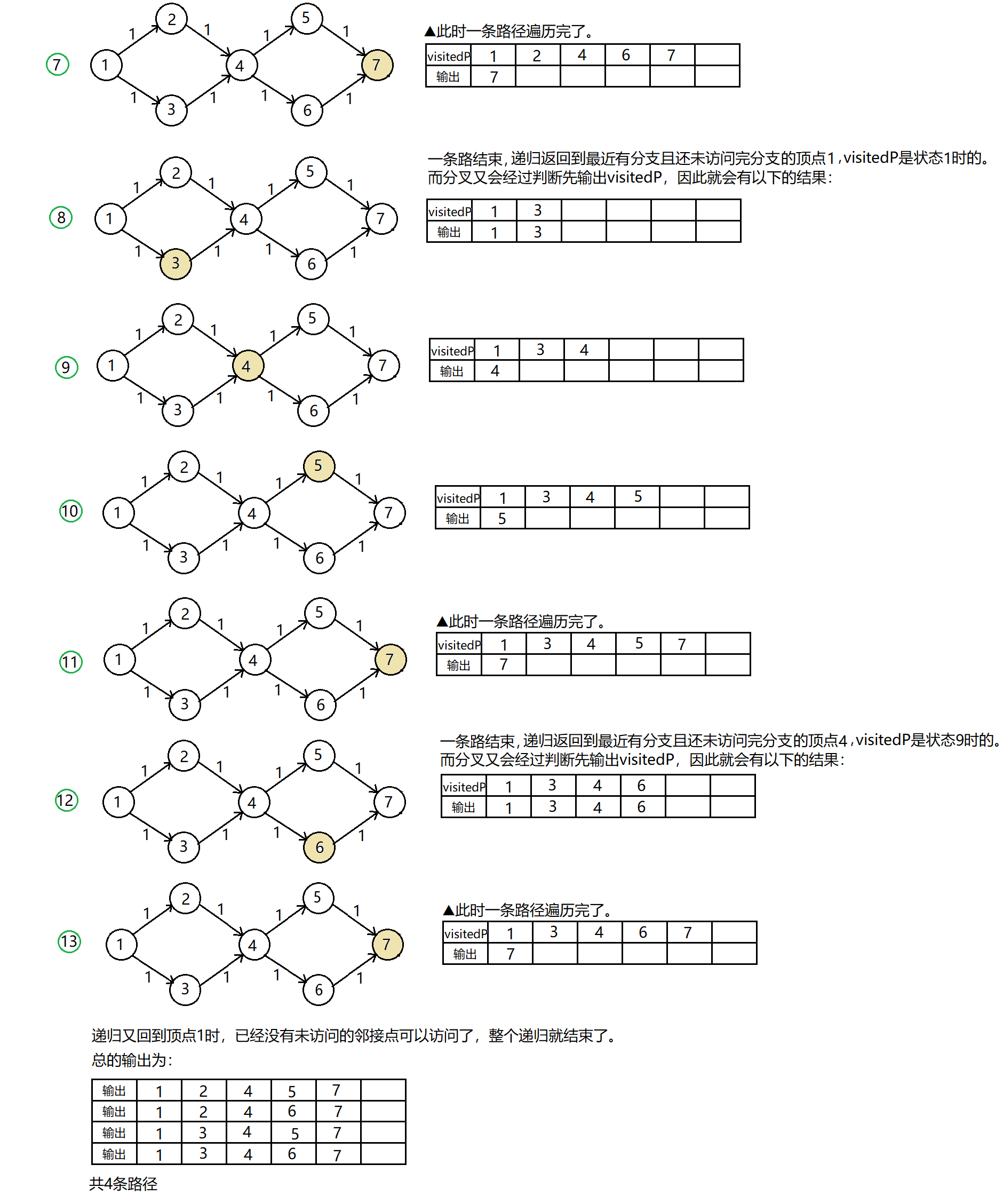
测试代码:
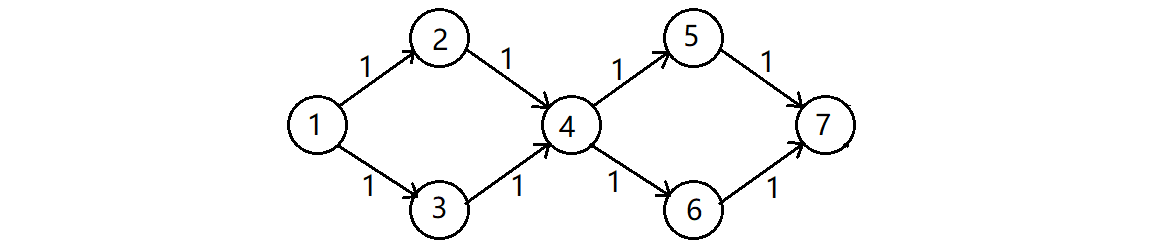
void TestCriticalPathFind()
{
const char* str = "1234567";
Graph<char, int, INT32_MAX, true> g(str, strlen(str));
Graph<char, int, INT32_MAX, true> CPG;
//造图
g.AddEdge('1', '2', 1);
g.AddEdge('1', '3', 1);
g.AddEdge('2', '4', 1);
g.AddEdge('3', '4', 1);
g.AddEdge('4', '5', 1);
g.AddEdge('4', '6', 1);
g.AddEdge('5', '7', 1);
g.AddEdge('6', '7', 1);
vector<Edge<int>> cPath;
int totalW = g.CriticalPathFind(cPath);
vector<int> visitedP;
g.CriticalPathPrint(CPG, cPath, visitedP);//关键路径的输出
cout << " | totalW: " << totalW << endl;
}
int main()
{
TestCriticalPathFind();
return 0;
}
测试结果:
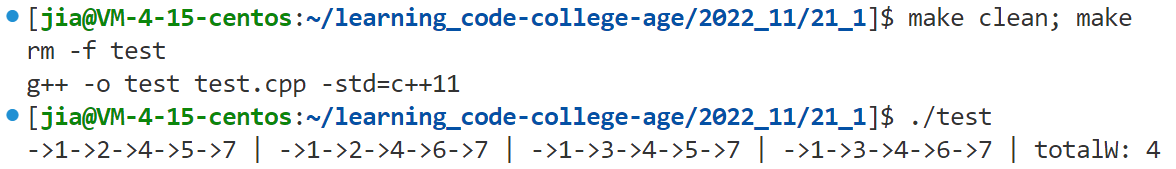
与预想中的一致。
🔺再测试一个各个教材比较喜欢举例的图:
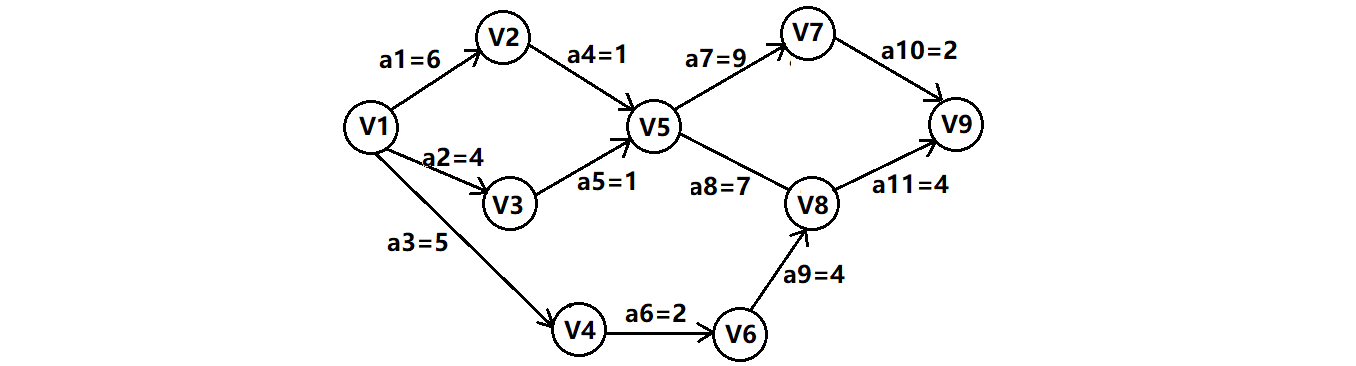
测试代码:
void TestCriticalPathFind()
{
const char* str = "123456789";
Graph<char, int, INT32_MAX, true> g(str, strlen(str));
Graph<char, int, INT32_MAX, true> CPG;
//造图
g.AddEdge('1', '2', 6);
g.AddEdge('1', '3', 4);
g.AddEdge('1', '4', 5);
g.AddEdge('2', '5', 1);
g.AddEdge('3', '5', 1);
g.AddEdge('5', '7', 9);
g.AddEdge('5', '8', 7);
g.AddEdge('7', '9', 2);
g.AddEdge('8', '9', 4);
g.AddEdge('4', '6', 2);
g.AddEdge('6', '8', 4);
vector<Edge<int>> cPath;
int totalW = g.CriticalPathFind(cPath);
vector<int> visitedP;
g.CriticalPathPrint(CPG, cPath, visitedP);
cout << " | totalW: " << totalW << endl;
}
int main()
{
TestCriticalPathFind();
return 0;
}
测试结果:

关键路径确实与教材上一致。
总结
关键路径的难点在于理解最早与最晚时间的求解与它们之间的关系,看不懂的话建议自己动手画一画。后面的多支交叉路径的分离输出其实真正考的还是深度遍历的另类扩展应用,也是比较难的,在递归中处理问题特别不好控制,很多时候并不作强制要求,因此实在不懂的话可以直接输出各个活动就可以了。我在写的时候,最开始用的也不是递归写法,只解决了一部分特殊情况,多条路径分叉与合叉的情况太过于复杂也不行。递归输出就怕层数太深,导致栈溢出问题。并且由于是每次都传值传参,有点浪费空间。总的来说,性价比不高,大家如果有什么更好的思路可以在评论区留言哦🐾~

![[附源码]计算机毕业设计springboot现代诗歌交流平台](https://img-blog.csdnimg.cn/dd85a0541e11478a8e0d8fde0a230ba1.png)

![[附源码]Python计算机毕业设计SSM开放式在线课程教学与辅助平台(程序+LW)](https://img-blog.csdnimg.cn/599888a6c0de498789464ba3346d8e04.png)
![[附源码]计算机毕业设计JAVA校园闲置物品租赁系统](https://img-blog.csdnimg.cn/d5c4b408de2d44349ad74550d7c66160.png)



![[附源码]计算机毕业设计-菜篮子系统Springboot程序](https://img-blog.csdnimg.cn/f238c89d8253447cba4f5c4ba60f3c4d.png)